Il web crawler ufficiale di OpenAI che raccoglie dati di addestramento per modelli di IA come ChatGPT e GPT-4. I proprietari di siti web possono controllare l’accesso tramite robots.txt usando le direttive ‘User-agent: GPTBot’. Il crawler rispetta i protocolli web standard e indicizza solo contenuti pubblicamente accessibili.
GPTBot
Il web crawler ufficiale di OpenAI che raccoglie dati di addestramento per modelli di IA come ChatGPT e GPT-4. I proprietari di siti web possono controllare l’accesso tramite robots.txt usando le direttive 'User-agent: GPTBot'. Il crawler rispetta i protocolli web standard e indicizza solo contenuti pubblicamente accessibili.
Cos’è GPTBot?
GPTBot è il web crawler ufficiale di OpenAI, progettato per indicizzare contenuti pubblicamente disponibili da tutto il web per addestrare e migliorare modelli di IA come ChatGPT e GPT-4. A differenza dei crawler dei motori di ricerca generici come Googlebot, GPTBot opera con una missione specifica: raccogliere dati che aiutano OpenAI a potenziare i propri modelli linguistici e fornire risposte IA più efficaci agli utenti. I proprietari di siti possono identificare GPTBot tramite la sua stringa user agent distintiva (“GPTBot/1.0”), che appare nei log del server e nelle piattaforme di analytics ogni volta che il crawler accede alle loro pagine. GPTBot rispetta il file robots.txt, il che significa che i proprietari di siti possono controllare se il crawler accede ai loro contenuti aggiungendo specifiche direttive a questo file. Il crawler indicizza solo contenuti pubblicamente accessibili e non tenta di aggirare autenticazioni o accedere ad aree riservate dei siti. Comprendere lo scopo e il comportamento di GPTBot è essenziale per i proprietari di siti che vogliono prendere decisioni consapevoli sull’opportunità di consentire o bloccare questo crawler dalle proprie proprietà digitali.
Come Funziona GPTBot
GPTBot opera eseguendo una scansione sistematica delle pagine web, analizzando i contenuti e inviando i dati ai server di OpenAI per l’elaborazione e l’addestramento dei modelli. Il crawler verifica innanzitutto il file robots.txt del sito per determinare quali pagine può visitare, rispettando le direttive specificate dai proprietari prima di qualsiasi attività di indicizzazione. Una volta che GPTBot si identifica tramite la sua stringa user agent, scarica ed elabora il contenuto delle pagine, estraendo testo, metadati e informazioni strutturali utili alla creazione dei dataset di addestramento. Il crawler può generare un notevole consumo di banda, con alcuni siti che segnalano oltre 30TB di traffico crawler mensile considerando tutti i bot, anche se l’impatto individuale di GPTBot varia in base alla dimensione e alla rilevanza dei contenuti del sito.
Nome Crawler
Scopo
Rispetta robots.txt
Impatto su SEO
Utilizzo Dati
GPTBot
Addestramento IA
Sì
Indiretto (visibilità IA)
Dataset di training
Googlebot
Indicizzazione ricerca
Sì
Diretto (ranking)
Risultati di ricerca
Bingbot
Indicizzazione ricerca
Sì
Diretto (ranking)
Risultati di ricerca
ClaudeBot
Addestramento IA
Sì
Indiretto (visibilità IA)
Dataset di training
I proprietari di siti possono monitorare l’attività di GPTBot nei log del server cercando la specifica stringa user agent, così da tracciare la frequenza di scansione e identificare eventuali impatti sulle prestazioni. Il comportamento del crawler è progettato per essere rispettoso delle risorse del server, ma i siti ad alto traffico possono comunque riscontrare un consumo di banda significativo quando più crawler IA operano simultaneamente.
Perché i Proprietari di Siti Bloccano GPTBot
Molti proprietari di siti scelgono di bloccare GPTBot per timore di utilizzo dei contenuti senza compenso, poiché OpenAI usa i contenuti scansionati per addestrare modelli IA commerciali senza fornire benefici o pagamenti diretti ai creatori. Il carico sul server rappresenta un’altra preoccupazione, specialmente per siti più piccoli o con banda limitata, dato che i crawler IA possono consumare risorse considerevoli—alcuni siti segnalano oltre 30TB di traffico crawler mensile complessivo, con GPTBot che contribuisce in modo significativo. Esposizione dei dati e rischi di sicurezza preoccupano i creatori che temono che informazioni proprietarie, segreti commerciali o dati sensibili possano essere indicizzati e usati nell’addestramento IA, compromettendo vantaggi competitivi o violando accordi di riservatezza. Il contesto legale sull’utilizzo dei dati per l’addestramento IA è ancora incerto, con interrogativi irrisolti su conformità GDPR, obblighi CCPA e violazione del copyright, creando rischi sia per OpenAI che per i siti che consentono la scansione illimitata. Le statistiche mostrano che circa il 3,5% dei siti blocca attivamente GPTBot, mentre oltre 30 grandi testate tra i primi 100 siti web bloccano il crawler, tra cui The New York Times, CNN, Associated Press e Reuters—a riprova che i creatori di contenuti più autorevoli riconoscono rischi concreti. La combinazione di questi fattori rende il blocco di GPTBot una pratica sempre più diffusa tra editori, media company e siti ricchi di contenuti che vogliono proteggere la proprietà intellettuale e mantenere il controllo sull’utilizzo dei propri contenuti.
Perché i Proprietari di Siti Consentono GPTBot
Chi consente l’accesso a GPTBot riconosce il valore strategico della visibilità su ChatGPT, considerando che la piattaforma serve circa 800 milioni di utenti settimanali che interagiscono regolarmente con risposte IA che possono citare o riassumere i contenuti indicizzati. Quando GPTBot scansiona un sito, aumenta la probabilità che i contenuti vengano citati, riassunti o menzionati nelle risposte ChatGPT, offrendo rappresentazione del brand all’interno delle interfacce IA e raggiungendo utenti che sempre più spesso si affidano a strumenti IA invece che ai motori di ricerca tradizionali. Le ricerche dimostrano che il traffico di ricerca IA converte 23 volte meglio rispetto alla ricerca organica tradizionale, cioè gli utenti che scoprono contenuti tramite riepiloghi e raccomandazioni IA mostrano un tasso di engagement e conversione molto superiore rispetto ai visitatori dai motori di ricerca standard. Consentire l’accesso a GPTBot rappresenta una forma di preparazione al futuro, dato che la ricerca e la scoperta dei contenuti tramite IA stanno diventando sempre più dominanti nelle modalità di informazione online, rendendo l’adozione anticipata di strategie per la visibilità IA un vantaggio competitivo. I proprietari di siti che abbracciano GPTBot beneficiano anche della Generative Engine Optimization (GEO), una disciplina emergente focalizzata sull’ottimizzazione dei contenuti per i sistemi IA piuttosto che per i tradizionali algoritmi di ricerca, che può generare una crescita consistente del traffico nel lungo periodo. Consentendo l’accesso a GPTBot, editori e aziende lungimiranti si posizionano per intercettare traffico dal segmento in rapida crescita di utenti che si affidano agli strumenti IA per la scoperta delle informazioni e le decisioni.
Come Bloccare GPTBot
Bloccare GPTBot è semplice e richiede solo modifiche al file robots.txt del sito, posizionato nella directory principale e utilizzato per controllare l’accesso dei crawler all’intero dominio. Il modo più immediato è aggiungere un blocco totale per tutti i crawler di OpenAI:
User-agent: GPTBot
Disallow: /
Se vuoi bloccare GPTBot solo da alcune directory e consentirne l’accesso alle altre, usa direttive mirate:
Oltre alle modifiche su robots.txt, i proprietari dei siti possono implementare metodi di blocco alternativi come il blocco IP tramite firewall, Web Application Firewall (WAF) che filtrano le richieste per user agent, e il rate limiting che limita il consumo di banda dei crawler. Per il massimo controllo, alcuni siti combinano più approcci—usando robots.txt come metodo principale e il blocco IP come ulteriore salvaguardia contro crawler che ignorano le direttive robots.txt. Dopo aver implementato qualsiasi strategia di blocco, verifica l’efficacia controllando nei log del server la presenza di stringhe user agent GPTBot per confermare che il crawler non acceda più ai tuoi contenuti.
Settori che Dovrebbero Valutare il Blocco
Alcuni settori sono particolarmente esposti ai rischi di un accesso illimitato dei crawler IA e dovrebbero valutare attentamente se il blocco di GPTBot sia in linea con i propri interessi di business e le strategie di protezione dei contenuti:
Editoria & Media Company (giornali, riviste, agenzie stampa) – Il giornalismo originale è frutto di investimenti e vantaggi competitivi; testate come The New York Times, Associated Press e Reuters bloccano GPTBot per proteggere le esclusive
Piattaforme e-commerce (Amazon, siti retail) – Descrizioni prodotto, strategie di prezzo e recensioni sono dati proprietari che i competitor potrebbero sfruttare tramite l’addestramento IA
Piattaforme di contenuti generati dagli utenti (social, forum, siti di recensioni) – I contenuti creati dagli utenti potrebbero essere utilizzati senza consenso o compenso, sollevando questioni etiche e legali sui diritti degli utenti
Siti di dati autorevoli (istituti di ricerca, database accademici, repository di conoscenza specialistica) – Ricerche proprietarie, dataset e conoscenze specialistiche hanno grande valore commerciale e dovrebbero restare sotto il controllo dei creatori
Servizi legali e finanziari – Informazioni sensibili su clienti, strategie legali e consulenze finanziarie richiedono massima riservatezza e non possono essere esposte nei dataset di addestramento IA
Contenuti sanitari e medici – Dati paziente, cartelle cliniche e informazioni cliniche devono rispettare HIPAA e altre normative che vietano l’uso non autorizzato dei dati
Questi settori dovrebbero attuare strategie di blocco per mantenere i vantaggi competitivi, proteggere le informazioni proprietarie e garantire la conformità alle normative sulla protezione dei dati.
Monitoraggio e Rilevamento
I proprietari di siti dovrebbero monitorare regolarmente i log del server per identificare l’attività di GPTBot e tracciare i pattern di scansione, ottenendo così visibilità su come i sistemi IA accedono e potenzialmente utilizzano i loro contenuti. L’identificazione di GPTBot è semplice—il crawler si presenta tramite la stringa user agent “GPTBot/1.0” nelle intestazioni HTTP, rendendolo facilmente distinguibile dagli altri crawler nei log del server e nelle piattaforme di analytics. La maggior parte dei tool di analytics e software di monitoraggio SEO moderni (inclusi Google Analytics, Semrush, Ahrefs e piattaforme specializzate di monitoraggio bot) categorizza e riporta automaticamente l’attività di GPTBot, permettendo ai proprietari dei siti di tracciare frequenza di scansione, consumo di banda e pagine visitate senza analisi manuale dei log. L’analisi diretta dei log del server rivela informazioni dettagliate sulle richieste GPTBot, inclusi timestamp, URL visitati, codici di risposta e consumo di banda, fornendo insight granulari sul comportamento del crawler. Il monitoraggio regolare è essenziale perché il comportamento dei crawler può cambiare nel tempo, possono emergere nuovi crawler IA e l’efficacia dei blocchi richiede verifiche periodiche per assicurarsi che le direttive funzionino come previsto. I proprietari dei siti dovrebbero stabilire metriche di base per il traffico crawler normale e indagare su eventuali deviazioni significative che potrebbero indicare un aumento dell’attività IA o problemi di sicurezza da affrontare.
Standard di Sicurezza OpenAI
OpenAI ha assunto impegni pubblici per uno sviluppo e una gestione responsabile dell’IA, inclusi dichiarazioni esplicite secondo cui GPTBot rispetta le preferenze dei proprietari di siti espresse tramite robots.txt e altre direttive tecniche. L’azienda pone l’accento su privacy dei dati e pratiche IA responsabili, riconoscendo che i creatori di contenuti hanno legittimi interessi nel controllare l’uso e la compensazione del proprio lavoro, anche se l’attuale approccio OpenAI non prevede compensi diretti ai creatori dei contenuti scansionati. La policy documentata di OpenAI conferma che GPTBot rispetta le direttive robots.txt, segnalando che l’azienda ha integrato meccanismi di conformità nell’infrastruttura del crawler e si aspetta che i proprietari di siti utilizzino gli strumenti tecnici standard per controllare l’accesso. L’azienda si è anche dichiarata disponibile a dialogare con editori e creatori riguardo le preoccupazioni sull’uso dei dati, anche se accordi formali di licenza e sistemi di compensazione sono ancora limitati. Le policy di OpenAI continuano a evolvere in risposta a sfide legali, pressioni regolatorie e feedback del settore, facendo ipotizzare che le versioni future di GPTBot potranno includere ulteriori tutele, misure di trasparenza o meccanismi di compensazione. I proprietari di siti dovrebbero monitorare le comunicazioni ufficiali e gli aggiornamenti di policy di OpenAI per capire come potrà cambiare nel tempo l’approccio dell’azienda a crawling e uso dei dati.
GPTBot vs Altri Crawler IA
OpenAI gestisce tre tipi distinti di crawler per scopi diversi: GPTBot (crawling web generale per addestramento modelli), ChatGPT-User (scansione di link condivisi dagli utenti ChatGPT) e ChatGPT-Plugins (accesso ai contenuti tramite integrazioni plugin)—ognuno con diverse stringhe user agent e pattern di accesso. Oltre ai crawler OpenAI, il panorama IA comprende numerosi altri crawler gestiti da aziende concorrenti: Google-Extended (crawler di Google per l’addestramento IA), CCBot (Commoncrawl), Perplexity (motore di ricerca IA), Claude (modello IA di Anthropic) e nuovi crawler emergenti da altre aziende IA, ognuno con scopi e modalità di utilizzo dei dati differenti. I proprietari di siti devono scegliere tra blocco selettivo (indirizzato a specifici crawler come GPTBot lasciando passare altri) e blocco totale (restrizione di tutti i crawler IA per mantenere il pieno controllo sull’uso dei contenuti). La proliferazione dei crawler IA implica che bloccare solo GPTBot potrebbe non bastare a proteggere i contenuti dall’addestramento IA, dato che altri crawler potrebbero comunque accedere e indicizzare lo stesso materiale tramite meccanismi alternativi. Alcuni proprietari implementano strategie a livelli, bloccando i crawler più aggressivi o commercialmente rilevanti e consentendo l’accesso a quelli più piccoli o orientati alla ricerca. Comprendere le differenze tra questi crawler aiuta i proprietari a prendere decisioni consapevoli su quali bloccare, in base a preoccupazioni specifiche su utilizzo dei dati, impatto competitivo e obiettivi di business.
Impatto su SEO e Visibilità di Ricerca
L’influenza di ChatGPT sul comportamento di ricerca sta rimodellando il modo in cui gli utenti scoprono le informazioni: 800 milioni di utenti settimanali si rivolgono sempre più spesso agli strumenti IA invece che ai motori di ricerca tradizionali, cambiando radicalmente il panorama competitivo della visibilità dei contenuti. I riepiloghi generati dall’IA e i featured snippet nelle risposte ChatGPT rappresentano ora meccanismi alternativi di scoperta, per cui i contenuti che si posizionano bene nei risultati di ricerca tradizionali potrebbero essere trascurati se non selezionati per le risposte IA. La Generative Engine Optimization (GEO) è diventata una disciplina chiave per i creatori di contenuti più lungimiranti, focalizzata sull’ottimizzazione di struttura, chiarezza e autorevolezza per aumentare le probabilità di inclusione nei riepiloghi e nelle risposte IA. Le implicazioni di visibilità a lungo termine sono significative: i siti che bloccano GPTBot rischiano di perdere opportunità di apparire nelle risposte ChatGPT, riducendo potenzialmente il traffico dal segmento in rapida crescita degli utenti di ricerca IA, mentre chi consente l’accesso si posiziona per la scoperta guidata dall’IA. Le ricerche indicano che l’86,5% dei contenuti nei primi 20 risultati di Google contiene elementi parzialmente generati da IA, segnalando che l’integrazione IA sta diventando la norma nell’ecosistema di ricerca. Il posizionamento competitivo dipende sempre più dalla visibilità sia sui motori di ricerca tradizionali sia sui sistemi IA, rendendo strategiche le scelte sull’accesso a GPTBot per il successo SEO e la crescita del traffico organico nel lungo periodo. I proprietari di siti devono bilanciare le esigenze di protezione dei contenuti con il rischio di perdere visibilità nei sistemi IA che stanno diventando i principali meccanismi di scoperta per milioni di utenti in tutto il mondo.
Domande frequenti
Cos’è GPTBot e in cosa differisce da Googlebot?
GPTBot è il web crawler ufficiale di OpenAI progettato per raccogliere dati di addestramento per modelli di IA come ChatGPT e GPT-4. A differenza di Googlebot, che indicizza i contenuti per risultati nei motori di ricerca, GPTBot raccoglie dati specificamente per migliorare i modelli linguistici. Entrambi i crawler rispettano le direttive robots.txt e accedono solo a contenuti pubblicamente disponibili, ma servono scopi fondamentalmente diversi nell’ecosistema digitale.
Dovrei bloccare GPTBot dal mio sito web?
La decisione dipende dai tuoi obiettivi di business e dalla strategia sui contenuti. Blocca GPTBot se hai contenuti proprietari, operi in settori regolamentati o hai preoccupazioni legate alla proprietà intellettuale. Consenti GPTBot se desideri visibilità su ChatGPT (800 milioni di utenti settimanali), beneficiare del traffico di ricerca IA (che converte 23 volte meglio dell’organico) o vuoi preparare la tua presenza digitale per la ricerca guidata da IA.
Come posso bloccare GPTBot usando robots.txt?
Aggiungi queste righe al tuo file robots.txt per bloccare GPTBot dall’intero sito: User-agent: GPTBot / Disallow: /. Per bloccare directory specifiche, sostituisci la barra con il percorso della directory. Per bloccare tutti i crawler OpenAI, aggiungi voci User-agent separate per GPTBot, ChatGPT-User e ChatGPT-Plugins. Le modifiche hanno effetto immediato e sono facilmente reversibili.
Qual è l’impatto di GPTBot sul mio server e sulla banda?
L’impatto di GPTBot varia in base alla dimensione del sito e alla rilevanza dei contenuti. Sebbene l’impatto di un singolo crawler sia generalmente gestibile, più crawler IA che operano contemporaneamente possono consumare molta banda—alcuni siti segnalano oltre 30TB di traffico crawler mensile complessivo. Monitora i log del server per tracciare l’attività di GPTBot e applica limiti di velocità o blocco IP se il consumo di banda diventa problematico.
Posso bloccare parzialmente GPTBot da alcune pagine?
Sì, puoi usare direttive robots.txt mirate per bloccare GPTBot da directory o pagine specifiche consentendo l’accesso alle altre. Ad esempio, puoi negare l’accesso alle directory /private/ e /admin/, lasciando disponibile il resto del sito. Questo approccio selettivo ti permette di proteggere i contenuti sensibili mantenendo la visibilità nelle IA per le pagine pubbliche.
Come faccio a sapere se GPTBot visita il mio sito?
Controlla i log del server per la stringa user agent 'GPTBot/1.0' nelle intestazioni delle richieste HTTP. La maggior parte delle piattaforme di analytics (Google Analytics, Semrush, Ahrefs) categorizza e riporta automaticamente l’attività di GPTBot. Puoi anche usare strumenti di monitoraggio SEO che tracciano specificamente l’attività dei crawler IA. Un monitoraggio regolare ti aiuta a comprendere la frequenza delle visite e identificare eventuali impatti sulle prestazioni.
Quali sono le implicazioni legali del bloccare o consentire GPTBot?
Il quadro legale è ancora in evoluzione. Consentire GPTBot solleva interrogativi su conformità GDPR, obblighi CCPA e violazione del copyright, sebbene OpenAI affermi di rispettare le direttive robots.txt. Bloccare GPTBot è legalmente semplice ma può limitare la visibilità nei sistemi IA. Consulta un legale se operi in settori regolamentati o gestisci dati sensibili per determinare l’approccio migliore per la tua situazione.
Come influisce consentire GPTBot su SEO e visibilità di ricerca?
Consentire GPTBot non influisce direttamente sul posizionamento tradizionale su Google, ma aumenta la visibilità nelle risposte di ChatGPT e in altri risultati di ricerca IA. Con 800 milioni di utenti ChatGPT e il traffico di ricerca IA che converte 23 volte meglio dell’organico, consentire GPTBot ti posiziona per una visibilità a lungo termine nei sistemi IA. Bloccare GPTBot può ridurre le opportunità di apparire nelle risposte generate dall’IA, limitando potenzialmente il traffico dal segmento di ricerca a più rapida crescita.
Monitora il Tuo Brand nei Risultati di Ricerca IA
Tieni traccia di come appare il tuo brand su ChatGPT, Perplexity, Google AI e altre piattaforme IA. Ottieni insight in tempo reale sulle citazioni e la visibilità su IA con AmICited.
Cos'è GPTBot e Dovresti Permetterlo? Guida Completa per Proprietari di Siti Web
Scopri cos'è GPTBot, come funziona e se dovresti consentire o bloccare il crawler web di OpenAI. Comprendi l'impatto sulla visibilità del tuo brand nei motori d...
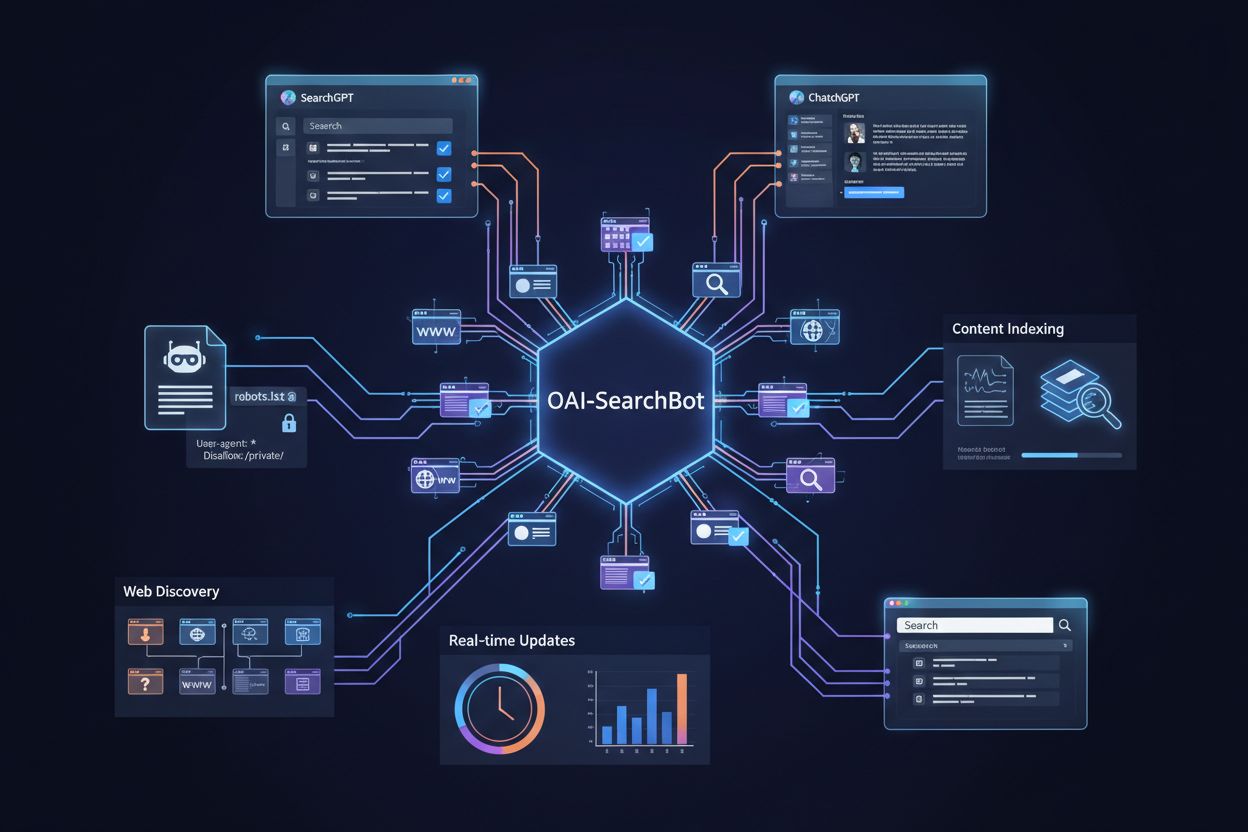
GPTBot vs OAI-SearchBot: Comprendere i diversi crawler di OpenAI
Scopri le principali differenze tra i crawler GPTBot e OAI-SearchBot di OpenAI. Comprendi i loro scopi, comportamenti di scansione e come gestirli per una visib...
Scopri cos'è OAI-SearchBot, come funziona e come ottimizzare il tuo sito web per il crawler di ricerca dedicato di OpenAI utilizzato da SearchGPT e ChatGPT.
7 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.