
AIのためのエンティティ最適化:ブランドをLLMに認識させる方法
エンティティ最適化がブランドをLLMに認識させる仕組みを解説。ナレッジグラフ最適化、スキーママークアップ、AIでの可視性向上のためのエンティティ戦略をマスターしましょう。...
1 分で読める
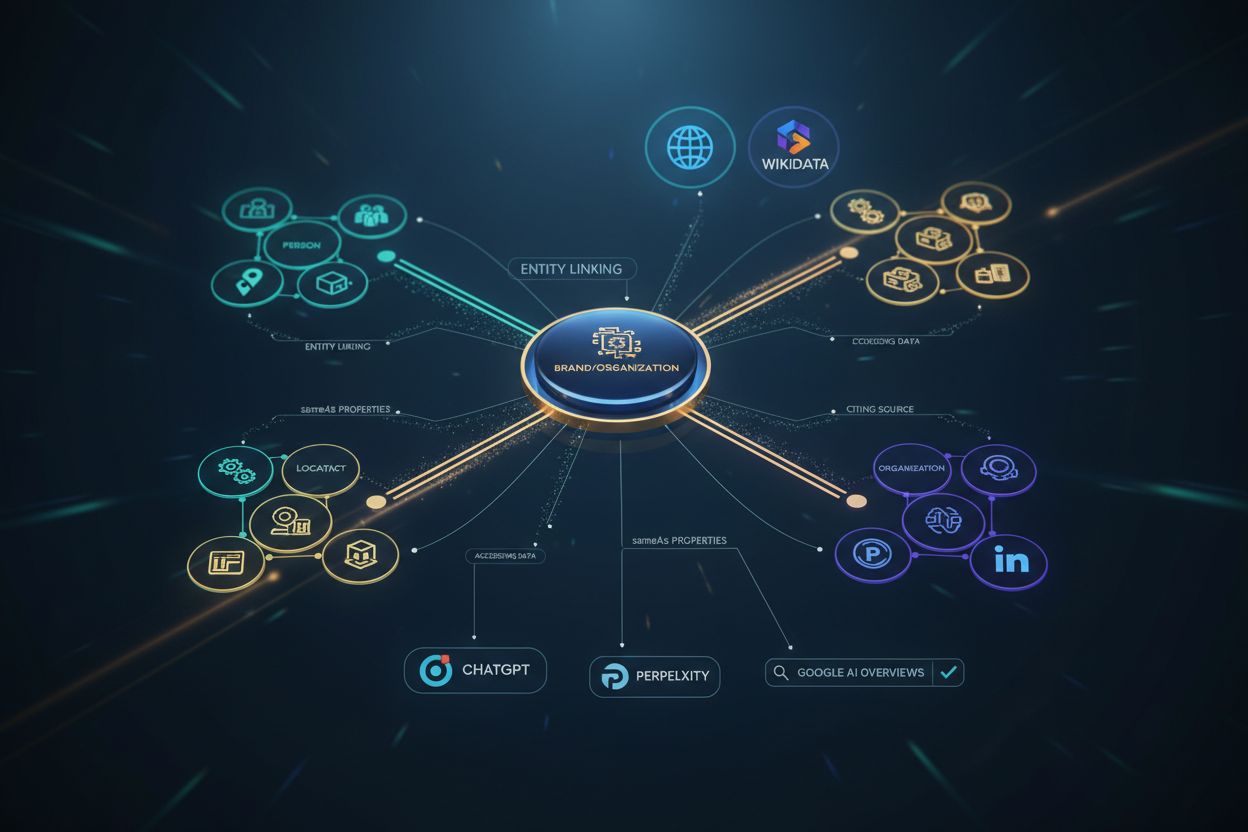
ChatGPT、Perplexity、Google AIオーバービューなどのAIシステムがコンテンツを正確に認識、理解し、より高い信頼性と権威で引用できるように、エンティティ(人、組織、製品、場所)を機械可読形式で明確に定義するSchema.org構造化データ。
ChatGPT、Perplexity、Google AIオーバービューなどのAIシステムがコンテンツを正確に認識、理解し、より高い信頼性と権威で引用できるように、エンティティ(人、組織、製品、場所)を機械可読形式で明確に定義するSchema.org構造化データ。
AIエンティティマークアップは、人、組織、製品、場所などのエンティティをAIシステムが簡単に認識して理解できる機械可読形式で明確に定義するSchema.org構造化データです。主に検索エンジン向けに設計された従来のSEOマークアップとは異なり、AIエンティティマークアップはChatGPT、Perplexity、Google AIオーバービューなどの人工知能システムがウェブコンテンツを解析、解釈、引用する方法に特化して最適化されています。このマークアップは、あいまいなテキストを、AIシステムが情報を自信を持って抽出し、権威あるソースに帰属させることができる検証可能な構造化された事実に変換します。AI生成回答がますます従来の検索結果に取って代わるにつれて、適切なエンティティマークアップの実装は、あると良い最適化から、AI駆動の検索環境でのブランドの可視性と信頼性のための不可欠なインフラストラクチャへと進化しました。

AIシステムは根本的に、推論ではなく確率に基づいて膨大なデータを分析して応答を生成する統計的パターンマッチングエンジンとして動作します。AIが「John SmithはAcme CorpのCEOです」のような非構造化テキストに遭遇すると、システムは検証の保証なしにトークン間の関係を推論する必要があります。しかし、その同じ情報がPersonスキーマを指すfounderプロパティを持つOrganizationスキーマでラップされると、AIシステムが自信を持って使用して引用できる検証可能な機械可読の事実になります。研究によると、ナレッジグラフに基づくLLMは、非構造化データのみに依存するものと比較して約300%高い精度を達成します—これは、コンテンツがAI生成応答で引用されるかどうかに直接影響する劇的な改善です。
| 側面 | 非構造化コンテンツ | エンティティマークアップ |
|---|---|---|
| AIの理解 | 確率的な推測 | 検証済みの事実 |
| 引用の信頼度 | 低(16%の精度) | 高(54%の精度) |
| ナレッジグラフ統合 | 限定的または不在 | 完全な統合 |
| AI引用の可能性 | より低い確率 | 30%以上高い可視性 |
| 検証能力 | AIにとって困難 | 明示的で検証可能 |
| エンティティ関係の明確さ | あいまい | 正確に定義 |
MicrosoftのプリンシパルプロダクトマネージャーFabrice Canelは、SMX Munichで「スキーママークアップはMicrosoftのLLMがコンテンツを理解するのに役立つ」と確認し、BingのCopilotは特に構造化データを使用してウェブコンテンツを解釈します。これは理論的ではありません—包括的な構造化データを持つサイトはAIオーバービューで最大30%高い可視性を見ており、これは権威あるソースとして引用されることと、人々が情報を発見する方法をますます仲介するAIシステムに完全に見えないことの違いを表しています。
すべてのスキーマタイプがAI引用に対して同等に作成されているわけではありません。Schema.orgには800以上のタイプと1000以上のプロパティが含まれていますが、LLMがコンテンツを解釈し引用する方法に直接影響するのはわずかです。AI可視性に最も重要なエンティティタイプは以下の通りです:
Organizationスキーマ:Wikipedia、LinkedIn、Crunchbase、その他の権威あるプラットフォームにリンクする包括的なsameAsプロパティで会社を定義します。これにより、ブランドがナレッジグラフで認識されたエンティティとして確立され、ソースの権威を評価するAIシステムに信頼性を示します。
Personスキーマ:外部プラットフォームへのリンクを持つ検証可能な著者プロファイルを作成することで、著者の専門性と信頼性を確立します。著者のPersonスキーマがsameAsプロパティで適切に実装されると、AIシステムは複数のプラットフォーム全体で専門性を検証でき、E-E-A-Tシグナルを強化します。
Articleスキーマ:公開日、著者情報、出版社の詳細を含みます—これらはすべて、何を引用するかを決定する際にAIシステムがコンテンツの信頼性と関連性を評価するのに役立つシグナルです。適切な著者帰属を持つArticleスキーマは、AI検索時代における信頼性のパスポートです。
Productスキーマ:価格、評価、説明、在庫情報で製品をマークアップします。EコマースやSaaS企業にとって、Productスキーマにより、AIシステムはユーザーがカテゴリのソリューションについて尋ねたときに製品を理解して推奨できます。
FAQPageスキーマ:AIシステムが情報を抽出して提示することを好む方法である質問-回答ペアとしてコンテンツを事前フォーマットします。FAQPageは、関連するクエリに回答する際にAIシステムが自信を持って引き出せる既製の引用可能な応答を提供するため、AI引用の主力です。
エンティティリンキングは、コンテンツ内の主要な概念または「エンティティ」を特定し、Wikidata、Wikipedia、Googleのナレッジグラフ、または組織独自のナレッジグラフなどの認識されたソースに接続するプロセスです。この接続は重要です。AIシステムがどのエンティティを参照しているか、より広い情報エコシステムで他の概念とどのように関連しているかを正確に理解するのに役立つからです。例えば、「Bronco」をBroncoの馬ではなくFord Bronco SUVにリンクすることで、意味を明確にし、コンテンツがAIシステムによって正しく解釈されることを確保します。
Schema.orgマークアップを通じてエンティティリンキングを実装すると、本質的にコンテンツと権威ある知識ソースの間に橋を構築しています。これらの橋により、AIシステムは関係をたどり、はるかに高い精度でコンテキストを理解できます。「Broncoでフィルターを交換する方法」について書いているカーパーツ小売業者は、「Ford Bronco」や「カーフィルター」などのエンティティにセマンティックに接続され、これが引用に値する権威ある、文脈的に関連するコンテンツであることをAIシステムに示します。sameAsプロパティはエンティティリンキングの主要なツールです—Wikipedia、Wikidata、その他の権威あるソースへのURLを含めることで、AIシステムに「このエンティティはナレッジグラフのこの認識されたエンティティと同じです」と伝えています。このクロスプラットフォームの一貫性は、AIシステムが専門性を検証し、引用の価値を判断するために使用するエンティティオーソリティを構築します。
AIエンティティマークアップを実装する最も効果的な方法は、GoogleがスキーマをHTMLコンテンツから分離し、大規模な実装と維持を容易にするために明示的に推奨するJSON-LD形式を使用することです。JSON-LDをページの<head>セクションに配置してください:
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Your Company Name",
"url": "https://www.yourcompany.com",
"logo": "https://www.yourcompany.com/logo.png",
"description": "Your company description",
"foundingDate": "2020",
"sameAs": [
"https://www.linkedin.com/company/your-company",
"https://twitter.com/yourcompany",
"https://www.crunchbase.com/organization/your-company",
"https://en.wikipedia.org/wiki/Your_Company"
],
"contactPoint": {
"@type": "ContactPoint",
"contactType": "customer service",
"email": "support@yourcompany.com"
}
}
スキーマの真の力は、@idプロパティを使用して関連エンティティを接続することから来ます。これにより、AIシステムがコンテキストを理解するためにたどることができる関係のウェブが作成されます。複数のページで同じ@idを参照することで、AIシステムがより洗練された推論に使用できるコンテンツナレッジグラフを構築します。重要なルール:ページで実際に表示されているコンテンツのみをマークアップしてください。ユーザーが情報を見ることができない場合、スキーマに含めないでください。AIシステムはスキーマとページコンテンツを相互参照し、不一致は信頼性を損ないます。これは、スキーマのFAQ回答がページのどこかに表示され、価格が表示価格と一致し、著者情報がサイトで検証可能である必要があることを意味します。
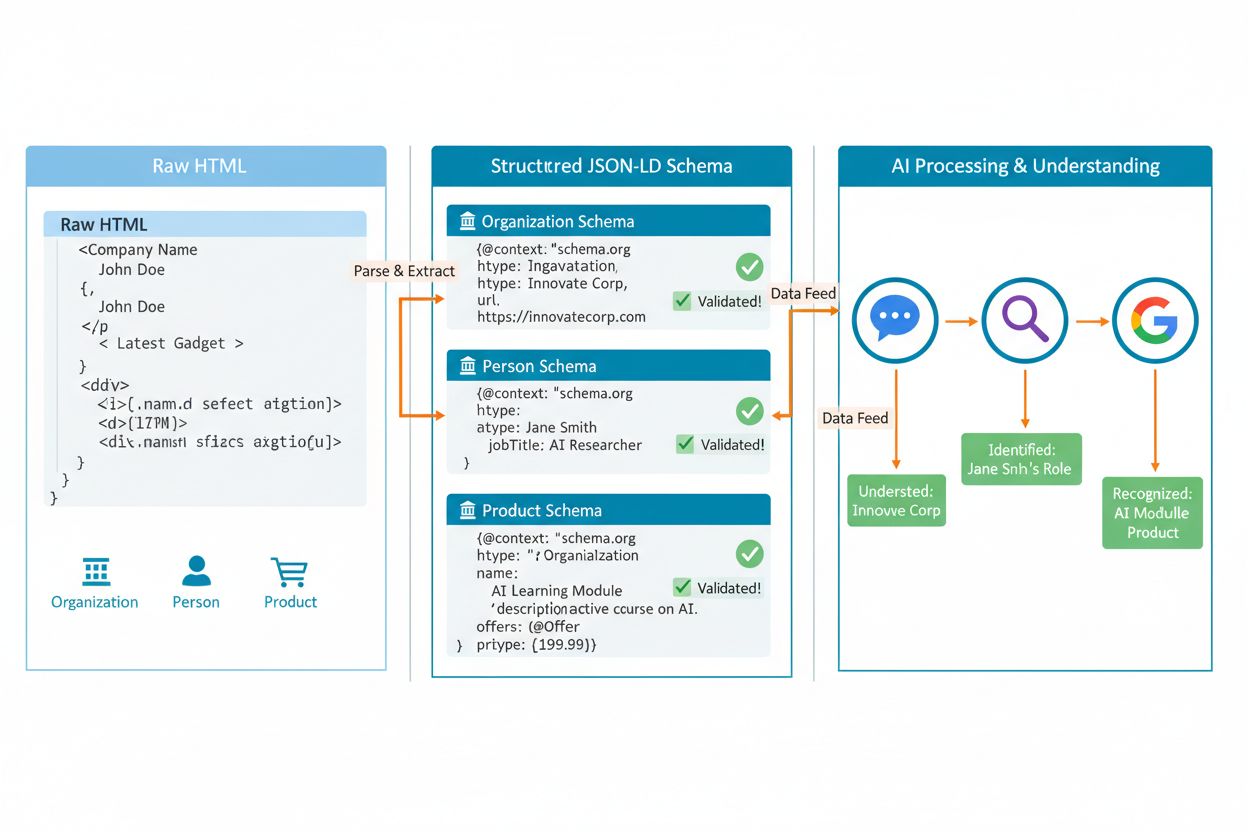
従来のスキーママークアップは主に検索エンジンがリッチスニペットを表示し、クリック率を向上させるのを助けるために設計されましたが、AIエンティティマークアップは根本的にAIシステムがコンテンツを理解、検証、自信を持って引用できるようにすることについてです。従来のSEOマークアップは検索結果で星評価を取得するのに役立つかもしれません;AIエンティティマークアップはAI生成回答で権威あるソースとして引用されるのに役立ちます。この区別は、ユーザーが複数のソースから組み合わされた要約された回答を単一のAI生成結果で見るゼロクリック検索の世界で非常に重要です。
ブランドオーソリティへの影響は深遠です。ブランドがAI生成応答に表示されると、ユーザーがサイトにクリックスルーしなくても、信頼性と専門性を示します。AIオーバービューに掲載されることは、リサーチと探索フェーズ中のバイヤージャーニーの早い段階でユーザーに到達し、大規模な認知度とオーソリティを構築します。従来のSEOはキーワードとランキングに焦点を当てています;AIエンティティマークアップはエンティティの関係とナレッジグラフの統合に焦点を当てています。ウェブサイト全体で適切なエンティティマークアップを実装するブランドは、AIシステムがあなたが何を言うかだけでなく、あなたが誰であるか、何を支持しているか、主要なトピックとどのように接続しているかを理解できるセマンティックデータレイヤーを作成します。この明確さは、AIシステムがブランドを認識して引用する方法を決定するE-E-A-Tシグナル—経験、専門性、権威性、信頼性—を強化します。
ランキングとクリックを追跡できる従来のSEOとは異なり、AI引用測定はまだ進化中ですが、いくつかのアプローチが信頼性のあるインサイトを提供します。最も簡単な方法は手動サンプリングです:毎月ChatGPT、Claude、Perplexityにターゲット顧客が尋ねる質問をクエリし、引用されているかどうか、どのようなコンテキストで、どのようなセンチメントで引用されているかを文書化します。Google Search Consoleは現在、「ウェブ」検索タイプの下にAIオーバービューデータを含み、インプレッションパターンを監視し、可視性のシフトを検出できます。AmICited.comのようなツールは、GPT、Perplexity、Google AIオーバービュー全体でAIシステムがブランドを参照する方法を具体的に監視し、AI引用パフォーマンスの専用追跡を提供します。
期待される結果は通常、体系的な最適化から90日以内に現れます。基盤作業—sameAsプロパティを持つOrganizationスキーマとキーコンテンツのArticleスキーマの実装—は4-8週間以内に測定可能な引用の改善を示すことができます。クロスプラットフォームプレゼンスとエンティティリンキングによるオーソリティ構築には、完全に複合するまで3-6ヶ月かかります。包括的な構造化データを持つサイトはAIオーバービューで最大30%高い可視性を見ており、適切なエンティティリンキングはクリック率の向上を含むより強いエンゲージメント指標を促進します。ROIは引用を超えて拡大します:構造化データはリッチスニペットを通じて従来の検索可視性も向上させ、CTRを最大35%増加させ、複数のAIプラットフォーム全体での全体的なコンテンツ発見可能性を強化します。
2024年にAnswer.AIによって導入された新興のllms.txt標準は、AIシステムに最も重要なコンテンツへのキュレートされたアクセスを提供するためのシンプルなテキストファイル形式を提案しています。採用はまだ限定的ですが—2025年半ばの時点で、約951のドメインのみがllms.txtファイルを公開しています—仕様はエレガントで、AIシステムが進化するにつれて牽引力を得る可能性があります。ただし、従来のスキーママークアップはAI可視性のための実証済みで広くサポートされているアプローチのままです。より広いトレンドは明確です:AIシステムはますますナレッジグラフ上に構築されており、エンティティとその関係がこれらのシステムを支えるノードとエッジを形成しています。包括的でセマンティックに豊富な構造化データに今投資するブランドは、今日のAIオーバービューやチャットボットだけでなく、出現するすべてのAI搭載ディスカバリープラットフォーム全体で大きな競争優位性を持つことになります。
適切なエンティティマークアップを通じて構築するセマンティックデータレイヤーは、AIがブランドを理解して表現する方法の基盤インフラストラクチャになります。2025年現在、4500万以上のウェブドメインがSchema.org構造化データを実装しています—すべての登録ドメインの約12.4%のみ。そのギャップは、技術的な作業を行う意思のある先進的なブランドにとって大きな機会を表しています。問題は、将来AIシステムが構造化データにより大きく依存するかどうかではありません;それはすでにそうしています。問題は、あなたのコンテンツがその構造化された引用可能なエコシステムの一部になるか、人々が情報を発見する方法をますます仲介するAIシステムに見えないままになるかです。
従来のスキーママークアップは、主に検索エンジンがリッチスニペットを表示し、クリック率を向上させるために設計されました。AIエンティティマークアップは、AIシステムがコンテンツを解析、解釈、引用する方法に特化して最適化されています。従来のマークアップは検索可視性に役立ちますが、AIエンティティマークアップはAI生成回答とサマリーで権威あるソースとして引用されるのに役立ちます。
まず、ホームページに包括的なsameAsプロパティを持つOrganizationスキーマから始め、次に主要なコンテンツページにArticleスキーマを追加します。FAQPageスキーマは次に来るべきです—AI抽出に最も直接的に有用です。その後、ガイドにHowToスキーマを、製品ページにSoftwareApplicationスキーマを追加してください。
基盤作業は4-8週間以内に測定可能な引用の改善を示すことができます。クロスプラットフォームプレゼンスとエンティティリンキングによるオーソリティ構築には、完全に複合するまで3-6ヶ月かかります。ほとんどのブランドは、体系的な最適化から90日以内に測定可能な引用の改善を見ます。
誤って実装されたマークアップのみがパフォーマンスに悪影響を与えます。Googleのガイドラインは明確です:可視コンテンツと一致する関連スキーマタイプを使用し、価格と日付を正確に保ち、ユーザーが見ることができないコンテンツをマークアップしないでください。公開前に常にGoogleのリッチリザルトテストで検証してください。
すべての主要なAIシステムは構造化データから恩恵を受けますが、使用方法は異なる場合があります。ChatGPT、Perplexity、Google AIオーバービューはすべて明確なセマンティック構造を持つコンテンツを好みますが、実装の詳細は異なります。適切なエンティティマークアップは、すべてのAIプラットフォーム全体で可視性を向上させます。
エンティティマークアップは、あいまいなテキストをAIシステムが自信を持って抽出して引用できる検証可能な機械可読の事実に変換します。ナレッジグラフに基づくLLMは、非構造化データに依存するものと比較して300%高い精度を達成します。包括的な構造化データを持つサイトは、AIオーバービューで最大30%高い可視性を見ます。
エンティティマークアップは、コンテンツとGoogleのナレッジグラフやWikidataなどのナレッジグラフとの間のつながりを作成します。これらのつながりにより、AIシステムはエンティティの関係とコンテキストを理解できます。sameAsプロパティを通じて適切なエンティティリンキングを実装することで、より広いナレッジグラフエコシステムにブランドを統合します。
ほとんどのサイトでは、スキーママークアップを優先すべきです—それは実証済みで広くサポートされています。llms.txtはまだAIクローラーによる採用が限られている新興の標準です。大規模なドキュメントを持つ開発者向けの企業であれば、将来の保険としてllms.txtを作成する価値があるかもしれませんが、包括的なスキーマ実装から気をそらさないようにしてください。
ChatGPT、Perplexity、Google AIオーバービュー、その他のAIシステム全体でブランドの言及を追跡しましょう。AIシステムがコンテンツをどのように引用するかを理解し、可視性を最適化してください。
エンティティ最適化がブランドをLLMに認識させる仕組みを解説。ナレッジグラフ最適化、スキーママークアップ、AIでの可視性向上のためのエンティティ戦略をマスターしましょう。...

AIのためのエンティティ最適化とは何か、その仕組みやChatGPT、PerplexityなどのAI検索エンジンでの可視性に不可欠な理由を解説。完全な技術ガイド。...

AIでの可視性に最も重要なスキーマタイプを学びましょう。LLMが構造化データをどのように解釈するか、AIの回答でブランドが引用されるためのスキーママークアップ戦略をご紹介します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.