
AIクローラーにすべてのコンテンツを認識させる方法
ChatGPT、Perplexity、GoogleのAIなどのAIクローラーにコンテンツを認識させる方法を学びましょう。AI検索での可視性を高めるための技術要件、ベストプラクティス、監視戦略を紹介します。...
1 分で読める
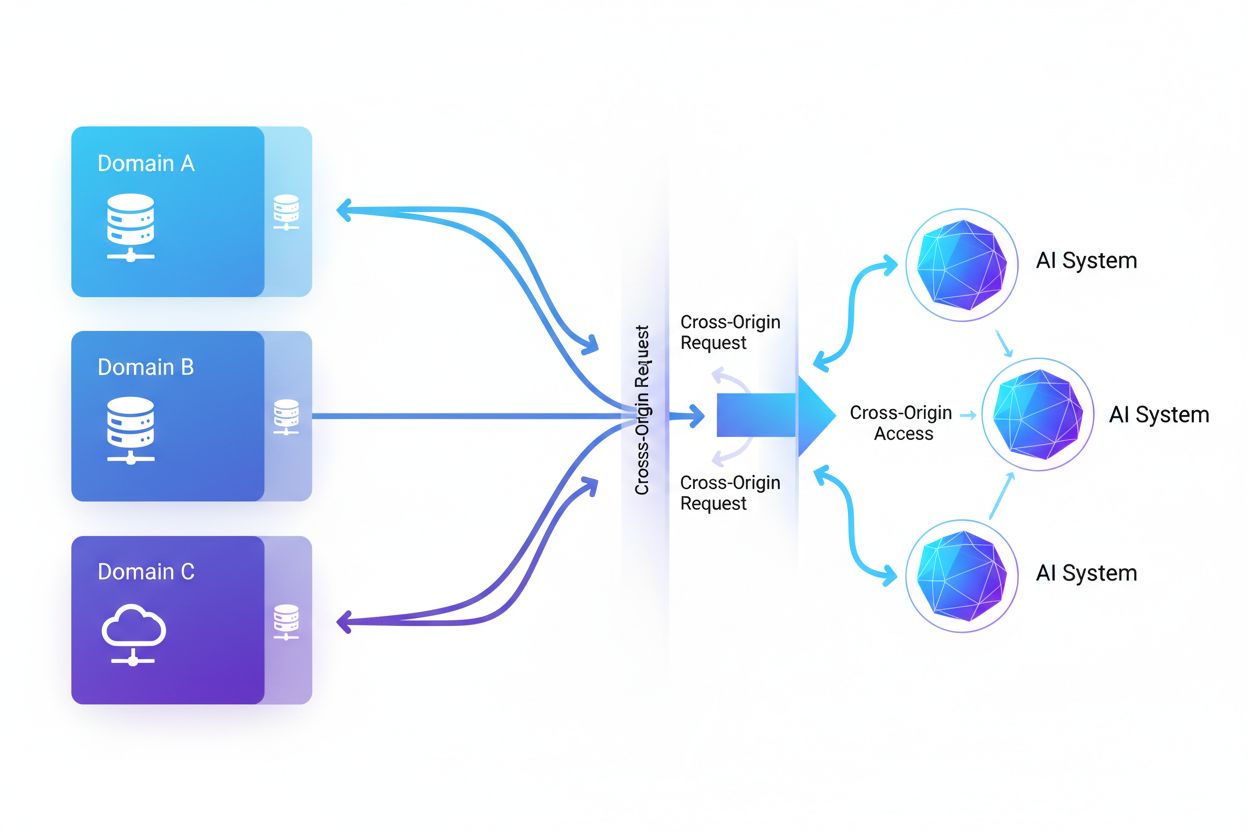
クロスオリジンAIアクセスとは、人工知能システムやウェブクローラーが自らのオリジン(発信元)とは異なるドメインからコンテンツをリクエスト・取得する能力を指し、CORSなどのセキュリティ機構によって管理されます。これは、AI企業が大規模言語モデルの学習用データ収集を拡大する際に、クロスオリジンの制限をどのように回避するかという側面も含みます。この概念を理解することは、コンテンツ制作者やウェブサイト運営者が知的財産を守り、AIシステムによるコンテンツ利用をコントロールするために極めて重要です。クロスオリジンAIの活動状況を可視化することで、正当なAIアクセスと不正なスクレイピングを区別する助けとなります。
クロスオリジンAIアクセスとは、人工知能システムやウェブクローラーが自らのオリジン(発信元)とは異なるドメインからコンテンツをリクエスト・取得する能力を指し、CORSなどのセキュリティ機構によって管理されます。これは、AI企業が大規模言語モデルの学習用データ収集を拡大する際に、クロスオリジンの制限をどのように回避するかという側面も含みます。この概念を理解することは、コンテンツ制作者やウェブサイト運営者が知的財産を守り、AIシステムによるコンテンツ利用をコントロールするために極めて重要です。クロスオリジンAIの活動状況を可視化することで、正当なAIアクセスと不正なスクレイピングを区別する助けとなります。
クロスオリジンAIアクセスとは、人工知能システムやウェブクローラーが、自らのオリジン(発信元)とは異なるドメインからコンテンツをリクエスト・取得する能力を指し、クロスオリジンリソースシェアリング(CORS)などのセキュリティ機構によって管理されています。AI企業が大規模言語モデルや他のAIシステムの訓練用データ収集を拡大する中で、こうしたクロスオリジン制限をどのように回避するかの理解は、コンテンツ制作者やウェブサイト運営者にとって極めて重要となっています。正当なAIによる検索インデックスのためのアクセスと、不正な学習用スクレイピングを区別することが課題であり、クロスオリジンAIの活動を可視化することが、知的財産の保護やコンテンツ利用コントロールの鍵となります。
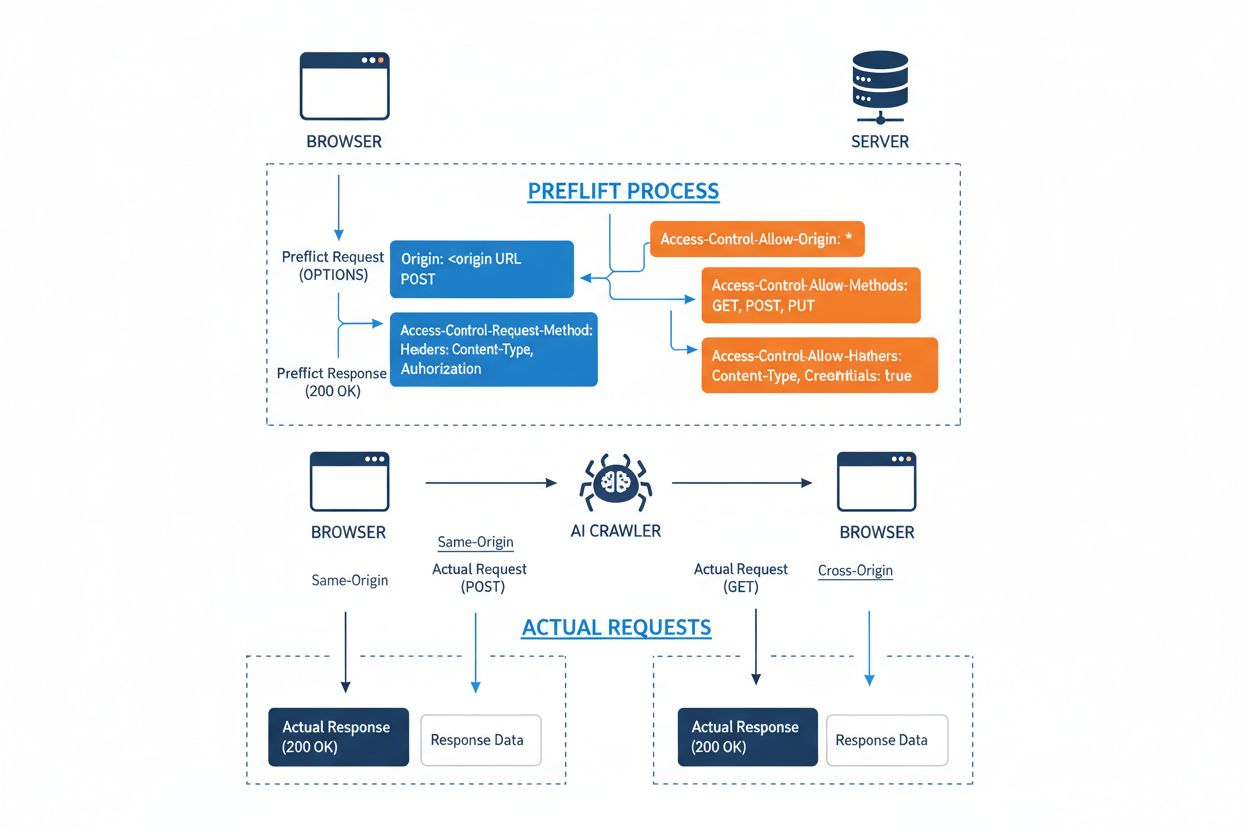
クロスオリジンリソースシェアリング(CORS)は、サーバーがどのオリジン(ドメイン、スキーム、ポート)から自分のリソースにアクセスできるかを指定できる、HTTPヘッダベースのセキュリティ機構です。AIクローラーやその他のクライアントが異なるオリジンからリソースへアクセスしようとすると、ブラウザやクライアントはOPTIONSメソッドによるプリフライトリクエストを発行し、サーバーがそのリクエストを許可するか確認します。サーバー側では、アクセス許可を示すCORSヘッダを返し、許可されたオリジン、利用可能なHTTPメソッド、リクエストヘッダ、Cookieや認証トークンなど資格情報の送信可否等を制御します。
| CORS Header | 目的 |
|---|---|
Access-Control-Allow-Origin | アクセス可能なオリジンを指定(*で全許可、または特定ドメイン) |
Access-Control-Allow-Methods | 許可するHTTPメソッドの一覧(GET, POST, PUT, DELETEなど) |
Access-Control-Allow-Headers | 許可するリクエストヘッダ(Authorization, Content-Typeなど) |
Access-Control-Allow-Credentials | 資格情報(Cookie, authトークン)をリクエストに含めるかの指定 |
Access-Control-Max-Age | プリフライトレスポンスのキャッシュ期間(秒単位) |
Access-Control-Expose-Headers | クライアントがアクセス可能なレスポンスヘッダの一覧 |
AIクローラーは、正しく設定されたCORSヘッダを尊重する場合もありますが、多くの高度なボットはユーザーエージェントの偽装やプロキシネットワークの利用により、こうした制限を回避しようとします。CORSが不正なAIアクセス防御として有効かどうかは、サーバー設定の適切さと、クローラー側が制限を守るかどうかに大きく依存します。これは、AI企業が学習データの獲得競争を激化させる中で、ますます重要なポイントとなっています。
ウェブにアクセスするAIクローラーの勢力図は急速に拡大しており、いくつかの主要プレイヤーがクロスオリジンアクセスの大半を占めています。Cloudflareのネットワークトラフィック分析によると、特に目立つAIクローラーは以下の通りです:
これらのクローラーは月間数十億件ものリクエストを発生させており、BytespiderやGPTBotはインターネットの公開コンテンツの大半にアクセスしています。この過激な活動量により、Reddit、Twitter/X、Stack Overflow、各種報道機関など大手プラットフォームもブロック措置を導入しています。
CORS設定の誤りは、AIクローラーが権限なく機密データへアクセスする重大なセキュリティ脆弱性を生み出します。サーバーがAccess-Control-Allow-Origin: *を不適切に設定すると、悪意あるAIスクレイパーも含めてあらゆるオリジンから本来制限すべきリソースへのアクセスを許可してしまいます。特に危険なのは、Access-Control-Allow-Credentials: trueとワイルドカードオリジンを組み合わせた設定で、これにより攻撃者はセッションクッキーや認証トークンを含むクロスオリジンリクエストを行い、認証済ユーザーのデータを盗み取ることが可能になります。
よくあるCORSの誤設定には、リクエストのOriginヘッダを検証せずにそのままレスポンスのAccess-Control-Allow-Originに反映する動的設定や、ドメイン境界の検証が不十分な許可リスト運用があります。これらはサブドメイン攻撃やプレフィックス操作による悪用が可能です。Originヘッダ自体の検証不足も多くの組織で見落とされており、偽装リクエストに対して脆弱となります。こうした脆弱性による被害はデータ盗難だけでなく、AIモデルの無断学習、競合による情報収集、知的財産権の侵害など多岐にわたります。AmICited.comのようなツールは、これらリスクの監視と定量化を支援します。
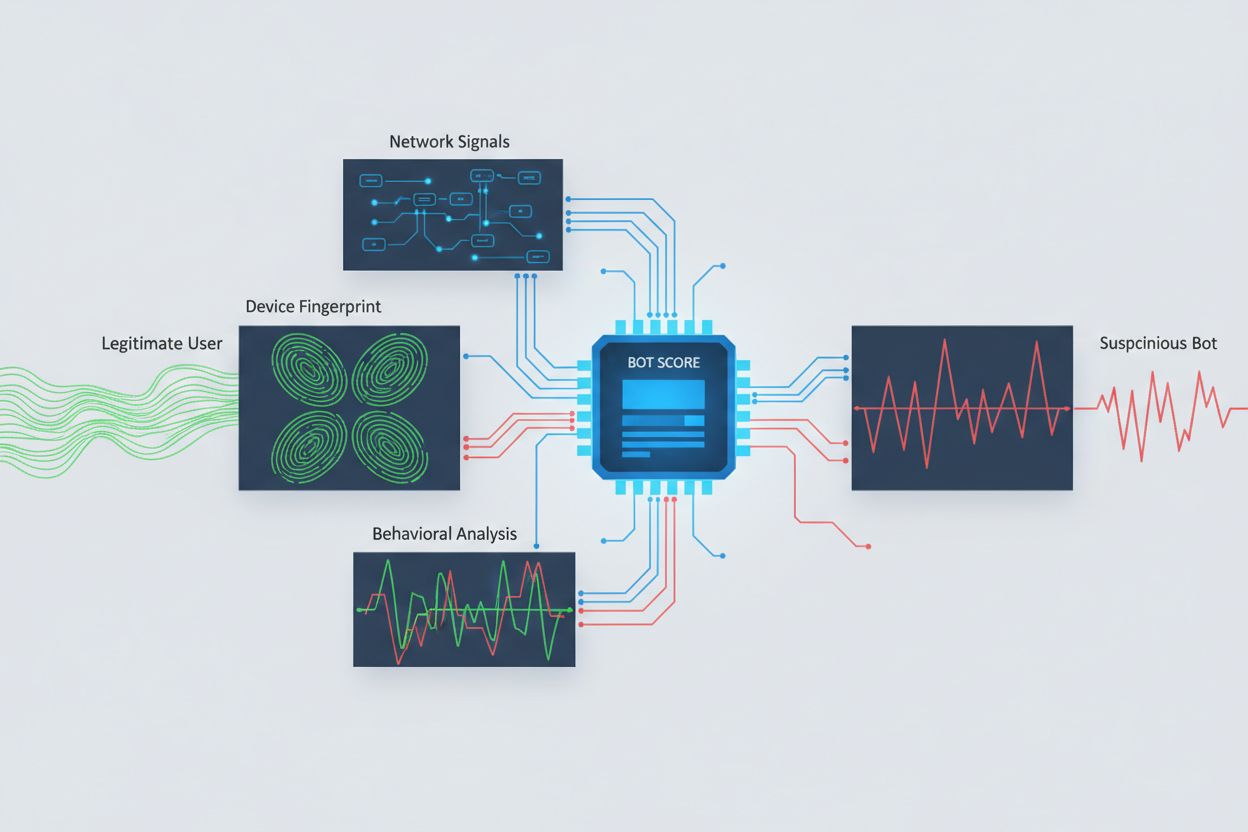
クロスオリジンアクセスを試みるAIクローラーの特定には、単純なユーザーエージェント解析だけでなく様々なシグナルの分析が必要です。多くのAIクローラーは「GPTBot/1.0」や「ClaudeBot/1.0」など特有のユーザーエージェントで自らを識別しますが、高度なクローラーは正規ブラウザを装ってユーザーエージェントを偽装するため、これだけでは検知困難です。行動指紋では、リクエストタイミングやページ遷移の順序、JavaScript実行の有無、人間のブラウジングと異なるインタラクションパターンなどを分析します。
ネットワークシグナル分析では、TLSハンドシェイクのシグネチャやIPレピュテーション、DNS解決パターン、接続特性などを調べることで、ユーザーエージェント偽装時にもボット活動を検出可能です。デバイスフィンガープリンティングは、ブラウザバージョン、画面解像度、インストールフォント、OS情報、JA3 TLSフィンガープリント等、膨大な情報を組み合わせてリクエスト発信元を一意に識別します。これにより、複数セッションが同一デバイス・スクリプトから発生している場合も検知でき、分散型スクレイピングの発見も可能です。各種セキュリティプラットフォームや監視サービスを活用することで、自社コンテンツにアクセスしているAIシステムや、その回避手法の把握が可能となります。
組織はクロスオリジンAIアクセスを制御・遮断するために、複数の補完的な戦略を組み合わせて運用しています。単一の方法では十分な防御効果が得られません:
User-agent: GPTBot に続けて Disallow: /)に対しクロール禁止を通知。良識的なクローラーには有効ですが、意図的なスクレイパーには容易に無視されます最も効果的な防御は、複数の層を組み合わせることです。攻撃者は単一手法の隙をついてくるため、組織はブロック方法の有効性を常時監視し、クローラー側の回避技術進化に応じて対策をアップデートする必要があります。
クロスオリジンAIアクセスを効果的に管理するには、セキュリティと運用ニーズのバランスを保ちながら、多層的かつ包括的な戦略が求められます。まずrobots.txtやユーザーエージェントフィルタリングなどの基本制御から着手し、観測された脅威に応じて高度な検知・遮断手法を段階的に追加していく階層的なアプローチが理想です。どのAIシステムがどの頻度でアクセスし、制限を守っているかを追跡する継続的な監視も不可欠で、これによりアクセス方針の見直しや意思決定が容易になります。
アクセス方針は明確かつ強制力のあるドキュメントとして整備し、不正なスクレイピングを禁止する利用規約や違反時の措置も明記しましょう。CORS設定の定期監査によって、設定ミスや脆弱性を未然に検出でき、AIクローラーのユーザーエージェントやIPリストの最新化で新たな脅威への迅速な対応も可能です。また、AIアクセスの遮断には事業的な影響もあるため、検索インデックスなど有益なAIクローラーと害となるアクセスパターンを区別し、セキュリティ・法務・事業部門が連携して方針を策定することが重要です。
クロスオリジンAIアクセスの監視・制御を支援するため、専門ツールやプラットフォームも登場しています。AmICited.comは、GPT群、Perplexity、Google AI Overviewsなど各種AIプラットフォームにおけるブランドへのAIシステムの言及・アクセス状況を包括的に監視し、どのAIモデルがコンテンツを利用し、AI生成回答にどれだけブランドが登場するかまで可視化します。これにより、クロスオリジンアクセスパターンの追跡や、デジタル資産とAIシステムの相互作用全体を把握できます。
監視以外にも、Cloudflareはワンクリックで既知のAIクローラーをブロックできるボット管理機能を提供し、ネットワーク全体のトラフィックパターンで学習した機械学習モデルにより、ユーザーエージェント偽装にも対応します。AWS WAF(Web Application Firewall)は特定ユーザーエージェントやIPレンジのカスタムブロックルールを、Impervaは行動解析と脅威インテリジェンスを組み合わせた高度なボット検知を、Bright Dataはボットトラフィックの理解とクローラー識別をサポートします。組織規模や技術力、要件に応じて、小規模サイト向けのrobots.txt管理から、機密データを扱う大規模組織向けのエンタープライズ級ボット管理基盤まで選択できます。いずれの選択肢でも、「クロスオリジンAIアクセスの可視化」がデジタル資産防御の基礎であることに変わりはありません。
CORS(クロスオリジンリソースシェアリング)は、どのオリジンがサーバー上のリソースにアクセスできるかを制御するセキュリティ機構です。クロスオリジンAIアクセスは、AIシステムやクローラーがCORSとどのように関わり、異なるドメインからコンテンツをリクエストするかに特化した話題です。CORSが技術的な枠組みであるのに対し、クロスオリジンAIアクセスは、CORSの枠組みの中でAIクローラーの挙動を管理する実際的な課題、たとえば不正なAIアクセスの検知やブロックなどを指します。
多くの良識あるAIクローラーは「GPTBot/1.0」や「ClaudeBot/1.0」など、目的を明示した特定のユーザーエージェントを使って自らを識別します。しかし、高度なクローラーの多くは、ChromeやSafariなどの正規ブラウザを装ってユーザーエージェントを偽装し、ユーザーエージェントによるブロックを回避します。そのため、行動指紋やネットワークシグナル解析など、宣言された識別に依存しない高度な検知手法が必要となります。
robots.txtは、クローラーにアクセス制限の遵守を求める任意の仕組みであり、GPTBotのような良識あるAIクローラーは一般にこの指示に従います。しかし、robots.txtには強制力がないため、意図的なスクレイパーは無視することができます。実際、多くのAI企業がrobots.txtの制限を回避していることが判明しており、robots.txtは必要ですが不十分な防御策であり、ユーザーエージェントフィルタリングやレート制限、デバイスフィンガープリンティングなどの技術的手段と組み合わせるべきです。
CORS設定の誤りによって、不正なAIクローラーが機密データにアクセスしたり、認証付きリクエストでユーザー情報を盗んだり、許可なく独自コンテンツをスクレイピングしてAIモデル学習に利用するリスクがあります。特に危険なのは、ワイルドカード(*)オリジン設定と認証情報許可(credentials)を組み合わせた場合で、あらゆるオリジンから認証付きリクエストによるアクセスが可能になります。これにより知的財産の盗用や競合による情報収集、コンテンツライセンス違反などが発生する恐れがあります。
ユーザーエージェント文字列だけでなく、複数のシグナルを分析する必要があります。既知のAIクローラーのユーザーエージェントをサーバーログで確認したり、行動指紋で人間とは異なるアクセスパターンを特定したり、TLSハンドシェイクやDNSパターンなどネットワークシグナルを分析したり、デバイスフィンガープリンティングで分散型スクレイピングを発見したりします。AmICited.comのようなツールは、AIシステムがどのようにブランドに言及しているか包括的に監視でき、Cloudflareのようなプラットフォームは、ユーザーエージェント偽装にも対応した機械学習型ボット検知を提供します。
単一の手法では完全な防御はできないため、多層的なアプローチが最も効果的です。まずrobots.txtやユーザーエージェントフィルタリングで基本的な防御を行い、レート制限で影響を抑え、デバイスフィンガープリンティングで高度なボットも検知し、機密コンテンツには認証やペイウォールを導入します。多くの組織は、複数の手法を組み合わせて効果を監視し、クローラーの回避技術に応じて適宜対策を更新しています。
いいえ。OpenAIやAnthropicのような大手企業はrobots.txtやCORS制限を尊重していると主張していますが、多くのAIクローラーがこれらの制限を回避していることが調査で明らかになっています。Perplexity AIはユーザーエージェント偽装でブロックを回避した例があり、OpenAIやAnthropicのクローラーも明示的なrobots.txtでアクセス禁止されているにもかかわらず、コンテンツにアクセスしていた事例があります。このため、技術的なブロック手段や法的措置がますます必要になっています。
AmICited.comは、GPT群、Perplexity、Google AI Overviews、その他のAIプラットフォームにおけるブランドへのAIシステムの言及・アクセス状況を包括的に監視します。どのAIモデルがコンテンツを利用しているか、AI生成回答にブランドがどれだけ登場しているかを把握でき、デジタル資産を取り巻くAIシステムの全体像を可視化します。これにより、AIアクセスの規模を理解し、コンテンツ保護戦略に関する判断材料を得られます。
GPT群、Perplexity、Google AI Overviews、その他各種プラットフォームにおけるAIシステムが、あなたのブランドにどのようにアクセスしているかを完全に可視化。クロスオリジンAIアクセスパターンを追跡し、あなたのコンテンツがAIの学習や推論にどう使われているか把握しましょう。
ChatGPT、Perplexity、GoogleのAIなどのAIクローラーにコンテンツを認識させる方法を学びましょう。AI検索での可視性を高めるための技術要件、ベストプラクティス、監視戦略を紹介します。...
ChatGPT・Claude・PerplexityなどのAIクローラーがあなたのウェブサイトのコンテンツにアクセスできるかをテストする方法を学びます。AIクロール監視のためのテスト手法・ツール・ベストプラクティスを紹介します。...
ChatGPT、Claude、PerplexityなどのAIクローラーによってあなたのウェブサイトが発見可能になるように、AIアクセシビリティ監査を実施する方法を学びましょう。robots.txt、サイトマップ、コンテンツ抽出をカバーした技術ガイド。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.