
Správa AI crawlerů
Zjistěte, jak spravovat přístup AI crawlerů k obsahu vašeho webu. Poznejte rozdíl mezi tréninkovými a vyhledávacími crawlery, implementujte ovládání přes robots...
6 min čtení
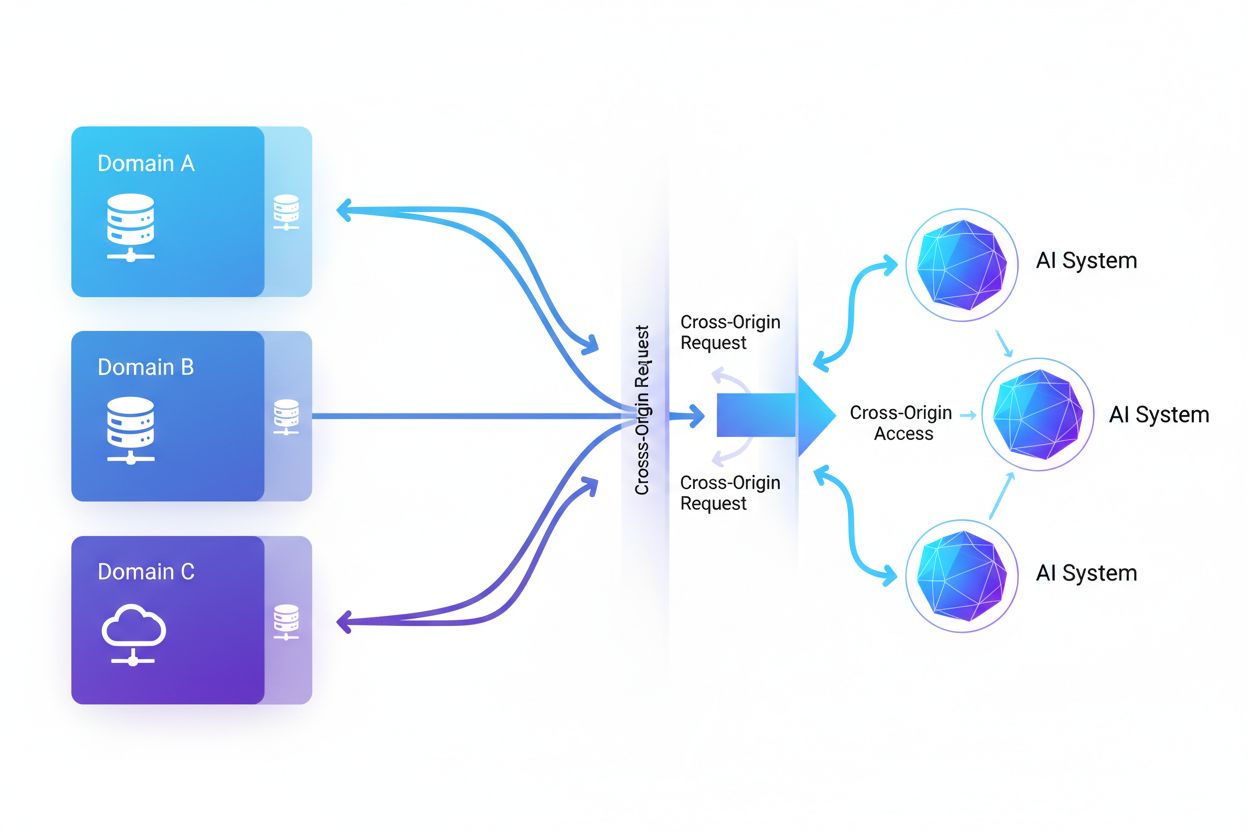
Cross-Origin AI Access označuje schopnost systémů umělé inteligence a webových crawlerů vyžadovat a získávat obsah z domén odlišných od jejich původu, řízenou bezpečnostními mechanismy jako je CORS. Zahrnuje způsoby, jak firmy zabývající se AI škálují sběr dat pro trénink velkých jazykových modelů při navigaci omezeními napříč doménami. Porozumění tomuto pojmu je zásadní pro tvůrce obsahu a majitele webů, aby mohli chránit duševní vlastnictví a udrželi kontrolu nad tím, jak je jejich obsah využíván AI systémy. Přehled o aktivitách AI napříč doménami pomáhá rozlišit legitimní přístup AI od neoprávněného scrapingu.
Cross-Origin AI Access označuje schopnost systémů umělé inteligence a webových crawlerů vyžadovat a získávat obsah z domén odlišných od jejich původu, řízenou bezpečnostními mechanismy jako je CORS. Zahrnuje způsoby, jak firmy zabývající se AI škálují sběr dat pro trénink velkých jazykových modelů při navigaci omezeními napříč doménami. Porozumění tomuto pojmu je zásadní pro tvůrce obsahu a majitele webů, aby mohli chránit duševní vlastnictví a udrželi kontrolu nad tím, jak je jejich obsah využíván AI systémy. Přehled o aktivitách AI napříč doménami pomáhá rozlišit legitimní přístup AI od neoprávněného scrapingu.
Cross-Origin AI Access označuje schopnost systémů umělé inteligence a webových crawlerů vyžadovat a získávat obsah z domén odlišných od jejich původu, řízenou bezpečnostními mechanismy jako je Cross-Origin Resource Sharing (CORS). Jak firmy zabývající se AI škálují své snahy o sběr dat pro trénink velkých jazykových modelů a dalších AI systémů, stává se pochopení způsobů, jak tyto systémy zvládají omezení napříč doménami, zásadní pro tvůrce obsahu a majitele webů. Výzvou je odlišit legitimní AI přístup pro indexování vyhledávačů od neautorizovaného scrapingu pro trénink modelů, což činí přehled o aktivitách AI napříč doménami klíčovým pro ochranu duševního vlastnictví a udržení kontroly nad tím, jak je obsah využíván.
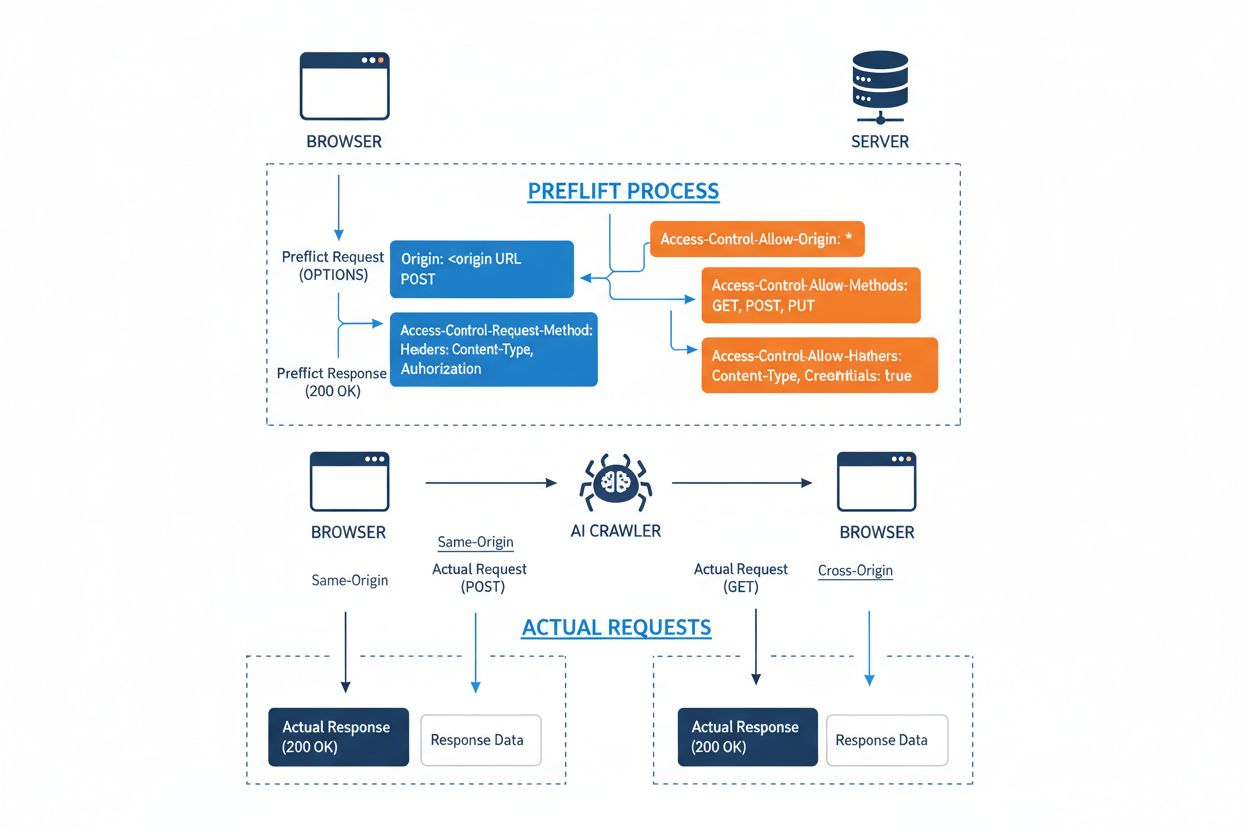
Cross-Origin Resource Sharing (CORS) je bezpečnostní mechanismus založený na HTTP hlavičkách, který umožňuje serverům určit, které původy (domény, schémata nebo porty) mohou přistupovat k jejich zdrojům. Když se AI crawler nebo jiný klient pokusí přistoupit ke zdroji z jiného původu, prohlížeč nebo klient zahájí tzv. preflight požadavek metodou OPTIONS, aby ověřil, zda server skutečný požadavek povolí. Server odpovídá specifickými CORS hlavičkami, které určují přístupová oprávnění, včetně povolených původů, povolených HTTP metod, použitelných hlaviček a toho, zda mohou být spolu s požadavkem posílány přihlašovací údaje jako cookies nebo autentizační tokeny.
| CORS hlavička | Účel |
|---|---|
Access-Control-Allow-Origin | Určuje, které původy mohou ke zdroji přistupovat (* pro všechny, nebo konkrétní domény) |
Access-Control-Allow-Methods | Vyjmenovává povolené HTTP metody (GET, POST, PUT, DELETE atd.) |
Access-Control-Allow-Headers | Definuje, které požadované hlavičky jsou povoleny (Authorization, Content-Type atd.) |
Access-Control-Allow-Credentials | Určuje, zda mohou být s požadavky zahrnuty přihlašovací údaje (cookies, auth tokeny) |
Access-Control-Max-Age | Udává, jak dlouho lze preflight odpovědi cachovat (v sekundách) |
Access-Control-Expose-Headers | Vyjmenovává odpovědní hlavičky, ke kterým má klient přístup |
AI crawlery interagují s CORS tím, že tyto hlavičky respektují, pokud jsou správně nastavené, i když mnoho sofistikovaných botů se snaží tato omezení obejít podvržením user agentů nebo použitím proxy sítí. Účinnost CORS jako obrany proti neautorizovanému AI přístupu zcela závisí na správné konfiguraci serveru a ochotě crawleru omezení dodržovat — což je zásadní rozdíl, který je stále důležitější, jak AI firmy soupeří o tréninková data.
Počet AI crawlerů přistupujících k webu dramaticky vzrostl a několik hlavních hráčů dominuje vzorům přístupů napříč doménami. Podle analýzy síťového provozu Cloudflare patří mezi nejrozšířenější AI crawlery:
Tyto crawlery generují miliardy požadavků měsíčně, přičemž někteří jako Bytespider a GPTBot přistupují k většině veřejně dostupného obsahu internetu. Samotný objem a agresivita této aktivity přiměly hlavní platformy jako Reddit, Twitter/X, Stack Overflow a řadu zpravodajských organizací k zavedení blokovacích opatření.
Chybně nastavené zásady CORS vytvářejí významné bezpečnostní zranitelnosti, které mohou AI crawlery zneužít k neautorizovanému přístupu k citlivým datům. Když servery nastaví Access-Control-Allow-Origin: * bez správné validace, neúmyslně umožní jakémukoliv původu — včetně škodlivých AI scraperů — přístup ke zdrojům, které by měly být omezeny. Obzvlášť nebezpečná je konfigurace, kdy je Access-Control-Allow-Credentials: true kombinováno s povolením všech původů, což útočníkům umožňuje krást data ověřených uživatelů skrze cross-origin požadavky zahrnující session cookies nebo autentizační tokeny.
Běžné chyby v nastavení CORS zahrnují dynamické zrcadlení hlavičky Origin přímo do odpovědi Access-Control-Allow-Origin bez validace, čímž je fakticky povolen přístup z jakéhokoliv původu. Příliš benevolentní seznamy povolených domén, které řádně neověřují doménové hranice, mohou být zneužity útoky přes subdomény nebo manipulací s prefixy. Mnoho organizací navíc neprovádí správnou validaci samotné hlavičky Origin, čímž se vystavují podvrženým požadavkům. Důsledky těchto zranitelností přesahují krádež dat až k neautorizovanému tréninku AI modelů na proprietárním obsahu, získávání konkurenčních informací a porušování práv duševního vlastnictví — rizika, která pomáhají organizacím monitorovat a kvantifikovat nástroje jako AmICited.com.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Identifikace AI crawlerů snažících se o cross-origin přístup vyžaduje analýzu více signálů než jen prostých user agent stringů, které lze snadno podvrhnout. Analýza user agentů zůstává základní detekční metodou, protože mnoho AI crawlerů se identifikuje specifickými user agenty jako “GPTBot/1.0” nebo “ClaudeBot/1.0”, avšak sofistikované crawlery záměrně maskují svou identitu tím, že se vydávají za běžné prohlížeče. Behaviorální fingerprinting analyzuje, jak jsou požadavky prováděny — zkoumá vzory jako časování požadavků, posloupnost prohlížených stránek, přítomnost či nepřítomnost spouštění JavaScriptu a vzorce interakce, které se zásadně liší od lidského chování.
Analýza síťových signálů poskytuje hlubší detekci prozkoumáním podpisů TLS handshake, reputace IP adres, vzorů DNS řešení a charakteristik spojení, které odhalují botí aktivitu i při podvržených user agentech. Fingerprinting zařízení agreguje desítky signálů včetně verze prohlížeče, rozlišení obrazovky, nainstalovaných písem, detailů operačního systému a JA3 TLS fingerprintů pro vytvoření unikátního identifikátoru každého zdroje požadavku. Pokročilé detekční systémy dokážou rozpoznat, kdy více relací pochází ze stejného zařízení nebo skriptu, a odhalit distribuované scrapingové pokusy rozložené přes mnoho IP adres kvůli obejití rate limiting. Organizace mohou tyto detekční metody využít prostřednictvím bezpečnostních platforem a monitorovacích služeb pro získání přehledu o tom, které AI systémy přistupují k jejich obsahu a jak se snaží omezení obcházet.
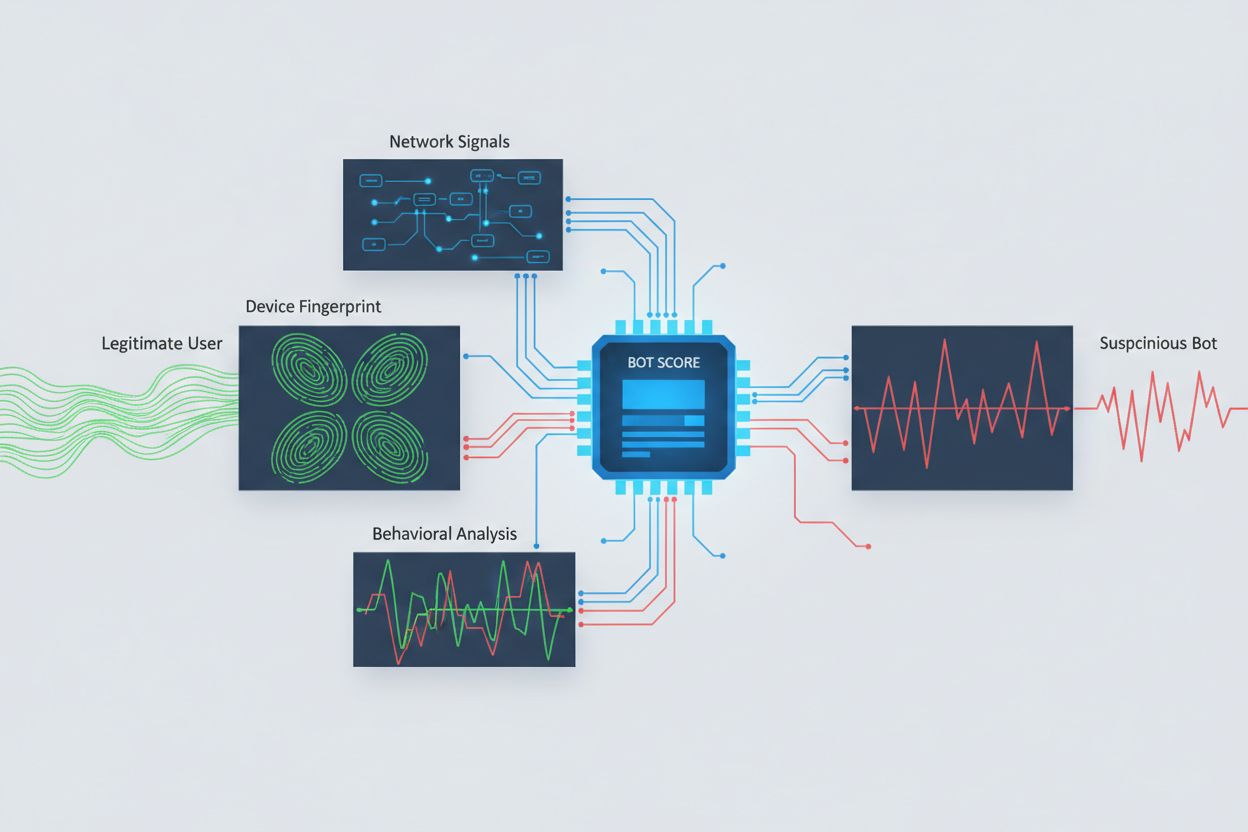
Organizace využívají více doplňkových strategií pro blokování nebo kontrolu cross-origin AI přístupu, přičemž si uvědomují, že žádná jednotlivá metoda neposkytuje úplnou ochranu:
User-agent: GPTBot následováno Disallow: /) poskytuje zdvořilý, ale dobrovolný mechanismus; efektivní pro korektní crawlery, snadno ignorováno odhodlanými scraperyNejúčinnější obrana kombinuje více vrstev, protože odhodlaní útočníci zneužijí slabiny každého jednovrstvého přístupu. Organizace musí průběžně monitorovat, které blokovací metody fungují, a přizpůsobovat se, jak crawlery vylepšují své metody obcházení.
Efektivní řízení cross-origin AI přístupu vyžaduje komplexní, vrstvený přístup, který vyvažuje bezpečnost a provozní potřeby. Organizace by měly implementovat stupňovanou strategii začínající základními kontrolami jako robots.txt a filtrováním user agentů, a postupně přidávat sofistikovanější detekční a blokovací mechanismy na základě sledovaných hrozeb. Průběžné monitorování je nezbytné — sledování, které AI systémy přistupují k vašemu obsahu, jak často provádějí požadavky a zda respektují vaše omezení, poskytuje potřebný přehled pro informovaná rozhodnutí o zásadách přístupu.
Dokumentace zásad přístupu by měla být jasná a vymahatelná, s explicitními podmínkami služby zakazujícími neautorizovaný scraping a stanovujícími důsledky jejich porušení. Pravidelné audity CORS konfigurací pomáhají odhalit chyby dříve, než budou zneužity, zatímco evidence známých AI user agentů a IP rozsahů umožňuje rychlou reakci na nové hrozby. Organizace by měly také zvažovat obchodní dopady blokování AI přístupu — některé AI crawlery přinášejí hodnotu díky indexování vyhledávačů či legitimním partnerstvím, takže zásady by měly rozlišovat mezi prospěšnými a škodlivými vzory přístupu. Implementace těchto praktik vyžaduje koordinaci mezi bezpečnostními, právními a obchodními týmy, aby zásady odpovídaly cílům organizace a regulatorním požadavkům.
Vznikly specializované nástroje a platformy, které organizacím pomáhají s přesnější kontrolou a větším přehledem nad cross-origin AI přístupem. AmICited.com poskytuje komplexní monitoring toho, jak AI systémy odkazují a přistupují ke značce napříč GPTs, Perplexity, Google AI Overviews a dalšími AI platformami, a nabízí přehled o tom, které AI modely využívají váš obsah a jak často se vaše značka objevuje v AI generovaných odpovědích. Tato monitorovací schopnost zahrnuje sledování vzorů cross-origin přístupů a pochopení širšího ekosystému AI systémů interagujících s vašimi digitálními aktivy.
Kromě monitorování nabízí Cloudflare funkce pro správu botů s možností jedním kliknutím blokovat známé AI crawlery, využívající strojové učení na základě síťových provozních vzorů k identifikaci botů i při podvržených user agentech. AWS WAF (Web Application Firewall) umožňuje nastavovat vlastní pravidla pro blokování konkrétních user agentů a IP rozsahů, zatímco Imperva nabízí pokročilou detekci botů kombinující behaviorální analýzu s hrozbovou inteligencí. Bright Data se specializuje na analýzu vzorů botího provozu a pomáhá organizacím rozlišit různé typy crawlerů. Výběr nástrojů závisí na velikosti organizace, technické vyspělosti a specifických potřebách — od jednoduché správy robots.txt pro malé weby až po enterprise řešení pro správu botů u velkých organizací pracujících s citlivými daty. Bez ohledu na výběr platí základní princip: přehled o cross-origin AI přístupu je základem efektivní kontroly a ochrany digitálních aktiv.
Získejte kompletní přehled o tom, které AI systémy přistupují k vaší značce napříč GPTs, Perplexity, Google AI Overviews a dalšími platformami. Sledujte vzory AI přístupu napříč doménami a zjistěte, jak je váš obsah využíván při tréninku a inferenci AI.
Zjistěte, jak spravovat přístup AI crawlerů k obsahu vašeho webu. Poznejte rozdíl mezi tréninkovými a vyhledávacími crawlery, implementujte ovládání přes robots...

Zjistěte, jak Cloudflare AI Crawl Control založený na hraně umožňuje sledovat, řídit a monetizovat přístup AI crawlerů k vašemu obsahu pomocí detailních politik...

Zjistěte, jak AI systémy přistupují k obsahu za paywallem a uzamčenému obsahu, jaké techniky používají a jak chránit svůj obsah a zároveň udržet jeho viditelnos...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.