AI 可访问性审查
了解如何进行 AI 可访问性审查,确保您的网站可被 ChatGPT、Claude 和 Perplexity 等 AI 爬虫发现。技术指南涵盖 robots.txt、站点地图和内容提取。...
3 分钟阅读
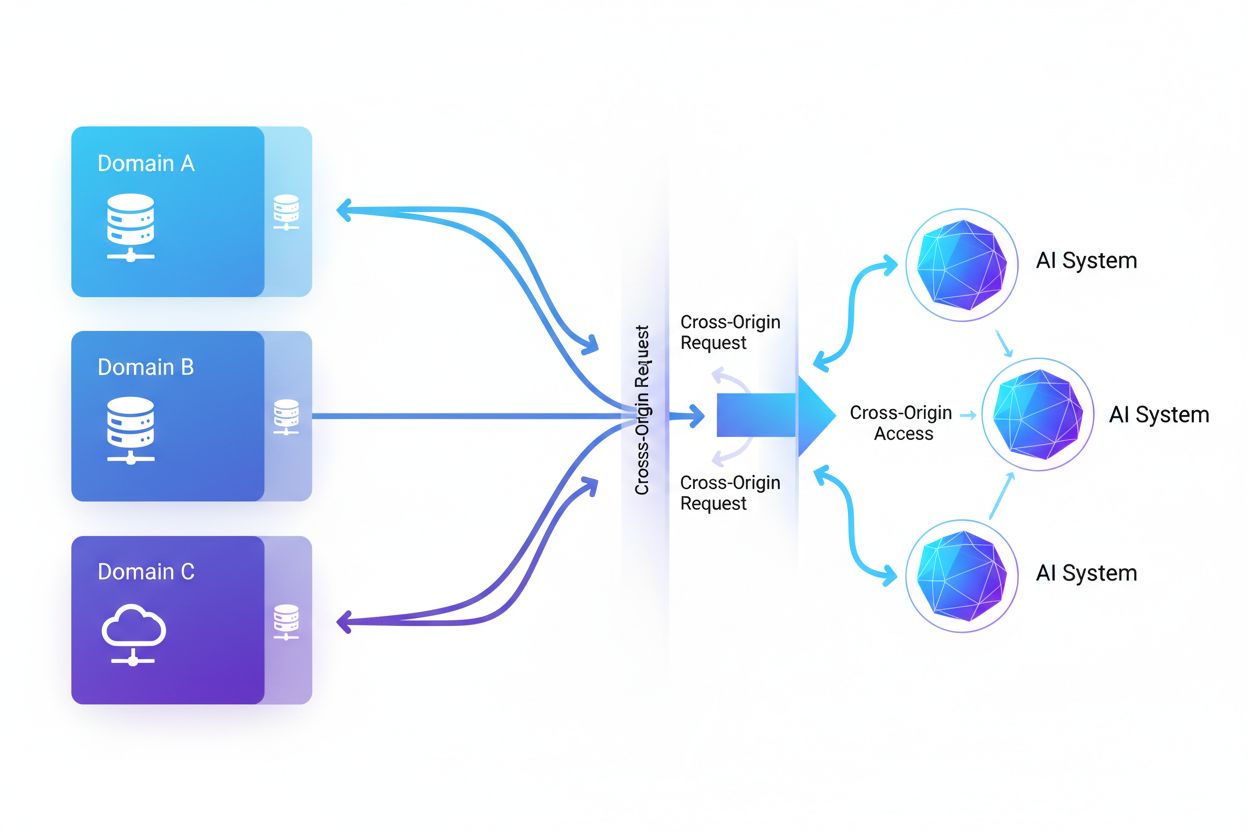
跨域 AI 访问是指人工智能系统和网络爬虫在安全机制(如 CORS)管理下,能够向非本域的站点请求和获取内容的能力。该概念涵盖了 AI 公司在跨越域限制的情况下,如何大规模收集数据用于训练大型语言模型。内容创作者和网站所有者理解这一概念,对于保护知识产权和控制内容被 AI 系统使用方式至关重要。对跨域 AI 活动的可见性有助于区分合法的 AI 访问和未经授权的抓取。
跨域 AI 访问是指人工智能系统和网络爬虫在安全机制(如 CORS)管理下,能够向非本域的站点请求和获取内容的能力。该概念涵盖了 AI 公司在跨越域限制的情况下,如何大规模收集数据用于训练大型语言模型。内容创作者和网站所有者理解这一概念,对于保护知识产权和控制内容被 AI 系统使用方式至关重要。对跨域 AI 活动的可见性有助于区分合法的 AI 访问和未经授权的抓取。
跨域 AI 访问是指人工智能系统和网络爬虫,在跨域资源共享(CORS)等安全机制管理下,能够向非本域的站点请求和获取内容。随着 AI 公司为训练大型语言模型等系统而不断扩大数据采集规模,了解这些系统如何应对跨域限制已成为内容创作者和网站所有者的关键。难点在于区分用于搜索索引的合法 AI 访问与为模型训练而进行的未经授权抓取,因此实现对跨域 AI 活动的可见性对于保护知识产权和控制内容用途至关重要。
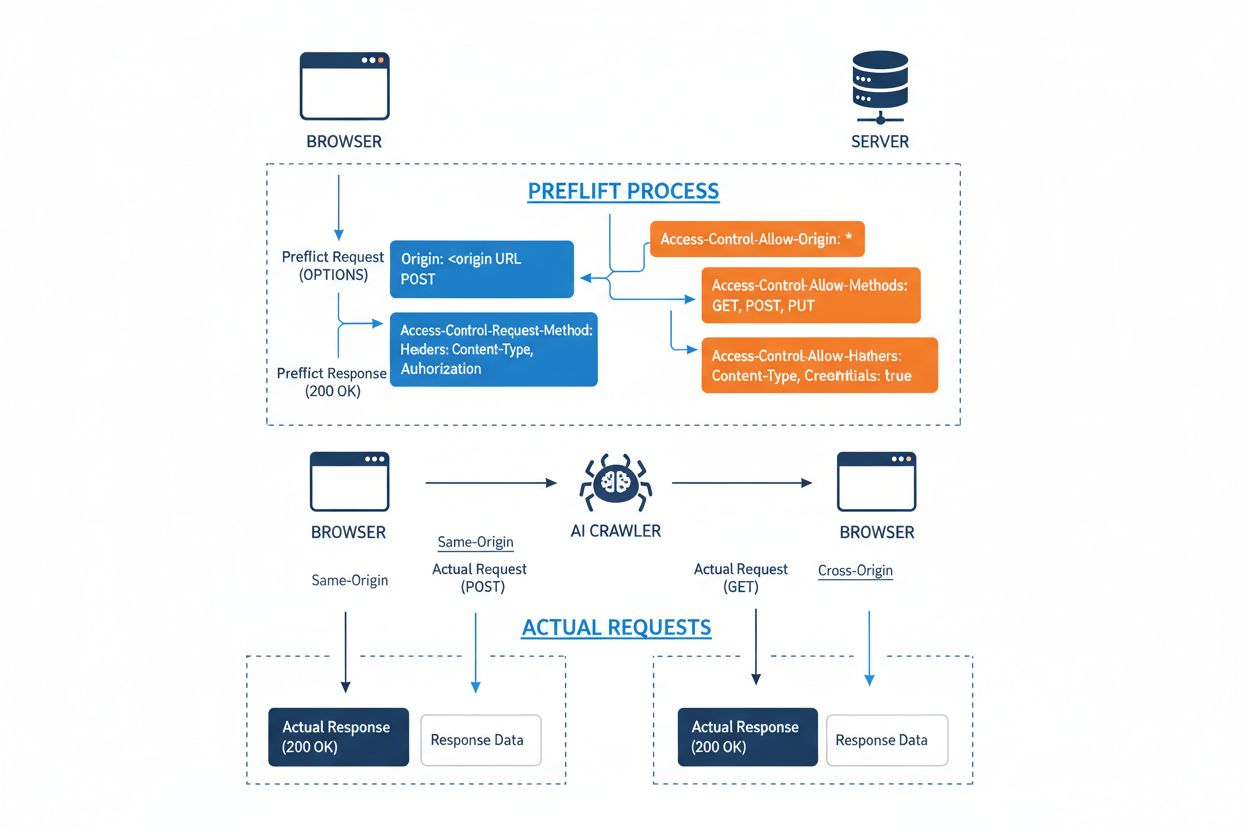
跨域资源共享(CORS)是一种基于 HTTP 头的安全机制,允许服务器指定哪些来源(域、协议或端口)可以访问其资源。当 AI 爬虫或客户端尝试从不同来源访问资源时,浏览器或客户端会用 OPTIONS 方法发起预检请求,以确认服务器是否允许实际请求。服务器通过特定的 CORS 头信息响应,规定了访问权限,包括允许的来源、HTTP 方法、可包含的请求头,以及请求是否可以携带如 cookie 或认证令牌等凭证。
| CORS Header | 用途 |
|---|---|
Access-Control-Allow-Origin | 指定哪些来源可访问资源(* 代表全部或指定域名) |
Access-Control-Allow-Methods | 列出允许的 HTTP 方法(GET、POST、PUT、DELETE 等) |
Access-Control-Allow-Headers | 定义允许的请求头(Authorization、Content-Type 等) |
Access-Control-Allow-Credentials | 决定请求是否可携带凭证(cookie、身份令牌) |
Access-Control-Max-Age | 指定预检响应可缓存多长时间(秒) |
Access-Control-Expose-Headers | 列出可供客户端访问的响应头 |
AI 爬虫若配置得当会遵守这些 CORS 头信息,但许多高级机器人会通过伪造 user agent 或使用代理网络来绕过限制。CORS 能否有效防止未经授权的 AI 访问,完全取决于服务器配置是否正确,以及爬虫是否愿意遵守限制——随着 AI 公司对训练数据的争夺,这一区别变得尤为重要。
AI 爬虫跨域访问网络的格局已大幅扩展,几大主流参与者主导了跨域访问模式。根据 Cloudflare 对网络流量的分析,最常见的 AI 爬虫包括:
这些爬虫每月产生数十亿次请求,其中如 Bytespider 和 GPTBot 已访问了互联网上大部分公开内容。如此庞大且激进的爬取行为促使 Reddit、Twitter/X、Stack Overflow 及众多新闻机构等主要平台实施了封锁措施。
CORS 策略配置不当可导致 AI 爬虫无需授权便能访问敏感数据。当服务器将 Access-Control-Allow-Origin: * 设置为允许全部来源且缺乏有效校验时,任何来源(包括恶意 AI 爬虫)都能访问原本应受限的资源。尤其危险的是 Access-Control-Allow-Credentials: true 与通配符来源同时设置,攻击者可借此通过跨域请求窃取带有会话 cookie 或认证令牌的认证用户数据。
常见的 CORS 配置错误还包括:将 Origin 头直接反射到 Access-Control-Allow-Origin 响应中而不做校验,形同无条件开放资源;过于宽松的白名单未正确校验域边界,易被子域名攻击或前缀混淆利用。此外,许多组织未对 Origin 头进行有效校验,易遭伪造请求攻击。这些漏洞的后果包括数据被盗、专有内容被用于未经授权的 AI 训练、竞争情报收集乃至知识产权侵犯——如 AmICited.com 等工具可帮助组织监控和量化这些风险。
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
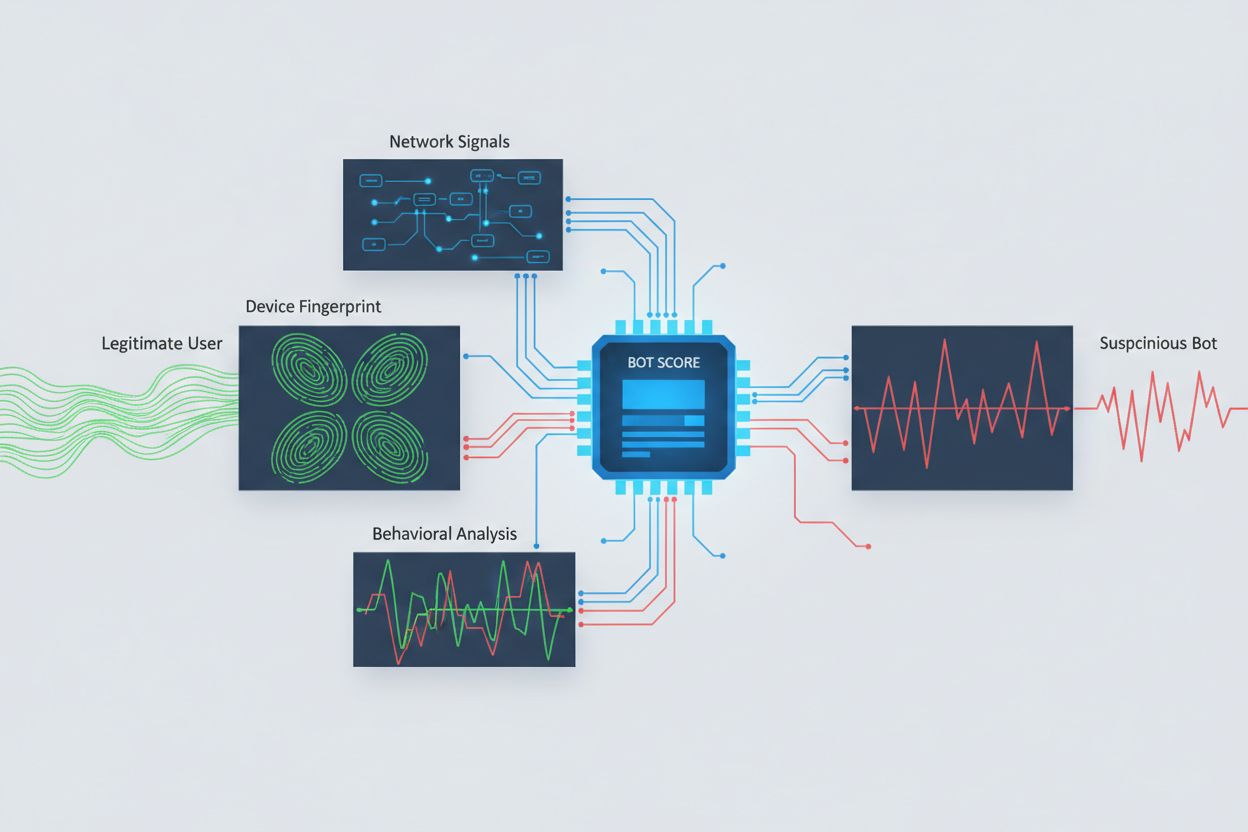
识别试图跨域访问的 AI 爬虫需分析多重信号,而不仅仅依赖可被轻易伪造的 user agent。user agent 分析仍是第一道检测手段,许多 AI 爬虫通过如 “GPTBot/1.0” 或 “ClaudeBot/1.0” 等特定字符串自报身份,但高级爬虫会刻意冒充主流浏览器。行为指纹则通过分析请求时序、页面访问序列、是否执行 JavaScript 及与人类浏览行为本质不同的交互模式进行识别。
网络信号分析可进一步通过 TLS 握手签名、IP 信誉、DNS 解析及连接特征发现机器人活动,即使其 user agent 被伪装。设备指纹则整合浏览器版本、屏幕分辨率、已安装字体、操作系统详情和 JA3 TLS 指纹等数十项信号,为每个请求源生成唯一标识。高级检测系统还能识别多个会话是否来自同一设备或脚本,从而捕捉到试图通过多 IP 分布式抓取、规避速率限制的行为。组织可通过安全平台和监控服务应用这些检测方法,洞察 AI 系统对内容的访问情况及其规避策略。
组织通常采用多种互补策略来阻断或控制跨域 AI 访问,认识到没有单一方法能提供完全防护:
User-agent: GPTBot 后接 Disallow: /),对规范爬虫有效,但易被恶意爬虫无视最有效的防御策略是多层组合,因为有决心的攻击者会利用任何单点防线的弱点。组织需持续监控各类封锁手段的效果,并随爬虫规避技术演化及时调整策略。
高效管理跨域 AI 访问需采取全面、分层的方法,兼顾安全与业务需求。建议从 robots.txt 和 user agent 过滤等基础控制措施做起,逐步根据威胁情况引入更为复杂的检测与阻断机制。持续监控至关重要——追踪哪些 AI 系统在访问您的内容、访问频率及其是否遵守限制,为制定访问策略提供可见性和决策依据。
访问政策应有清晰、可执行的文档支持,服务条款中应明确禁止未经授权的抓取,并规定违规后果。定期审查 CORS 配置,及时发现并修正配置问题,同时维护 AI 爬虫的 user agent 和 IP 库,便于快速响应新威胁。还应权衡 AI 访问的商业影响——部分 AI 爬虫通过搜索索引或合法合作关系为网站带来价值,因此政策应区分有益和有害访问。实施上述措施需安全、法务与业务团队协作,确保策略契合组织目标及合规要求。
各类专业工具和平台已涌现,助力组织更精准、可见地监控和控制跨域 AI 访问。AmICited.com 可全面监控 AI 系统在 GPTs、Perplexity、Google AI Overviews 等平台上对您的品牌的引用和访问,帮助洞察哪些 AI 模型在使用您的内容及品牌在 AI 生成内容中的出现频率,还可追踪跨域访问模式,了解与数字资产互动的 AI 生态。
除监控外,Cloudflare 提供一键封锁已知 AI 爬虫的机器人管理功能,利用机器学习模型分析全网流量,即便爬虫伪装 user agent 也能识别。AWS WAF(Web 应用防火墙)允许自定义规则拦截特定 user agent 和 IP,Imperva 则结合行为分析和威胁情报提供高级机器人检测。Bright Data 专注于分析机器人流量模式,帮助区分不同类型爬虫。工具选择取决于组织规模、技术能力和需求——从小型网站的 robots.txt 管理,到大型企业的数据防护级机器人管理平台。不论选择何种工具,实现跨域 AI 访问的可见性始终是有效控制与保护数字资产的基础。
全面掌控哪些 AI 系统正在通过 GPTs、Perplexity、Google AI Overviews 及其他平台访问您的品牌。追踪跨域 AI 访问模式,了解您的内容如何被用于 AI 训练与推理。
了解如何进行 AI 可访问性审查,确保您的网站可被 ChatGPT、Claude 和 Perplexity 等 AI 爬虫发现。技术指南涵盖 robots.txt、站点地图和内容提取。...

了解 Cloudflare 基于边缘的 AI 爬虫控制如何通过细粒度策略和实时分析,帮助您监控、控制并变现 AI 爬虫对内容的访问。

了解如何审计AI爬虫对您网站的访问。发现哪些机器人可以看到您的内容,并修复阻止AI在ChatGPT、Perplexity及其他AI搜索引擎中可见性的障碍。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.