AI検索エンジンの仕組み:アーキテクチャ、検索、生成
ChatGPT、Perplexity、Google AI OverviewsなどのAI検索エンジンがどのように機能するかを学びましょう。LLM、RAG、セマンティックサーチ、リアルタイム検索メカニズムを解説します。...
1 分で読める
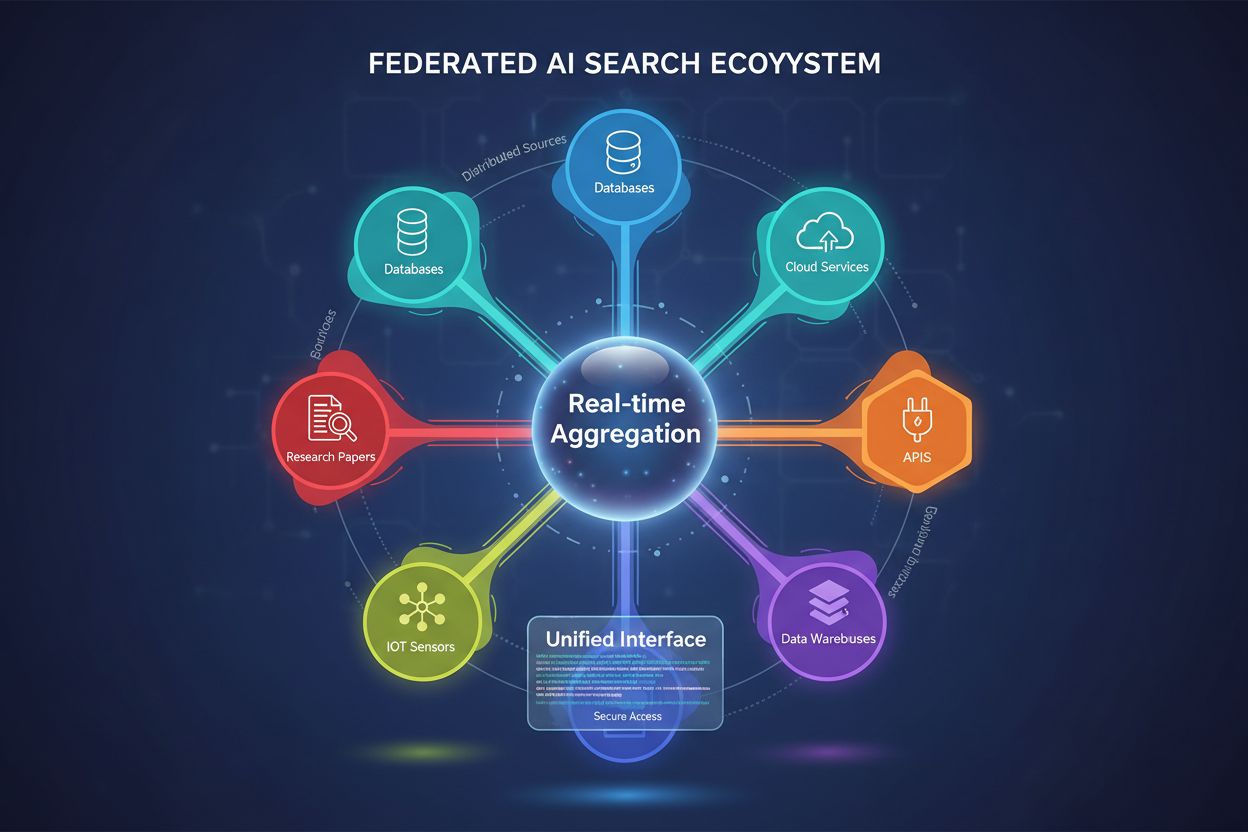
フェデレーテッドAI検索は、単一の検索クエリで複数の独立したデータソースを同時に照会し、データを移動または複製することなくリアルタイムで結果を集約するシステムです。これにより、組織はデータベース、API、クラウドサービスなど分散した情報にアクセスしつつ、データのセキュリティとコンプライアンスを維持できます。従来の集中型検索エンジンとは異なり、フェデレーテッドシステムはデータの自律性を守りながら、統一された情報発見を実現します。このアプローチは、異なる部門や地域、組織にまたがる多様なデータソースを管理する企業に特に有用です。
フェデレーテッドAI検索は、単一の検索クエリで複数の独立したデータソースを同時に照会し、データを移動または複製することなくリアルタイムで結果を集約するシステムです。これにより、組織はデータベース、API、クラウドサービスなど分散した情報にアクセスしつつ、データのセキュリティとコンプライアンスを維持できます。従来の集中型検索エンジンとは異なり、フェデレーテッドシステムはデータの自律性を守りながら、統一された情報発見を実現します。このアプローチは、異なる部門や地域、組織にまたがる多様なデータソースを管理する企業に特に有用です。
フェデレーテッドAI検索は、複数の異種データソースを同時に照会し、人工知能技術を用いてインテリジェントに結果を集約する分散型情報検索システムです。単一のインデックス化リポジトリを維持する従来の集中型検索エンジンとは異なり、フェデレーテッドAI検索は、データの統合や集中型インデックス作成を必要とせず、独立したデータベースやナレッジベース、情報システムの分散型ネットワーク上で動作します。
フェデレーテッドAI検索の根底にある核心原則はソース非依存型クエリです。単一のユーザークエリがインテリジェントに関連データソースへルーティングされ、それぞれのソースで個別に処理され、最終的に統合された結果セットとして合成されます。このアプローチは、データの自律性を保ちつつ、組織や技術的な境界を越えた包括的な情報発見を可能にします。
フェデレーテッドAI検索システムの主な特徴は以下の通りです:
分散アーキテクチャ:データはそれぞれのリポジトリに元のまま保持され、データ移行や集中ストレージが不要です。各ソースは独自にインデックス、アクセス制御、更新機構を維持します。
インテリジェントなクエリルーティング:AIアルゴリズムがクエリを解析し、関連情報を持つ可能性が高いソースを特定。検索効率を最適化し、不要なデータベースへのクエリを削減します。
結果集約とランキング:機械学習モデルが複数ソースからの結果を合成し、ソースの信頼性、結果の関連性、新鮮さ、ユーザーコンテキストなどを考慮した高度なランキングアルゴリズムを適用します。
異種ソース対応:リレーショナルデータベース、ドキュメントストア、ナレッジグラフ、API、非構造テキストリポジトリなど、多様なデータ形式・スキーマ・クエリ言語・アクセスプロトコルに対応します。
リアルタイム統合:バッチ型データウェアハウスと異なり、全ての接続ソースから最新情報をほぼリアルタイムで取得し、結果の新鮮さと正確さを保証します。
セマンティック理解:現代のフェデレーテッドAI検索は、自然言語処理とセマンティック解析を活用し、キーワード一致を超えたクエリ意図の理解や、より正確なソース選択・結果解釈を実現します。
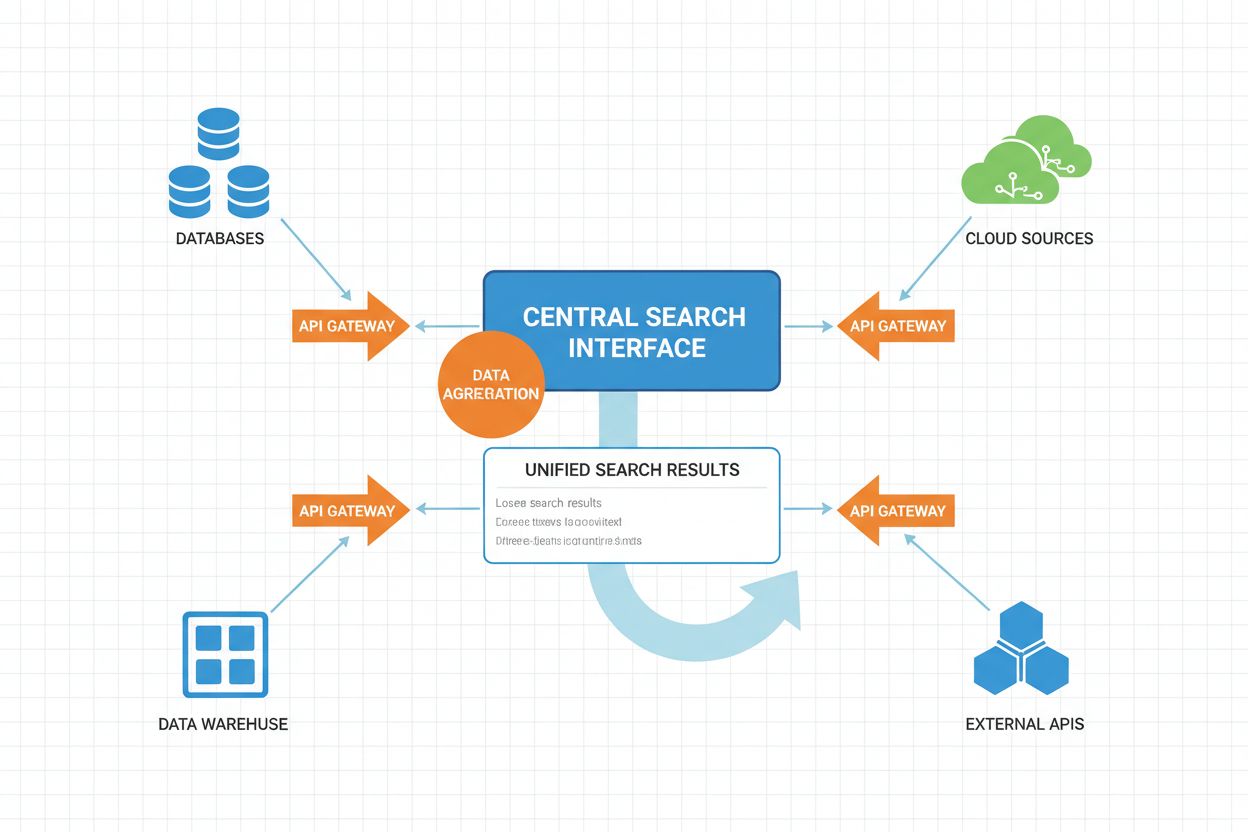
フェデレーテッドAI検索の運用ワークフローは、パフォーマンスと結果品質を最適化するためにAIで強化された複数の協調ステージで構成されます。
| ステージ | プロセス | AIコンポーネント | 出力 |
|---|---|---|---|
| クエリ解析 | ユーザークエリを構文解析し、意図・エンティティ・コンテキストを分析 | NLP、固有表現抽出、意図分類 | 構造化クエリ表現、識別エンティティ、意図シグナル |
| ソース選択 | クエリに最適なデータソースを特定 | 機械学習ランキングモデル、ソース関連性分類 | 優先順位付きソースリスト、信頼スコア |
| クエリ変換 | クエリを各ソース固有のフォーマットやクエリ言語に変換 | スキーママッピング、クエリ変換モデル、セマンティックマッチング | ソース固有クエリ(SQL、SPARQL、APIコール等) |
| 分散実行 | 選択されたソースに対してクエリを並列実行 | 負荷分散、タイムアウト管理、並列処理 | 各ソースからの生データ結果、実行メタデータ |
| 結果正規化 | 異なるソースの結果を共通フォーマットに変換 | スキーマ整合、データ型変換、フォーマット標準化 | 一貫した構造の正規化済み結果セット |
| セマンティック付与 | 結果に追加コンテキストやメタデータを付与 | エンティティリンク、セマンティックタグ付与、ナレッジグラフ統合 | セマンティックアノテーション付き結果 |
| ランキング・重複排除 | 結果を関連度順に並べ重複を除外 | ラーニング・トゥ・ランクモデル、類似性検出、関連性スコアリング | 重複排除済み・ランキング済みの結果リスト |
| パーソナライズ | ユーザープロファイルや嗜好に基づき結果をカスタマイズ | 協調フィルタリング、ユーザーモデリング、コンテキスト認識 | 個人化された結果順序 |
| プレゼンテーション | ユーザー向けに結果を整形表示 | 自然言語生成、結果要約 | ユーザー向け結果表示 |
このワークフローは並列実行を核とし、複数ソースへのクエリを逐次ではなく同時に実行します。これにより、複数ソース調整のオーバーヘッドがあっても全体のクエリ遅延を大幅に削減します。高度なフェデレーテッドシステムは適応型クエリプランニングを実装し、過去のクエリパターンから学習してソース選択や実行戦略を最適化します。
タイムアウトおよびフォールバック機構はシステムの信頼性を担保します。ソースの応答が遅い・失敗した場合も、適応的なタイムアウトや利用可能なソースの結果のみで動作し、全体の結果が失敗に終わるのではなく部分的にでも提供できるよう設計されています。
フェデレーテッドAI検索システムは、様々な観点で分類できます。
アーキテクチャモデル別:
データソースタイプ別:
スコープ・規模別:
インテリジェンスレベル別:
データ自律性・ガバナンス:データを集中リポジトリに移動せず、各組織が自ら管理を継続できます。これにより、情報ガバナンスポリシーやコンプライアンス、セキュリティ管理をソース単位で維持可能。
統合なしのスケーラビリティ:新規ソースを追加するだけでシステムを拡張でき、データ移行やウェアハウス再構築が不要。ビジネスニーズの変化に柔軟対応。
リアルタイム情報アクセス:ソースを直接照会するため、バッチ型ウェアハウスに見られる遅延なしに最新情報を取得。タイムセンシティブな用途で特に有用。
コスト効率:集中型データウェアハウスの構築・維持にかかる大規模インフラ・運用コストが不要。データの重複保存やETL作業も省略。
データ冗長性の低減:データウェアハウスのような複製なしで、単一の信頼ソースを維持でき、ストレージ負荷を軽減し一貫性も担保。
柔軟性・適応性:新規ソースの統合時も既存インフラや集中インデックス再構築が不要。ビジネス要件の変化に迅速対応。
データ品質向上:権威あるソースを直接照会するため、ウェアハウスの同期遅延・不整合リスクを低減。
セキュリティ強化:機密データが元の場所から外部に出ることがなく、不正アクセスや漏洩リスクを最小化。アクセス制御もソース単位で管理。
異種ソース対応:技術・形式・プロトコルの多様性を受け入れ、標準化や共通基盤への移行なしに統合可能。
インテリジェントな結果合成:AI駆動のランキング・集約で、単純なマージよりも高品質な結果を生成。ソース信頼性・関連性・ユーザー文脈も考慮。
現代のフェデレーテッドAI検索システムは、複数の技術コンポーネントが連携して統合検索機能を実現します。
クエリ処理エンジン:ユーザークエリの受付・ワークフローの指揮を担当。構文解析、セマンティック解析、意図認識モジュールを含み、高度な実装ではトランスフォーマーベースの言語モデルを活用して複雑な意味や暗黙的意図も理解。
ソースレジストリ・メタデータ管理:利用可能なデータソースのスキーマ情報、内容特性、更新頻度、可用性パターン、パフォーマンス指標などを一元管理。インテリジェントなソース選択やクエリ最適化の基盤となる。機械学習モデルが過去クエリ傾向を分析し、新規クエリへのソース関連性を予測。
インテリジェント・ソース選択モジュール:機械学習分類器で、クエリに関連する可能性が高いソースを判断。内容範囲、過去クエリ成功率、可用性、応答時間見積もりなど多角的に評価。強化学習でソース選択戦略を継続最適化する高度なシステムも。
クエリ変換・適応レイヤー:ユーザークエリを各ソース向けフォーマット・言語に変換。リレーショナルDB向けSQLや、ナレッジグラフ向けSPARQL、Webサービス向けAPIコール、非構造テキスト向け自然言語クエリなど。意味マッピングで意図の一貫性も維持。
分散実行コーディネーター:複数ソースへの並列クエリ実行を管理し、タイムアウト・負荷分散・障害復旧を担う。ソース応答傾向・システム負荷に応じた適応型タイムアウトを実装。
結果正規化エンジン:異種ソースの結果を共通形式へ変換し、集約・ランキングが可能な状態に整形。スキーマ整合・型変換・フォーマット標準化を担当。欠損フィールドや型不一致もハンドリング。
セマンティック付与モジュール:エンティティリンク、オントロジーベースのタグ付与、非構造テキストからの関係抽出などで、結果に追加コンテキスト・意味情報を付与。ランキング精度や理解性向上に貢献。
ラーニング・トゥ・ランクモデル:過去のクエリ-結果ペアを学習し、結果の関連度を予測する機械学習モデル。ソース信頼性、新鮮さ、ユーザープロファイル合致度、意味的類似度など数百の特徴量を活用。勾配ブースティングやニューラルネットワーク系が主流。
重複排除エンジン:異なるソースからの重複・類似結果を特定・除去。完全一致・ファジー文字列一致・埋め込みベースの意味的類似度など多様な指標で判定。
パーソナライゼーションエンジン:ユーザープロファイルや履歴、コンテキストに基づき結果順序をカスタマイズ。協調フィルタリングや内容ベース推薦技術を導入。
キャッシュ・最適化レイヤー:冗長なクエリを抑制するインテリジェントキャッシュ戦略を実装。クエリ結果・ソースメタデータ・学習済みクエリパターンのキャッシュなど。
モニタリング・アナリティクスモジュール:システムパフォーマンス、ソース信頼性、クエリ傾向、結果品質指標などを監視。最適化コンポーネントへフィードバックし、継続改善を実現。
医療・医学研究:フェデレーテッド検索で、病院間の患者記録、研究データベース、治験レジストリ、医学文献リポジトリを統合。医師は複数医療機関の履歴を一括照会でき、研究者も分散臨床データにHIPAA準拠でアクセス。
金融サービス:銀行や投資会社が、取引データ、市場情報、規制データベース、社内取引記録を同時検索。リアルタイムのリスク評価・規制監視・市場分析を実現し、機密金融データの集中を回避。
法務・コンプライアンス:法律事務所や企業法務部門が判例データベース、規制リポジトリ、社内ドキュメント管理、契約書DBなどを横断検索。包括的な法務調査を行いつつ、守秘義務や機密性も維持。
EC・小売:オンライン小売が複数倉庫、サプライヤー、マーケットプレイスのカタログを統合。サプライヤーごとの在庫・価格自律性を保ちつつ統一商品発見を実現。
行政・公共機関:各種分散DB(国勢調査、税務、許認可、公的記録など)を一元検索。市民情報の集中を避けつつ公共サービスを拡充。
製造・サプライチェーン:供給元DB、在庫管理、製造記録、物流プラットフォームを統合。独立システム・機密情報を保持しつつサプライチェーン全体を可視化。
教育・研究:大学が学内リポジトリ、図書館システム、研究DB、オープンアクセス出版物を横断検索。知的財産や機関自律性を尊重しつつ包括的調査を実現。
通信:顧客DB、ネットワークインフラ記録、請求システム、サービスカタログを統合検索。サービスラインや地域ごとの独立システムを維持しつつ、統一カスタマーサービスを提供。
エネルギー・公益:発電所、流通網、顧客DB、規制準拠システムを横断検索。地域事業者の独立性を維持しつつ運用可視化を実現。
メディア・出版:コンテンツリポジトリ、アーカイブ、権利管理、配信プラットフォームを統合検索。所有権やライセンス制限を尊重しつつ包括的なコンテンツ発見を支援。
ソースの多様性・統合の複雑さ:異なるスキーマ・クエリ言語・プロトコルを持つソースの統合には多大なエンジニアリングが必要。スキーママッピングや意味整合は特に困難。
クエリ遅延・パフォーマンス:複数ソースへの照会により、集中型より遅延が生じやすい。遅い・応答しないソースが全体の検索品質を劣化させる。タイムアウト管理の調整が不可欠。
ソース信頼性・可用性:外部ソースの可用性・応答性に依存。ネットワーク障害やソースダウン、性能劣化が直接検索品質に影響。優雅な機能劣化設計が必要。
結果品質・ランキング精度:ソースごとに品質・範囲・関連基準が異なるため、結果の集約とランキングが難しい。ランキングモデルは信頼性の違いも加味する必要。
データ新鮮さ・一貫性:アクセスするソースごとに更新頻度や整合保証が異なる。矛盾する情報の調停には高度なコンフリクト解決が不可欠。
スケーラビリティ限界:ソース数が増えるほどクエリ調整オーバーヘッドが増大。数千ソースからの選択は計算コストが高く、並列実行インフラも不可欠。
セキュリティ・アクセス制御:ソース単位でアクセス管理を徹底しながら統一インターフェースを提供する必要があり、特にマルチテナント環境では複雑。
プライバシー・データ保護:GDPRやCCPAなど規制遵守が必須。集約やメタデータ分析で機密情報が漏洩しない設計が求められる。
ソース発見・管理:ソースの発見・カタログ化・正確なメタデータ維持・ライフサイクル管理(追加・削除・更新)には継続的な運用が必要。
意味的相互運用性:異なるオントロジーやデータモデル間で真の意味的相互運用性を実現するのは困難。自動スキーママッピングやエンティティ解決にも限界。
調整コスト:データ統合コストは削減できても、実行調整や障害対応、クエリルーティング最適化など分散システム固有の運用負荷が発生。
標準化の遅れ:普遍的なフェデレーテッド検索プロトコルやインターフェース標準が未整備なため、システム統合の難易度やベンダーロックインリスクが高い。
フェデレーテッドAI検索 vs. データウェアハウジング:ウェアハウジングは複数ソースのデータを集中リポジトリに統合し、高速クエリを実現しますが、ETL作業とデータ遅延が発生します。フェデレーテッド検索はソースを直接照会し、リアルタイムだがクエリ遅延は高め。ウェアハウスは履歴分析・レポート、フェデレーテッドは最新情報発見向き。
フェデレーテッドAI検索 vs. データレイク:データレイクは複数ソースの生データを集中保存し柔軟性は高いが、ストレージやガバナンス負担が大きい。フェデレーテッド検索は統合自体を回避し、ソース自律性を維持しつつ高度なクエリ処理を実現。
フェデレーテッドAI検索 vs. API・マイクロサービス:APIは個々サービスへのプログラム的アクセスを提供するが、各サービスのインターフェースを把握する必要あり。フェデレーテッド検索はソース固有情報を抽象化し、統一クエリを実現。APIはアプリ間連携、フェデレーテッドは横断的情報発見に最適。
フェデレーテッドAI検索 vs. ナレッジグラフ:ナレッジグラフはエンティティと関係性を表現し、意味推論を可能にする。フェデレーテッド検索は分散ナレッジグラフも照会可能だが、集中型グラフ構築は不要。ナレッジグラフは深い意味理解、フェデレーテッドはソース自律性を重視。
フェデレーテッドAI検索 vs. 検索エンジン:従来の検索エンジンはクロールした内容を集中インデックス化。フェデレーテッド検索は事前インデックスなしでソース直接照会。検索エンジンは公開情報の網羅性、フェデレーテッドは非公開・専門ソース統合に強み。
フェデレーテッドAI検索 vs. マスターデータ管理(MDM):MDMは複数ソースを統合し権威あるマスターレコードを生成。フェデレーテッド検索はマスター生成せず、独立ソースを個別照会。MDMはガバナンス・一貫性、フェデレーテッドは自律性・リアルタイム性重視。
フェデレーテッドAI検索 vs. エンタープライズ検索:エンタープライズ検索は社内DBや文書を集中インデックス化し高速全文検索を提供。フェデレーテッドは集中インデックスなしで多様なソース・リアルタイム対応。
フェデレーテッドAI検索 vs. ブロックチェーン・分散台帳:ブロックチェーンはノード間で分散合意・改ざん耐性を実現。フェデレーテッド検索は合意形成なしに独立ソースを照会。ブロックチェーンは信頼・検証向け、フェデレーテッドは情報発見が主眼。
包括的なソース評価:統合前にデータ品質、更新頻度、可用性、スキーマ複雑性、アクセスプロトコル等を詳細に評価。これがソース選択アルゴリズムや期待値設定の基盤
従来の集中型検索は、すべてのデータを単一のインデックス化されたリポジトリに統合するため、データ移行が必要で遅延も発生します。フェデレーテッドAI検索は、複数の独立したソースをリアルタイムで直接照会し、データを移動・複製することなくソースの自律性を保ちながら統一的なアクセスを提供します。これにより、分散したデータソースと厳格なデータガバナンス要件を持つ組織に最適です。
フェデレーテッドAI検索では、データを元の場所に保持し、各ソースのアクセス制御やセキュリティポリシーを尊重します。ユーザーは自分が許可された情報のみアクセスでき、機密データがソースシステムから外部に出ることはありません。この手法により、GDPRやHIPAAなどの規制遵守が簡素化され、機密情報の集中管理に伴うリスクが排除されます。
主な課題には、異なるスキーマやフォーマットを持つ多様なデータソースの管理、複数ソースからのクエリ遅延の対応、ソース間で一貫した結果ランキングの実現、ソースが利用不能な場合の信頼性維持などがあります。また、パフォーマンス最適化のために堅牢なメタデータ管理やインテリジェントなソース選択アルゴリズムへの投資も必要です。
はい。フェデレーテッドAI検索は、データ移行やウェアハウスの再構築を必要とせず新しいソースを追加することでスケールします。ただし、ソース数が増えるとクエリ調整のオーバーヘッドも増加します。最新のシステムは、機械学習を用いたインテリジェントなソース選択やキャッシュ戦略を導入し、大規模でもパフォーマンスを維持しています。
データウェアハウジングはデータを集中リポジトリに統合し、高速な検索が可能ですが、ETL作業が多くデータ遅延も発生します。フェデレーテッド検索はソースを直接照会し、リアルタイムアクセスが可能ですが、クエリ遅延は高くなります。ウェアハウスは履歴分析やレポートに適し、フェデレーテッド検索は分散ソースからの最新情報発見に優れています。
医療、金融、EC、行政、研究機関がフェデレーテッド検索の恩恵を大きく受けています。医療では患者記録の統合、金融ではコンプライアンスやリスク評価、ECでは統一的な商品検索、研究機関では分散した学術データベースの横断検索などに活用されています。
AIは自然言語処理によるクエリ理解、機械学習によるインテリジェントなソース選択、セマンティック解析による高度なランキング、自動重複排除などでフェデレーテッド検索を強化します。AIモデルはクエリパターンから学習し、ソース選択や結果集約を継続的に最適化し、システムパフォーマンスを向上させます。
セマンティック理解により、フェデレーテッドシステムはキーワード一致を超えてクエリの意図を把握し、より適切なソース選択と意味に基づくランキングが可能となります。これにはエンティティ認識、関係抽出、ナレッジグラフ統合などが含まれ、より文脈に合った検索結果を実現します。
ChatGPT、Perplexity、Google AI OverviewsなどのAI検索エンジンがどのように機能するかを学びましょう。LLM、RAG、セマンティックサーチ、リアルタイム検索メカニズムを解説します。...
ChatGPT、Perplexity、Claude、GeminiでのAI検索クエリのリサーチとモニタリング方法をご紹介。ブランド言及の追跡やAI検索での可視性最適化の手法も解説します。...
ChatGPT、Perplexity、Google AI OverviewsなどのAI検索エンジン向けにコンテンツを最適化するための基本的なステップを学びましょう。コンテンツ構造化、スキーママークアップの実装、AIによる引用のための権威性構築の方法を解説します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.