
Come Ricercare le Query di Ricerca AI?
Scopri come ricercare e monitorare le query di ricerca AI su ChatGPT, Perplexity, Claude e Gemini. Scopri metodi per tracciare le menzioni del brand e ottimizza...
10 min di lettura
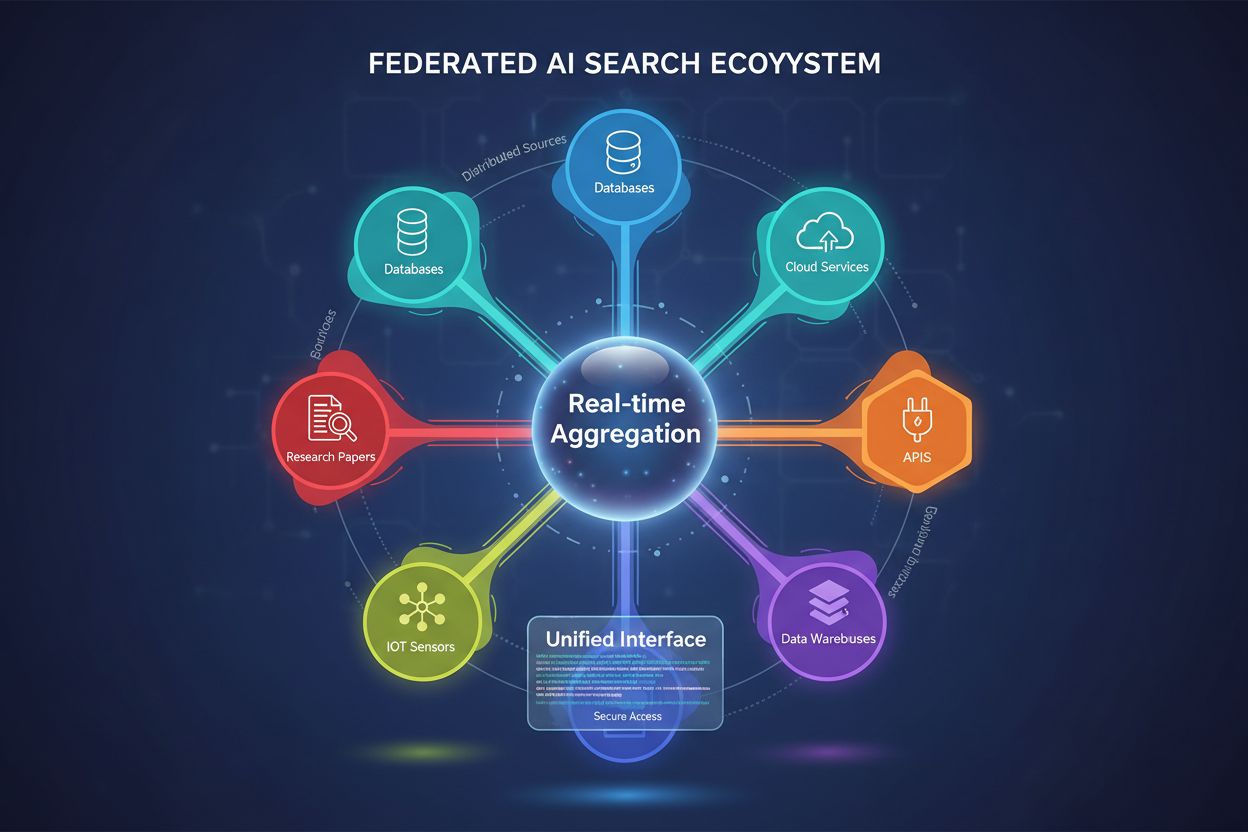
La Ricerca AI Federata è un sistema che interroga simultaneamente più fonti di dati indipendenti utilizzando una sola query di ricerca e aggrega i risultati in tempo reale senza spostare o duplicare i dati. Consente alle organizzazioni di accedere a informazioni distribuite tra database, API e servizi cloud mantenendo sicurezza e conformità dei dati. A differenza dei motori di ricerca centralizzati tradizionali, i sistemi federati preservano l’autonomia dei dati offrendo comunque una scoperta unificata delle informazioni. Questo approccio è particolarmente prezioso per le imprese che gestiscono fonti di dati eterogenee tra reparti, aree geografiche o organizzazioni diverse.
La Ricerca AI Federata è un sistema che interroga simultaneamente più fonti di dati indipendenti utilizzando una sola query di ricerca e aggrega i risultati in tempo reale senza spostare o duplicare i dati. Consente alle organizzazioni di accedere a informazioni distribuite tra database, API e servizi cloud mantenendo sicurezza e conformità dei dati. A differenza dei motori di ricerca centralizzati tradizionali, i sistemi federati preservano l'autonomia dei dati offrendo comunque una scoperta unificata delle informazioni. Questo approccio è particolarmente prezioso per le imprese che gestiscono fonti di dati eterogenee tra reparti, aree geografiche o organizzazioni diverse.
Ricerca AI Federata è un sistema distribuito di recupero delle informazioni che interroga simultaneamente più fonti di dati eterogenee e aggrega in modo intelligente i risultati utilizzando tecniche di intelligenza artificiale. A differenza dei motori di ricerca centralizzati tradizionali che mantengono un unico repository indicizzato, la ricerca AI federata opera su reti decentralizzate di database indipendenti, knowledge base e sistemi informativi senza richiedere consolidamento o indicizzazione centralizzata dei dati.
Il principio fondamentale della ricerca AI federata è la query agnostica rispetto alla fonte, dove una singola query utente viene instradata in modo intelligente verso le fonti di dati rilevanti, elaborata indipendentemente da ciascuna fonte e poi sintetizzata in un insieme di risultati unificato. Questo approccio preserva l’autonomia dei dati permettendo una scoperta informativa completa attraverso confini organizzativi e tecnici.
Le caratteristiche principali dei sistemi di ricerca AI federata includono:
Architettura Distribuita: I dati rimangono nella loro posizione originale su più repository, eliminando la necessità di migrazione o archiviazione centralizzata. Ogni fonte mantiene in autonomia il proprio indice, i controlli di accesso e i meccanismi di aggiornamento.
Instradamento Intelligente delle Query: Algoritmi di AI analizzano le query in ingresso per determinare quali fonti hanno più probabilità di contenere informazioni rilevanti, ottimizzando l’efficienza della ricerca e riducendo query inutili verso database irrilevanti.
Aggregazione e Classifica dei Risultati: Modelli di machine learning sintetizzano i risultati provenienti da più fonti, applicando sofisticati algoritmi di ranking che considerano credibilità della fonte, rilevanza, freschezza e contesto utente.
Supporto a Fonti Eterogenee: I sistemi federati gestiscono formati di dati, schemi, linguaggi di query e protocolli di accesso diversi, inclusi database relazionali, document store, knowledge graph, API e repository di testo non strutturato.
Integrazione in Tempo Reale: A differenza degli approcci batch del data warehousing, la ricerca federata offre accesso quasi in tempo reale alle informazioni correnti tra tutte le fonti collegate, garantendo freschezza e accuratezza dei risultati.
Comprensione Semantica: Le moderne ricerche AI federate sfruttano NLP e analisi semantica per comprendere l’intento della query oltre la corrispondenza delle parole chiave, consentendo una selezione delle fonti e un’interpretazione dei risultati più precise.
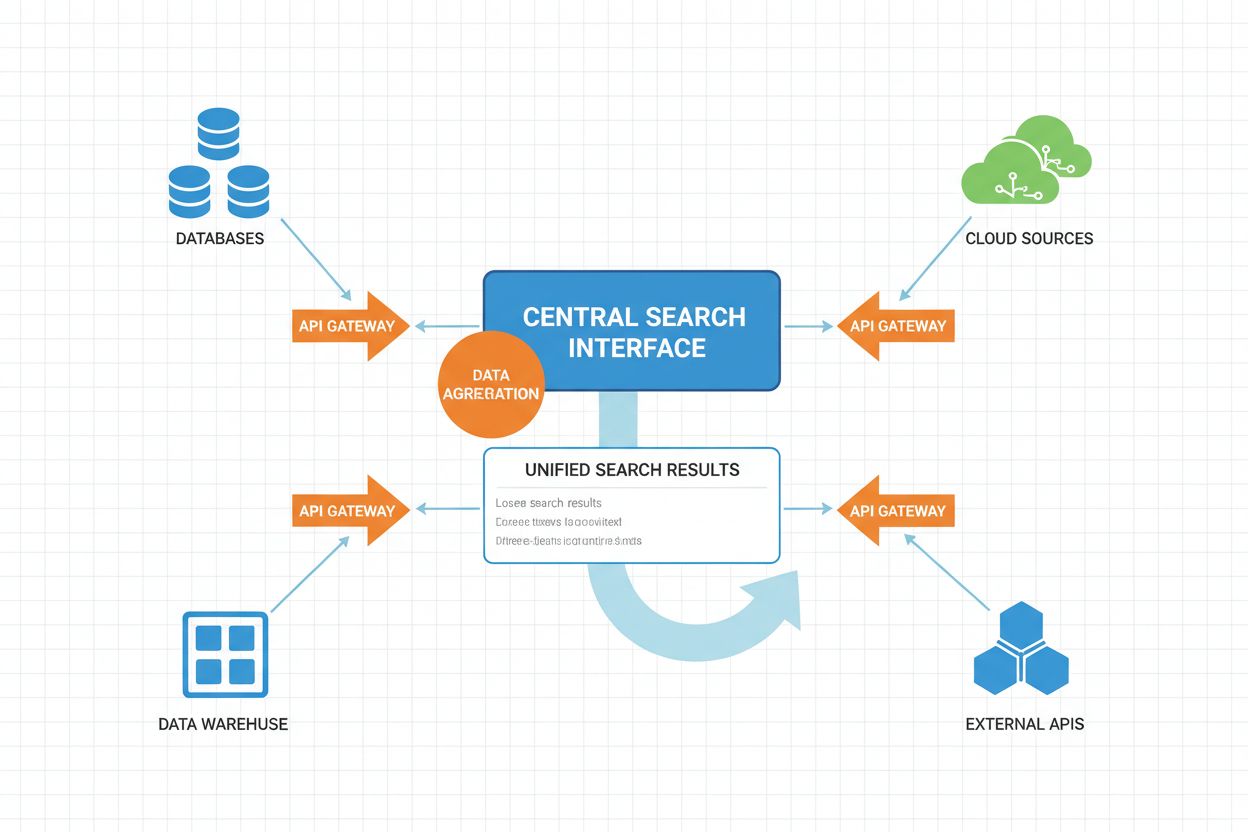
Il flusso operativo della ricerca AI federata prevede più fasi coordinate, ciascuna ottimizzata dall’intelligenza artificiale per migliorare le prestazioni e la qualità dei risultati.
| Fase | Processo | Componente AI | Output |
|---|---|---|---|
| Analisi della Query | La query utente viene analizzata per intenti, entità e contesto | NLP, Named Entity Recognition, Intent Classification | Rappresentazione strutturata della query, entità identificate, segnali di intento |
| Selezione della Fonte | Il sistema determina quali fonti sono più rilevanti per la query | Modelli ML di ranking, Classificatori di rilevanza delle fonti | Elenco prioritario delle fonti target, punteggi di confidenza |
| Traduzione della Query | La query viene tradotta nei formati e linguaggi specifici di ciascuna fonte | Mapping di schema, Modelli di traduzione query, Matching semantico | Query specifiche per fonte (SQL, SPARQL, chiamate API, ecc.) |
| Esecuzione Distribuita | Le query vengono eseguite in parallelo sulle fonti selezionate | Load Balancing, Gestione timeout, Elaborazione parallela | Risultati grezzi da ciascuna fonte, metadati di esecuzione |
| Normalizzazione dei Risultati | I risultati vengono convertiti in un formato comune | Allineamento schema, Conversione tipi dati, Standardizzazione formato | Set di risultati normalizzati con struttura coerente |
| Arricchimento Semantico | I risultati vengono arricchiti con contesto e metadati aggiuntivi | Entity linking, Semantic tagging, Integrazione knowledge graph | Risultati arricchiti con annotazioni semantiche |
| Ranking e Deduplicazione | I risultati vengono ordinati per rilevanza e deduplicati | Modelli Learning-to-Rank, Rilevamento similarità, Scoring rilevanza | Lista di risultati deduplicata e ordinata |
| Personalizzazione | I risultati vengono personalizzati secondo profilo e preferenze utente | Collaborative filtering, User modeling, Context awareness | Ordinamento dei risultati personalizzato |
| Presentazione | I risultati sono formattati per la fruizione utente | Generazione linguaggio naturale, Sintesi dei risultati | Visualizzazione dei risultati per l’utente |
Il workflow opera con esecuzione parallela al centro, interrogando simultaneamente più fonti invece che in sequenza. Questa parallelizzazione riduce notevolmente la latenza complessiva delle query nonostante l’overhead di coordinamento. I sistemi federati avanzati implementano pianificazione adattiva delle query, imparando dai pattern storici delle query per ottimizzare la selezione delle fonti e le strategie di esecuzione nel tempo.
Meccanismi di Timeout e Fallback sono componenti critici per l’affidabilità del sistema. Quando una fonte risponde lentamente o fallisce, il sistema può attendere con timeout adattivi o proseguire con i risultati disponibili, degradando la completezza ma evitando il fallimento totale.
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
I sistemi di ricerca AI federata possono essere classificati secondo più dimensioni:
Per Modello Architetturale:
Per Tipo di Fonte Dati:
Per Ambito e Scala:
Per Livello di Intelligenza:
Autonomia dei Dati e Governance: Le organizzazioni mantengono il controllo sui propri dati, eliminando la necessità di trasferire informazioni sensibili verso repository centralizzati. Questo preserva policy di governance, requisiti di conformità e controlli di sicurezza a livello di fonte.
Scalabilità Senza Consolidamento: I sistemi federati scalano aggiungendo nuove fonti senza richiedere migrazioni o ristrutturazioni. Ciò consente integrazione incrementale dei dati in base alle esigenze aziendali.
Accesso alle Informazioni in Tempo Reale: Interrogando direttamente le fonti, la ricerca federata offre accesso alle informazioni correnti senza la latenza tipica delle soluzioni batch. Questo è particolarmente utile per applicazioni time-sensitive.
Efficienza dei Costi: Elimina i costi infrastrutturali e operativi legati alla costruzione e manutenzione di warehouse centralizzati. Si evita duplicazione, storage ridondante e processi ETL complessi.
Riduzione della Ridondanza dei Dati: Al contrario del data warehousing, la ricerca federata mantiene un’unica versione delle informazioni, riducendo overhead di storage e garantendo coerenza.
Flessibilità e Adattabilità: Nuove fonti vengono integrate senza modificare l’infrastruttura esistente o reindicizzare. Questa flessibilità consente risposte rapide alle esigenze di business.
Migliore Qualità dei Dati: Interrogando direttamente le fonti autorevoli, si riducono problemi di staleness e inconsistenza derivanti dalla sincronizzazione periodica dei dati.
Sicurezza Rafforzata: I dati sensibili non lasciano mai la fonte originale, riducendo il rischio di accessi non autorizzati. I controlli d’accesso rimangono a livello di fonte.
Supporto a Fonti Eterogenee: I sistemi federati supportano tecnologie, formati e protocolli diversi senza necessità di standardizzazione.
Sintesi Intelligente dei Risultati: Il ranking e l’aggregazione AI-driven producono risultati di qualità superiore rispetto a semplici merge, considerando credibilità, rilevanza e contesto utente.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
I moderni sistemi di ricerca AI federata sono composti da vari componenti tecnici interconnessi che lavorano insieme per offrire capacità di ricerca integrate.
Motore di Elaborazione delle Query: Il componente centrale che riceve le query utente e orchestra il workflow federato. Include parsing, analisi semantica e riconoscimento dell’intento. Le implementazioni avanzate utilizzano modelli linguistici transformer per comprendere query complesse e intenti impliciti.
Registro delle Fonti e Gestione Metadati: Mantiene metadati esaustivi sulle fonti disponibili, inclusi schemi, caratteristiche del contenuto, frequenza aggiornamenti, disponibilità e metriche di performance. Questo registro abilita selezione intelligente delle fonti e ottimizzazione delle query. Modelli ML analizzano pattern storici delle query per prevedere la rilevanza delle fonti.
Modulo di Selezione Intelligente delle Fonti: Usa classificatori ML per determinare quali fonti possano contenere informazioni rilevanti per una query. Considera copertura, tassi di successo storici, disponibilità e tempi di risposta stimati. Sistemi avanzati impiegano reinforcement learning per ottimizzare le strategie di selezione.
Layer di Traduzione e Adattamento delle Query: Converte le query in formati e linguaggi specifici delle fonti. Include generazione SQL, SPARQL, chiamate API REST e query in linguaggio naturale per sistemi non strutturati. Il mapping semantico assicura la conservazione dell’intento.
Coordinatore di Esecuzione Distribuita: Gestisce l’esecuzione parallela delle query, timeout, bilanciamento del carico e recovery dai fallimenti. Implementa timeout adattivi in base ai pattern di risposta e ai carichi di sistema.
Motore di Normalizzazione dei Risultati: Converte i risultati eterogenei in formato comune per aggregazione e ranking, gestendo allineamenti di schema, conversioni di tipo, differenze strutturali e dati mancanti.
Modulo di Arricchimento Semantico: Arricchisce i risultati con contesto ed elementi semantici: entity linking, tagging basato su ontologie, estrazione di relazioni da testi non strutturati. Questi arricchimenti migliorano ranking e comprensibilità.
Modello Learning-to-Rank: Modello ML addestrato su coppie query-risultato storiche per prevedere la rilevanza. Considera centinaia di feature: credibilità, freschezza, allineamento utente, similarità semantica. Le implementazioni moderne usano boosting o reti neurali.
Motore di Deduplicazione: Identifica e rimuove risultati duplicati o quasi duplicati usando metriche di similarità (match esatto, fuzzy, similarità semantica tramite embedding).
Motore di Personalizzazione: Ordina i risultati in base a profili utente, preferenze storiche e contesto, applicando collaborative filtering e raccomandazioni content-based.
Layer di Caching e Ottimizzazione: Implementa strategie di caching intelligenti per ridurre query ridondanti: caching dei risultati, dei metadati e pattern appresi.
Modulo di Monitoraggio e Analytics: Traccia performance, affidabilità delle fonti, pattern delle query e metriche di qualità dei risultati. Questi dati alimentano i componenti di ottimizzazione.
Sanità e Ricerca Medica: Integra cartelle cliniche tra sistemi ospedalieri, database di ricerca, registri di trial clinici e repository di letteratura. I medici ottengono storici completi senza centralizzare dati sensibili; i ricercatori accedono a dati clinici distribuiti mantenendo compliance HIPAA e privacy.
Servizi Finanziari: Banche e investitori interrogano dati di trading, informazioni di mercato, database regolatori e registri transazionali simultaneamente. Si abilitano valutazione rischi in tempo reale, monitoraggio della conformità e analisi di mercato senza centralizzare dati sensibili.
Legale e Compliance: Studi legali e dipartimenti aziendali cercano tra banche dati giuridiche, repository normativi, sistemi documentali e database contrattuali. La ricerca federata consente ricerche esaustive mantenendo riservatezza e privilegio cliente-avvocato.
E-Commerce e Retail: I rivenditori online integrano cataloghi tra magazzini, sistemi dei fornitori e piattaforme marketplace. La ricerca federata offre scoperta prodotti unificata pur consentendo ai fornitori autonomia su inventario e prezzi.
Pubblica Amministrazione: Le agenzie governative cercano tra database distribuiti (censimenti, tasse, permessi, registri pubblici) senza centralizzare dati sensibili dei cittadini, garantendo servizi pubblici completi e sicurezza dati.
Manifattura e Supply Chain: I produttori integrano database fornitori, sistemi inventario, registri di produzione e piattaforme logistiche. La ricerca federata fornisce visibilità sulla catena di fornitura mantenendo sistemi e informazioni proprietarie indipendenti.
Istruzione e Ricerca: Le università cercano tra repository istituzionali, sistemi bibliotecari, database di ricerca e pubblicazioni open access. La ricerca federata consente scoperta accademica completa rispettando autonomia e diritti di proprietà intellettuale.
Telecomunicazioni: I provider telefonici cercano tra database clienti, registri di rete, sistemi di billing e cataloghi servizi. Si ottiene un servizio clienti unificato mantenendo sistemi separati per linee di servizio e regioni.
Energia e Utility: Le aziende energetiche cercano tra centrali di generazione, reti di distribuzione, database clienti e sistemi di compliance regolatoria. Si ha visibilità operativa mantenendo sistemi regionali indipendenti.
Media e Editoria: Le organizzazioni media cercano tra repository di contenuti, archivi, sistemi di gestione diritti e piattaforme di distribuzione. La ricerca federata consente scoperta completa preservando proprietà e restrizioni di licenza.
Eterogeneità delle Fonti e Complessità di Integrazione: Integrare fonti con schemi, linguaggi di query e protocolli di accesso diversi richiede notevole sforzo ingegneristico. Mapping di schema e allineamento semantico restano sfide, specie con rappresentazioni differenti degli stessi concetti.
Latenza delle Query e Prestazioni: La ricerca federata, dovendo interrogare più fonti, introduce latenza rispetto ai sistemi centralizzati. Fonti lente o non rispondenti degradano le performance. La gestione dei timeout va calibrata tra completezza e reattività.
Affidabilità e Disponibilità delle Fonti: I sistemi federati dipendono dalla disponibilità e responsività delle fonti esterne. Malfunzionamenti di rete, downtime o degrado prestazionale impattano la qualità della ricerca. È necessaria una degradazione controllata in caso di fallimenti.
Qualità dei Risultati e Accuratezza del Ranking: Aggregare risultati da fonti con qualità e criteri di rilevanza diversi è complesso. I modelli di ranking devono tenere conto delle variazioni di credibilità ed evitare bias verso certe fonti.
Freschezza e Coerenza dei Dati: Le fonti possono avere frequenze di aggiornamento e garanzie di consistenza diverse. Riconciliare informazioni conflittuali richiede strategie sofisticate di risoluzione.
Limiti di Scalabilità: Crescendo il numero di fonti, cresce il sovraccarico di coordinamento. Selezionare fonti rilevanti tra migliaia può essere oneroso. L’esecuzione parallela su molte fonti richiede infrastruttura robusta.
Sicurezza e Controllo Accessi: I sistemi federati devono applicare controlli di accesso a livello di fonte offrendo al contempo interfacce unificate. Garantire che l’utente veda solo ciò che è autorizzato è complesso, specie in ambienti multi-tenant.
Privacy e Protezione dei Dati: La ricerca federata deve rispettare regolamentazioni come GDPR, CCPA e requisiti di settore. Evitare leak di dati sensibili tramite aggregazione o analisi dei metadati richiede design attento.
Scoperta e Gestione delle Fonti: Identificare, catalogare e mantenere metadati accurati sulle fonti, gestendo il ciclo di vita (aggiunta, rimozione, aggiornamento), richiede sforzo continuo.
Interoperabilità Semantica: Raggiungere vera interoperabilità semantica tra fonti con ontologie e modelli dati diversi è difficile. Le tecniche di mapping e entity resolution hanno ancora limiti.
Costo di Coordinamento: Pur eliminando i costi di consolidamento, la ricerca federata introduce overhead di coordinamento. Gestire esecuzione distribuita, errori e ottimizzare l’instradamento richiede infrastruttura sofisticata.
Standardizzazione Limitata: L’assenza di standard universali per protocolli e interfacce rende l’integrazione più difficile e aumenta il rischio di lock-in.
Ricerca AI Federata vs. Data Warehousing: Il warehousing consolida i dati in un unico repository, offrendo query rapide ma richiedendo notevoli sforzi ETL e latenza. La ricerca federata interroga direttamente le fonti, offrendo accesso in tempo reale ma con maggiore latenza nelle query. Il warehousing è ideale per analisi storiche, la ricerca federata per la scoperta di informazioni attuali.
Ricerca AI Federata vs. Data Lake: I data lake archiviano dati grezzi da più fonti in una posizione centralizzata con trasformazione minima, offrendo flessibilità ma richiedendo storage e governance onerosi. La ricerca federata evita la centralizzazione, preservando autonomia ma richiedendo query processing sofisticato.
Ricerca AI Federata vs. API e Microservizi: Le API forniscono accesso programmato a servizi individuali ma richiedono conoscenza specifica di ciascuna interfaccia. La ricerca federata astrae i dettagli, permettendo query unificate. Le API sono adatte all’integrazione applicativa; la ricerca federata alla scoperta trasversale.
Ricerca AI Federata vs. Knowledge Graph: I knowledge graph rappresentano informazioni come entità e relazioni, abilitando ragionamento semantico. La ricerca federata può interrogare graph distribuiti ma non richiede centralizzazione. I knowledge graph offrono comprensione profonda, la ricerca federata autonomia delle fonti.
Ricerca AI Federata vs. Motori di Ricerca: I motori di ricerca tradizionali mantengono indici centralizzati. La ricerca federata interroga direttamente le fonti senza pre-indicizzazione. I motori coprono contenuti pubblici, la ricerca federata integra fonti private o specialistiche.
Ricerca AI Federata vs. Master Data Management (MDM): L’MDM crea record master consolidando fonti diverse. La ricerca federata interroga le fonti senza creare master. L’MDM è per governance e coerenza, la ricerca federata per autonomia e accesso in tempo reale.
Ricerca AI Federata vs. Enterprise Search: L’enterprise search indicizza documenti e database interni in un indice centralizzato. La ricerca federata interroga direttamente le fonti senza indicizzazione. L’enterprise search offre ricerca full-text rapida, la federata gestisce fonti eterogenee e aggiornamenti in tempo reale.
Ricerca AI Federata vs. Blockchain e Distributed Ledger: La blockchain mantiene consenso distribuito tra nodi, garantendo integrità e immutabilità. La ricerca federata coordina query tra fonti indipendenti senza consenso. La blockchain è per fiducia e verifica, la federata per la scoperta informativa.
Valutazione Approfondita delle Fonti: Prima dell’integrazione, valutare qualità dati, frequenza aggiornamenti, pattern di disponibilità, complessità degli schemi e protocolli di accesso. Questi dati informano algoritmi di selezione e aspettative di performance.
Integrazione Incrementale: Iniziare con poche fonti note e ampliare gradualmente. Ciò consente di sviluppare esperienza, identificare criticità e raffinare i processi prima della scalabilità.
Gestione Solida dei Metadati: Investire in metadati completi su schemi, copertura, qualità e performance delle fonti. Automatizzare il monitoraggio e validare periodicamente l’accuratezza.
Selezione Intelligente delle Fonti: Implementare selezione tramite machine learning che apprende dagli esiti delle query. Tracciare quali fonti sono rilevanti per certi tipi di query e ottimizzare le strategie.
Gestione Adattiva dei Timeout: Adottare strategie di timeout adattive in base ai pattern di risposta delle fonti e al carico del sistema, evitando timeout fissi troppo lunghi o troppo brevi.
Assicurazione Qualità dei Risultati: Definire metriche di qualità (rilevanza, freschezza, completezza) e implementare feedback degli utenti per migliorare i modelli di ranking.
Monitoraggio Completo: Tracciare disponibilità, tempi di risposta, qualità e soddisfazione utente. Usare questi dati per identificare fonti problematiche e ottimizzare il routing.
Sicurezza e Controllo Accessi: Implementare controlli di accesso a livello di fonte che rispettino le policy di autorizzazione sull’intero sistema federato.
Strategie di Caching: Implementare caching intelligente su più livelli: risultati, metadati delle fonti e pattern appresi. Bilanciare freschezza e performance.
Ottimizzazione User Experience: Progettare interfacce che comunichino chiaramente le fonti, i livelli di confidenza e la freschezza dei risultati.
Ottimizzazione delle Prestazioni: Profilare l’esecuzione delle query per identificare colli di bottiglia e ottimizzare selezione fonti, traduzione query e aggregazione.
Apprendimento Continuo: Implementare loop di feedback dalle interazioni utente per migliorare selezione delle fonti, ranking e presentazione.
Documentazione e Governance: Mantenere documentazione esaustiva sulle fonti, approcci di integrazione e architettura. Definire policy di governance su aggiunta, rimozione e modifica delle fonti.
Testing e Validazione: Implementare test unitari, di integrazione e end-to-end su workflow completi. Validare la qualità dei risultati rispetto a ground truth noti.
Comprensione Avanzata del Linguaggio Naturale: I sistemi futuri sfrutteranno grandi modelli linguistici e tecniche NLP avanzate per comprendere query complesse con contesto implicito e intenti sfumati, migliorando la selezione delle fonti e l’interpretazione dei risultati.
Scoperta Autonoma delle Fonti: Sistemi ML scopriranno e catalogheranno automaticamente le fonti disponibili, ne valuteranno rilevanza e qualità e le integreranno con minimo intervento umano.
Integrazione Semantic Web: Con la maturazione delle tecnologie semantic web, i sistemi federati sfrutteranno ontologie e standard linked data per interoperabilità semantica profonda.
Explainable AI e Trasparenza: I sistemi futuri offriranno spiegazioni dettagliate sulle decisioni di ranking, selezione e aggregazione, costruendo fiducia e comprensione.
Integrazione Federated Learning: Tecniche di federated learning permetteranno di addestrare modelli ML su fonti distribuite senza centralizzare i dati, unendo autonomia e potenza predittiva.
Integrazione Streaming Real-Time: I sistemi federati integreranno sempre più stream dati in tempo reale oltre ai database tradizionali, abilitando ricerca su fonti in aggiornamento continuo.
Ricerca Multimodale: I sistemi federati futuri ricercheranno tra testi, immagini, video e audio. Modelli AI multimodali abiliteranno ricerche e sintesi cross-modali.
Personalizzazione e Consapevolezza del Contesto: Modellazione utente avanzata e comprensione del contesto permetteranno esperienze altamente personalizzate, adattando la presentazione dei risultati a competenze e necessità.
Applicazioni del Quantum Computing: Con la maturazione del quantum computing, i sistemi federati potranno usare algoritmi quantistici per ottimizzare selezione delle fonti e ranking.
Integrazione Blockchain: I sistemi federati potranno integrare la blockchain per verifica delle fonti, tracciamento della provenienza e coordinamento decentralizzato in applicazioni critiche.
Edge Computing e Elaborazione Distribuita: La ricerca federata sfrutterà sempre più l’edge computing per elaborare le query vicino alle fonti, riducendo latenza e traffico, migliorando la privacy.
Ottimizzazione Autonoma: Sistemi federati auto-ottimizzanti apprenderanno continuamente da pattern di query, caratteristiche delle fonti e feedback utente, migliorando le prestazioni senza intervento umano.
Integrazione Conoscenza Cross-Dominio: I sistemi del futuro integreranno conoscenze tra domini diversi, abilitando la scoperta di connessioni e insight inaspettati dalla combinazione di fonti eterogenee.
AmICited traccia come sistemi AI come ChatGPT, Perplexity e Google AI Overviews citano e fanno riferimento al tuo brand. Comprendi la tua visibilità nell'AI e ottimizza la tua presenza nelle risposte generate dall'intelligenza artificiale.
Scopri come ricercare e monitorare le query di ricerca AI su ChatGPT, Perplexity, Claude e Gemini. Scopri metodi per tracciare le menzioni del brand e ottimizza...
Comprendi come i funnel di ricerca AI funzionano in modo diverso rispetto ai funnel di marketing tradizionali. Scopri come sistemi AI come ChatGPT e Google AI c...

Scopri cos'è SearchGPT, come funziona e il suo impatto su ricerca, SEO e marketing digitale. Esplora le funzionalità, i limiti e il futuro della ricerca aliment...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.