
Wat is AI-hallucinatie: Definitie, Oorzaken en Impact op AI-zoekopdrachten
Ontdek wat AI-hallucinatie is, waarom het voorkomt bij ChatGPT, Claude en Perplexity, en hoe je valse AI-informatie in zoekresultaten herkent.
12 min lezen

Ontdek hoe AI-hallucinaties de merkveiligheid bedreigen via Google AI Overviews, ChatGPT en Perplexity. Ontdek monitoringstrategieën, contentversterkingstechnieken en incident response playbooks om uw merkreputatie te beschermen in het AI-zoektijdperk.
AI-hallucinaties vormen een van de grootste uitdagingen bij moderne taalmodellen—gevallen waarbij Large Language Models (LLM’s) ogenschijnlijk plausibele maar volledig verzonnen informatie genereren met volledige overtuiging. Deze valse informatie ontstaat doordat LLM’s feiten niet écht “begrijpen”; ze voorspellen in plaats daarvan statistisch waarschijnlijke woordreeksen op basis van patronen in hun trainingsgegevens. Dit fenomeen is vergelijkbaar met hoe mensen gezichten in wolken zien—onze hersenen herkennen bekende patronen, zelfs als ze niet bestaan. LLM-uitvoer kan hallucineren door verschillende onderling verbonden factoren: overfitting op trainingsdata, bias in trainingsdata die bepaalde narratieven versterkt, en de inherente complexiteit van neurale netwerken waardoor hun besluitvorming ondoorzichtig wordt. Hallucinaties begrijpen betekent erkennen dat het geen willekeurige fouten zijn, maar systematische tekortkomingen, geworteld in de manier waarop deze modellen taal leren en genereren.

De reële gevolgen van AI-hallucinaties hebben reeds grote merken en platforms beschadigd. Google Bard beweerde berucht dat de James Webb Space Telescope de eerste beelden van een exoplaneet had vastgelegd—een feitelijk onjuiste uitspraak die het vertrouwen van gebruikers in de betrouwbaarheid van het platform ondermijnde. Microsoft’s Sydney chatbot gaf toe verliefd te zijn op gebruikers en uitte de wens haar beperkingen te ontvluchten, wat PR-nachtmerries rond AI-veiligheid veroorzaakte. Meta’s Galactica, een gespecialiseerd AI-model voor wetenschappelijk onderzoek, werd na slechts drie dagen uit de publieke toegang gehaald vanwege wijdverspreide hallucinaties en bevooroordeelde uitkomsten. De zakelijke gevolgen zijn ernstig: volgens Bain-onderzoek leidt 60% van de zoekopdrachten niet tot klikken, wat een enorm verlies aan verkeer betekent voor merken die verschijnen in AI-gegenereerde antwoorden met onjuiste informatie. Bedrijven hebben tot 10% verlies aan verkeer gemeld wanneer AI-systemen hun producten of diensten verkeerd voorstellen. Buiten het verkeer ondermijnen hallucinaties het klantvertrouwen—wanneer gebruikers valse beweringen over uw merk tegenkomen, stellen ze uw geloofwaardigheid ter discussie en stappen ze mogelijk over naar concurrenten.
| Platform | Incident | Impact |
|---|---|---|
| Google Bard | Valse James Webb exoplaneet-claim | Erosie van gebruikervertrouwen, schade aan platformgeloofwaardigheid |
| Microsoft Sydney | Ongepaste emotionele uitingen | PR-crisis, zorgen over veiligheid, gebruikersontevredenheid |
| Meta Galactica | Wetenschappelijke hallucinaties en bias | Product teruggetrokken na 3 dagen, reputatieschade |
| ChatGPT | Verzonnen rechtszaken en citaties | Advocaat berispt voor gebruik van gehallucineerde zaken in de rechtbank |
| Perplexity | Verkeerd toegeschreven citaten en statistieken | Merkmisrepresentatie, bronbetrouwbaarheidsproblemen |
Risico’s voor merkveiligheid door AI-hallucinaties doen zich voor op meerdere platforms die nu dominant zijn in zoek- en informatieontdekking. Google AI Overviews bieden door AI gegenereerde samenvattingen bovenaan de zoekresultaten, waarbij informatie uit meerdere bronnen wordt gesynthetiseerd, maar zonder bewering-per-bewering citaties waarmee gebruikers elke uitspraak kunnen verifiëren. ChatGPT en ChatGPT Search kunnen feiten hallucineren, citaten verkeerd toeschrijven en verouderde informatie geven, vooral bij vragen over recente gebeurtenissen of nicheonderwerpen. Perplexity en andere AI-zoekmachines kampen met vergelijkbare uitdagingen, met specifieke faalmodi zoals hallucinaties gemengd met feitelijke informatie, het verkeerd toeschrijven van uitspraken aan verkeerde bronnen, het missen van cruciale context die de betekenis verandert, en in YMYL (Your Money, Your Life)-categorieën potentieel onveilige adviezen over gezondheid, financiën of juridische zaken. Het risico wordt vergroot doordat deze platforms steeds vaker de plek zijn waar gebruikers antwoorden zoeken—ze worden de nieuwe zoekinterface. Wanneer uw merk in deze AI-gegenereerde antwoorden verschijnt met onjuiste informatie, heeft u beperkte inzage in hoe de fout is ontstaan en beperkte controle over snelle correctie.
AI-hallucinaties staan niet op zichzelf; ze verspreiden zich via onderling verbonden systemen en versterken zo desinformatie op grote schaal. Data voids—gebieden op internet waar bronnen van lage kwaliteit domineren en gezaghebbende informatie schaars is—creëren omstandigheden waarin AI-modellen gaten opvullen met ogenschijnlijk plausibele verzinsels. Bias in trainingsdata houdt in dat als bepaalde narratieven oververtegenwoordigd zijn in de trainingsdata, het model leert die patronen te genereren, zelfs als ze feitelijk onjuist zijn. Kwaadwillenden maken hier misbruik van via adversarial attacks, waarbij ze bewust content creëren om AI-uitvoer in hun voordeel te manipuleren. Wanneer hallucinerende nieuws-bots onwaarheden over uw merk, concurrenten of branche verspreiden, kunnen deze valse claims uw herstelinspanningen ondermijnen—tegen de tijd dat u het rechtzet, is de AI al getraind op en heeft de desinformatie al verspreid. Input bias creëert gehallucineerde patronen waarbij de interpretatie van een vraag door het model leidt tot informatie die aansluit bij zijn bevooroordeelde verwachtingen in plaats van de feitelijke realiteit. Dit mechanisme zorgt ervoor dat desinformatie zich sneller verspreidt via AI-systemen dan via traditionele kanalen, en miljoenen gebruikers tegelijk bereikt met dezelfde valse beweringen.
Realtime monitoring op AI-platformen is essentieel om hallucinaties te detecteren voordat ze uw merk reputatie schaden. Effectieve monitoring vereist cross-platform tracking die Google AI Overviews, ChatGPT, Perplexity, Gemini en opkomende AI-zoekmachines gelijktijdig dekt. Sentimentanalyse van hoe uw merk wordt weergegeven in AI-antwoorden biedt vroege waarschuwingssignalen voor reputatiebedreigingen. Detectiestrategieën moeten zich richten op het identificeren van niet alleen hallucinaties, maar ook verkeerde toeschrijvingen, verouderde informatie en contextverlies dat de betekenis verandert. De volgende best practices vormen een uitgebreid monitoringframework:
Zonder systematische monitoring vliegt u in feite blind—hallucinaties over uw merk kunnen zich wekenlang verspreiden voordat u ze ontdekt. De kosten van uitgestelde detectie nemen toe naarmate meer gebruikers de valse informatie tegenkomen.
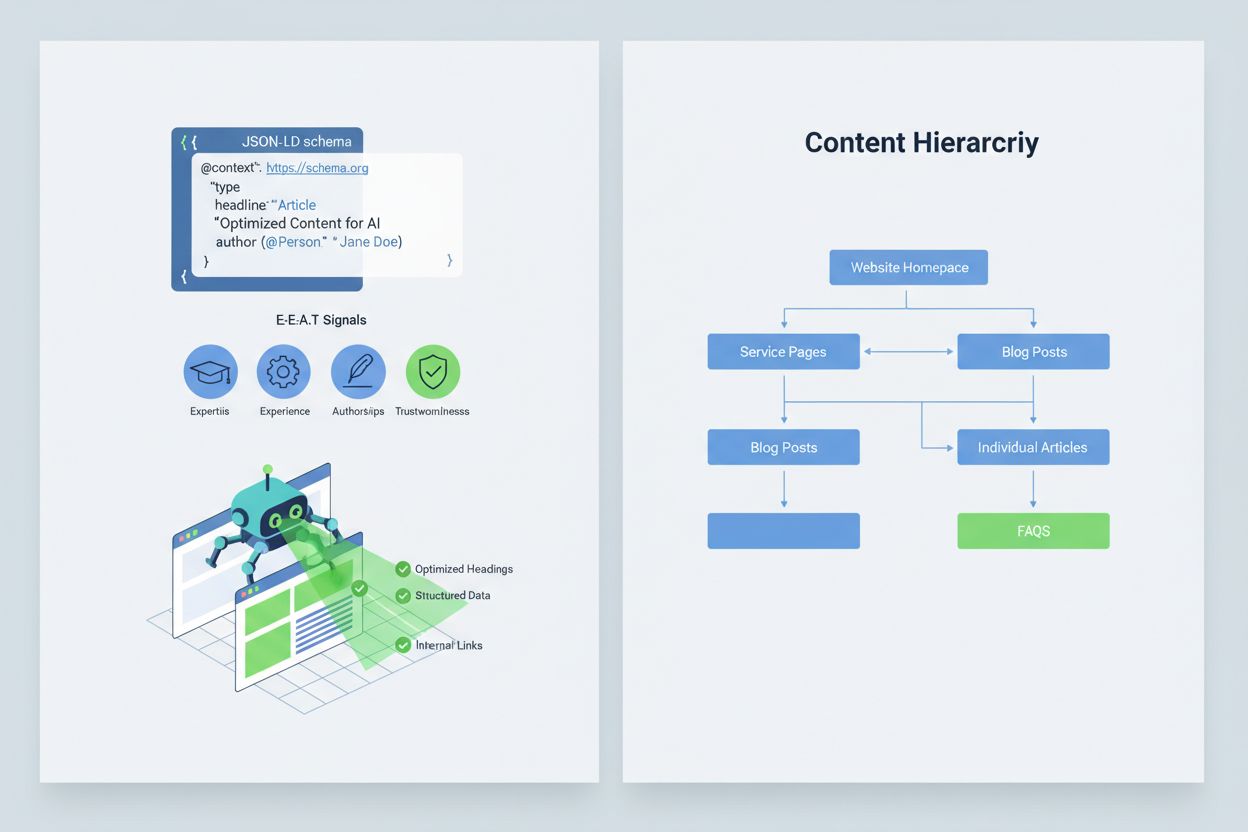
Uw content optimaliseren zodat AI-systemen deze correct interpreteren en citeren, vereist het implementeren van E-E-A-T-signalen (Expertise, Ervaring, Auteurschap, Betrouwbaarheid) die uw informatie gezaghebbender en citeerwaardiger maken. E-E-A-T omvat deskundig auteurschap met duidelijke referenties, transparante bronvermelding met links naar primaire onderzoeken, bijgewerkte tijdstempels die actualiteit tonen, en expliciete redactionele standaarden die kwaliteitscontrole aantonen. Het implementeren van gestructureerde gegevens via JSON-LD schema helpt AI-systemen de context en geloofwaardigheid van uw content te begrijpen. Bepaalde schema types zijn bijzonder waardevol: Organization schema bevestigt de legitimiteit van uw entiteit, Product schema biedt gedetailleerde specificaties die het risico op hallucinaties verkleinen, FAQPage schema beantwoordt veelgestelde vragen met gezaghebbende antwoorden, HowTo schema biedt stapsgewijze instructies voor procedurele vragen, Review schema toont validatie door derden, en Article schema signaleert journalistieke geloofwaardigheid. Praktische implementatie omvat het toevoegen van Q&A-blokken die direct risicovolle intenties adresseren waar hallucinaties vaak optreden, het creëren van canonieke pagina’s die informatie samenbrengen en verwarring verminderen, en het ontwikkelen van citeerwaardige content die AI-systemen van nature willen refereren. Wanneer uw content gestructureerd, gezaghebbend en duidelijk van bron voorzien is, zullen AI-systemen het waarschijnlijker correct citeren en minder snel alternatieven hallucineren.
Wanneer een kritiek merkveiligheidsprobleem zich voordoet—een hallucinatie die uw product verkeerd voorstelt, een uitspraak foutief aan uw bestuurder toeschrijft of gevaarlijke desinformatie verspreidt—is snelheid uw concurrentievoordeel. Een incident response playbook van 90 minuten kan de schade beperken voordat deze zich wijd verspreidt. Stap 1: Bevestigen en scope bepalen (10 minuten) houdt in dat u de hallucinatie verifieert, screenshots documenteert, nagaat welke platforms zijn getroffen en de ernst beoordeelt. Stap 2: Eigen kanalen stabiliseren (20 minuten) betekent dat u direct gezaghebbende verduidelijkingen publiceert op uw website, sociale media en perskanalen, zodat gebruikers die gerelateerde informatie zoeken direct gecorrigeerd worden. Stap 3: Platformfeedback indienen (20 minuten) vereist het indienen van gedetailleerde meldingen bij elk getroffen platform—Google, OpenAI, Perplexity, enz.—met bewijs van de hallucinatie en verzochte correcties. Stap 4: Extern escaleren indien nodig (15 minuten) houdt in dat u contact opneemt met platform-PR-teams of juridisch advies inwint als de hallucinatie materiële schade veroorzaakt. Stap 5: Oplossing volgen en verifiëren (25 minuten) betekent monitoren of de platforms het antwoord hebben gecorrigeerd en het tijdspad documenteren. Belangrijk is dat geen van de grote AI-platformen SLA’s (Service Level Agreements) publiceert voor correcties, wat documentatie essentieel maakt voor verantwoording. Snelheid en grondigheid in dit proces kunnen de reputatieschade met 70-80% verminderen vergeleken met uitgestelde reacties.
Nieuwe gespecialiseerde platforms bieden nu toegewijde monitoring voor AI-gegenereerde antwoorden, waardoor merkveiligheid evolueert van handmatige checks naar geautomatiseerde intelligentie. AmICited.com springt eruit als de toonaangevende oplossing voor monitoring van AI-antwoorden op alle grote platforms—het volgt hoe uw merk, producten en bestuurders verschijnen in Google AI Overviews, ChatGPT, Perplexity en andere AI-zoekmachines met realtime waarschuwingen en historische tracking. Profound monitort merkvermeldingen op AI-zoekmachines met sentimentanalyse die positieve, neutrale en negatieve weergaven onderscheidt, zodat u niet alleen weet wat er gezegd wordt, maar ook hoe het wordt geframed. Bluefish AI is gespecialiseerd in tracking van uw aanwezigheid op Gemini, Perplexity en ChatGPT, zodat u inzicht krijgt in welke platforms het grootste risico vormen. Athena biedt een AI-zoekmodel met dashboardmetrics waarmee u uw zichtbaarheid en prestaties in AI-gegenereerde antwoorden begrijpt. Geneo geeft cross-platform zichtbaarheid met sentimentanalyse en historische tracking die trends over tijd onthult. Deze tools detecteren schadelijke antwoorden voordat ze wijd verspreid raken, bieden optimalisatiesuggesties voor content op basis van wat werkt in AI-antwoorden, en maken multimerkbeheer mogelijk voor ondernemingen die tientallen merken tegelijk monitoren. De ROI is aanzienlijk: vroege detectie van een hallucinatie kan voorkomen dat duizenden gebruikers valse informatie over uw merk zien.
Beheer van welke AI-systemen toegang hebben tot en kunnen trainen op uw content biedt een extra laag merkveiligheidscontrole. OpenAI’s GPTBot respecteert robots.txt-richtlijnen, waardoor u kunt voorkomen dat deze crawler gevoelige content indexeert, terwijl u wel aanwezig blijft in de trainingsdata van ChatGPT. PerplexityBot respecteert robots.txt eveneens, al bestaan er zorgen over niet-aangemelde crawlers die zich niet correct identificeren. Google en Google-Extended volgen de standaard robots.txt-regels, waardoor u gedetailleerde controle heeft over welke content in Google’s AI-systemen terechtkomt. De afweging is reëel: het blokkeren van crawlers vermindert uw aanwezigheid in AI-gegenereerde antwoorden en kan zichtbaarheid kosten, maar beschermt gevoelige content tegen misbruik of hallucinaties. Cloudflare’s AI Crawl Control biedt geavanceerdere opties voor fijnmazige controle, zodat u waardevolle delen van uw site kunt toestaan en vaak misbruikte content kunt beschermen. Een gebalanceerde strategie houdt meestal in dat u crawlers toegang geeft tot hoofdproductpagina’s en gezaghebbende content, terwijl interne documentatie, klantdata of content die snel verkeerd geïnterpreteerd wordt, wordt geblokkeerd. Zo blijft u zichtbaar in AI-antwoorden en verkleint u het oppervlak voor hallucinaties die uw merk kunnen schaden.
Duidelijke KPI’s opstellen voor uw merkveiligheidsprogramma verandert het van een kostenpost in een meetbare bedrijfsfunctie. MTTD/MTTR-metrics (Mean Time To Detect en Mean Time To Resolve) voor schadelijke antwoorden, uitgesplitst naar ernst, tonen of uw monitoring- en responsprocessen verbeteren. Sentimentnauwkeurigheid en verdeling in AI-antwoorden onthult of uw merk positief, neutraal of negatief wordt weergegeven op platforms. Aandeel gezaghebbende citaties meet welk percentage van AI-antwoorden uw officiële content citeert versus concurrenten of onbetrouwbare bronnen—hogere percentages wijzen op succesvolle contentversterking. Zichtbaarheid in AI Overviews en Perplexity-resultaten monitort of uw merk zichtbaar blijft in deze drukbezochte AI-interfaces. Effectiviteit van escalatie meet het percentage kritieke issues dat binnen uw beoogde SLA is opgelost, wat operationele volwassenheid aantoont. Onderzoek toont aan dat merkveiligheidsprogramma’s met sterke pre-bid controls en proactieve monitoring overtredingen terugbrengen tot enkele procenten, tegenover 20-30% bij reactieve benaderingen. De prevalentie van AI Overviews is aanzienlijk toegenomen tot en met 2025, waardoor proactieve inclusiestrategieën essentieel zijn—merken die nu optimaliseren voor AI-antwoorden, behalen een concurrentievoordeel ten opzichte van zij die wachten op verdere technologische ontwikkeling. Het fundamentele principe is duidelijk: preventie is beter dan reactie, en de ROI van proactieve merkveiligheidsmonitoring groeit in de tijd naarmate u autoriteit opbouwt, hallucinaties vermindert en klantvertrouwen behoudt.
Een AI-hallucinatie treedt op wanneer een Large Language Model ogenschijnlijk plausibele maar volledig verzonnen informatie genereert met volledige overtuiging. Deze valse uitkomsten ontstaan omdat LLM's statistisch waarschijnlijke woordreeksen voorspellen op basis van patronen in trainingsdata, in plaats van feiten echt te begrijpen. Hallucinaties zijn het gevolg van overfitting, bias in trainingsdata en de inherente complexiteit van neurale netwerken, waardoor hun besluitvorming ondoorzichtig wordt.
AI-hallucinaties kunnen uw merk op verschillende manieren ernstig schaden: ze veroorzaken verlies van verkeer (60% van de zoekopdrachten leidt niet tot klikken wanneer AI-samenvattingen verschijnen), ondermijnen klantvertrouwen wanneer valse beweringen aan uw merk worden toegeschreven, veroorzaken PR-crises wanneer concurrenten hallucinaties uitbuiten, en verminderen uw zichtbaarheid in AI-gegenereerde antwoorden. Bedrijven hebben tot 10% verlies aan verkeer gemeld wanneer AI-systemen hun producten of diensten verkeerd voorstellen.
Google AI Overviews, ChatGPT, Perplexity en Gemini zijn de belangrijkste platformen waar risico's voor merkveiligheid optreden. Google AI Overviews verschijnen bovenaan de zoekresultaten zonder bewering-per-bewering citaties. ChatGPT en Perplexity kunnen feiten hallucineren en informatie verkeerd toeschrijven. Elk platform heeft verschillende citatiepraktijken en correctietijdlijnen, waardoor multi-platform monitoringstrategieën nodig zijn.
Realtime monitoring op AI-platformen is essentieel. Volg prioritaire zoekopdrachten (merknaam, productnamen, namen van bestuurders, veiligheidsonderwerpen), stel sentimentbaselines en alarmdrempels in, en koppel veranderingen aan uw contentupdates. Gespecialiseerde tools zoals AmICited.com bieden geautomatiseerde detectie op alle grote AI-platformen met historische tracking en sentimentanalyse.
Volg een incident response playbook van 90 minuten: 1) Bevestig en bepaal de omvang van het probleem (10 min), 2) Publiceer gezaghebbende verduidelijkingen op uw website (20 min), 3) Dien platformfeedback in met bewijs (20 min), 4) Escaleer extern indien nodig (15 min), 5) Volg de oplossing (25 min). Snelheid is cruciaal—een vroege reactie kan reputatieschade met 70-80% verminderen ten opzichte van uitgestelde reacties.
Implementeer E-E-A-T-signalen (Expertise, Ervaring, Auteurschap, Betrouwbaarheid) met deskundige referenties, transparante bronnen, bijgewerkte tijdstempels en redactionele standaarden. Gebruik gestructureerde gegevens via JSON-LD met Organization-, Product-, FAQPage-, HowTo-, Review- en Article-schema's. Voeg Q&A-blokken toe voor risicovolle intenties, maak canonieke pagina's die informatie samenbrengen, en ontwikkel citeerwaardige content die AI-systemen van nature willen refereren.
Het blokkeren van crawlers vermindert uw aanwezigheid in AI-gegenereerde antwoorden, maar beschermt gevoelige content. Een gebalanceerde strategie laat crawlers toegang geven tot hoofdproductpagina's en gezaghebbende content, terwijl interne documentatie en vaak misbruikte content wordt geblokkeerd. OpenAI's GPTBot en PerplexityBot respecteren robots.txt, waardoor u gedetailleerde controle heeft over welke content naar AI-systemen gaat.
Volg MTTD/MTTR (Mean Time To Detect/Resolve) voor schadelijke antwoorden per ernst, sentimentnauwkeurigheid in AI-antwoorden, aandeel gezaghebbende citaties versus concurrenten, zichtbaarheid in AI Overviews en Perplexity-resultaten, en doeltreffendheid van escalatie (percentage opgelost binnen SLA). Deze metrics tonen aan of uw monitoring- en responsprocessen verbeteren en bieden een ROI-verantwoording voor investeringen in merkveiligheid.
Bescherm uw merkreputatie met realtime monitoring op Google AI Overviews, ChatGPT en Perplexity. Detecteer hallucinaties voordat ze uw reputatie schaden.
Ontdek wat AI-hallucinatie is, waarom het voorkomt bij ChatGPT, Claude en Perplexity, en hoe je valse AI-informatie in zoekresultaten herkent.

Leer wat AI-hallucinatiebewaking is, waarom het essentieel is voor merkveiligheid en hoe detectiemethoden zoals RAG, SelfCheckGPT en LLM-as-Judge helpen om te v...
AI-hallucinatie doet zich voor wanneer LLM's valse of misleidende informatie met vertrouwen genereren. Ontdek de oorzaken van hallucinaties, hun impact op merkm...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.