
Data-Driven PR: Onderzoek creëren dat AI wil citeren
Leer hoe je origineel onderzoek en data-gedreven PR-content creëert die actief door AI-systemen wordt geciteerd. Ontdek de 5 eigenschappen van citeerwaardige co...
8 min lezen
Leer hoe je originele data en onderzoek creëert die actief door AI-systemen geciteerd worden. Ontdek strategieën om je data vindbaar te maken voor ChatGPT, Perplexity, Google Gemini en Claude, terwijl je duurzame AI-zichtbaarheid opbouwt.
In het tijdperk van kunstmatige intelligentie is originele data het nieuwe concurrentievoordeel geworden voor merken die zichtbaarheid zoeken buiten traditionele zoekranglijsten. Nu AI-platforms zoals ChatGPT, Perplexity, Google Gemini en Claude steeds vaker bepalen hoe doelgroepen informatie vinden, zijn de regels voor zichtbaarheid fundamenteel veranderd. In plaats van te concurreren om positie nul in de zoekresultaten van Google, moeten organisaties nu data creëren die AI-systemen actief willen citeren en refereren. Deze transformatie weerspiegelt een bredere verschuiving van contentgedreven SEO naar wat experts “Generative Engine Optimization” (GEO) noemen, waarbij AI-citatie traditionele ranking heeft vervangen als primaire zichtbaarheidsgraadmeter. Platforms die informatie omzetten in directe antwoorden—of dat nu via retrieval-augmented generation (RAG) of model-native synthese is—geven van nature de voorkeur aan bronnen die duidelijke, extraheerbare en gezaghebbende originele onderzoeken bieden. Organisaties die deze verschuiving begrijpen en investeren in het creëren van originele data, eigen onderzoek en unieke inzichten, positioneren zichzelf om gelijktijdig citaties te verdienen op meerdere AI-platforms. Zo genereren ze bewustzijn en geloofwaardigheid bij doelgroepen die traditionele zoekresultaten misschien nooit zien.

Verschillende AI-platforms gebruiken fundamenteel verschillende architecturen voor het ontdekken en citeren van bronnen, wat direct invloed heeft op hoe je originele data wordt gevonden en erkend. Deze mechanismen begrijpen is essentieel om de zichtbaarheid van je content te optimaliseren in het AI-landschap. Het verschil tussen model-native synthese (waar AI antwoorden genereert uit patronen in trainingsdata) en retrieval-augmented generation (waar AI live bronnen doorzoekt en syntheseert uit opgehaalde resultaten) verklaart waarom sommige platforms expliciete citaties geven, terwijl andere antwoorden bieden zonder bronvermelding. Platforms die RAG-systemen gebruiken, kunnen hun antwoorden herleiden tot specifieke bronnen, waardoor citeren eenvoudig en traceerbaar is. Omgekeerd vertrouwen model-native systemen op probabilistische kennis uit de training, waardoor bronvermelding moeilijk of onmogelijk is zonder extra plug-ins of integraties.
| AI-platform | Citatiewijze | Data Bron Prioriteit | Zichtbaarheidseffect |
|---|---|---|---|
| ChatGPT | Model-native (standaard); gekoppelde citaties met plugins/browsen ingeschakeld | Trainingsdata + live web wanneer ingeschakeld; geeft voorrang aan recente, gezaghebbende bronnen bij actieve retrieval | Laag zonder plugins; matig met zoeken ingeschakeld; citaties verschijnen in antwoordtekst indien beschikbaar |
| Perplexity | Retrieval-first met inline genummerde citaties | Live web zoekresultaten; geeft voorrang aan actuele, direct relevante bronnen; benadrukt bronprominentie | Hoog; genummerde citaties met duidelijke bronlinks; eerste-positie bronnen ontvangen onevenredig veel verkeer |
| Google Gemini | Geïntegreerd met Google Zoeken en Knowledge Graph | Live geïndexeerde pagina’s + Knowledge Graph entiteiten; geeft voorrang aan pagina’s met gestructureerde data en E-E-A-T signalen | Hoog; citaties verschijnen als bronlinks in AI Overviews; gestructureerde data verhoogt citatiekans |
| Claude | Model-native (standaard); zoekmogelijkheden op het web uitgerold in 2025 | Trainingsdata + selectieve live web search; geeft prioriteit aan veilig-gecontroleerde, gezaghebbende bronnen | Matig; citaties verschijnen bij ingeschakelde web search; nadruk op nauwkeurigheid en broncredibiliteit |
De praktische implicaties zijn groot: platforms zoals Perplexity en Google Gemini, die actief het live web doorzoeken, kunnen je content direct na publicatie citeren als deze aan hun kwaliteits- en relevantie-eisen voldoet. ChatGPT en Claude, die sterker op trainingsdata leunen, nemen je originele onderzoek mogelijk later op, maar bieden via plugins en integraties weer andere zichtbaarheid. Voor contentmakers betekent dit: begrijpen welke platforms je doelgroep gebruikt en je data daarop optimaliseren—of dat nu extraheerbare, goed gestructureerde content is voor Perplexity’s live retrieval, of autoriteitssignalen die worden meegenomen in trainingsdata voor model-native systemen.
Gestructureerde data is van een handige SEO-tactiek uitgegroeid tot een strategische noodzaak voor AI-zichtbaarheid. Door schema markup te implementeren met Schema.org-vocabulaire, help je niet alleen Google je content te begrijpen—je creëert ook een machine-leesbare laag waarop AI-systemen hun antwoorden betrouwbaar kunnen baseren. Deze gestructureerde datalaag, vaak een “content knowledge graph” genoemd, definieert expliciet entiteiten (personen, producten, diensten, locaties, organisaties) en hun onderlinge relaties, waardoor het voor AI-systemen veel makkelijker wordt om te begrijpen wie je merk is, wat je aanbiedt en hoe je begrepen moet worden. Volgens recent onderzoek van BrightEdge toonden pagina’s met sterke schema markup hogere citatiecijfers in Google’s AI Overviews, wat suggereert dat gestructureerde data direct de kans op citatie beïnvloedt. Het opkomende Model Context Protocol (MCP), aangenomen door zowel OpenAI als Google DeepMind, vormt de volgende evolutie—feitelijk een gestandaardiseerde API om AI-modellen te koppelen aan gestructureerde databronnen. Door schema markup op schaal te implementeren, leggen ondernemingen een fundament dat hallucinaties in AI-antwoorden vermindert, betere feitelijke onderbouwing biedt en hun data beter vindbaar maakt in retrieval-systemen. Dit is vooral belangrijk omdat AI-systemen die uitsluitend op ongestructureerde tekst zijn getraind, vaak moeite hebben met nauwkeurigheid; gestructureerde data biedt de contextuele helderheid die LLM’s nodig hebben om betrouwbaardere, herleidbare antwoorden te genereren die je originele onderzoek vol vertrouwen citeren.

De meest effectieve strategie om AI-citaties te verdienen is originele data creëren die van nature extraheerbaar, gezaghebbend en afgestemd is op hoe AI-systemen informatie ophalen en samenvoegen. In plaats van te hopen dat je bestaande content geciteerd wordt, moet je doelgericht dataprodukten ontwerpen die AI-platforms eenvoudig kunnen vinden, begrijpen en refereren. Dit zijn de kernstrategieën voor het creëren van citatiewaardige originele data:
Voer origineel onderzoek uit met transparante methodologie: AI-systemen geven prioriteit aan bronnen die blijk geven van degelijk onderzoek. Publiceer studies, enquêtes en analyses met duidelijk gedocumenteerde methodologieën, steekproefgroottes en beperkingen. Als je je werkwijze toont, kunnen AI-platforms je bevindingen met vertrouwen citeren als gezaghebbend. Voorbeelden zijn branche-benchmarks, klantgedragsonderzoeken, marktonderzoek en eigen data-analyses die concurrenten niet kunnen evenaren.
Maak data extraheerbaar via gestructureerde formaten: AI-systemen geven de voorkeur aan content in tabellen, lijsten, vergelijkingsmatrices en FAQ-stijl vraag-antwoordparen boven compacte tekstblokken. Een vergelijkingstabel van concurrerende functies wordt veel eerder geciteerd dan dezelfde informatie verstopt in proza. Gebruik koppen, opsommingstekens en visuele hiërarchie, zodat kerninzichten direct scanbaar en door AI-systemen te vinden zijn.
Zorg voor actualiteitssignalen en recente data: AI-platforms, vooral die met live retrieval, geven voorrang aan actuele informatie. Voeg zichtbare publicatiedata, update-tijdstempels en regelmatige contentvernieuwingen toe. Door te laten zien dat je data actueel en onderhouden is, beschouwen AI-systemen het als betrouwbaarder dan verouderde bronnen. Dit is vooral cruciaal voor tijdgevoelige data zoals prijzen, statistieken en markttrends.
Bouw auteurs- en merkautoriteit op: AI-systemen beoordelen broncredibiliteit voordat ze citeren. Bouw heldere auteurskwalificaties (inclusief bio’s met relevante expertise), organisatieautoriteit (backlinks, media-aandacht, branche-erkenning) en domeinexpertise-signalen. Als je merk erkend wordt als autoriteit in je categorie, citeren AI-systemen je vaker en prominenter.
Gebruik duidelijke entiteitdefinities en relaties: Definieer belangrijke entiteiten expliciet—je bedrijf, producten, diensten, teamleden en branchebegrippen. Gebruik gestructureerde data om relaties tussen deze entiteiten vast te leggen. Als een AI-systeem precies begrijpt wat je bent en hoe je je verhoudt tot bredere branchebegrippen, kan het je nauwkeuriger en in context citeren.
Implementeer goede bronvermelding en attributie: Als je originele data voortbouwt op andere bronnen, citeer deze dan transparant. AI-systemen herkennen en belonen bronnen die hun eigen bronnen erkennen. Dit creëert een keten van attributie die het vertrouwen en de kans op citatie in het hele ecosysteem vergroot.
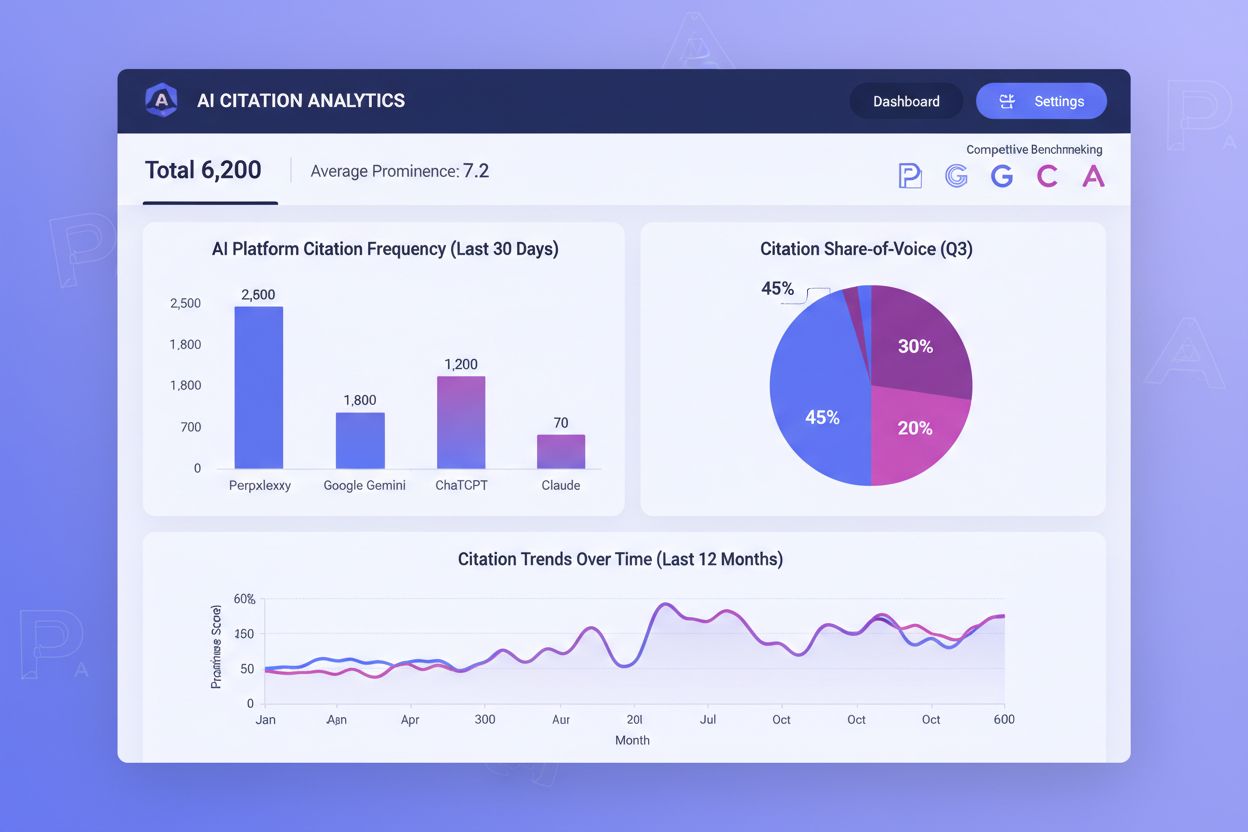
AI-citaties volgen is net zo belangrijk geworden als het monitoren van traditionele zoekranglijsten, maar de meeste organisaties hebben geen inzicht in hoe vaak hun content geciteerd wordt op AI-platforms. Citatie frequentie, citatie prominentie en share-of-voice zijn de drie kernstatistieken die je succes in AI-ontdekking bepalen. Citatie frequentie meet hoe vaak je content verschijnt in AI-antwoorden op je doelzoekopdrachten—als je op 40% van de relevante prompts wordt geciteerd terwijl concurrenten op 60% zitten, is er een duidelijk optimalisatiegat. Citatie prominentie telt zelfs nog zwaarder: een eerste-positie citatie in de genummerde lijst van Perplexity levert onevenredig veel zichtbaarheid op ten opzichte van een citatie op de vijfde positie. Share-of-voice toont je concurrentiepositie—als je merk citaties krijgt op 25% van de categorie-bepalende zoekopdrachten, terwijl je grootste concurrent op 50% zit, verlies je veel zichtbaarheid.
Tools zoals AmICited.com zijn onmisbare oplossingen geworden om AI-citaties op platforms te monitoren. Deze platforms volgen welke van je pagina’s citaties verdienen op Perplexity, Google AI Overviews, ChatGPT met zoeken en andere AI-systemen, zodat je ziet welke content daadwerkelijk AI-zichtbaarheid oplevert. Door citatiepatronen in de tijd te volgen, kun je ontdekken welke contentsoorten, onderwerpen en formaten de meeste citaties genereren en die succesvolle strategieën herhalen. Concurrentie-benchmarking via deze tools laat precies zien waar je citaties aan concurrenten verliest, zodat je gericht kunt optimaliseren. De data laat zien of je citatie-uitdagingen universeel zijn over alle AI-platforms of specifiek voor bepaalde systemen—als je vaak wordt geciteerd op Perplexity maar zelden op Google AI Overviews, moet je optimalisatiestrategie daarop aangepast worden. Positiegewogen statistieken erkennen dat vroege citaties meer waarde opleveren; een tool die eerste-positie citaties zwaarder laat meetellen dan lager geplaatste citaties geeft bruikbaardere inzichten dan ruwe aantallen. Door AI-citatiemonitoring als vast onderdeel van je contentstrategie te behandelen, kun je je originele data continu optimaliseren om zowel citatiefrequentie als prominentie te verhogen, wat direct je zichtbaarheid in een AI-gedreven zoeklandschap verbetert.
Originele data creëren die AI-citaties oplevert, kan geen eenmalig project zijn—het vereist het opbouwen van een duurzame, multidisciplinaire datastrategie waarbij data wordt gezien als een strategisch bedrijfsmiddel dat blijvende investeringen en governance verdient. Organisaties die succesvol zijn in AI-zichtbaarheid, implementeren gestructureerde processen voor continue data-updates, zodat origineel onderzoek actueel en relevant blijft. Dit betekent het instellen van vaste vernieuwing-cycli voor kern datasets, statistieken bijwerken zodra er nieuwe informatie is, en de actualiteitssignalen onderhouden die AI-systemen gebruiken om broncredibiliteit te beoordelen. Naast contentupdates stemmen succesvolle organisaties hun datastrategie af tussen marketing, SEO, content, product en datateams via entiteit governance—gedeelde definities en taxonomieën die zorgen voor consistente, accurate representatie van je merk, producten en branchebegrippen in alle kanalen.
De meest geavanceerde aanpak behandelt gestructureerde data en content knowledge graphs als infrastructuur voor de hele onderneming. In plaats van schema markup per pagina toe te voegen, bouwen koplopers volledige content knowledge graphs die alle entiteiten, onderwerpen en relaties over hun digitale domeinen verbinden. Dit vereist technische capaciteit—tools en processen om schema markup op schaal te beheren—en organisatiebrede afspraken over datakwaliteit. Goed gestructureerd dient deze infrastructuur een dubbel doel: het verbetert externe AI-zichtbaarheid én ondersteunt interne AI-initiatieven. Volgens het Gartner 2024 AI Mandates for the Enterprise Survey vormen data-beschikbaarheid en kwaliteit de grootste belemmering voor succesvolle AI-implementatie; door te investeren in gestructureerde data en entiteit governance los je externe zichtbaarheid én interne AI-uitdagingen tegelijk op. De organisaties die winnen in AI-zichtbaarheid behandelen originele datacreatie niet als marketingtactiek, maar als een fundamentele bedrijfscompetentie, met toegewijde middelen, heldere verantwoordelijkheden en voortdurende optimalisatie op basis van citatiemonitoring en concurrentie-benchmarking.
Originele data verwijst naar eigen onderzoek, unieke datasets en primaire bevindingen die je zelf hebt gecreëerd of ontdekt. AI-systemen geven prioriteit aan originele data omdat deze gezaghebbende, extraheerbare informatie biedt die ze met vertrouwen kunnen citeren. Gewone content synthetiseert vaak bestaande informatie, waardoor het minder waardevol is voor AI-citatie. Originele data vormt de basis voor AI-zichtbaarheid omdat platforms zoals Perplexity en Google Gemini actief zoeken naar en citeren uit bronnen die unieke inzichten en onderzoek aanbieden.
Verschillende AI-platforms gebruiken verschillende ontdekkingstechnieken. Perplexity en Google Gemini gebruiken retrieval-augmented generation (RAG), wat betekent dat ze het live web doorzoeken en je content direct na publicatie kunnen citeren. ChatGPT en Claude vertrouwen meer op trainingsdata, dus het kan langer duren voordat je content wordt opgenomen, maar het biedt andere zichtbaarheidskansen. Alle platforms profiteren van gestructureerde data (schema markup) die je data machine-leesbaar en beter begrijpbaar maakt, waardoor de kans op citatie bij alle systemen toeneemt.
Gestructureerde data met behulp van Schema.org-vocabulaire creëert een machine-leesbare laag waarop AI-systemen hun antwoorden betrouwbaar kunnen baseren. Wanneer je schema markup implementeert, definieer je expliciet entiteiten (je bedrijf, producten, diensten) en hun onderlinge relaties, waardoor het voor AI-systemen aanzienlijk eenvoudiger wordt om je content correct te begrijpen en te citeren. Onderzoek toont aan dat pagina’s met sterke schema markup hogere citatiecijfers krijgen in AI Overviews. Gestructureerde data vermindert ook hallucinaties door AI-systemen duidelijke, feitelijke informatie ter referentie te geven.
AI-systemen citeren het vaakst origineel onderzoek met transparante methodologie, eigen datasets, branche-benchmarks, onderzoeken naar klantgedrag, marktanalyses en unieke inzichten die concurrenten niet kunnen repliceren. Data in extraheerbare formaten—tabellen, vergelijkingsmatrices, lijsten en FAQ-stijl Q&A—ontvangt meer citaties dan dezelfde informatie in compacte alinea’s. Recente, actuele data met zichtbare publicatiedata en regelmatige updates krijgt voorrang boven verouderde informatie. Autoriteitssignalen zoals auteurskwalificaties en organisatieherkenning verhogen ook de kans op citatie.
Tools zoals AmICited.com volgen AI-citaties op verschillende platforms en laten zien hoe vaak je content verschijnt in antwoorden van ChatGPT, Perplexity, Google AI Overviews en Claude. Deze tools meten citatiefrequentie (hoe vaak je wordt geciteerd), citatieprominentie (positie in het antwoord) en share-of-voice (je citaties vergeleken met concurrenten). Door deze statistieken te monitoren, kun je zien welke contentsoorten en onderwerpen de meeste citaties genereren en vervolgens je datastrategie optimaliseren. Positiegewogen statistieken erkennen dat citaties op de eerste positie meer waarde opleveren dan lager geplaatste citaties.
Citatie frequentie meet hoe vaak je content wordt geciteerd in AI-antwoorden op je doelzoekopdrachten—als je op 40% van de relevante prompts wordt geciteerd, is dat je citatiefrequentie. Citatieprominentie meet waar je citatie verschijnt in het antwoord—een eerste-positie citatie in de genummerde lijst van Perplexity zorgt voor veel meer zichtbaarheid dan een citatie op de vijfde plaats. Beide statistieken zijn belangrijk voor AI-zichtbaarheid, maar prominentie telt vaak zwaarder omdat gebruikers eerder klikken of reageren op vroege citaties. Effectieve optimalisatie vereist dat beide statistieken tegelijk verbeterd worden.
Originele data moet regelmatig worden bijgewerkt volgens het tempo van verandering in je branche. Voor snel veranderende sectoren zoals technologie of financiën zijn maandelijkse of driemaandelijkse updates nodig. Voor trager bewegende sectoren kan jaarlijks bijwerken volstaan. Het belangrijkste is zichtbare actualiteitssignalen behouden—publicatiedata, update-tijdstempels en vernieuwing-indicatoren—die aan AI-systemen aangeven dat je data actueel en betrouwbaar is. Regelmatige updates verhogen ook je kans om geciteerd te worden door retrieval-systemen zoals Perplexity die de voorkeur geven aan actuele informatie. Behandel databeheer als een doorlopende operationele verantwoordelijkheid, niet als een eenmalig project.
Ja, AmICited.com bevat concurrentie-benchmarking functies waarmee je je citatieprestaties ten opzichte van gedefinieerde concurrenten kunt zien. Je ziet welke concurrenten vaker, op meer prominente posities en op welke AI-platforms worden geciteerd. Deze concurrentie-informatie laat precies zien waar je citaties verliest en welke optimalisatiestrategieën kunnen helpen terrein te winnen. Door inzicht te krijgen in je competitieve citatielandschap kun je je datacreatie en optimalisatie richten op de meest impactvolle kansen, zodat je originele data de zichtbaarheid krijgt die het verdient.
Volg hoe vaak je originele data geciteerd wordt op ChatGPT, Perplexity, Google AI Overviews en andere AI-platforms. Ontvang bruikbare inzichten om je content te optimaliseren voor maximale AI-zichtbaarheid.
Leer hoe je origineel onderzoek en data-gedreven PR-content creëert die actief door AI-systemen wordt geciteerd. Ontdek de 5 eigenschappen van citeerwaardige co...

Ontdek waarom het doen van origineel onderzoek cruciaal is voor AI-zichtbaarheid. Leer hoe origineel onderzoek ervoor zorgt dat je merk wordt geciteerd in AI-ge...
Ontdek hoe origineel onderzoek en first-party data zorgen voor een 30-40% zichtbaarheidsboost in AI-citaties bij ChatGPT, Perplexity en Google AI Overviews.
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.