Query Fanout
Ontdek hoe Query Fanout werkt in AI-zoeksystemen. Leer hoe AI enkele vragen uitbreidt naar meerdere subvragen om de nauwkeurigheid van antwoorden en het begrip ...
11 min lezen
Ontdek hoe moderne AI-systemen zoals Google AI-modus en ChatGPT één enkele zoekopdracht opsplitsen in meerdere zoekopdrachten. Leer query fanout-mechanismen, implicaties voor AI-zichtbaarheid en optimalisatie van contentstrategieën.
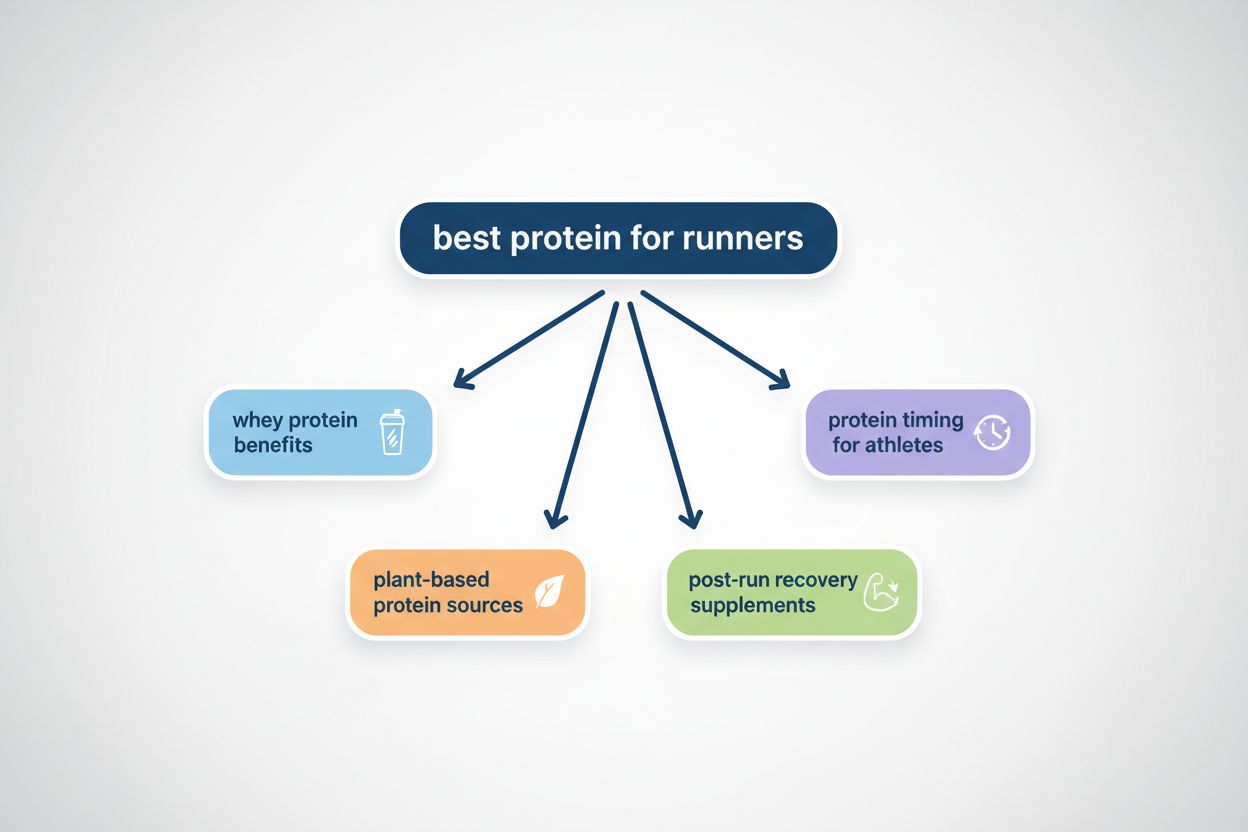
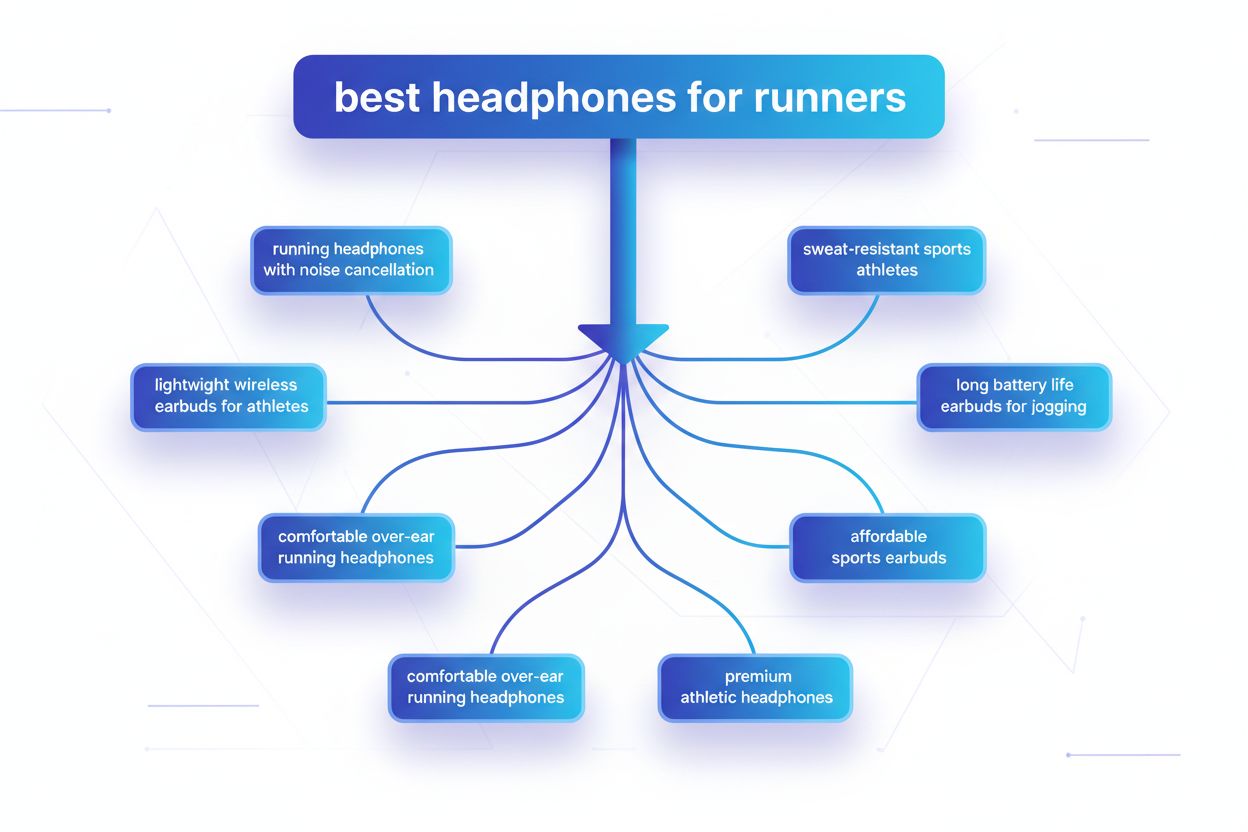
Query fanout is het proces waarbij grote taalmodellen automatisch één enkele gebruikersvraag opsplitsen in meerdere subvragen om meer uitgebreide informatie te verzamelen uit diverse bronnen. In plaats van één zoekopdracht uit te voeren, splitsen moderne AI-systemen de gebruikersintentie op in 5-15 gerelateerde zoekopdrachten die verschillende invalshoeken, interpretaties en aspecten van het oorspronkelijke verzoek omvatten. Wanneer een gebruiker bijvoorbeeld “beste koptelefoons voor hardlopers” zoekt in de AI-modus van Google, genereert het systeem ongeveer 8 verschillende zoekopdrachten, waaronder variaties als “hardloopkoptelefoons met noise cancelling,” “lichte draadloze oordopjes voor atleten,” “zweetbestendige sportkoptelefoons” en “oordopjes met lange batterijduur voor joggen.” Dit is een fundamenteel verschil met traditioneel zoeken, waarbij één querystring wordt vergeleken met een index. Belangrijke kenmerken van query fanout zijn:
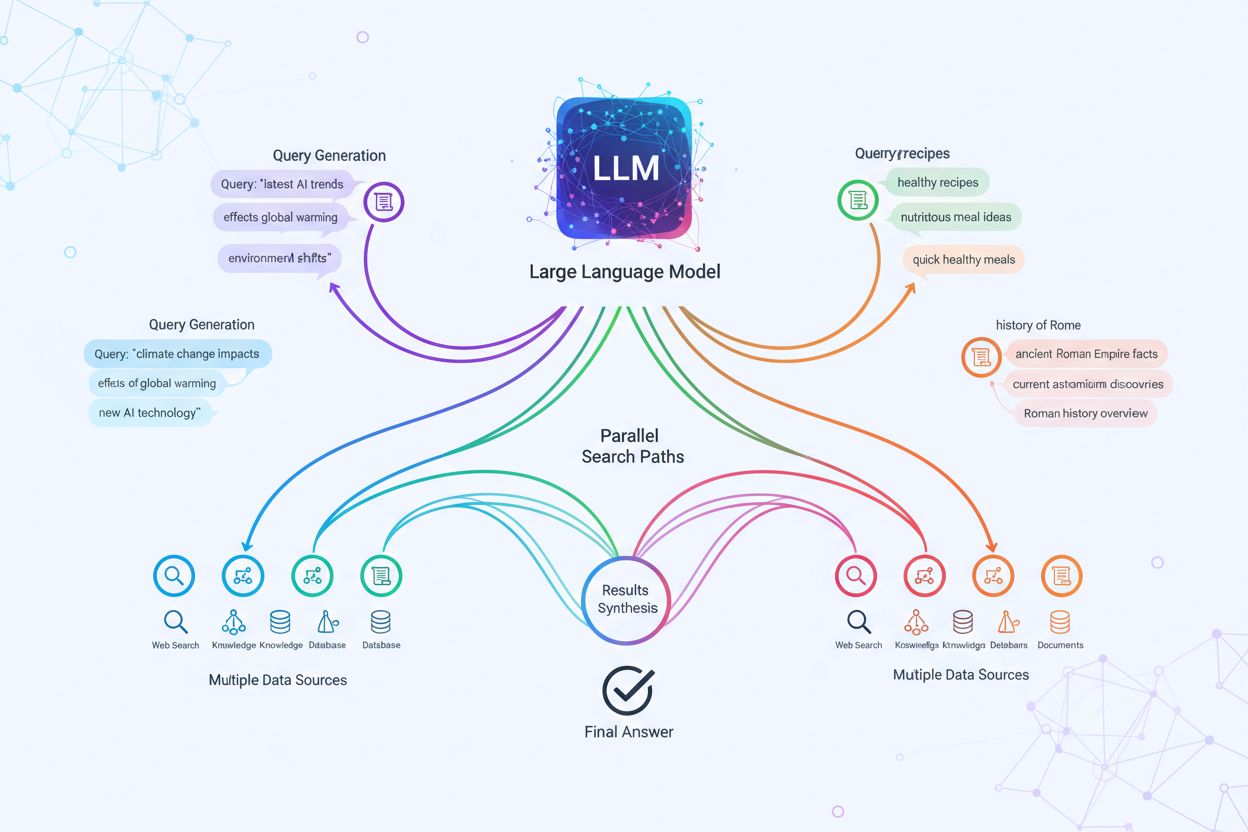
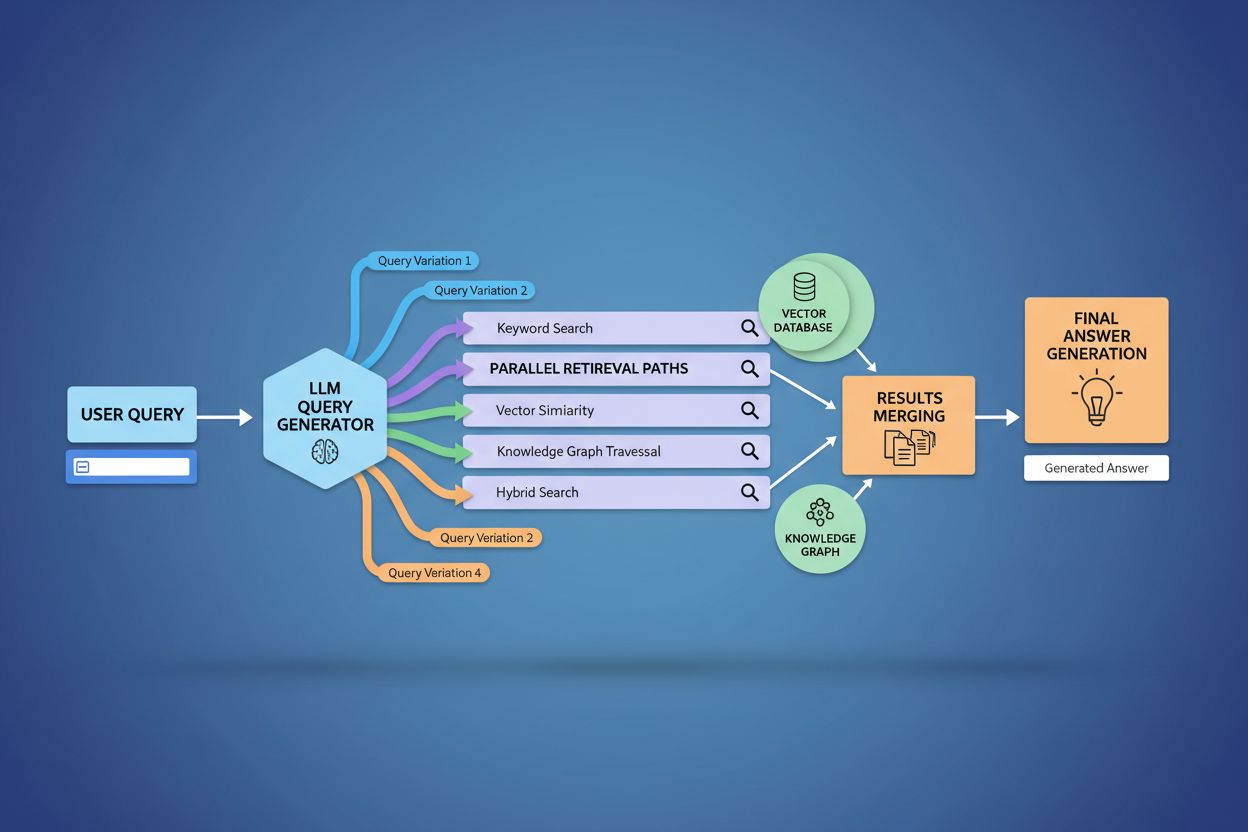
De technische implementatie van query fanout is afhankelijk van geavanceerde NLP-algoritmen die de complexiteit van zoekopdrachten analyseren en semantisch zinvolle varianten genereren. LLM’s produceren acht primaire typen queryvarianten: equivalente zoekopdrachten (herformulering met identieke betekenis), vervolgvragen (verkennen van gerelateerde onderwerpen), generalisatievragen (verbreden van de scope), specificatievragen (versmallen van de focus), canonisatievragen (standaardiseren van terminologie), vertaalvragen (omzetten tussen domeinen), entailment-vragen (logische implicaties verkennen) en verduidelijkingsvragen (ondubbelzinnig maken van onduidelijke termen). Het systeem gebruikt neurale taalmodellen om de complexiteit van zoekopdrachten te beoordelen—door factoren als aantal entiteiten, relatie-dichtheid en semantische ambiguïteit te meten—om te bepalen hoeveel subvragen moeten worden gegenereerd. Eenmaal gegenereerd, worden deze zoekopdrachten parallel uitgevoerd over meerdere retrievalsystemen, waaronder webcrawlers, kennisgrafen (zoals Google’s Knowledge Graph), gestructureerde databases en vector-similariteitsindexen. Verschillende platforms implementeren deze architectuur met uiteenlopende transparantie en verfijning:
| Platform | Mechanisme | Transparantie | Aantal zoekopdrachten | Rangschikkingsmethode |
|---|---|---|---|---|
| Google AI-modus | Expliciete fanout met zichtbare queries | Hoog | 8-12 zoekopdrachten | Multi-stage ranking |
| Microsoft Copilot | Iteratieve Bing Orchestrator | Medium | 5-8 zoekopdrachten | Relevantiescore |
| Perplexity | Hybride retrieval met multi-stage ranking | Hoog | 6-10 zoekopdrachten | Citaatgebaseerd |
| ChatGPT | Impliciete querygeneratie | Laag | Onbekend | Interne weging |
Complexe zoekopdrachten ondergaan een geavanceerde decompositie waarbij het systeem deze opbreekt in afzonderlijke entiteiten, attributen en relaties voordat varianten worden gegenereerd. Bij het verwerken van een zoekopdracht als “Bluetooth-koptelefoons met comfortabel over-ear ontwerp en langdurige batterij geschikt voor hardlopers,” voert het systeem entiteitgericht begrip uit door belangrijke entiteiten (Bluetooth-koptelefoons, hardlopers) te identificeren en kritische attributen te extraheren (comfortabel, over-ear, langdurige batterij). Het decompositieproces maakt gebruik van kennisgrafen om te begrijpen hoe deze entiteiten zich tot elkaar verhouden en welke semantische variaties er bestaan—herkennen dat “over-ear koptelefoons” en “circumaurale koptelefoons” gelijkwaardig zijn, of dat “langdurige batterij” afhankelijk van de context 8+ uur, 24+ uur of meerdere dagen kan betekenen. Het systeem identificeert gerelateerde concepten via semantische gelijkenis, begrijpt dat zoekopdrachten naar “zweetbestendigheid” en “waterbestendigheid” verwant maar verschillend zijn, en dat “hardlopers” ook kunnen verwijzen naar “fietsers,” “sportschoolbezoekers” of “buitenatleten.” Deze decompositie maakt het mogelijk om gerichte subvragen te genereren die verschillende facetten van de gebruikersintentie omvatten in plaats van alleen de originele vraag te herformuleren.
Query fanout versterkt fundamenteel de retrievalcomponent van Retrieval-Augmented Generation (RAG)-frameworks door rijkere en meer diverse bewijsvergaring mogelijk te maken vóór de generatie-fase. In traditionele RAG-pijplijnen wordt één zoekopdracht ge-embed en vergeleken met een vectordatabank, waarbij mogelijk relevante informatie wordt gemist die andere terminologie of conceptuele framing gebruikt. Query fanout pakt deze beperking aan door meerdere retrieval-operaties parallel uit te voeren, elk geoptimaliseerd voor een specifieke queryvariant, die samen bewijs verzamelen vanuit verschillende invalshoeken en bronnen. Deze parallelle retrievalstrategie vermindert het risico op hallucinaties aanzienlijk door LLM-antwoorden te onderbouwen met meerdere onafhankelijke bronnen—wanneer het systeem informatie over “over-ear koptelefoons,” “circumaurale ontwerpen” en “full-size koptelefoons” afzonderlijk ophaalt, kan het claims cross-refereren en valideren over deze diverse resultaten. De architectuur omvat semantische chunking en passage-gebaseerde retrieval, waarbij documenten worden opgedeeld in betekenisvolle semantische eenheden in plaats van vaste lengtes, zodat het systeem de meest relevante passages kan ophalen, ongeacht de documentstructuur. Door bewijs uit meerdere subquery-retrievals te combineren, leveren RAG-systemen antwoorden op die vollediger, beter onderbouwd en minder vatbaar zijn voor zelfverzekerde maar onjuiste uitkomsten die enkelvoudige retrieval benaderingen teisteren.
Gebruikerscontext en personalisatiesignalen bepalen dynamisch hoe query fanout individuele verzoeken uitbreidt, waardoor gepersonaliseerde retrievalpaden ontstaan die sterk kunnen verschillen van gebruiker tot gebruiker. Het systeem verwerkt meerdere personalisatiedimensies, waaronder gebruikerskenmerken (geografische locatie, demografisch profiel, professionele rol), zoekgeschiedenispatronen (vorige zoekopdrachten en aangeklikte resultaten), temporele signalen (tijdstip, seizoen, actuele gebeurtenissen) en taakcontext (of de gebruiker aan het onderzoeken, winkelen of leren is). Zo wordt een zoekopdracht naar “beste koptelefoons voor hardlopers” anders uitgebreid voor een 22-jarige ultramarathonloper in Kenia dan voor een 45-jarige recreatieve jogger in Minnesota—de eerste krijgt nadruk op duurzaamheid en hittebestendigheid, de tweede op comfort en toegankelijkheid. Toch introduceert deze personalisatie het “twee-punten-transformatie”-probleem waarbij het systeem huidige zoekopdrachten behandelt als variaties op historische patronen, waardoor verkenning mogelijk wordt beperkt en bestaande voorkeuren worden versterkt. Personalisatie kan onbedoeld filterbubbels creëren waarbij query expansion systematisch bronnen en perspectieven bevoordeelt die aansluiten bij het historische gedrag van de gebruiker, waardoor de blootstelling aan alternatieve standpunten of nieuwe informatie wordt beperkt. Inzicht in deze personalisatiemechanismen is cruciaal voor contentmakers, aangezien dezelfde content al dan niet wordt opgehaald, afhankelijk van het gebruikersprofiel en de geschiedenis.
Grote AI-platforms implementeren query fanout met duidelijk verschillende architecturen, transparantieniveaus en strategische benaderingen die hun onderliggende infrastructuur en ontwerpfilosofieën weerspiegelen. De AI-modus van Google gebruikt expliciete, zichtbare query fanout waarbij gebruikers de 8-12 gegenereerde subvragen zien naast de resultaten, en honderden individuele zoekopdrachten tegen de Google-index worden uitgevoerd om uitgebreid bewijs te verzamelen. Microsoft Copilot gebruikt een iteratieve aanpak via de Bing Orchestrator, die 5-8 zoekopdrachten sequentieel genereert en het queryset verfijnt op basis van tussentijdse resultaten voordat de uiteindelijke retrieval-fase wordt uitgevoerd. Perplexity implementeert een hybride retrievalstrategie met multi-stage ranking, genereert 6-10 zoekopdrachten en voert deze uit op zowel webbronnen als de eigen index, waarna geavanceerde rangschikkingsalgoritmen worden toegepast om de meest relevante passages te tonen. De aanpak van ChatGPT blijft grotendeels ondoorzichtig voor gebruikers, waarbij querygeneratie impliciet plaatsvindt binnen de interne verwerking van het model, waardoor het moeilijk te achterhalen is hoeveel zoekopdrachten er worden gegenereerd of hoe ze worden uitgevoerd. Deze architecturale verschillen hebben grote gevolgen voor transparantie, reproduceerbaarheid en de mogelijkheid voor contentmakers om te optimaliseren voor elk platform:
| Aspect | Google AI-modus | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Queryzichtbaarheid | Volledig zichtbaar voor gebruikers | Gedeeltelijk zichtbaar | Zichtbaar in citaties | Verborgen |
| Uitvoeringsmodel | Parallel batch | Iteratief sequentieel | Parallel met ranking | Intern/impliciet |
| Brondiversiteit | Alleen Google-index | Bing + eigen | Web + eigen index | Trainingsdata + plugins |
| Citatietransparantie | Hoog | Medium | Zeer hoog | Laag |
| Aanpassingsopties | Beperkt | Medium | Hoog | Medium |
Query fanout introduceert verschillende technische en semantische uitdagingen die ertoe kunnen leiden dat het systeem afwijkt van de werkelijke gebruikersintentie en technisch gerelateerde maar uiteindelijk onbruikbare informatie ophaalt. Semantische drift ontstaat door generatieve uitbreiding wanneer het LLM queryvarianten maakt die, hoewel semantisch verwant aan het origineel, geleidelijk de betekenis verschuiven—een zoekopdracht naar “beste koptelefoons voor hardlopers” kan worden uitgebreid naar “atletische koptelefoons,” vervolgens “sportuitrusting,” dan “fitnessapparatuur,” waardoor de oorspronkelijke intentie steeds verder afdrijft. Het systeem moet onderscheid maken tussen latente intentie (wat de gebruiker mogelijk had gewild als hij meer wist) en expliciete intentie (wat daadwerkelijk gevraagd is), en agressieve query expansion kan deze categorieën verwarren doordat informatie wordt opgehaald over producten waaraan de gebruiker nooit had gedacht. Iteratieve uitbreidingsafwijking ontstaat wanneer elke gegenereerde zoekopdracht extra subvragen voortbrengt, waardoor een vertakkende boom van steeds meer zijdelingse zoekopdrachten ontstaat die gezamenlijk informatie ophalen die ver van het oorspronkelijke verzoek verwijderd is. Filterbubbels en personalisatiebias betekenen dat twee gebruikers met identieke vragen systematisch verschillende query expansions krijgen op basis van hun profiel, wat echo chambers kan creëren waarin elke uitbreiding bestaande voorkeuren versterkt. Praktijkvoorbeelden tonen deze valkuilen aan: een gebruiker die zoekt naar “betaalbare koptelefoons” kan, afhankelijk van zijn browsegeschiedenis, uitgebreid worden naar luxe merken, of een zoekopdracht naar “koptelefoons voor slechthorenden” kan worden uitgebreid naar algemene toegankelijkheidsproducten, waardoor de specificiteit van de oorspronkelijke intentie verwatert.
De opkomst van query fanout verschuift contentstrategie fundamenteel van keyword-ranking optimalisatie naar citaatgebaseerde zichtbaarheid, waardoor contentmakers moeten heroverwegen hoe ze informatie structureren en presenteren. Traditionele SEO was gericht op ranking voor specifieke zoekwoorden; AI-gedreven zoeken geeft voorrang aan het geciteerd worden als gezaghebbende bron in meerdere queryvarianten en contexten. Contentmakers zouden atomische, entiteit-rijke contentstrategieën moeten hanteren waarbij informatie is gestructureerd rond specifieke entiteiten (producten, concepten, personen) met rijke semantische markup, zodat AI-systemen relevante passages kunnen extraheren en citeren. Topic clustering en thematische autoriteit worden steeds belangrijker—succesvolle content biedt brede dekking van onderwerpen, waardoor de kans groter wordt dat deze wordt opgehaald via de diverse queryvarianten die door fanout worden gegenereerd. Schema markup en gestructureerde data zorgen ervoor dat AI-systemen de contentstructuur beter begrijpen en relevante informatie effectiever kunnen extraheren, wat de kans op citatie vergroot. Succesmetrics verschuiven van keyword rankings naar het monitoren van citaatfrequentie via tools als AmICited.com, die bijhoudt hoe vaak merken en content verschijnen in AI-gegenereerde antwoorden. Concreet betekent dit: maak uitgebreide, goed onderbouwde content die meerdere invalshoeken van een onderwerp behandelt; implementeer rijke schema markup (Organization, Product, Article schemas); bouw thematische autoriteit met onderling verbonden content; en audit regelmatig hoe jouw content verschijnt in AI-antwoorden op verschillende platforms en bij verschillende gebruikerssegmenten.
Query fanout is de belangrijkste architecturale verschuiving in zoeken sinds mobile-first indexing en herstructureert fundamenteel hoe informatie wordt ontdekt en gepresenteerd aan gebruikers. De evolutie richting semantische infrastructuur betekent dat zoeksystemen steeds meer op betekenis zullen werken in plaats van op zoekwoorden, waarbij query fanout het standaardmechanisme voor informatieopvraging wordt in plaats van een optionele verbetering. Citaatmetrics worden even belangrijk als backlinks bij het bepalen van contentzichtbaarheid en autoriteit—een stuk content dat in 50 verschillende AI-antwoorden wordt geciteerd, weegt zwaarder dan content die op nummer 1 staat voor één zoekwoord. Deze verschuiving brengt zowel uitdagingen als kansen met zich mee: traditionele SEO-tools die keyword rankings volgen, worden minder relevant, waardoor nieuwe meetkaders nodig zijn gericht op citaatfrequentie, brondiversiteit en zichtbaarheid in verschillende queryvarianten. Tegelijkertijd ontstaan er kansen voor merken om zich specifiek te optimaliseren voor AI-zoekopdrachten door gezaghebbende, goed gestructureerde content te bouwen die als betrouwbare bron dient bij meerdere queryinterpretaties. De toekomst zal waarschijnlijk meer transparantie rondom query fanout-mechanismen brengen, waarbij platforms concurreren op hoe duidelijk ze gebruikers laten zien waarom ze meerdere zoekopdrachten uitvoeren, en contentmakers gespecialiseerde strategieën ontwikkelen om zichtbaarheid te maximaliseren over de diverse retrievalpaden die fanout creëert.
Query fanout is het geautomatiseerde proces waarbij AI-systemen een enkele gebruikersvraag opsplitsen in meerdere subvragen en deze parallel uitvoeren, terwijl query expansion traditioneel verwijst naar het toevoegen van gerelateerde termen aan één zoekopdracht. Query fanout is geavanceerder, genereert semantisch diverse varianten die verschillende invalshoeken en interpretaties van de oorspronkelijke intentie vastleggen.
Query fanout heeft een grote invloed op zichtbaarheid omdat je content vindbaar moet zijn via meerdere queryvarianten, niet alleen de exacte gebruikersvraag. Content die verschillende invalshoeken behandelt, gevarieerde terminologie gebruikt en goed is gestructureerd met schema markup, wordt vaker opgehaald en geciteerd in de diverse subvragen die door fanout worden gegenereerd.
Alle grote AI-zoekplatforms gebruiken query fanout-mechanismen: Google AI-modus gebruikt expliciete, zichtbare fanout (8-12 zoekopdrachten); Microsoft Copilot gebruikt iteratieve fanout via Bing Orchestrator; Perplexity implementeert hybride retrieval met multi-stage ranking; en ChatGPT gebruikt impliciete querygeneratie. Elk platform implementeert het anders, maar allemaal splitsen ze complexe zoekopdrachten op in meerdere zoekopdrachten.
Ja. Optimaliseer door het creëren van atomische, entiteit-rijke content gestructureerd rond specifieke concepten; het implementeren van uitgebreide schema markup; het opbouwen van thematische autoriteit via onderling verbonden content; het gebruik van duidelijke, gevarieerde terminologie; en het behandelen van meerdere invalshoeken van een onderwerp. Tools zoals AmICited.com helpen je te monitoren hoe je content verschijnt in verschillende querydecomposities.
Query fanout verhoogt de latentie omdat meerdere zoekopdrachten parallel worden uitgevoerd, maar moderne systemen beperken dit door parallelle verwerking. Waar één zoekopdracht 200 ms kan duren, voegt het uitvoeren van 8 zoekopdrachten parallel meestal slechts 300-500 ms totale latentie toe dankzij gelijktijdige uitvoering. Deze afweging is de moeite waard voor betere antwoordkwaliteit.
Query fanout versterkt Retrieval-Augmented Generation (RAG) door rijkere bewijsvergaring mogelijk te maken. In plaats van documenten op te halen voor één zoekopdracht, haalt fanout bewijs op voor meerdere queryvarianten parallel, waardoor het LLM meer diverse, uitgebreide context biedt voor het genereren van nauwkeurige antwoorden en het verkleinen van het risico op hallucinaties.
Personalisatie bepaalt hoe zoekopdrachten worden opgesplitst op basis van gebruikerskenmerken (locatie, geschiedenis, demografie), temporele signalen en taakcontext. Dezelfde zoekopdracht wordt anders uitgebreid voor verschillende gebruikers, wat zorgt voor gepersonaliseerde retrievalpaden. Dit kan de relevantie verbeteren, maar creëert ook filterbubbels waarbij gebruikers systematisch verschillende resultaten zien afhankelijk van hun profiel.
Query fanout vertegenwoordigt de grootste verschuiving in zoeken sinds mobile-first indexing. Traditionele keyword ranking-metrics worden minder relevant omdat dezelfde zoekopdracht anders wordt uitgebreid voor verschillende gebruikers. SEO-professionals moeten de focus verleggen van keyword rankings naar citaat-gebaseerde zichtbaarheid, contentstructuur en entiteitoptimalisatie om succesvol te zijn in AI-gedreven zoeken.
Begrijp hoe jouw merk verschijnt op AI-zoekplatforms wanneer zoekopdrachten worden uitgebreid en opgesplitst. Volg citaties en vermeldingen in AI-gegenereerde antwoorden.
Ontdek hoe Query Fanout werkt in AI-zoeksystemen. Leer hoe AI enkele vragen uitbreidt naar meerdere subvragen om de nauwkeurigheid van antwoorden en het begrip ...
Lees meer over AI-querypatronen - terugkerende structuren en formuleringen die gebruikers hanteren bij het stellen van vragen aan AI-assistenten. Ontdek hoe dez...

Query refinement is het iteratieve proces van het optimaliseren van zoekopdrachten voor betere resultaten in AI-zoekmachines. Leer hoe het werkt bij ChatGPT, Pe...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.