
Hoe AI-crawlers in je serverlogs herkennen
Leer hoe je AI-crawlers zoals GPTBot, ClaudeBot en PerplexityBot in je serverlogs kunt herkennen en monitoren. Volledige gids met user-agent strings, IP-verific...
8 min lezen

Leer hoe je AI-crawleractiviteit op je website volgt en monitort met behulp van serverlogs, tools en best practices. Identificeer GPTBot, ClaudeBot en andere AI-bots.
Kunstmatige intelligentie-bots zijn nu goed voor meer dan 51% van het wereldwijde internetverkeer, maar de meeste website-eigenaren hebben geen idee dat ze toegang hebben tot hun content. Traditionele analysetools zoals Google Analytics missen deze bezoekers volledig omdat AI-crawlers bewust vermijden om JavaScript-gebaseerde trackingcode te activeren. Serverlogs registreren 100% van de botverzoeken en vormen daarmee de enige betrouwbare bron om te begrijpen hoe AI-systemen met uw site omgaan. Inzicht in het gedrag van bots is cruciaal voor AI-zichtbaarheid, want als AI-crawlers uw content niet goed kunnen benaderen, wordt deze niet opgenomen in AI-gegenereerde antwoorden wanneer potentiële klanten relevante vragen stellen.

AI-crawlers gedragen zich fundamenteel anders dan traditionele zoekmachinebots. Waar Googlebot uw XML-sitemap volgt, robots.txt respecteert en regelmatig crawlt om zoekindexen te updaten, kunnen AI-bots standaardprotocollen negeren, pagina’s bezoeken om taalmodellen te trainen en aangepaste identificaties gebruiken. Belangrijke AI-crawlers zijn onder andere GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google’s AI-trainingsbot), Bingbot-AI (Microsoft) en Applebot-Extended (Apple). Deze bots richten zich op content die gebruikersvragen beantwoordt in plaats van alleen rankingsignalen, waardoor hun crawlpatronen onvoorspelbaar en vaak agressief zijn. Begrijpen welke bots uw site bezoeken en hoe ze zich gedragen is essentieel om uw contentstrategie te optimaliseren voor het AI-tijdperk.
| Crawler Type | Typical RPS | Behavior | Purpose |
|---|---|---|---|
| Googlebot | 1-5 | Steady, respects crawl-delay | Search indexing |
| GPTBot | 5-50 | Burst patterns, high volume | AI model training |
| ClaudeBot | 3-30 | Targeted content access | AI training |
| PerplexityBot | 2-20 | Selective crawling | AI search |
| Google-Extended | 5-40 | Aggressive, AI-focused | Google AI training |
Uw webserver (Apache, Nginx of IIS) genereert automatisch logs die elk verzoek aan uw website vastleggen, ook die van AI-bots. Deze logs bevatten cruciale informatie: IP-adressen die de oorsprong van verzoeken tonen, user agents die de software identificeren die verzoeken doet, tijdstempels die aangeven wanneer verzoeken plaatsvonden, opgevraagde URL’s die laten zien welke content is bezocht en response codes die serverreacties aanduiden. U kunt logs openen via FTP of SSH door verbinding te maken met uw hostingserver en naar de logs-map te navigeren (meestal /var/log/apache2/ voor Apache of /var/log/nginx/ voor Nginx). Elke logregel volgt een standaardformaat dat precies onthult wat er bij elk verzoek gebeurde.
Hier is een voorbeeld van een logregel met uitleg van de velden:
192.168.1.100 - - [01/Jan/2025:12:00:00 +0000] "GET /blog/ai-crawlers HTTP/1.1" 200 5432 "-" "Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot)"
IP Address: 192.168.1.100
User Agent: GPTBot/1.0 (identificeert de bot)
Timestamp: 01/Jan/2025:12:00:00
Request: GET /blog/ai-crawlers (de bezochte pagina)
Status Code: 200 (geslaagd verzoek)
Response Size: 5432 bytes
De eenvoudigste manier om AI-bots te identificeren is door bekende user agent strings in uw logs te zoeken. Veelvoorkomende AI-bot user agent-handtekeningen zijn onder andere “GPTBot” voor OpenAI’s crawler, “ClaudeBot” voor Anthropics crawler, “PerplexityBot” voor Perplexity AI, “Google-Extended” voor Google’s AI-trainingsbot en “Bingbot-AI” voor Microsoft’s AI-crawler. Sommige AI-bots identificeren zichzelf echter niet duidelijk, waardoor ze moeilijker te detecteren zijn met eenvoudige user agent-zoekopdrachten. U kunt commandoregeltools gebruiken zoals grep om snel specifieke bots te vinden: grep "GPTBot" access.log | wc -l telt alle GPTBot-verzoeken, terwijl grep "GPTBot" access.log > gptbot_requests.log een apart bestand maakt voor analyse.
Bekende AI-bot user agents om te monitoren:
Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot)Mozilla/5.0 (compatible; PerplexityBot/1.0; +https://www.perplexity.ai/bot)Mozilla/5.0 (compatible; Google-Extended; +https://www.google.com/bot.html)Mozilla/5.0 (compatible; Bingbot-AI/1.0)Voor bots die zichzelf niet duidelijk identificeren, kunt u IP-reputatiecontrole toepassen door IP-adressen te vergelijken met gepubliceerde reeksen van grote AI-bedrijven.
Het monitoren van de juiste statistieken onthult de bedoelingen van bots en helpt u uw site dienovereenkomstig te optimaliseren. Het verzoekenpercentage (gemeten in requests per second of RPS) laat zien hoe agressief een bot uw site crawlt—gezonde crawlers hanteren 1-5 RPS terwijl agressieve AI-bots tot 50+ RPS kunnen gaan. Resourceverbruik is van belang omdat één AI-bot in een dag meer bandbreedte kan verbruiken dan al uw menselijke bezoekers samen. De verdeling van HTTP-statuscodes laat zien hoe uw server reageert op botverzoeken: hoge percentages 200 (OK) duiden op geslaagde crawling, terwijl veel 404’s wijzen op gebroken links of pogingen om verborgen resources te benaderen. Crawlfrequentie en patronen tonen of bots reguliere bezoekers zijn of burst-and-pause types, terwijl geografische oorsprongscontrole laat zien of verzoeken van legitieme bedrijfsinfrastructuur komen of van verdachte locaties.
| Metric | What It Means | Healthy Range | Red Flags |
|---|---|---|---|
| Requests/Hour | Bot activity intensity | 100-1000 | 5000+ |
| Bandwidth (MB/hour) | Resource consumption | 50-500 | 5000+ |
| 200 Status Codes | Successful requests | 70-90% | <50% |
| 404 Status Codes | Broken links accessed | <10% | >30% |
| Crawl Frequency | How often bot visits | Daily-Weekly | Multiple times/hour |
| Geographic Concentration | Request origin | Known data centers | Residential ISPs |
U heeft verschillende opties om AI-crawleractiviteit te monitoren: van gratis commandoregeltools tot enterpriseplatforms. Commandoregeltools zoals grep, awk en sed zijn gratis en krachtig voor kleine tot middelgrote sites en stellen u in staat om patronen binnen enkele seconden uit logs te halen. Commerciële platforms zoals Botify, Conductor en seoClarity bieden geavanceerde functies zoals automatische botidentificatie, visuele dashboards en correlatie met rankings- en verkeersdata. Loganalysetools als Screaming Frog Log File Analyser en OnCrawl bieden gespecialiseerde functies voor het verwerken van grote logbestanden en het identificeren van crawlpatronen. AI-gestuurde analyseplatforms gebruiken machine learning om automatisch nieuwe bottype te identificeren, gedrag te voorspellen en afwijkingen te detecteren zonder handmatige configuratie.
| Tool | Cost | Features | Best For |
|---|---|---|---|
| grep/awk/sed | Free | Command-line pattern matching | Technical users, small sites |
| Botify | Enterprise | AI bot tracking, performance correlation | Large sites, detailed analysis |
| Conductor | Enterprise | Real-time monitoring, AI crawler activity | Enterprise SEO teams |
| seoClarity | Enterprise | Log file analysis, AI bot tracking | Comprehensive SEO platforms |
| Screaming Frog | $199/year | Log file analysis, crawl simulation | Technical SEO specialists |
| OnCrawl | Enterprise | Cloud-based analysis, performance data | Mid-market to enterprise |
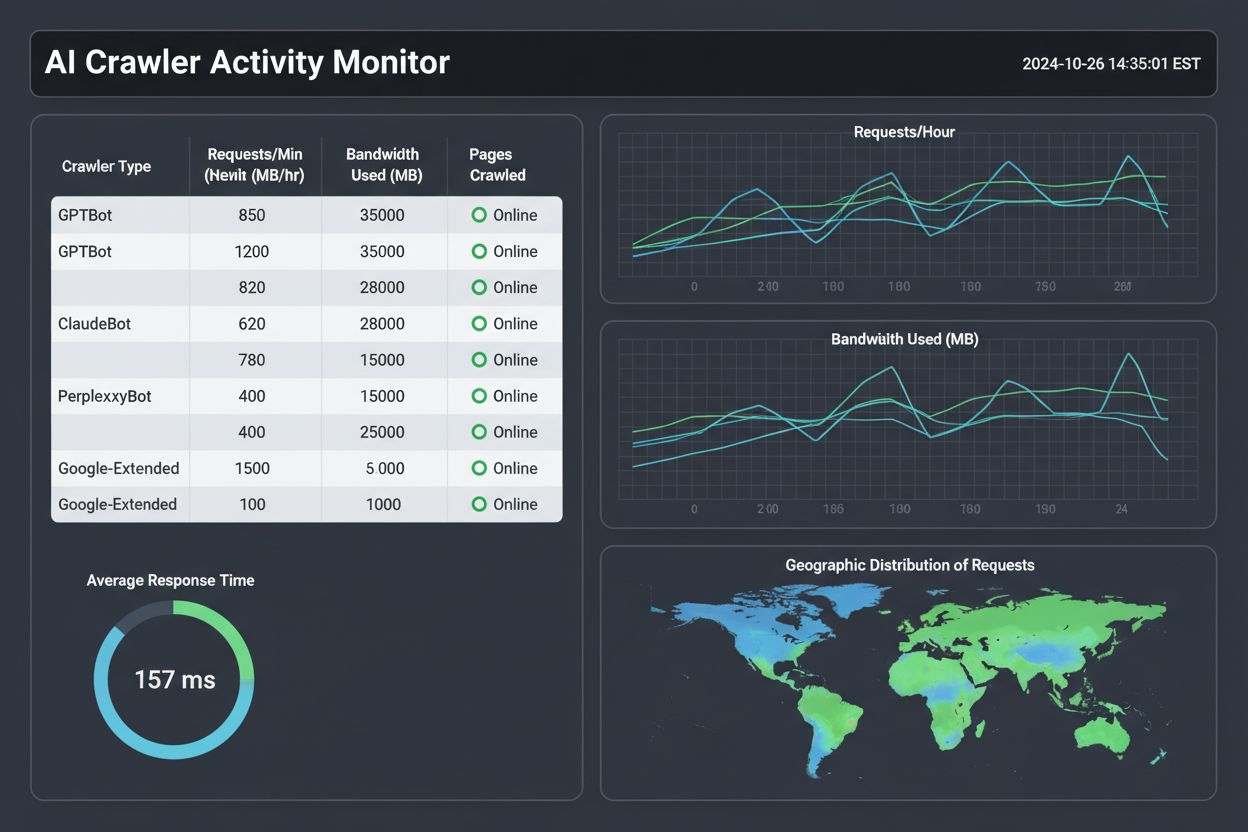
Het vaststellen van basis-crawlpatronen is uw eerste stap naar effectieve monitoring. Verzamel minstens twee weken aan logdata (bij voorkeur een maand) om normaal botgedrag te begrijpen voordat u conclusies trekt over afwijkingen. Stel geautomatiseerde monitoring in door scripts te maken die dagelijks draaien om logs te analyseren en rapporten te genereren, bijvoorbeeld met Python en de pandas-bibliotheek of eenvoudige bashscripts. Stel alerts in voor ongebruikelijke activiteit zoals plotselinge pieken in verzoeken, nieuwe bottype of bots die beperkte resources benaderen. Plan regelmatige logreviews—wekelijks voor drukbezochte sites om problemen vroeg te signaleren, maandelijks voor kleinere sites om trends te ontdekken.
Hier is een eenvoudig bashscript voor continue monitoring:
#!/bin/bash
# Daily AI bot activity report
LOG_FILE="/var/log/nginx/access.log"
REPORT_FILE="/reports/bot_activity_$(date +%Y%m%d).txt"
echo "=== AI Bot Activity Report ===" > $REPORT_FILE
echo "Date: $(date)" >> $REPORT_FILE
echo "" >> $REPORT_FILE
echo "GPTBot Requests:" >> $REPORT_FILE
grep "GPTBot" $LOG_FILE | wc -l >> $REPORT_FILE
echo "ClaudeBot Requests:" >> $REPORT_FILE
grep "ClaudeBot" $LOG_FILE | wc -l >> $REPORT_FILE
echo "PerplexityBot Requests:" >> $REPORT_FILE
grep "PerplexityBot" $LOG_FILE | wc -l >> $REPORT_FILE
# Send alert if unusual activity detected
GPTBOT_COUNT=$(grep "GPTBot" $LOG_FILE | wc -l)
if [ $GPTBOT_COUNT -gt 10000 ]; then
echo "ALERT: Unusual GPTBot activity detected!" | mail -s "Bot Alert" admin@example.com
fi
Uw robots.txt-bestand is de eerste verdedigingslinie voor het beheren van AI-bottoegang, en grote AI-bedrijven respecteren specifieke instructies voor hun trainingsbots. U kunt aparte regels maken voor verschillende bottype—Googlebot volledige toegang geven maar GPTBot beperken tot specifieke secties, of crawl-delay waarden instellen om het aantal verzoeken te beperken. Rate limiting zorgt ervoor dat bots uw infrastructuur niet overbelasten door limieten in te stellen op meerdere niveaus: per IP-adres, per user agent en per resourcetype. Wanneer een bot de limieten overschrijdt, retourneert u een 429 (Too Many Requests) response met een Retry-After-header; goedgedragende bots respecteren dit en vertragen, terwijl scrapers dit negeren en geblokkeerd kunnen worden.
Hier zijn robots.txt-voorbeelden voor het beheren van AI-crawlertoegang:
# Allow search engines, limit AI training bots
User-agent: Googlebot
Allow: /
User-agent: GPTBot
Disallow: /private/
Disallow: /proprietary-content/
Crawl-delay: 1
User-agent: ClaudeBot
Disallow: /admin/
Crawl-delay: 2
User-agent: *
Disallow: /
De opkomende LLMs.txt-standaard biedt extra controle door u in staat te stellen voorkeuren voor AI-crawlers in een gestructureerd formaat te communiceren, vergelijkbaar met robots.txt maar specifiek ontworpen voor AI-toepassingen.
Uw site AI-crawler-vriendelijk maken verbetert hoe uw content verschijnt in door AI gegenereerde antwoorden en zorgt ervoor dat bots uw meest waardevolle pagina’s kunnen bereiken. Een duidelijke sitestructuur met consistente navigatie, sterke interne links en logische contentorganisatie helpt AI-bots uw content efficiënt te begrijpen en doorzoeken. Implementeer schema-markup met JSON-LD-formaat om het contenttype, kerninformatie, relaties tussen contentonderdelen en bedrijfsgegevens te verduidelijken—dit helpt AI-systemen uw content nauwkeurig te interpreteren en te citeren. Zorg voor snelle laadtijden om time-outs te voorkomen, onderhoud een mobielvriendelijk ontwerp dat werkt voor alle bottype en maak hoogwaardige, originele content die AI-systemen nauwkeurig kunnen vermelden.
Best practices voor AI-crawleroptimalisatie:
Veel site-eigenaren maken cruciale fouten bij het beheren van AI-crawlertoegang die hun AI-zichtbaarheidsstrategie ondermijnen. Botverkeer verkeerd identificeren door uitsluitend op user agent strings te vertrouwen, mist geavanceerde bots die zich voordoen als browsers—gebruik gedragsanalyse zoals verzoekfrequentie, contentvoorkeuren en geografische verdeling voor nauwkeurige identificatie. Incomplete loganalyse die alleen naar user agents kijkt en andere gegevens negeert, mist belangrijke botactiviteit; volledige tracking moet verzoekfrequentie, contentvoorkeuren, geografische verdeling en prestatiestatistieken omvatten. Te veel blokkeren via te restrictieve robots.txt-bestanden voorkomt dat legitieme AI-bots waardevolle content bereiken die zichtbaarheid in AI-antwoorden kan opleveren.
Veelgemaakte fouten om te vermijden:
Het AI-botlandschap ontwikkelt zich snel en uw monitoringspraktijken moeten zich daaraan aanpassen. AI-bots worden geavanceerder, voeren JavaScript uit, vullen formulieren in en navigeren complexe site-architecturen—waardoor traditionele botdetectiemethoden minder betrouwbaar zijn. Verwacht opkomende standaarden die gestructureerde manieren bieden om uw voorkeuren aan AI-bots te communiceren, vergelijkbaar met robots.txt maar met meer gedetailleerde controle. Regelgevende veranderingen zijn op komst nu wetgevers eisen dat AI-bedrijven hun trainingsbronnen openbaar maken en contentmakers compenseren, waardoor uw logbestanden mogelijk juridisch bewijs van botactiviteit worden. Botbrokerdiensten zullen waarschijnlijk ontstaan om toegang tussen contentmakers en AI-bedrijven te regelen, inclusief toestemming, vergoeding en technische implementatie.
De branche beweegt richting standaardisatie met nieuwe protocollen en uitbreidingen op robots.txt die gestructureerde communicatie met AI-bots mogelijk maken. Machine learning zal steeds vaker loganalysetools aandrijven, waardoor nieuwe botpatronen automatisch worden herkend en beleidsaanpassingen worden voorgesteld zonder handmatige interventie. Sites die nu AI-crawlermonitoring onder de knie krijgen, hebben straks een groot voordeel in het beheren van hun content, infrastructuur en businessmodel nu AI-systemen steeds centraler worden in de informatiestroom op het web.
Klaar om te monitoren hoe AI-systemen uw merk citeren en vermelden? AmICited.com vult serverloganalyse aan door daadwerkelijke merkvermeldingen en citaties in AI-antwoorden te volgen, waaronder ChatGPT, Perplexity, Google AI Overviews en andere AI-platforms. Waar serverlogs laten zien welke bots uw site crawlen, toont AmICited het echte effect—hoe uw content wordt gebruikt en geciteerd in AI-antwoorden. Begin vandaag nog met het volgen van uw AI-zichtbaarheid.
AI-crawlers zijn bots die door AI-bedrijven worden gebruikt om taalmodellen te trainen en AI-toepassingen aan te sturen. In tegenstelling tot zoekmachinebots die indexen bouwen voor ranking, richten AI-crawlers zich op het verzamelen van diverse content om AI-modellen te trainen. Ze crawlen vaak agressiever en negeren mogelijk traditionele robots.txt-regels.
Controleer uw serverlogs op bekende AI-bot user agent strings zoals 'GPTBot', 'ClaudeBot' of 'PerplexityBot'. Gebruik commandoregeltools zoals grep om naar deze identificaties te zoeken. U kunt ook loganalysetools zoals Botify of Conductor gebruiken die AI-crawleractiviteit automatisch identificeren en categoriseren.
Dat hangt af van uw zakelijke doelen. Door AI-crawlers te blokkeren, verschijnt uw content niet in door AI gegenereerde antwoorden, wat de zichtbaarheid kan verminderen. Als u zich echter zorgen maakt over contentdiefstal of verbruik van resources, kunt u robots.txt gebruiken om de toegang te beperken. Overweeg toegang tot openbare content toe te staan en eigendomsinformatie te beperken.
Volg het aantal verzoeken per seconde, bandbreedteverbruik, HTTP-statuscodes, crawlfrequentie en geografische oorsprong van verzoeken. Monitor welke pagina's bots het vaakst bezoeken en hoe lang ze op uw site blijven. Deze statistieken onthullen de bedoelingen van bots en helpen u uw site daarop af te stemmen.
Gratis opties zijn commandoregeltools (grep, awk) en open-source loganalyzers. Commerciële platforms zoals Botify, Conductor en seoClarity bieden geavanceerde functies, waaronder automatische botidentificatie en prestatiecorrelatie. Kies op basis van uw technische vaardigheden en budget.
Zorg voor snelle laadtijden, gebruik gestructureerde data (schema-markup), behoud een duidelijke site-architectuur en maak content gemakkelijk toegankelijk. Implementeer de juiste HTTP-headers en robots.txt-regels. Maak hoogwaardige, originele content die AI-systemen nauwkeurig kunnen citeren en vermelden.
Ja, agressieve AI-crawlers kunnen aanzienlijke bandbreedte en serverresources verbruiken, wat kan leiden tot vertragingen of hogere hostingkosten. Monitor crawleractiviteit en implementeer rate limiting om uitputting van resources te voorkomen. Gebruik robots.txt en HTTP-headers om indien nodig de toegang te regelen.
LLMs.txt is een opkomende standaard waarmee websites voorkeuren voor AI-crawlers in een gestructureerd formaat kunnen communiceren. Hoewel niet alle bots dit al ondersteunen, geeft implementatie extra controle over hoe AI-systemen uw content benaderen. Het lijkt op robots.txt, maar is specifiek ontworpen voor AI-toepassingen.
Volg hoe AI-systemen uw content citeren en vermelden in ChatGPT, Perplexity, Google AI Overviews en andere AI-platforms. Begrijp uw AI-zichtbaarheid en optimaliseer uw contentstrategie.
Leer hoe je AI-crawlers zoals GPTBot, ClaudeBot en PerplexityBot in je serverlogs kunt herkennen en monitoren. Volledige gids met user-agent strings, IP-verific...

Leer hoe je een audit uitvoert op AI-crawler toegang tot je website. Ontdek welke bots jouw content kunnen zien en los blokkades op die AI-zichtbaarheid in Chat...

Leer hoe je AI-crawlers zoals GPTBot, PerplexityBot en ClaudeBot kunt identificeren en monitoren in je serverlogs. Ontdek user-agent strings, IP-verificatiemeth...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.