
Scoren van contentrelevantie
Ontdek hoe het scoren van contentrelevantie door AI-algoritmen wordt gebruikt om te meten hoe goed content aansluit bij gebruikersvragen en intentie. Begrijp BM...
7 min lezen

AI Retrieval Scoring is het proces waarbij de relevantie en kwaliteit van opgehaalde documenten of passages ten opzichte van een gebruikersvraag worden gekwantificeerd. Het maakt gebruik van geavanceerde algoritmen om semantische betekenis, contextuele geschiktheid en informatiekwaliteit te evalueren, en bepaalt welke bronnen worden doorgegeven aan taalmodellen voor antwoordgeneratie in RAG-systemen.
AI Retrieval Scoring is het proces waarbij de relevantie en kwaliteit van opgehaalde documenten of passages ten opzichte van een gebruikersvraag worden gekwantificeerd. Het maakt gebruik van geavanceerde algoritmen om semantische betekenis, contextuele geschiktheid en informatiekwaliteit te evalueren, en bepaalt welke bronnen worden doorgegeven aan taalmodellen voor antwoordgeneratie in RAG-systemen.
AI Retrieval Scoring is het proces waarbij de relevantie en kwaliteit van opgehaalde documenten of passages worden gekwantificeerd ten opzichte van een gebruikersvraag of taak. In tegenstelling tot eenvoudige zoekwoordmatching, die alleen oppervlakkige termoverlap identificeert, maakt retrieval scoring gebruik van geavanceerde algoritmen om semantische betekenis, contextuele geschiktheid en informatiekwaliteit te evalueren. Dit scoreringsmechanisme is fundamenteel voor Retrieval-Augmented Generation (RAG)-systemen, waar het bepaalt welke bronnen worden doorgegeven aan taalmodellen voor antwoordgeneratie. In moderne LLM-toepassingen heeft retrieval scoring directe invloed op antwoordnauwkeurigheid, het verminderen van hallucinaties en gebruikers-tevredenheid door ervoor te zorgen dat alleen de meest relevante informatie de generatie-fase bereikt. De kwaliteit van retrieval scoring is daarom een cruciaal onderdeel van de algehele systeemprestatie en betrouwbaarheid.
Retrieval scoring maakt gebruik van meerdere algoritmische benaderingen, elk met specifieke sterke punten voor verschillende use cases. Semantische similariteit scoring gebruikt embedding-modellen om de conceptuele overeenstemming te meten tussen vragen en documenten in vectorruimte, en vangt betekenis op die verder gaat dan oppervlakkige zoekwoorden. BM25 (Best Matching 25) is een probabilistische rangschikkingsfunctie die rekening houdt met termfrequentie, inverse documentfrequentie en documentlengte-normalisatie, waardoor het zeer effectief is voor traditionele tekstophaling. TF-IDF (Term Frequency-Inverse Document Frequency) weegt termen op basis van hun belang binnen documenten en verzamelingen, al ontbreekt semantisch begrip. Hybride benaderingen combineren meerdere methoden—zoals het samenvoegen van BM25- en semantische scores—om zowel lexicale als semantische signalen te benutten. Naast scoreringsmethoden bieden evaluatiemetrics zoals Precision@k (percentage van de top-k resultaten dat relevant is), Recall@k (percentage van alle relevante documenten gevonden in top-k), NDCG (Normalized Discounted Cumulative Gain, die rekening houdt met de rangschikking), en MRR (Mean Reciprocal Rank) kwantitatieve maten voor retrievalkwaliteit. Het begrijpen van de sterke en zwakke punten van elke aanpak—zoals de efficiëntie van BM25 versus het diepere begrip van semantische scoring—is essentieel voor het selecteren van geschikte methoden voor specifieke toepassingen.
| Scoringmethode | Werking | Beste Toepassing | Belangrijkste Voordeel |
|---|---|---|---|
| Semantische Similariteit | Vergelijkt embeddings met cosine similarity of andere afstandsmetrics | Conceptuele betekenis, synoniemen, parafrases | Vangt semantische relaties buiten zoekwoorden |
| BM25 | Probabilistische rangschikking op basis van termfrequentie en documentlengte | Exacte frase-matching, zoekwoord gebaseerde queries | Snel, efficiënt, bewezen in productie |
| TF-IDF | Weegt termen op basis van frequentie in document en zeldzaamheid in collectie | Traditionele informatieophaling | Simpel, interpreteerbaar, lichtgewicht |
| Hybride Scoring | Combineert semantische en zoekwoord-gebaseerde benaderingen met gewogen fusie | Algemeen retrieval, complexe queries | Benut sterke punten van meerdere methoden |
| LLM-gebaseerde Scoring | Gebruikt taalmodellen om relevantie te beoordelen met aangepaste prompts | Complexe context-evaluatie, domeinspecifieke taken | Vangt genuanceerde semantische relaties |
In RAG-systemen werkt retrieval scoring op meerdere niveaus om de generatiekwaliteit te waarborgen. Het systeem scoort doorgaans individuele chunks of passages binnen documenten, waardoor een fijnmazige relevantiebeoordeling mogelijk is in plaats van hele documenten als één geheel te behandelen. Deze per-chunk relevantie scoring stelt het systeem in staat om alleen de meest relevante informatiedelen te extraheren, waardoor ruis en irrelevante context die het taalmodel kunnen verwarren worden verminderd. RAG-systemen implementeren vaak scoringdrempels of cutoff-mechanismen die resultaten met lage scores filteren voordat ze de generatie-fase bereiken, zodat bronnen van lage kwaliteit geen invloed hebben op het uiteindelijke antwoord. De kwaliteit van opgehaalde context correleert direct met de kwaliteit van de gegenereerde antwoorden—hoog scorende, relevante passages leiden tot nauwkeurigere, beter onderbouwde antwoorden, terwijl retrievals van lage kwaliteit hallucinaties en feitelijke fouten introduceren. Het monitoren van retrieval scores biedt vroege waarschuwingssignalen voor systeemdegradatie, en is daarmee een belangrijke metric voor AI-antwoord monitoring en kwaliteitsborging in productiesystemen.
Re-ranking dient als een tweede filteringsmechanisme dat initiële retrievalresultaten verfijnt en vaak de rangschikking aanzienlijk verbetert. Nadat een initiële retriever kandidaatresultaten heeft gegenereerd met voorlopige scores, past een re-ranker geavanceerdere scoreringslogica toe om deze kandidaten te herordenen of te filteren, meestal met meer computationeel intensieve modellen die diepere analyse mogelijk maken. Reciprocal Rank Fusion (RRF) is een populaire techniek die ranglijsten van meerdere retrievers combineert door scores toe te kennen op basis van de positie in het resultaat, en deze scores samen te voegen tot één ranglijst die vaak beter presteert dan individuele retrievers. Score-normalisatie wordt cruciaal wanneer resultaten uit verschillende retrievalmethoden worden gecombineerd, omdat ruwe scores van BM25, semantische similariteit en andere benaderingen op verschillende schalen werken en moeten worden gekalibreerd naar vergelijkbare bereiken. Ensemble-retriever benaderingen maken gelijktijdig gebruik van meerdere retrievalstrategieën, waarbij re-ranking de uiteindelijke volgorde bepaalt op basis van gecombineerd bewijs. Deze meerstaps aanpak verbetert de rangschikking en robuustheid aanzienlijk ten opzichte van eentraps-retrieval, vooral in complexe domeinen waar verschillende retrievalmethoden complementaire relevantiesignalen oppikken.
Precision@k: Meet het aandeel relevante documenten binnen de top-k resultaten; nuttig om te beoordelen of opgehaalde resultaten betrouwbaar zijn (bijv. Precision@5 = 4/5 betekent 80% van de top-5 resultaten is relevant)
Recall@k: Berekent het percentage van alle relevante documenten dat is gevonden binnen de top-k resultaten; belangrijk voor een volledige dekking van beschikbare relevante informatie
Hit Rate: Binaire metric die aangeeft of ten minste één relevant document in de top-k resultaten verschijnt; nuttig voor snelle kwaliteitscontroles in productieomgevingen
NDCG (Normalized Discounted Cumulative Gain): Houdt rekening met de positie in de ranglijst door hogere waarde toe te kennen aan relevante documenten die eerder verschijnen; varieert van 0-1 en is ideaal voor evaluatie van rangschikkingskwaliteit
MRR (Mean Reciprocal Rank): Meet de gemiddelde positie van het eerste relevante resultaat over meerdere queries; vooral nuttig om te beoordelen of het meest relevante document hoog scoort
F1 Score: Harmonisch gemiddelde van precision en recall; biedt een gebalanceerde evaluatie wanneer zowel false positives als false negatives even belangrijk zijn
MAP (Mean Average Precision): Gemiddelde van precision-waarden op elke positie waar een relevant document is gevonden; uitgebreide metric voor algemene rangschikkingskwaliteit over meerdere queries
LLM-gebaseerde relevantie scoring gebruikt taalmodellen zelf als beoordelaars van documentrelevantie, en biedt een flexibel alternatief voor traditionele algoritmische benaderingen. In dit paradigma instrueren zorgvuldig geformuleerde prompts een LLM om te beoordelen of een opgehaalde passage een gegeven vraag beantwoordt, en levert zo binaire relevantiescores (relevant/niet relevant) of numerieke scores (bijv. schaal van 1-5 voor relevantiekracht). Deze aanpak vangt genuanceerde semantische relaties en domeinspecifieke relevantie op die traditionele algoritmen mogelijk missen, vooral bij complexe vragen die diepgaande interpretatie vereisen. LLM-gebaseerde scoring brengt echter uitdagingen met zich mee zoals hoge rekensnelheid (LLM-inferentie is duurder dan embedding-similariteit), mogelijke inconsistentie tussen verschillende prompts en modellen, en de behoefte aan kalibratie met menselijke labels om te zorgen dat scores overeenkomen met daadwerkelijke relevantie. Ondanks deze beperkingen is LLM-gebaseerde scoring waardevol gebleken voor het evalueren van RAG-systeemkwaliteit en voor het genereren van trainingsdata voor gespecialiseerde scoreringsmodellen, en vormt het daarmee een belangrijk instrument binnen de AI-monitoring toolkit voor het beoordelen van antwoordkwaliteit.
Het implementeren van effectieve retrieval scoring vereist zorgvuldige afweging van meerdere praktische factoren. Methodekeuze hangt af van de eisen van de use case: semantische scoring blinkt uit in het vatten van betekenis maar vereist embedding-modellen, terwijl BM25 snelheid en efficiëntie biedt voor lexicale matching. De afweging tussen snelheid en nauwkeurigheid is cruciaal—embedding-gebaseerde scoring biedt superieur relevantiebegrip maar brengt latentie met zich mee, terwijl BM25 en TF-IDF sneller zijn maar minder semantische verfijning bieden. Computationele kosten omvatten modelinferentietijd, geheugengebruik en infrastructuurschaling, wat vooral belangrijk is voor grootschalige productiesystemen. Parameter tuning omvat het afstellen van drempels, gewichten in hybride benaderingen en re-ranking cutoff’s om prestaties te optimaliseren voor specifieke domeinen en toepassingen. Continue monitoring van scoringprestaties met metrics als NDCG en Precision@k helpt bij het signaleren van degradatie in de tijd, waardoor proactieve systeemverbeteringen mogelijk zijn en consistente antwoordkwaliteit in productie-RAG-systemen wordt gegarandeerd.
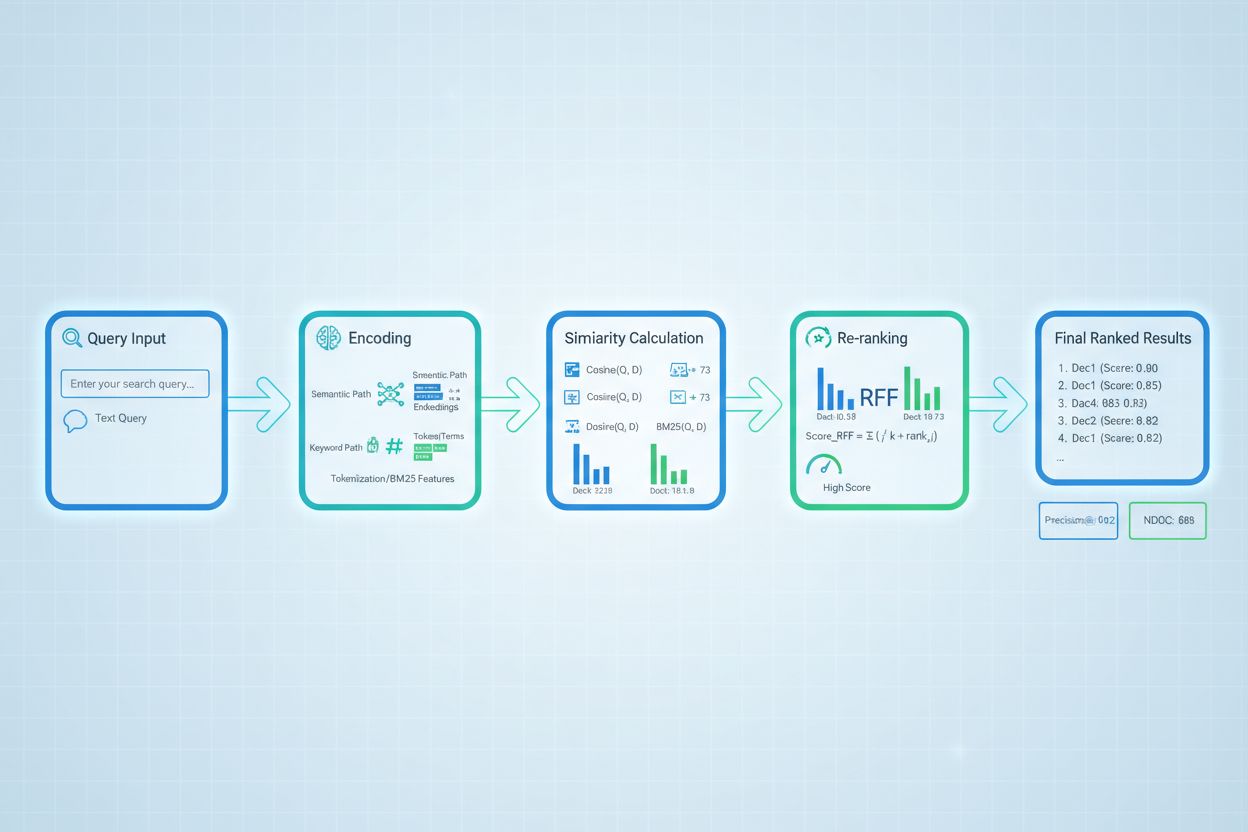
Geavanceerde retrieval scoring technieken gaan verder dan basisrelevantie om complexe contextuele relaties te vatten. Query rewriting kan scoring verbeteren door gebruikersvragen te herformuleren in meerdere semantisch equivalente vormen, zodat de retriever relevante documenten kan vinden die mogelijk worden gemist door letterlijke querymatching. Hypothetical Document Embeddings (HyDE) genereren synthetische relevante documenten uit queries en gebruiken deze hypothetische documenten om retrieval scoring te verbeteren door echte documenten te vinden die lijken op de ideale relevante inhoud. Multi-query benaderingen sturen meerdere queryvarianten naar retrievers en aggregeren hun scores, wat robuustheid en dekking verbetert ten opzichte van retrieval met één query. Domeinspecifieke scoringmodellen die getraind zijn op gelabelde data uit specifieke sectoren of kennisdomeinen kunnen superieure prestaties leveren ten opzichte van algemene modellen, vooral waardevol voor gespecialiseerde toepassingen zoals medische of juridische AI-systemen. Contextuele scoreringsaanpassingen houden rekening met factoren als actualiteit van documenten, bronautoriteit en gebruikerscontext, waardoor meer geavanceerde relevantiebeoordeling mogelijk is die verder gaat dan zuivere semantische similariteit en real-world relevantiefactoren integreert die cruciaal zijn voor productie-AI-systemen.
Retrieval scoring kent numerieke relevantiewaarden toe aan documenten op basis van hun relatie tot een vraag, terwijl ranking documenten op basis van deze scores ordent. Scoring is het evaluatieproces, ranking is het ordeningsresultaat. Beide zijn essentieel voor RAG-systemen om nauwkeurige antwoorden te leveren.
Retrieval scoring bepaalt welke bronnen het taalmodel bereiken voor antwoordgeneratie. Hoge kwaliteit scoring zorgt ervoor dat relevante informatie wordt geselecteerd, waardoor hallucinaties worden verminderd en de nauwkeurigheid van antwoorden verbetert. Slechte scoring leidt tot irrelevante context en onbetrouwbare AI-antwoorden.
Semantische scoring gebruikt embeddings om conceptuele betekenis te begrijpen en pikt synoniemen en gerelateerde concepten op. Zoekwoord-gebaseerde scoring (zoals BM25) matcht exacte termen en zinnen. Semantische scoring is beter voor het begrijpen van intentie, terwijl zoekwoord scoring uitblinkt in het vinden van specifieke informatie.
Belangrijke metrics zijn onder andere Precision@k (nauwkeurigheid van de topposities), Recall@k (dekking van relevante documenten), NDCG (kwaliteit van rangschikking) en MRR (positie van het eerste relevante resultaat). Kies metrics op basis van je use case: Precision@k voor kwaliteit, Recall@k voor volledige dekking.
Ja, LLM-gebaseerde scoring gebruikt taalmodellen als beoordelaars om relevantie te evalueren. Deze aanpak vangt genuanceerde semantische relaties op maar is computationeel duur. Het is waardevol voor het evalueren van RAG-kwaliteit en het creëren van trainingsdata, hoewel afstemming met menselijke labels vereist is.
Re-ranking past een tweede filter toe met meer geavanceerde modellen om initiële resultaten te verfijnen. Technieken zoals Reciprocal Rank Fusion combineren meerdere retrievalmethodes, wat de nauwkeurigheid en robuustheid verbetert. Re-ranking presteert aanzienlijk beter dan eenstaps-retrieval in complexe domeinen.
BM25 en TF-IDF zijn snel en lichtgewicht, geschikt voor real-time systemen. Semantische scoring vereist embedding model inference, wat latentie toevoegt. LLM-gebaseerde scoring is het duurst. Kies op basis van je latentie-eisen en beschikbare rekencapaciteit.
Bedenk je prioriteiten: semantische scoring voor betekenisgerichte taken, BM25 voor snelheid en efficiëntie, hybride aanpak voor gebalanceerde prestaties. Evalueer in jouw specifieke domein met metrics zoals NDCG en Precision@k. Test meerdere methoden en meet hun impact op de uiteindelijke antwoordkwaliteit.
Volg hoe AI-systemen zoals ChatGPT, Perplexity en Google AI jouw merk vermelden en beoordeel de kwaliteit van hun bronophaling en rangschikking. Zorg dat jouw content correct wordt geciteerd en gerangschikt door AI-systemen.
Ontdek hoe het scoren van contentrelevantie door AI-algoritmen wordt gebruikt om te meten hoe goed content aansluit bij gebruikersvragen en intentie. Begrijp BM...

Leer wat RAG (Retrieval-Augmented Generation) is in AI-zoekopdrachten. Ontdek hoe RAG de nauwkeurigheid verbetert, hallucinaties vermindert en ChatGPT, Perplexi...

Ontdek wat Retrieval-Augmented Generation (RAG) is, hoe het werkt en waarom het essentieel is voor nauwkeurige AI-antwoorden. Verken RAG-architectuur, voordelen...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.