
A/B-testen voor AI-zichtbaarheid: Methodologie en Best Practices
Beheers A/B-testen voor AI-zichtbaarheid met onze uitgebreide gids. Leer GEO-experimenten, methodologie, best practices en praktijkvoorbeelden voor betere AI-mo...
10 min lezen

Geïsoleerde sandbox-omgevingen die zijn ontworpen om kunstmatige intelligentie modellen en applicaties te valideren, evalueren en debuggen voordat ze in productie worden genomen. Deze gecontroleerde ruimtes maken het mogelijk om de prestaties van AI-inhoud op verschillende platforms te testen, metrics te meten en betrouwbaarheid te waarborgen zonder live systemen te beïnvloeden of gevoelige data bloot te stellen.
Geïsoleerde sandbox-omgevingen die zijn ontworpen om kunstmatige intelligentie modellen en applicaties te valideren, evalueren en debuggen voordat ze in productie worden genomen. Deze gecontroleerde ruimtes maken het mogelijk om de prestaties van AI-inhoud op verschillende platforms te testen, metrics te meten en betrouwbaarheid te waarborgen zonder live systemen te beïnvloeden of gevoelige data bloot te stellen.
Een AI-testomgeving is een gecontroleerde, geïsoleerde computeromgeving die is ontworpen om kunstmatige intelligentiemodellen en -applicaties te valideren, evalueren en debuggen voordat ze naar productie worden uitgerold. Het dient als een sandbox waar ontwikkelaars, data scientists en QA-teams AI-modellen veilig kunnen uitvoeren, verschillende configuraties kunnen testen en prestaties kunnen meten aan de hand van vooraf bepaalde metrics, zonder live systemen te beïnvloeden of gevoelige data bloot te stellen. Deze omgevingen bootsen productiecondities na terwijl ze volledige isolatie behouden, waardoor teams problemen kunnen identificeren, modelgedrag kunnen optimaliseren en betrouwbaarheid in uiteenlopende scenario’s kunnen waarborgen. De testomgeving fungeert als een essentiële kwaliteitscontrole in de AI-ontwikkelcyclus en overbrugt de kloof tussen experimentele prototyping en bedrijfsbrede implementatie.

Een uitgebreide AI-testomgeving bestaat uit verschillende onderling verbonden technische lagen die samenwerken om volledige testmogelijkheden te bieden. De modeluitvoeringslaag verzorgt de daadwerkelijke inferentie en berekeningen en ondersteunt meerdere frameworks (PyTorch, TensorFlow, ONNX) en modeltypen (LLM’s, computer vision, tijdreeksen). De datamanagementlaag beheert testdatasets, fixtures en het genereren van synthetische data, terwijl data-isolatie en compliance behouden blijven. Het evaluatieframework omvat metrics-engines, assertiebibliotheken en scoresystemen die modeluitkomsten toetsen aan verwachte resultaten. De monitoring- en logginglaag legt uitvoeringstraces, prestatie-indicatoren, latencydata en foutlogs vast voor analyse achteraf. De orchestratie-laag beheert testworkflows, parallelle uitvoering, resource-allocatie en het provisioneren van omgevingen. Hieronder volgt een vergelijking van belangrijke architecturale componenten tussen verschillende typen testomgevingen:
| Component | LLM Testing | Computer Vision | Tijdreeksen | Multi-Modal |
|---|---|---|---|---|
| Model Runtime | Transformer-inferentie | GPU-versnelde inferentie | Sequentiële verwerking | Hybride uitvoering |
| Dataformaat | Tekst/tokens | Afbeeldingen/tensors | Numerieke reeksen | Gemengde media |
| Evaluatie-metrics | Semantische overeenkomst, hallucinatie | Nauwkeurigheid, IoU, F1-score | RMSE, MAE, MAPE | Cross-modal alignment |
| Latency-eisen | 100-500ms typisch | 50-200ms typisch | <100ms typisch | 200-1000ms typisch |
| Isolatiemethode | Container/VM | Container/VM | Container/VM | Firecracker microVM |
Moderne AI-testomgevingen moeten heterogene modelecosystemen ondersteunen, zodat teams applicaties kunnen evalueren over verschillende LLM-aanbieders, frameworks en uitroldoelen tegelijk. Multiplatform-testing stelt organisaties in staat om modeluitkomsten van OpenAI’s GPT-4, Anthropic’s Claude, Mistral en open-source alternatieven zoals Llama binnen dezelfde testomgeving te vergelijken, wat weloverwogen modelkeuzes vergemakkelijkt. Platforms zoals E2B bieden geïsoleerde sandboxes waarin code van elke LLM kan worden uitgevoerd, met ondersteuning voor Python, JavaScript, Ruby en C++ en volledige toegang tot het bestandssysteem, terminalmogelijkheden en pakketinstallatie. IntelIQ.dev maakt side-by-side vergelijking mogelijk van meerdere AI-modellen met een uniforme interface, zodat teams prompts met waarborgen en beleidssjablonen over verschillende aanbieders kunnen testen. Testomgevingen dienen het volgende te ondersteunen:
AI-testomgevingen voorzien in uiteenlopende behoeften binnen ontwikkeling, kwaliteitsborging en compliance. Ontwikkelteams gebruiken testomgevingen om modelgedrag te valideren tijdens iteratieve ontwikkeling, promptvariaties te testen, parameters te finetunen en onverwachte uitkomsten te debuggen voordat integratie plaatsvindt. Datascienceteams benutten deze omgevingen om modelprestaties op hold-out datasets te evalueren, verschillende architecturen te vergelijken en metrics zoals nauwkeurigheid, precisie, recall en F1-scores te meten. Productiemonitoring houdt in dat gedeployde modellen continu worden getest aan de hand van baseline metrics, prestatieafname wordt gedetecteerd en retrainingspijplijnen automatisch worden gestart bij overschrijding van kwaliteitsdrempels. Compliance- en securityteams valideren in testomgevingen of modellen voldoen aan regelgeving, geen bevooroordeelde uitkomsten genereren en gevoelige data correct verwerken. Enterprise-toepassingen omvatten:
Het AI-testinglandschap omvat gespecialiseerde platforms voor verschillende testscenario’s en organisatieniveaus. DeepEval is een open-source LLM-evaluatieframework met 50+ wetenschappelijk onderbouwde metrics zoals antwoordcorrectheid, semantische overeenkomst, hallucinatie-detectie en toxiciteitsscores, met native Pytest-integratie voor CI/CD-workflows. LangSmith (van LangChain) biedt uitgebreide observability, evaluatie en deployment-mogelijkheden met ingebouwde tracing, promptversiebeheer en datasetmanagement voor LLM-applicaties. E2B biedt beveiligde, geïsoleerde sandboxes op basis van Firecracker microVM’s, met code-uitvoering, sub-200ms opstarttijden, sessies tot 24 uur en integratie met grote LLM-aanbieders. IntelIQ.dev legt de nadruk op privacy-first testing met end-to-end encryptie, op rollen gebaseerde toegangscontrole en ondersteuning voor meerdere AI-modellen waaronder GPT-4, Claude en open-source alternatieven. Onderstaand een vergelijking van belangrijke mogelijkheden:
| Tool | Primair Doel | Metrics | CI/CD-integratie | Multi-model Support | Prijsmodel |
|---|---|---|---|---|---|
| DeepEval | LLM-evaluatie | 50+ metrics | Native Pytest | Beperkt | Open-source + cloud |
| LangSmith | Observability & evaluatie | Custom metrics | API-gebaseerd | LangChain-ecosysteem | Freemium + enterprise |
| E2B | Code-uitvoering | Performance metrics | GitHub Actions | Alle LLM’s | Pay-per-use + enterprise |
| IntelIQ.dev | Privacy-first testing | Custom metrics | Workflow builder | GPT-4, Claude, Mistral | Abonnement |
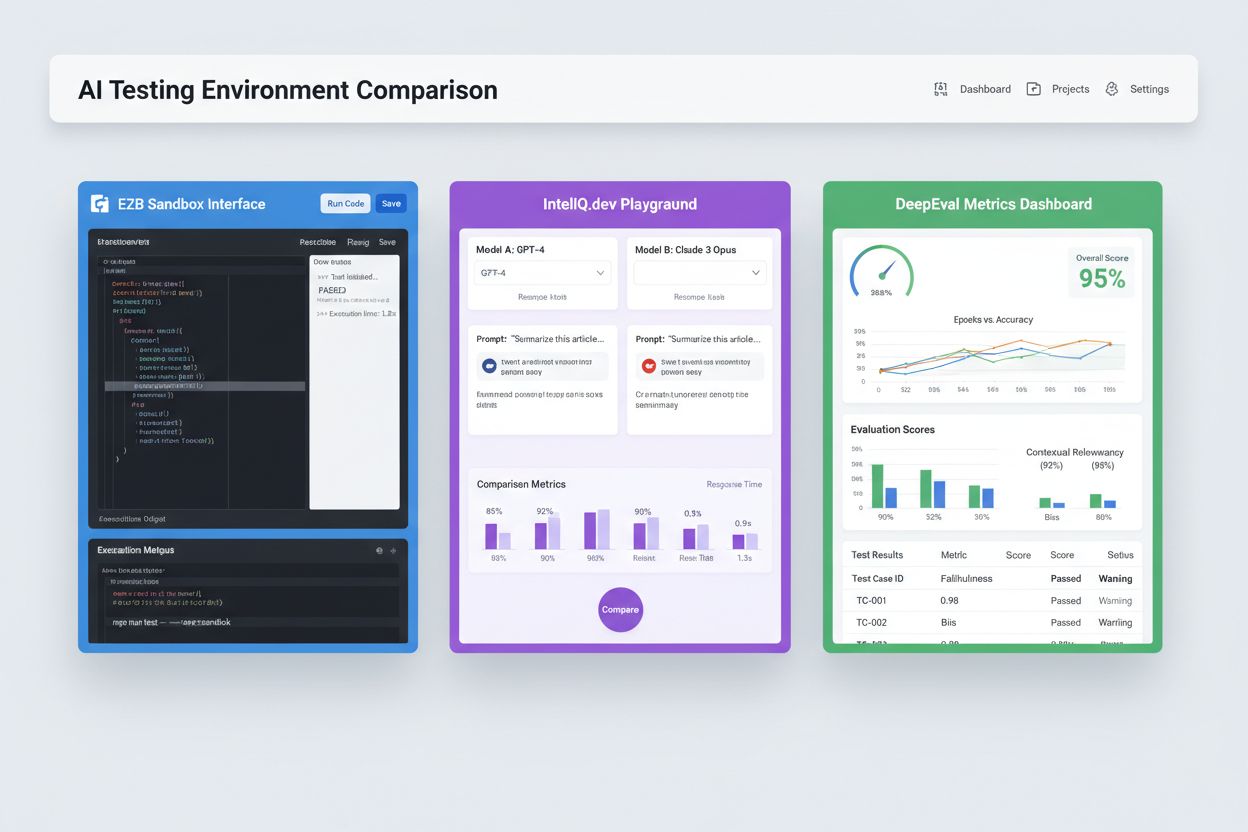
Enterprise AI-testomgevingen moeten strikte beveiligingsmaatregelen implementeren om gevoelige data te beschermen, te voldoen aan regelgeving en ongeautoriseerde toegang te voorkomen. Data-isolatie vereist dat testdata nooit uitlekt naar externe API’s of derden; platforms als E2B gebruiken Firecracker microVM’s voor volledige procesisolatie zonder gedeelde kerneltoegang. Encryptiestandaarden dienen end-to-end encryptie te bieden voor data in rust en tijdens transport, met ondersteuning voor HIPAA, SOC 2 Type 2 en GDPR-eisen. Toegangscontrole moet op rollen gebaseerd zijn, audit logging afdwingen en goedkeuringsworkflows hanteren voor gevoelige tests. Best practices omvatten: gescheiden testdatasets zonder productiedata, data masking van persoonsgegevens (PII), gebruik van synthetische data voor realistische tests zonder privacyrisico’s, regelmatige security-audits van de testinfrastructuur en documentatie van alle testresultaten voor compliance. Organisaties dienen ook biasdetectie toe te passen om discriminerend modelgedrag op te sporen, interpreteerbaarheidstools zoals SHAP of LIME te gebruiken voor inzicht in modelbeslissingen en beslissingslogging te implementeren om te traceren hoe modellen tot bepaalde uitkomsten komen voor verantwoording richting toezichthouders.
AI-testomgevingen moeten naadloos integreren met bestaande continuous integration- en continuous deployment-pijplijnen om geautomatiseerde kwaliteitscontroles en snelle iteratie mogelijk te maken. Native CI/CD-integratie zorgt ervoor dat tests automatisch worden uitgevoerd bij code commits, pull requests of geplande intervallen via platforms als GitHub Actions, GitLab CI of Jenkins. DeepEval’s Pytest-integratie stelt ontwikkelaars in staat testcases te schrijven als standaard Python-tests die binnen bestaande CI-workflows draaien, met resultaten naast traditionele unittests. Geautomatiseerde evaluatie kan modelprestaties meten, uitkomsten vergelijken met baseline-versies en deployments blokkeren als kwaliteitsdrempels niet worden gehaald. Artifactbeheer omvat het opslaan van testdatasets, modelcheckpoints en evaluatieresultaten in versiebeheersystemen of artifact repositories voor reproduceerbaarheid en audit trails. Integratiepatronen zijn onder meer:
Het landschap van AI-testomgevingen ontwikkelt zich snel om nieuwe uitdagingen op het gebied van modelcomplexiteit, schaal en diversiteit aan te pakken. Agentic testing wordt steeds belangrijker nu AI-systemen overstappen van single-model inferentie naar meerstapsworkflows waarin agents tools gebruiken, beslissingen nemen en met externe systemen communiceren—waarvoor nieuwe evaluatieframeworks nodig zijn die taakvoltooiing, veiligheid en betrouwbaarheid meten. Gedistrubueerde evaluatie maakt testen op schaal mogelijk door duizenden gelijktijdige testinstanties over cloudinfrastructuren te draaien, essentieel voor reinforcement learning en grootschalige modeltraining. Realtime monitoring verschuift van batch-evaluatie naar continue, productie-waardige testing die prestatieafname, datadrift en opkomende biases in live systemen detecteert. Observability-platforms zoals AmICited worden essentiële tools voor volledige AI-monitoring en zichtbaarheid, en bieden centrale dashboards die modelprestaties, gebruikspatronen en kwaliteitsmetrics bijhouden over hele AI-portefeuilles. Toekomstige testomgevingen zullen steeds vaker automatische remediëring bevatten, waarbij systemen niet alleen problemen detecteren maar ook automatisch retraining-pijplijnen of modelupdates starten, en cross-modale evaluatie, zodat tekst-, beeld-, audio- en videomodellen gelijktijdig getest kunnen worden binnen één framework.
Een AI-testomgeving is een geïsoleerde sandbox waarin je veilig modellen, prompts en configuraties kunt testen zonder live systemen of gebruikers te beïnvloeden. Productie-implementatie is de live omgeving waar modellen echte gebruikers bedienen. Testomgevingen stellen je in staat om problemen te detecteren, prestaties te optimaliseren en wijzigingen te valideren voordat ze de productie bereiken, waardoor risico's worden verminderd en kwaliteit wordt gewaarborgd.
Ja, moderne AI-testomgevingen ondersteunen het testen van meerdere modellen tegelijk. Platforms zoals E2B, IntelIQ.dev en DeepEval stellen je in staat om dezelfde prompt of invoer gelijktijdig te testen over verschillende LLM-aanbieders (OpenAI, Anthropic, Mistral, enz.), waardoor directe vergelijking van uitkomsten en prestatie-indicatoren mogelijk is.
Enterprise AI-testomgevingen implementeren meerdere beveiligingslagen, waaronder data-isolatie (containerisatie of microVM's), end-to-end encryptie, op rollen gebaseerde toegangscontrole, audit logging en compliance-certificeringen (SOC 2, GDPR, HIPAA). Gegevens verlaten nooit de geïsoleerde omgeving tenzij deze expliciet worden geëxporteerd, waarmee gevoelige informatie wordt beschermd.
Testomgevingen maken compliance mogelijk door audit trails van alle modelevaluaties te bieden, data masking en het genereren van synthetische data te ondersteunen, toegangscontrole af te dwingen en volledige isolatie van testdata van productieomgevingen te waarborgen. Deze documentatie en controle helpt organisaties te voldoen aan regelgeving zoals GDPR, HIPAA en SOC 2.
Belangrijke metrics hangen af van je use case: voor LLM's volg je nauwkeurigheid, semantische overeenkomst, hallucinatiepercentages en latency; voor RAG-systemen meet je context precision/recall en faithfulness; voor classificatiemodellen let je op precisie, recall en F1-scores; voor alle modellen houd je prestatieafname over tijd en bias-indicatoren bij.
De kosten variëren per platform: DeepEval is open-source en gratis; LangSmith biedt een gratis tier met betaalde plannen vanaf $39/maand; E2B gebruikt pay-per-use tarieven op basis van sandbox runtime; IntelIQ.dev werkt met abonnementen. Veel platforms bieden ook enterprise-prijzen voor grootschalige implementaties.
Ja, de meeste moderne testomgevingen ondersteunen CI/CD-integratie. DeepEval integreert native met Pytest, E2B werkt met GitHub Actions en GitLab CI, en LangSmith biedt API-gebaseerde integratie. Dit maakt geautomatiseerd testen mogelijk bij elke code commit en het afdwingen van deployment gates.
End-to-end testing behandelt je gehele AI-applicatie als een black box, waarbij het uiteindelijke resultaat wordt vergeleken met de verwachte uitkomst. Component-level testing evalueert afzonderlijke onderdelen (LLM-aanroepen, retrievers, toolgebruik) apart met tracing en instrumentatie. Component-level testing geeft diepere inzichten in waar problemen optreden, terwijl end-to-end testing het algehele systeemgedrag valideert.
AmICited volgt hoe AI-systemen jouw merk en content aanhalen op ChatGPT, Claude, Perplexity en Google AI. Krijg realtime inzicht in je AI-aanwezigheid met uitgebreide monitoring en analytics.
Beheers A/B-testen voor AI-zichtbaarheid met onze uitgebreide gids. Leer GEO-experimenten, methodologie, best practices en praktijkvoorbeelden voor betere AI-mo...
Ontdek wat een AI Visibility Center of Excellence is, de belangrijkste verantwoordelijkheden, monitoringmogelijkheden, en hoe het organisaties in staat stelt tr...

Leer hoe je promptbibliotheken bouwt en gebruikt voor handmatige AI-zichtbaarheidstesten. Doe-het-zelfgids voor het testen hoe AI-systemen jouw merk noemen op C...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.