Technische en juridische mechanismen waarmee contentmakers en rechthebbenden kunnen voorkomen dat hun werk wordt gebruikt in trainingsdatasets voor grote taalmodellen. Dit omvat robots.txt-richtlijnen, juridische opt-out-verklaringen en contractuele bescherming onder regelgeving zoals de EU AI Act.
Uitsluiten van AI-training
Technische en juridische mechanismen waarmee contentmakers en rechthebbenden kunnen voorkomen dat hun werk wordt gebruikt in trainingsdatasets voor grote taalmodellen. Dit omvat robots.txt-richtlijnen, juridische opt-out-verklaringen en contractuele bescherming onder regelgeving zoals de EU AI Act.
Wat is AI Training Opt-Out?
AI training opt-out verwijst naar de technische en juridische mechanismen waarmee contentmakers, rechthebbenden en website-eigenaren kunnen voorkomen dat hun werk wordt gebruikt in trainingsdatasets voor grote taalmodellen (LLM). Nu AI-bedrijven enorme hoeveelheden data van het internet verzamelen om steeds geavanceerdere modellen te trainen, is de mogelijkheid om te bepalen of uw content aan dit proces deelneemt essentieel geworden voor het beschermen van intellectueel eigendom en het behouden van creatieve controle. Deze opt-out-mechanismen werken op twee niveaus: technische instructies die AI-crawlers laten weten dat ze uw content moeten overslaan, en juridische kaders die contractuele rechten vastleggen om uw werk uit trainingsdatasets te houden. Inzicht in beide dimensies is cruciaal voor iedereen die zich zorgen maakt over het gebruik van hun content in het AI-tijdperk.
Technische Mechanismen: robots.txt en User Agents
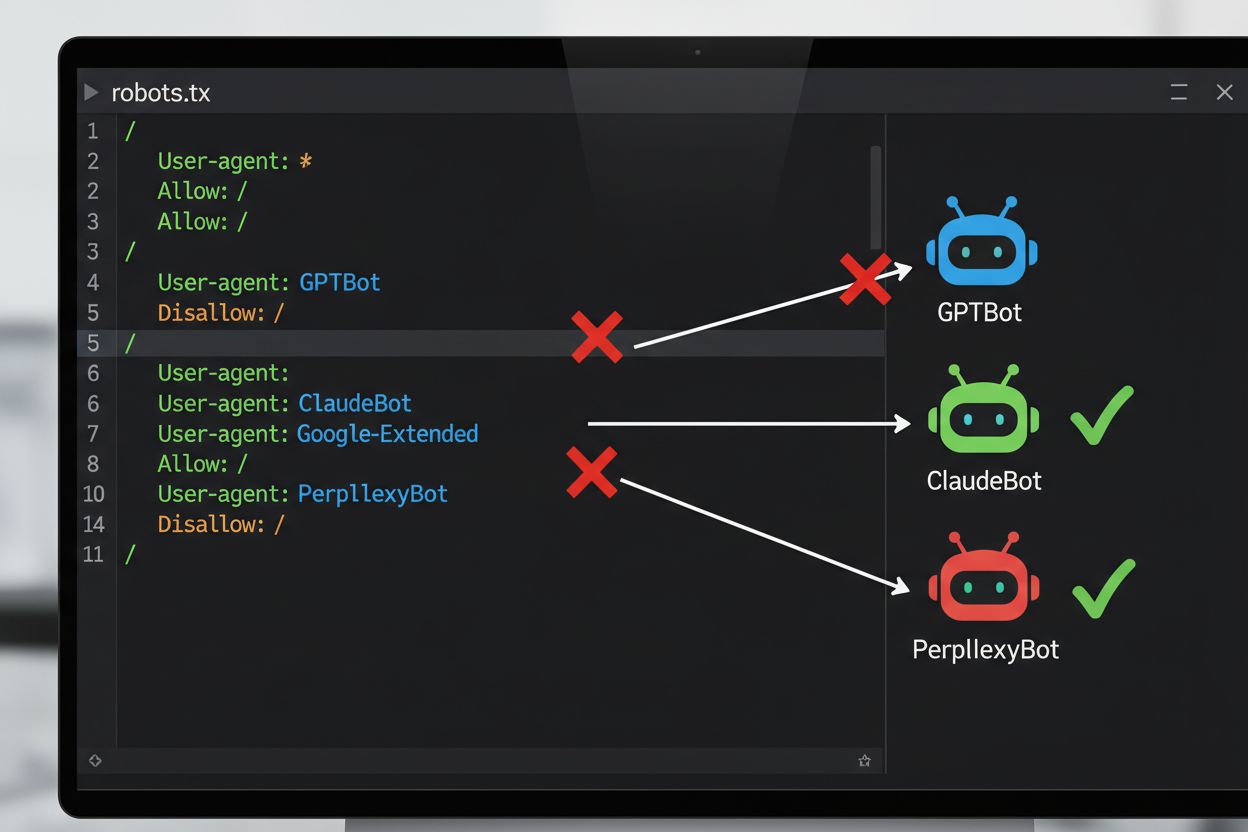
De meest voorkomende technische methode om uit te sluiten van AI-training is via het robots.txt-bestand, een eenvoudig tekstbestand in de hoofdmap van een website dat crawlerrechten communiceert aan geautomatiseerde bots. Wanneer een AI-crawler uw site bezoekt, controleert deze eerst robots.txt om te zien of toegang tot uw content is toegestaan. Door specifieke disallow-richtlijnen toe te voegen voor bepaalde crawler user agents kunt u AI-bots instrueren uw site volledig over te slaan. Elke AI-aanbieder gebruikt meerdere crawlers met unieke user agent-identificaties—dit zijn eigenlijk de “namen” waarmee bots zichzelf identificeren bij verzoeken. Zo identificeert OpenAI’s GPTBot zichzelf met de user agent-string “GPTBot”, terwijl Anthropic’s Claude “ClaudeBot” gebruikt. De syntax is eenvoudig: u geeft de naam van de user agent op en bepaalt vervolgens welke paden worden uitgesloten, zoals “Disallow: /” om de hele site te blokkeren.
AI-bedrijf
Crawlernaam
User Agent-token
Doel
OpenAI
GPTBot
GPTBot
Verzamelen van modeltrainingsdata
OpenAI
OAI-SearchBot
OAI-SearchBot
ChatGPT-zoekindexering
Anthropic
ClaudeBot
ClaudeBot
Chat-citatie ophalen
Google
Google-Extended
Google-Extended
Gemini AI-trainingsdata
Perplexity
PerplexityBot
PerplexityBot
AI-zoekindexering
Meta
Meta-ExternalAgent
Meta-ExternalAgent
AI-modeltraining
Common Crawl
CCBot
CCBot
Open dataset voor LLM-training
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Het juridische landschap rondom AI training opt-out is aanzienlijk veranderd met de invoering van de EU AI Act, die in 2024 van kracht werd en bepalingen uit de Text and Data Mining (TDM) Directive integreert. Volgens deze regelgeving mogen AI-ontwikkelaars auteursrechtelijk beschermde werken alleen gebruiken voor machine learning-doeleinden als ze wettige toegang hebben tot de content en de rechthebbende niet uitdrukkelijk het recht heeft voorbehouden hun werk uit te sluiten van text- en datamining. Dit creëert een formeel juridisch opt-out-mechanisme: rechthebbenden kunnen opt-out-voorbehouden bij hun werken indienen, waarmee ze het gebruik in AI-training zonder expliciete toestemming effectief verhinderen. De EU AI Act betekent een duidelijke kentering ten opzichte van het eerdere “move fast and break things”-beleid en bepaalt dat bedrijven die AI-modellen trainen moeten controleren of rechthebbenden hun content hebben voorbehouden en technische en organisatorische maatregelen moeten nemen om onbedoeld gebruik van uitgesloten werken te voorkomen. Dit juridische kader geldt in de hele Europese Unie en beïnvloedt hoe internationale AI-bedrijven omgaan met dataverzameling en trainingspraktijken.
Hoe Werken Opt-Out Mechanismen in de Praktijk?
Het implementeren van een opt-out-mechanisme vereist zowel technische configuratie als juridische documentatie. Aan de technische kant voegen website-eigenaren disallow-richtlijnen toe aan hun robots.txt-bestand voor specifieke AI-crawler user agents, die door conforme crawlers worden gerespecteerd bij een sitebezoek. Aan de juridische kant kunnen rechthebbenden opt-out-verklaringen indienen bij collectieve beheersorganisaties—zo hebben de Nederlandse beeldrechtorganisatie Pictoright en de Franse muziekrechtenorganisatie SACEM formele opt-out-procedures waarmee makers hun rechten tegen AI-training kunnen voorbehouden. Veel websites en contentmakers nemen nu expliciete opt-out-verklaringen op in hun algemene voorwaarden of metadata, waarin wordt aangegeven dat hun content niet gebruikt mag worden voor AI-modeltraining. De effectiviteit van deze mechanismen hangt echter af van de naleving door crawlers: terwijl grote partijen als OpenAI, Google en Anthropic publiekelijk hebben verklaard robots.txt-richtlijnen en opt-out-voorbehouden te respecteren, zorgt het ontbreken van een centraal afdwingingsmechanisme ervoor dat het controleren of opt-out-verzoeken daadwerkelijk worden nageleefd voortdurende monitoring en verificatie vereist.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Uitdagingen en Beperkingen van Opt-Out
Ondanks de beschikbaarheid van opt-out-mechanismen zijn er aanzienlijke uitdagingen die de effectiviteit beperken:
Vrijwillige standaard: robots.txt is een gentlemen’s agreement zonder juridisch afdwingingsmechanisme, waardoor niet-conforme crawlers uw richtlijnen kunnen negeren
Crawleromzeiling: geavanceerde bots kunnen user agent-strings vervalsen en zich voordoen als legitieme browsers, waardoor user agent-blokkering wordt omzeild
IP-rotatie: scrapers kunnen honderden duizenden IP-adressen via proxies of botnets gebruiken, waardoor IP-blokkering weinig effect heeft
Onvolledige dekking: robots.txt stopt ongeveer 40-60% van de AI-bots, waardoor een aanzienlijk deel onbelemmerd blijft zonder aanvullende technische maatregelen
Malafide crawlers: niet-betrouwbare AI-bedrijven en onafhankelijke scrapers kunnen opt-out-mechanismen volledig negeren en opereren in juridische grijze gebieden
Handhavingstekorten: zelfs als opt-out-schendingen plaatsvinden, zijn juridische procedures kostbaar en traag, met onzekere uitkomsten bij de rechter
Voor organisaties die sterkere bescherming willen dan robots.txt alleen biedt, kunnen verschillende aanvullende technische methoden worden ingezet. User agent-filtering op server- of firewallniveau kan verzoeken van specifieke crawler-identificaties blokkeren voordat ze uw applicatie bereiken, hoewel dit vatbaar blijft voor spoofing. IP-adresblokkering kan gericht zijn op bekende crawler-IP-reeksen die door grote AI-bedrijven worden gepubliceerd, maar vasthoudende scrapers kunnen dit omzeilen via proxy-netwerken. Rate limiting en throttling kunnen scrapers vertragen door het aantal toegestane verzoeken per seconde te beperken, waardoor scrapen economisch onaantrekkelijk wordt, hoewel geavanceerde bots verzoeken via meerdere IP’s kunnen verspreiden om limieten te omzeilen. Authenticatievereisten en betaalmuurconstructies bieden sterke bescherming door toegang te beperken tot ingelogde gebruikers of betalende klanten, waardoor geautomatiseerd scrapen effectief wordt voorkomen. Device fingerprinting en gedragsanalyse kunnen bots detecteren door patronen te analyseren zoals browser-API’s, TLS-handshakes en interactiepatronen die afwijken van menselijk gedrag. Sommige organisaties zetten zelfs honeypots en tarpits in—verborgen links of oneindige linkstructuren die alleen bots zouden volgen—om crawlerresources te verspillen en mogelijk hun trainingsdata te vervuilen met waardeloze data.
Praktijkvoorbeelden en Casestudy’s
De spanningen tussen AI-bedrijven en contentmakers hebben geleid tot verschillende spraakmakende confrontaties die de praktische uitdagingen van opt-out-handhaving illustreren. Reddit nam in 2023 rigoureuze maatregelen door de API-toegangsprijzen fors te verhogen, specifiek om AI-bedrijven te laten betalen voor data, waardoor ongeautoriseerde scrapers werden buitengesloten en bedrijven als OpenAI en Anthropic tot licentieovereenkomsten werden gedwongen. Twitter/X voerde nog extremere maatregelen in door tijdelijk alle niet-geregistreerde toegang tot tweets te blokkeren en het aantal te lezen tweets voor ingelogde gebruikers te beperken, expliciet gericht op dataverzamelaars. Stack Overflow blokkeerde aanvankelijk OpenAI’s GPTBot in hun robots.txt-bestand vanwege licentieproblemen met door gebruikers gegenereerde code, maar trok de blokkade later weer in—mogelijk na onderhandelingen met OpenAI. Nieuwsmedia reageerden massaal: in 2023 blokkeerde meer dan 50% van de grote nieuwssites AI-crawlers, waaronder The New York Times, CNN, Reuters en The Guardian, door GPTBot aan hun disallow-lijsten toe te voegen. Sommige nieuwsorganisaties stapten naar de rechter, zoals The New York Times die een auteursrechtzaak aanspande tegen OpenAI, terwijl anderen zoals Associated Press licentiedeals sloten om hun content te gelde te maken. Deze voorbeelden tonen aan dat hoewel opt-out-mechanismen bestaan, hun effectiviteit afhangt van zowel technische implementatie als de bereidheid juridische stappen te zetten bij overtredingen.
Monitoring- en Compliance Tools
Het implementeren van opt-out-mechanismen is slechts de helft van het werk; nagaan of ze daadwerkelijk werken vereist voortdurende monitoring en testen. Diverse tools kunnen helpen bij het valideren van uw configuratie: Google Search Console bevat een robots.txt-tester voor Googlebot-specifieke validatie, terwijl Merkle’s Robots.txt Tester en TechnicalSEO.com’s tool individueel crawlergedrag testen voor specifieke user agents. Voor uitgebreide monitoring of AI-bedrijven uw opt-out-richtlijnen daadwerkelijk respecteren, bieden platforms als AmICited.com gespecialiseerde monitoring waarmee wordt bijgehouden hoe AI-systemen uw merk en content aanhalen in GPT’s, Perplexity, Google AI Overviews en andere AI-platformen. Dit type monitoring is bijzonder waardevol omdat het niet alleen laat zien of crawlers uw site bezoeken, maar ook of uw content daadwerkelijk verschijnt in AI-gegenereerde antwoorden—wat aangeeft of uw opt-out in de praktijk werkt. Regelmatige analyse van serverlogs kan ook onthullen welke crawlers uw site proberen te benaderen en of ze uw robots.txt-richtlijnen naleven, hoewel dit technische expertise vereist om correct te interpreteren.
Best Practices voor Contentmakers
Om uw content effectief te beschermen tegen ongeautoriseerd gebruik voor AI-training, hanteert u het best een gelaagde aanpak met technische en juridische maatregelen. Ten eerste, implementeer robots.txt-richtlijnen voor alle grote AI-trainingcrawlers (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot en anderen), in de wetenschap dat dit een basisverdediging biedt tegen conforme partijen. Ten tweede, voeg expliciete opt-out-verklaringen toe aan de algemene voorwaarden en metadata van uw website, waarmee u duidelijk aangeeft dat uw content niet gebruikt mag worden voor AI-modeltraining—dit verstevigt uw juridische positie bij overtredingen. Ten derde, monitor uw configuratie regelmatig met testtools en serverlogs om te controleren of crawlers uw richtlijnen naleven en werk uw robots.txt elk kwartaal bij omdat er voortdurend nieuwe AI-crawlers bijkomen. Ten vierde, overweeg aanvullende technische maatregelen zoals user agent-filtering of rate limiting als u de technische middelen heeft, in de wetenschap dat deze extra bescherming bieden tegen geavanceerdere scrapers. Tot slot, documenteer uw opt-out-inspanningen grondig, want deze documentatie is essentieel als u juridische stappen moet ondernemen tegen bedrijven die uw richtlijnen negeren. Onthoud dat opt-out geen eenmalige configuratie is, maar een voortdurend proces dat waakzaamheid en aanpassing vraagt naarmate het AI-landschap blijft veranderen.
Veelgestelde vragen
Wat is het verschil tussen robots.txt opt-out en juridische opt-out?
robots.txt is een technische, vrijwillige standaard die crawlers instrueert om uw content over te slaan, terwijl juridische opt-out het indienen van formele voorbehouden bij auteursrechtenorganisaties of het opnemen van contractuele clausules in uw servicevoorwaarden inhoudt. robots.txt is eenvoudiger te implementeren maar biedt geen afdwingbaarheid, terwijl juridische opt-out sterkere juridische bescherming biedt, maar meer formele procedures vereist.
Respecteren alle AI-bedrijven robots.txt-richtlijnen?
Grote AI-bedrijven zoals OpenAI, Google, Anthropic en Perplexity hebben publiekelijk verklaard dat ze robots.txt-richtlijnen respecteren. Echter, robots.txt is een vrijwillige standaard zonder afdwingingsmechanisme, dus niet-conforme crawlers en malafide scrapers kunnen uw richtlijnen volledig negeren.
Heeft het blokkeren van AI-training bots invloed op mijn zoekmachineresultaten?
Nee. Het blokkeren van AI-trainingcrawlers zoals GPTBot en ClaudeBot heeft geen invloed op uw Google- of Bing-zoekresultaten omdat traditionele zoekmachines andere crawlers gebruiken (Googlebot, Bingbot) die onafhankelijk werken. Blokkeer deze alleen als u volledig uit de zoekresultaten wilt verdwijnen.
Hoe gaat de EU AI Act om met opt-out?
De EU AI Act vereist dat AI-ontwikkelaars wettige toegang hebben tot content en de opt-out-voorbehouden van rechthebbenden moeten respecteren. Rechthebbenden kunnen opt-out-verklaringen indienen bij hun werken, waardoor effectief het gebruik in AI-training zonder expliciete toestemming wordt voorkomen. Dit creëert een formeel juridisch mechanisme om content te beschermen tegen ongeautoriseerd trainingsgebruik.
Kan ik opt-out gebruiken om te voorkomen dat mijn content in AI-zoekresultaten verschijnt?
Dat hangt af van het specifieke mechanisme. Het blokkeren van alle AI-crawlers voorkomt dat uw content verschijnt in AI-zoekresultaten, maar hierdoor verdwijnt u ook volledig van AI-gestuurde zoekplatforms. Sommige uitgevers kiezen voor selectieve blokkering—zoekcrawlers toestaan, maar trainingscrawlers blokkeren—om zichtbaarheid in AI-zoek te behouden en tegelijkertijd content te beschermen tegen modeltraining.
Wat gebeurt er als een AI-bedrijf mijn opt-out negeert?
Als een AI-bedrijf uw opt-out-richtlijnen negeert, kunt u juridische stappen ondernemen wegens inbreuk op het auteursrecht of contractbreuk, afhankelijk van uw jurisdictie en de specifieke omstandigheden. Juridische procedures zijn echter kostbaar en traag, met onzekere uitkomsten. Daarom is monitoring en documentatie van uw opt-out-inspanningen cruciaal.
Hoe vaak moet ik mijn opt-out-configuratie bijwerken?
Controleer en werk uw robots.txt-configuratie minimaal elk kwartaal bij. Er verschijnen voortdurend nieuwe AI-crawlers, en bedrijven introduceren regelmatig nieuwe user agents. Bijvoorbeeld: Anthropic heeft hun 'anthropic-ai' en 'Claude-Web' bots samengevoegd tot 'ClaudeBot', waarmee de nieuwe bot tijdelijk onbeperkt toegang kreeg tot sites die hun regels niet hadden bijgewerkt.
Is opt-out effectief tegen alle AI-crawlers?
Opt-out is effectief tegen conforme, betrouwbare AI-bedrijven die robots.txt en juridische kaders respecteren. Het is echter minder effectief tegen malafide crawlers en niet-conforme scrapers die opereren in juridische grijze gebieden. robots.txt stopt ongeveer 40-60% van de AI-bots, daarom wordt een gelaagde aanpak met meerdere technische en juridische maatregelen aanbevolen.
Monitor hoe AI uw content gebruikt
Volg of uw content verschijnt in AI-gegenereerde antwoorden op ChatGPT, Perplexity, Google AI Overviews en andere AI-platforms met AmICited.
Hoe optimaliseer je jouw content voor AI-trainingsdata en AI-zoekmachines
Leer hoe je jouw content optimaliseert voor opname in AI-trainingsdata. Ontdek best practices om je website vindbaar te maken voor ChatGPT, Gemini, Perplexity e...
Wat is door Gebruikers Gegenereerde Content voor AI? Definitie en Toepassingen
Ontdek wat door gebruikers gegenereerde content voor AI is, hoe het wordt gebruikt om AI-modellen te trainen, de toepassingen ervan in verschillende sectoren en...
Hoe je je afmeldt voor AI-training op grote platforms
Compleet overzicht van het afmelden voor AI-trainingsgegevensverzameling bij ChatGPT, Perplexity, LinkedIn en andere platforms. Leer stapsgewijze instructies om...
8 min lezen
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.