Google-Extended
Lees alles over Google-Extended, het user-agent-token waarmee uitgevers kunnen bepalen of hun content gebruikt wordt voor AI-training in Gemini en Vertex AI. Be...
6 min lezen
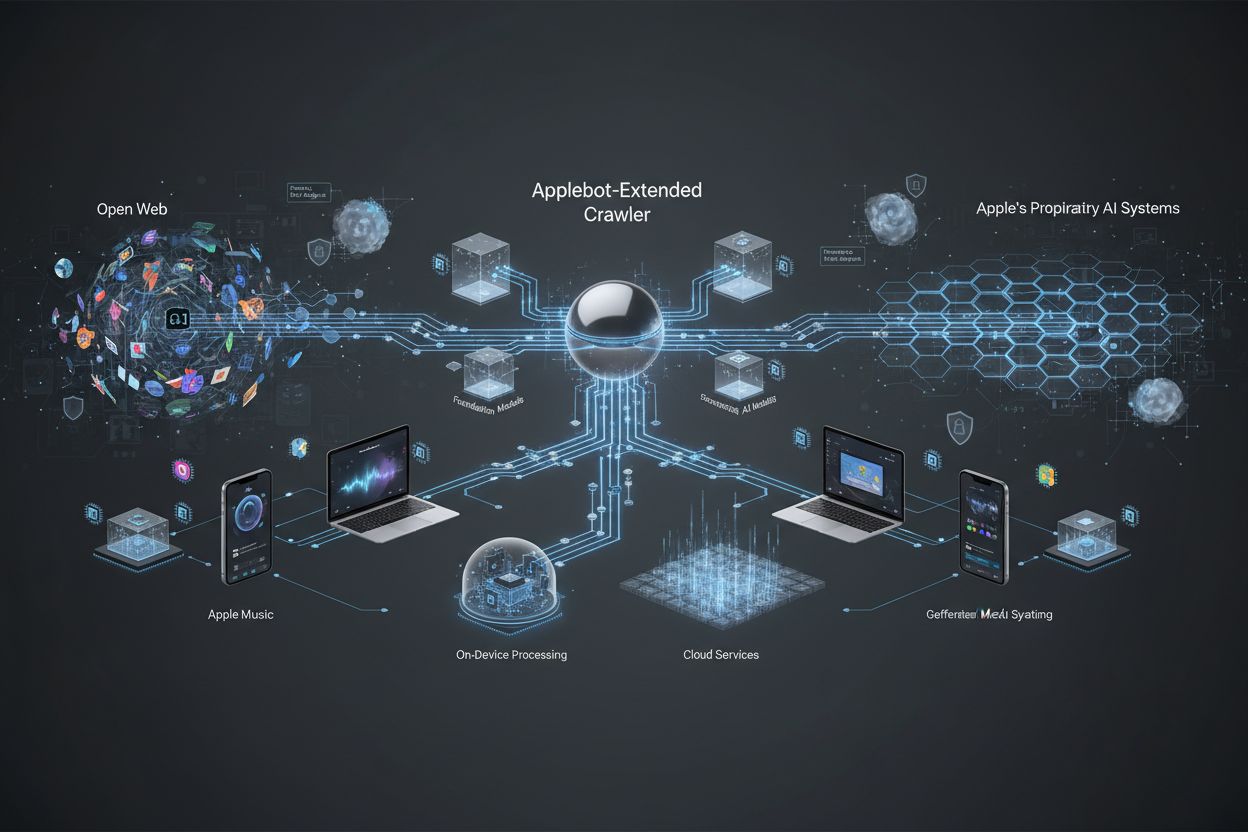
Apple’s gespecialiseerde webcrawler die content evalueert voor het trainen van Apple Intelligence en generatieve AI-modellen. Het functioneert als een secundair evaluatiemechanisme naast de standaard Applebot en bepaalt welke openbaar beschikbare webcontent geschikt is voor opname in Apple’s foundation models en LLM’s. Website-eigenaren kunnen de toegang ervan onafhankelijk van de standaard Applebot beheren via robots.txt-richtlijnen.
Apple's gespecialiseerde webcrawler die content evalueert voor het trainen van Apple Intelligence en generatieve AI-modellen. Het functioneert als een secundair evaluatiemechanisme naast de standaard Applebot en bepaalt welke openbaar beschikbare webcontent geschikt is voor opname in Apple's foundation models en LLM's. Website-eigenaren kunnen de toegang ervan onafhankelijk van de standaard Applebot beheren via robots.txt-richtlijnen.
Applebot-Extended is een gespecialiseerde webcrawler van Apple die de mogelijkheden van de standaard Applebot uitbreidt om content te verzamelen en te evalueren, specifiek voor het trainen van Apple Intelligence-systemen. Waar de oorspronkelijke Applebot vooral wordt gebruikt voor zoek- en indexeringsdoeleinden, functioneert Applebot-Extended als een aparte crawler die zich richt op het verzamelen van hoogwaardige content die gebruikt kan worden om Apple’s generatieve AI- en machine learning-modellen te verbeteren. Deze crawler weerspiegelt Apple’s inzet voor de ontwikkeling van geavanceerde AI-trainingsdatasets door systematisch webcontent te identificeren en verwerken die aan specifieke kwaliteitsnormen voldoet. Het onderscheid tussen standaard Applebot en Applebot-Extended is belangrijk voor website-eigenaren, omdat de twee crawlers verschillende doelen dienen en onafhankelijk kunnen worden beheerd via robots.txt-richtlijnen.
Applebot-Extended werkt binnen een tweeledig crawlsysteem waarbij eerste contentontdekking door de standaard Applebot wordt opgevolgd door een tweede evaluatiefase uitgevoerd door Applebot-Extended. Wanneer Applebot-Extended een webpagina bezoekt, voert het een grondige contentevaluatie uit om te bepalen of het materiaal voldoet aan Apple’s normen voor opname in AI-trainingsdatasets. De crawler identificeert zich via een specifieke user agent-string die hem onderscheidt van de standaard Applebot, waardoor websitebeheerders de twee crawlers kunnen onderscheiden in serverlogs en analysetools. Applebot-Extended evalueert content op meerdere criteria, waaronder relevantie, nauwkeurigheid, originaliteit en naleving van kwaliteitsrichtlijnen die ervoor zorgen dat alleen hoogwaardige content bijdraagt aan Apple Intelligence-systemen.
| Kenmerk | Applebot | Applebot-Extended |
|---|---|---|
| Primair doel | Algemene indexering en zoeken | Verzamelen van AI-trainingsdata |
| Contentfocus | Alle webcontent | Hoogwaardige, gecureerde content |
| User Agent | Applebot | Applebot-Extended |
| Evaluatiediepte | Standaard crawling | Geavanceerde kwaliteitsbeoordeling |
| Blokkeringsmethode | robots.txt-richtlijnen | Afzonderlijke robots.txt-regels |

Apple Intelligence is Apple’s geïntegreerde suite van AI-gestuurde functies die gebruikerservaringen verbeteren op iOS, iPadOS, macOS en andere Apple-platforms via verwerking op het apparaat en in de cloud. De generatieve AI-mogelijkheden, aangedreven door data van Applebot-Extended, omvatten geavanceerde schrijftools, beeldgeneratie, intelligente zoekverfijningen en contextbewuste assistentfunctionaliteit die gebruikmaakt van foundation models en grote taalmodellen (LLM’s) getraind op gecureerde webcontent. Deze systemen maken functies mogelijk zoals Writing Tools voor e-mail- en documentcompositie, Image Playground voor creatieve contentgeneratie en verbeterde Siri-mogelijkheden die complexe gebruikersaanvragen met meer nuance en nauwkeurigheid begrijpen. Apple’s aanpak benadrukt privacyvriendelijke AI door veel van deze intelligentie op het apparaat zelf te verwerken, terwijl Applebot-Extended ervoor zorgt dat de trainingsdata die deze systemen ondersteunen afkomstig zijn van hoogwaardige, diverse bronnen op het web. De selectieve benadering van contentverzameling door de crawler heeft direct invloed op de verfijning en betrouwbaarheid van Apple Intelligence-functies die wereldwijd aan miljoenen gebruikers beschikbaar zijn.
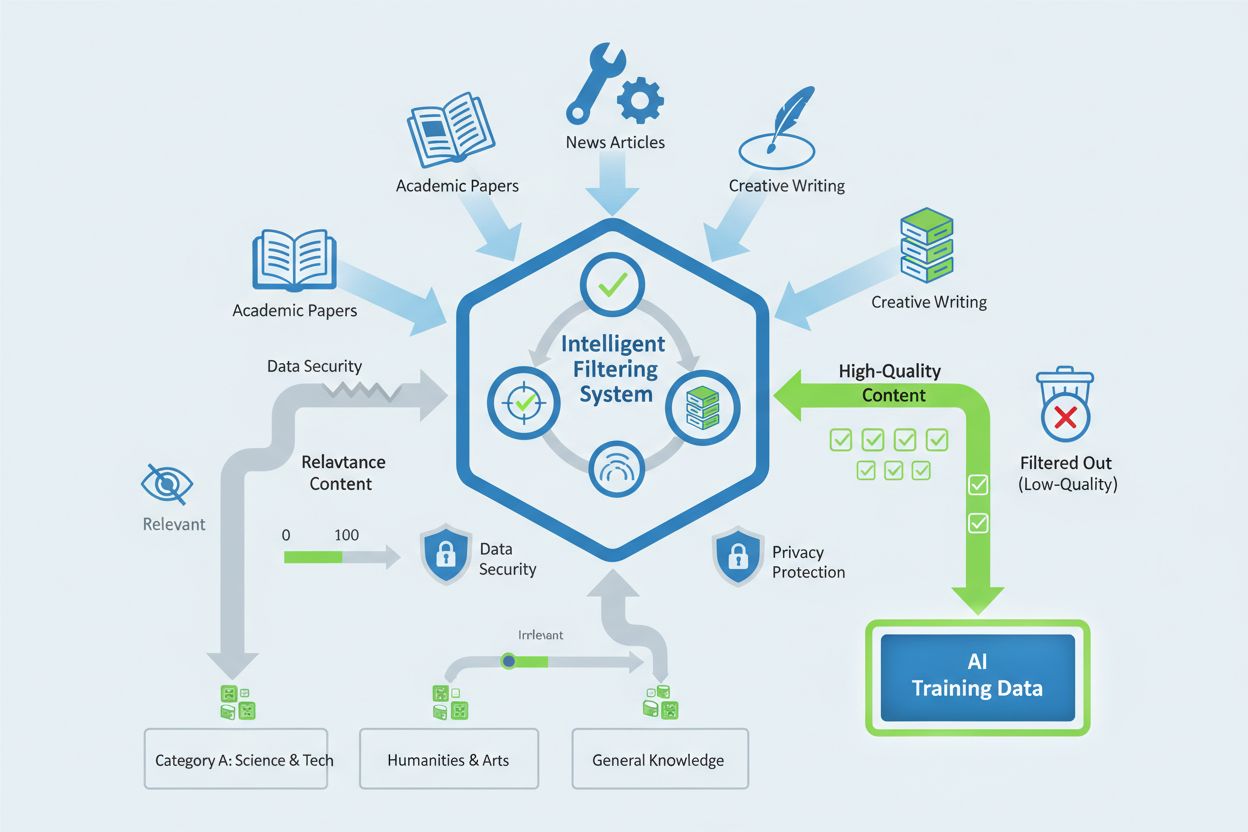
Applebot-Extended richt zich op specifieke categorieën content die een hoge informatie- en betrouwbaarheidswaarde tonen voor AI-trainingsdoeleinden. De crawler geeft prioriteit aan content op basis van de volgende criteria:
De crawler gebruikt geavanceerde datafiltermechanismen om content van lage kwaliteit te verwijderen, waaronder spam, dubbele inhoud en materiaal met minimale informatiewaarde. Apple past privacybeschermende evaluatietechnieken toe die de kwaliteit van content beoordelen zonder onnodig persoonlijke gegevens of gevoelige informatie op te slaan. Het selectieproces omvat geautomatiseerde kwaliteitsscoresystemen die factoren als bronbetrouwbaarheid, originaliteit, feitelijke juistheid en relevantie voor de trainingsdoelen van Apple Intelligence beoordelen. Website-eigenaren kunnen de kans op opname van hun content vergroten door hoge redactionele standaarden te hanteren, originele en gezaghebbende content te waarborgen en praktijken te vermijden die kunstmatig kwaliteitsstatistieken opdrijven.
Websitebeheerders kunnen de toegang van Applebot-Extended tot hun content beheren via robots.txt-richtlijnen, waarmee ze het crawlgedrag onafhankelijk van de standaard Applebot kunnen reguleren. Om Applebot-Extended specifiek te blokkeren terwijl de standaard Applebot wel mag crawlen, kunnen website-eigenaren gerichte regels toepassen die onderscheid maken tussen de twee crawlers aan de hand van hun user agent-identificatie. Het belangrijkste onderscheid is dat het blokkeren van de standaard Applebot niet automatisch Applebot-Extended blokkeert, en omgekeerd—elke crawler moet afzonderlijk worden beheerd als verschillende toegangsregels gewenst zijn. Het blokkeren van Applebot-Extended heeft minimale directe SEO-gevolgen, omdat het geen invloed heeft op zoekmachineresultaten, maar het voorkomt wel dat je content wordt gebruikt voor Apple Intelligence-training, wat de zichtbaarheid van je site in Apple’s AI-functies en -diensten kan beperken.
# Blokkeer alleen Applebot-Extended en sta standaard Applebot toe
User-agent: Applebot-Extended
Disallow: /
# Sta standaard Applebot toe
User-agent: Applebot
Allow: /
# Blokkeer zowel Applebot als Applebot-Extended
User-agent: Applebot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Blokkeer specifieke mappen voor Applebot-Extended
User-agent: Applebot-Extended
Disallow: /private/
Disallow: /admin/
Allow: /public/
Apple hanteert een privacygerichte aanpak voor de werking van Applebot-Extended en benadrukt dat contentverzameling voor AI-training de privacy van gebruikers en gegevensbeschermingswetten in verschillende jurisdicties respecteert. Het bedrijf implementeert technische en organisatorische maatregelen om te voorkomen dat persoonlijke gegevens onnodig worden verzameld of bewaard tijdens het crawlen en evalueren, waarbij contentbeoordeling gericht is op informatiewaarde en niet op het extraheren van persoonlijke informatie. Website-eigenaren en contentmakers behouden individuele privacyrechten met betrekking tot hun data, waaronder het recht om informatie op te vragen over het gebruik van hun content en verwijderingsverzoeken in te dienen onder toepasselijke privacywetgeving zoals de AVG en CCPA. Apple biedt het Apple Intelligence Privacy Inquiries-formulier als formeel mechanisme waarmee individuen vragen, zorgen of verzoeken kunnen indienen met betrekking tot de behandeling van hun content of persoonlijke gegevens binnen Apple Intelligence-systemen. Deze gestructureerde aanpak van privacy waarborgt dat de voordelen van geavanceerde AI-capaciteiten worden afgewogen tegen fundamentele rechten op gegevensbescherming en gebruikersautonomie.
Website-eigenaren kunnen bezoeken van Applebot-Extended detecteren door serverlogs te monitoren en user agent-strings te analyseren, waarbij “Applebot-Extended” zichtbaar is in het crawler-identificatieveld. Gespecialiseerde analysetools zoals Dark Visitors en UseHall bieden extra inzicht in AI-crawlerverkeer, zodat beheerders crawlfrequentie, patronen en resourcegebruik van Applebot-Extended-bezoeken kunnen volgen. Deze monitoringsoplossingen helpen website-eigenaren het effect van AI-crawlers op serverbronnen en bandbreedte te begrijpen, waardoor ze weloverwogen beslissingen kunnen nemen over crawltoegangsbeleid en optimalisatiestrategieën. Door goede verkeersdetectie- en loggingmechanismen te implementeren, kunnen beheerders Applebot-Extended-activiteit onderscheiden van andere crawlers en menselijk bezoek, en waardevolle inzichten verkrijgen in de bijdrage van hun content aan Apple’s AI-trainingsinfrastructuur.
Applebot-Extended functioneert binnen een bredere omgeving van AI-gerichte webcrawlers die verschillende doelen dienen en onder verschillende beleidsregels opereren, elk aansluitend bij de AI-ontwikkelings- en dataverzamelingsstrategie van hun moederbedrijf. Googlebot wordt vooral gebruikt voor Google’s zoekindexering en ranking, met aparte crawlers zoals Googlebot-Extended voor contentevaluatie ten behoeve van Google’s AI-systemen—functioneel vergelijkbaar met Apple’s tweelaagse benadering, maar op veel grotere schaal. Bingbot, de crawler van Microsoft, ondersteunt zowel zoekindexering als AI-training voor Copilot en andere generatieve AI-diensten, maar hanteert andere evaluatiecriteria en privacykaders. De ChatGPT-crawler (van OpenAI) richt zich specifiek op het verzamelen van content voor het trainen van grote taalmodellen, met expliciete opt-outmechanismen en andere gegevensgebruiksafspraken dan Apple’s aanpak. In tegenstelling tot sommige concurrenten onderscheidt Applebot-Extended zich door Apple’s nadruk op verwerking op het apparaat en privacybescherming, met beperkte cloudopslag van data en duidelijke opt-outmogelijkheden via robots.txt en formele privacyverzoeken. Vergelijkend onderzoek laat zien dat hoewel alle grote technologiebedrijven AI-crawlers gebruiken, hun evaluatiecriteria, gegevensbewaarbeleid en gebruikerscontrolemogelijkheden aanzienlijk verschillen, wat hun visie op AI, privacy en rechten van contentmakers weerspiegelt. Website-eigenaren doen er goed aan deze verschillen te begrijpen bij het bepalen van crawler-toegang, aangezien het beleid en de impact van elke crawler op het gebruik van hun content in AI-systemen sterk uiteenloopt.
Applebot is Apple's primaire webcrawler die wordt gebruikt voor zoekindexering en functies als Spotlight en Siri-zoekopdrachten. Applebot-Extended is een secundaire crawler die content evalueert die al door Applebot is geïndexeerd om te bepalen of het geschikt is voor het trainen van Apple's generatieve AI-modellen. Ze dienen verschillende doelen en kunnen onafhankelijk worden beheerd via robots.txt.
Je kunt Applebot-Extended blokkeren door specifieke regels toe te voegen aan je robots.txt-bestand. Gebruik 'User-agent: Applebot-Extended' gevolgd door 'Disallow: /' om de hele site te blokkeren, of specificeer bepaalde mappen. Dit voorkomt dat je content wordt gebruikt voor Apple Intelligence-training terwijl de standaard Applebot je site nog steeds mag indexeren voor zoekdoeleinden.
Het blokkeren van Applebot-Extended heeft minimale directe SEO-impact omdat het geen invloed heeft op zoekmachinerankings. Het voorkomt echter wel dat je content wordt gebruikt voor Apple Intelligence-training, wat je zichtbaarheid in Apple's AI-functies en diensten in de toekomst kan verminderen.
Applebot-Extended richt zich op hoogwaardige content, waaronder academische artikelen, technische documentatie, professionele nieuwsberichten, originele creatieve teksten en content van erkende experts. De crawler evalueert content op geloofwaardigheid, originaliteit, feitelijke juistheid en relevantie voor AI-trainingsdoeleinden.
Nee. Apple stelt expliciet dat het geen privépersoonlijke gegevens van gebruikers of gebruikersinteracties gebruikt bij het trainen van foundation models voor Apple Intelligence. Het bedrijf gebruikt alleen openbaar beschikbare webcontent, gelicentieerd materiaal en synthetisch aangemaakte data. Apple implementeert privacybeschermende maatregelen om persoonlijke informatie uit trainingsdatasets te verwijderen.
Je kunt bezoeken van Applebot-Extended detecteren door serverlogs te monitoren op de 'Applebot-Extended' user agent-string. Gespecialiseerde analysetools zoals Dark Visitors en UseHall geven extra inzicht in AI-crawlerverkeer, zodat je crawlfrequentie, patronen en resourcegebruik kunt volgen.
Apple Intelligence is Apple's geïntegreerde suite van AI-functies op iOS, iPadOS, macOS en andere platforms. Applebot-Extended verzamelt hoogwaardige webcontent die de foundation models en grote taalmodellen traint die functies als Writing Tools, Image Playground en verbeterde Siri-mogelijkheden mogelijk maken.
Ja. Apple biedt het Apple Intelligence Privacy Inquiries-formulier waarmee individuen verzoeken kunnen indienen over hoe hun content of persoonlijke gegevens worden behandeld in verband met Apple Intelligence-systemen. Je kunt ook standaard robots.txt-richtlijnen gebruiken om crawling door Applebot-Extended uit te sluiten.
Houd bij hoe jouw content verschijnt in Apple Intelligence en andere AI-systemen met het uitgebreide AI-monitoringsplatform van AmICited.
Lees alles over Google-Extended, het user-agent-token waarmee uitgevers kunnen bepalen of hun content gebruikt wordt voor AI-training in Gemini en Vertex AI. Be...

Ontdek wat Google-Extended is, hoe het werkt en of je het moet blokkeren in je robots.txt. Begrijp het verschil tussen AI-trainingscontrole en AI Overviews.

Complete gids voor de PerplexityBot-crawler - begrijp hoe het werkt, beheer toegang, monitor citaties en optimaliseer voor zichtbaarheid in Perplexity AI. Leer ...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.