
Wat is de noai meta tag en hoe beschermt het je content tegen AI?
Leer meer over de noai meta tag, hoe deze werkt om AI-trainingsdataverzameling te voorkomen, de beperkingen ervan, en hoe je deze op je website implementeert om...
7 min lezen

Een HTML-meta-tag die aan AI-trainingssystemen en webcrawlers aangeeft dat de website-inhoud niet gebruikt mag worden voor het trainen van machine learning-modellen. Oorspronkelijk geïntroduceerd door DeviantArt, dient het als een mechanisme voor inhoudsbescherming en als opt-out-signaal voor makers die zich zorgen maken over ongeoorloofde AI-gegevensverzameling.
Een HTML-meta-tag die aan AI-trainingssystemen en webcrawlers aangeeft dat de website-inhoud niet gebruikt mag worden voor het trainen van machine learning-modellen. Oorspronkelijk geïntroduceerd door DeviantArt, dient het als een mechanisme voor inhoudsbescherming en als opt-out-signaal voor makers die zich zorgen maken over ongeoorloofde AI-gegevensverzameling.
De NoAI-meta-tag is een mechanisme voor inhoudsbescherming dat wordt geïmplementeerd als een HTML-meta-tag die aan AI-trainingssystemen en webcrawlers aangeeft dat de inhoud van een website niet mag worden gebruikt voor machine learning model-training. Oorspronkelijk geïntroduceerd door DeviantArt in september 2022, ontstond de NoAI-richtlijn als een grassrootsreactie op zorgen over het scrapen van het werk van kunstenaars en het gebruik daarvan voor het trainen van generatieve AI-modellen zonder toestemming of compensatie. De meta-tag werkt door een eenvoudige HTML-verklaring toe te voegen aan de header van een webpagina, waarmee een duidelijke voorkeur aan AI-systemen wordt gecommuniceerd dat de inhoud niet mag worden gebruikt voor trainingsdoeleinden. Hoewel het in de meeste rechtsgebieden niet wettelijk bindend is, vertegenwoordigt de NoAI-tag een belangrijk opt-outmechanisme voor makers die hun intellectuele eigendom willen beschermen in een tijdperk van steeds agressievere AI-gegevensverzameling.
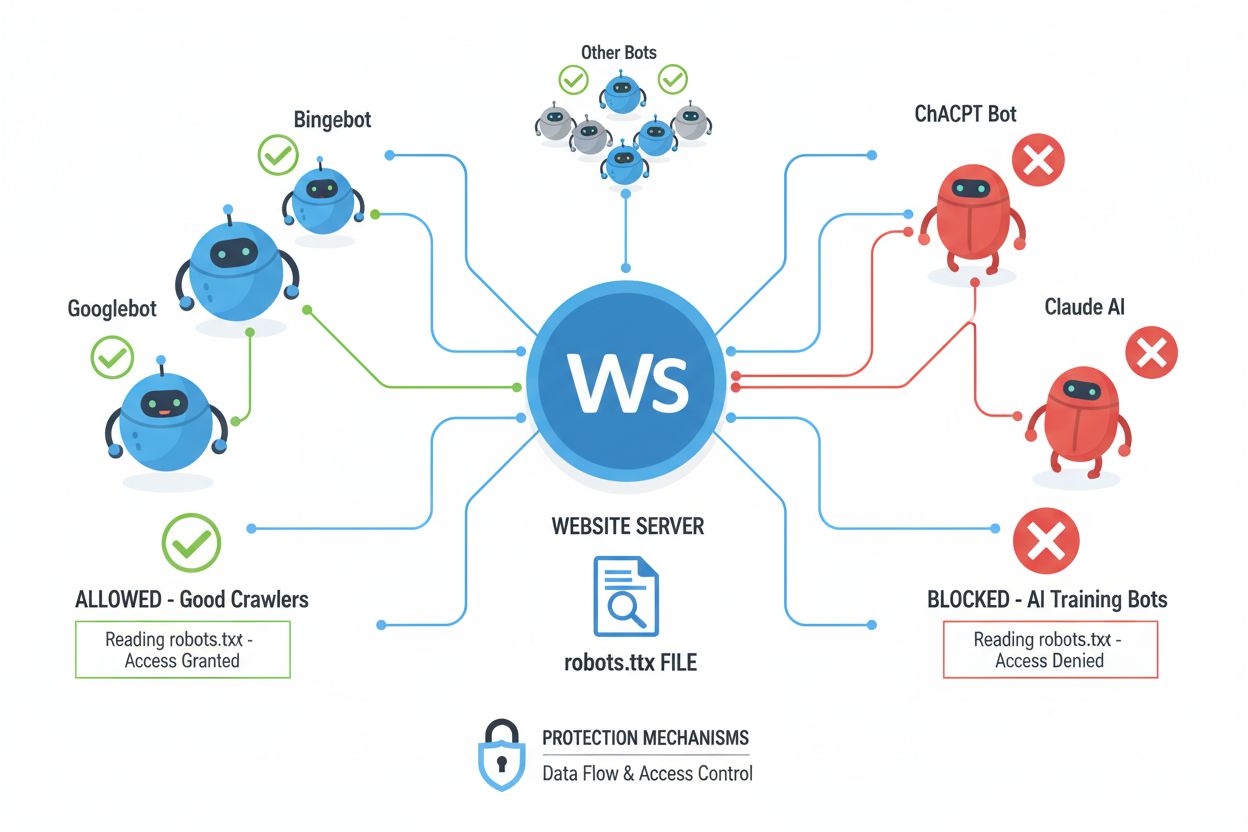
Webcrawlers (ook wel bots, spiders of scrapers genoemd) zijn geautomatiseerde softwareprogramma’s die systematisch het internet doorzoeken, links volgen en inhoud downloaden om deze te indexeren, analyseren of gegevens te verzamelen voor verschillende doeleinden. Deze crawlers werken door het robots.txt-bestand te lezen dat zich in de hoofdmap van een website bevindt, met instructies over welke delen van de site wel of niet toegankelijk mogen zijn voor geautomatiseerde bezoekers. Het robots.txt-bestand gebruikt specifieke richtlijnen zoals User-agent, Disallow en Allow om crawler-permissies te communiceren, hoewel naleving volledig vrijwillig is en afhangt van de keuze van de ontwikkelaar van de crawler om deze richtlijnen te respecteren. Naast robots.txt kunnen websites voorkeuren communiceren via HTTP-headers en meta-tags, die extra signalen bieden over gebruiksrechten en beperkingen van inhoud. Verschillende soorten crawlers gaan op verschillende manieren om met deze signalen:
| Crawler Type | robots.txt-naleving | Respect voor meta-tag | Gebruik voor AI-training |
|---|---|---|---|
| Zoekmachines | Hoog | Hoog | Beperkt |
| AI-trainingsbots | Gemiddeld | Gemiddeld | Ja |
| Commerciële scrapers | Laag | Laag | Variabel |
| Academische bots | Hoog | Gemiddeld | Alleen onderzoek |
| Kwaadwillende bots | Geen | Geen | Onbeperkt |
De noai- en noimageai-richtlijnen dienen verwante maar verschillende doelen bij inhoudsbescherming, waarbij het belangrijkste verschil ligt in hun reikwijdte en specificiteit. De noai-richtlijn is een bredere aanwijzing dat alle inhoud op een pagina—waaronder tekst, afbeeldingen, code en andere media—niet mag worden gebruikt voor AI-trainingsdoeleinden, waardoor het geschikt is voor websites met gemengde inhoud of die op zoek zijn naar uitgebreide bescherming. De noimageai-richtlijn daarentegen richt zich specifiek op alleen beeldinhoud, waardoor tekst en andere niet-beeldmaterialen mogelijk kunnen worden gebruikt voor training terwijl visuele middelen worden beschermd tegen AI-modeltraining. Dit onderscheid is vooral belangrijk voor websites die tekstgebaseerde AI-indexering (voor zoekmachines of toegankelijkheid) willen toestaan, maar hun visuele inhoud willen beschermen tegen gebruik in generatieve beeldmodellen. Hier zijn de implementatieverschillen:
<!-- Uitgebreide bescherming voor alle inhoud -->
<meta name="robots" content="noai">
<!-- Specifieke bescherming alleen voor afbeeldingen -->
<meta name="robots" content="noimageai">
<!-- Gecombineerde aanpak voor maximale duidelijkheid -->
<meta name="robots" content="noai, noimageai">
De NoAI-meta-tag kan op meerdere manieren worden geïmplementeerd, elk met verschillende voordelen afhankelijk van uw technische infrastructuur en specifieke behoeften. De meest eenvoudige aanpak is het rechtstreeks toevoegen van de meta-tag aan uw HTML-<head>-sectie, waarmee u de richtlijn op individuele pagina’s toepast en indien nodig per pagina kunt aanpassen. Voor websites met veel pagina’s of die een sitebrede oplossing zoeken, biedt implementatie via HTTP-responseheaders een meer schaalbare aanpak die uniform op alle inhoud wordt toegepast zonder dat elke pagina afzonderlijk hoeft te worden aangepast. Daarnaast kan het robots.txt-bestand richtlijnen bevatten die zich richten op specifieke AI-crawlers, hoewel deze methode minder gestandaardiseerd is dan meta-tags of headers. Hier zijn de drie primaire implementatiemethoden:
<!-- Methode 1: HTML-meta-tag (meest gebruikelijk) -->
<head>
<meta name="robots" content="noai">
</head>
# Methode 2: robots.txt-richtlijn
User-agent: *
Disallow: /
X-Robots-Tag: noai
# Methode 3: HTTP-header (via .htaccess of serverconfiguratie)
X-Robots-Tag: noai
Voor Apache-servers, voeg toe aan .htaccess:
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
Voor Nginx-servers, voeg toe aan uw server block:
add_header X-Robots-Tag "noai" always;
Hoewel de NoAI-meta-tag een belangrijke stap is richting inhoudsbescherming, werkt deze op basis van een erewoord dat volledig afhankelijk is van de bereidheid van AI-ontwikkelaars en datascrapers om het signaal te respecteren. Grote AI-bedrijven zoals OpenAI, Google en Anthropic zijn begonnen NoAI-richtlijnen in hun crawlers te respecteren, maar kwaadwillenden en ongeautoriseerde scrapers negeren deze signalen vaak, waardoor de tag niet effectief is tegen vastberaden datadieven. De effectiviteit van NoAI is verder beperkt doordat het alleen toekomstige training op inhoud kan voorkomen; het kan geen gegevens verwijderen die al zijn verzameld en gebruikt in bestaande modellen, noch biedt het juridische mogelijkheden bij schending. Nalevingspercentages variëren aanzienlijk tussen verschillende AI-systemen, waarbij sommige de richtlijn respecteren terwijl anderen deze bewust omzeilen, waardoor NoAI een nuttige maar onvolledige oplossing is. De tag biedt ook geen bescherming tegen directe downloads, screenshots of handmatig kopiëren van inhoud en kan niet voorkomen dat concurrenten uw inhoud gebruiken als zij de richtlijn gewoon negeren. Om deze redenen moet NoAI worden beschouwd als één laag binnen een bredere strategie voor inhoudsbescherming, en niet als een volledige oplossing.
De NoAI-meta-tag heeft aanzienlijke adoptie bereikt onder grote AI-bedrijven en platforms, waarbij OpenAI, Google en Stability AI publiekelijk hebben toegezegd de richtlijn te respecteren in hun trainingspijplijnen. De implementatie van NoAI door DeviantArt heeft bredere discussies in de branche beïnvloed over ethische AI-ontwikkeling en toestemming van makers, wat heeft geleid tot meer bewustwording bij zowel AI-ontwikkelaars als contentmakers. Toch blijft de adoptie inconsistent binnen de sector, met kleinere AI-bedrijven, academische onderzoekers en commerciële scrapers die verschillende niveaus van naleving tonen. De opkomst van concurrerende standaarden zoals C2PA (Coalition for Content Provenance and Authenticity) en discussies over machineleesbare rechtenexpressies suggereren dat de industrie zich beweegt richting meer geavanceerde, juridisch ondersteunde beschermingsmechanismen voor inhoud, verder dan vrijwillige meta-tags. Brancheorganisaties en standaardisatie-instanties werken actief aan het formaliseren van deze bescherming, met de verwachting dat toekomstige AI-regelgeving expliciete naleving van de voorkeuren van de contentmaker kan vereisen, waardoor NoAI mogelijk verandert van een vrijwillig signaal in een juridisch afdwingbare vereiste.
Het implementeren van NoAI-bescherming moet deel uitmaken van een gelaagde benadering van inhoudsbeveiliging en niet van een op zichzelf staande oplossing, waarbij technische, juridische en monitoringstrategieën worden gecombineerd voor een volledige bescherming. Om de effectiviteit te maximaliseren, overweeg deze best practices:
Voer daarnaast regelmatig audits uit van uw implementatie van inhoudsbescherming om te zorgen dat alle pagina’s de juiste richtlijnen bevatten, en overweeg geautomatiseerde tools te gebruiken om uw inhoud te scannen in openbare AI-datasets en trainingsrepositories. Documenteer uw NoAI-implementatie als onderdeel van uw content governance-beleid, en communiceer deze bescherming aan uw publiek zodat zij begrijpen welke stappen u neemt om hun werk te beschermen als u een platform bent dat door gebruikers gegenereerde content host.
De noai-richtlijn beschermt alle soorten inhoud (tekst, afbeeldingen, code) tegen AI-training, terwijl noimageai specifiek alleen beeldinhoud beschermt. Gebruik noai voor uitgebreide bescherming en noimageai wanneer u tekstindexering wilt toestaan, maar visuele middelen wilt beschermen tegen generatieve beeldmodellen.
Nee, de NoAI-meta-tag werkt op basis van het erewoord en hangt af van of AI-ontwikkelaars ervoor kiezen om deze te respecteren. Grote bedrijven zoals OpenAI en Google respecteren het, maar kwaadwillenden en ongeautoriseerde scrapers negeren deze signalen vaak, waardoor het slechts één laag van bescherming is en geen volledige oplossing.
U kunt het op drie manieren implementeren: voeg de HTML-meta-tag toe aan de header van uw pagina, stel HTTP-responseheaders in op uw server of neem richtlijnen op in uw robots.txt-bestand. De HTML-meta-tag-methode is het meest gebruikelijk en eenvoudig voor de meeste website-eigenaren.
Grote AI-bedrijven waaronder OpenAI (ChatGPT), Google, Anthropic (Claude) en Stability AI hebben publiekelijk toegezegd de NoAI-richtlijnen in hun trainingspijplijnen te respecteren. De naleving varieert echter bij kleinere AI-bedrijven, academische onderzoekers en commerciële scrapers.
Ja, u kunt beide tegelijk gebruiken voor maximale effectiviteit. De NoAI-meta-tag en robots.txt-richtlijnen werken samen om uw voorkeuren voor inhoudsbescherming aan verschillende soorten crawlers en systemen te communiceren.
Combineer NoAI met andere beschermingsmethoden zoals HTTP-headers, robots.txt-regels, watermerken, toegangscontroles en juridische gebruiksvoorwaarden. Monitor uw inhoud in AI-datasets en overweeg tools te gebruiken om ongeoorloofd gebruik te volgen.
Hoewel het breed wordt toegepast door grote AI-bedrijven, is NoAI nog geen formele W3C-standaard. Brancheorganisaties werken echter aan meer geavanceerde standaarden zoals C2PA en machineleesbare rechtenexpressies die uiteindelijk juridische ondersteuning kunnen bieden.
NoAI is het meest effectief in combinatie met andere methoden zoals robots.txt, HTTP-headers, watermerken, toegangscontroles en juridische bescherming. Geen enkele methode biedt volledige bescherming, dus een gelaagde aanpak wordt aanbevolen voor uitgebreide inhoudsbeveiliging.
Volg welke AI-systemen uw merk en inhoud vermelden met AmICited's AI-monitoringsplatform. Weet precies hoe uw werk wordt gebruikt door ChatGPT, Perplexity, Google AI Overviews en andere AI-systemen.
Leer meer over de noai meta tag, hoe deze werkt om AI-trainingsdataverzameling te voorkomen, de beperkingen ervan, en hoe je deze op je website implementeert om...
Discussie in de community over de noai meta tag en of deze daadwerkelijk content beschermt tegen AI-training. Gebruikers delen ervaringen en beperkingen van dez...
Ontdek hoe meta-tags zijn geëvolueerd voor AI-gedreven zoekopdrachten. Leer welke meta-tags het belangrijkst zijn voor AI-optimalisatie, zichtbaarheid in AI Ove...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.