
Hvordan implementere LLMs.txt: En trinnvis teknisk guide
Lær hvordan du implementerer LLMs.txt på nettstedet ditt for å hjelpe AI-systemer med å forstå innholdet ditt bedre. Komplett trinnvis guide for alle plattforme...
9 min lesing

Kritisk analyse av LLMs.txt sin effektivitet. Finn ut om denne AI-innholdsstandarden er nødvendig for ditt nettsted eller bare opphauset. Ekte data om bruk, plattformstøtte og hva som faktisk fungerer for AI-synlighet.
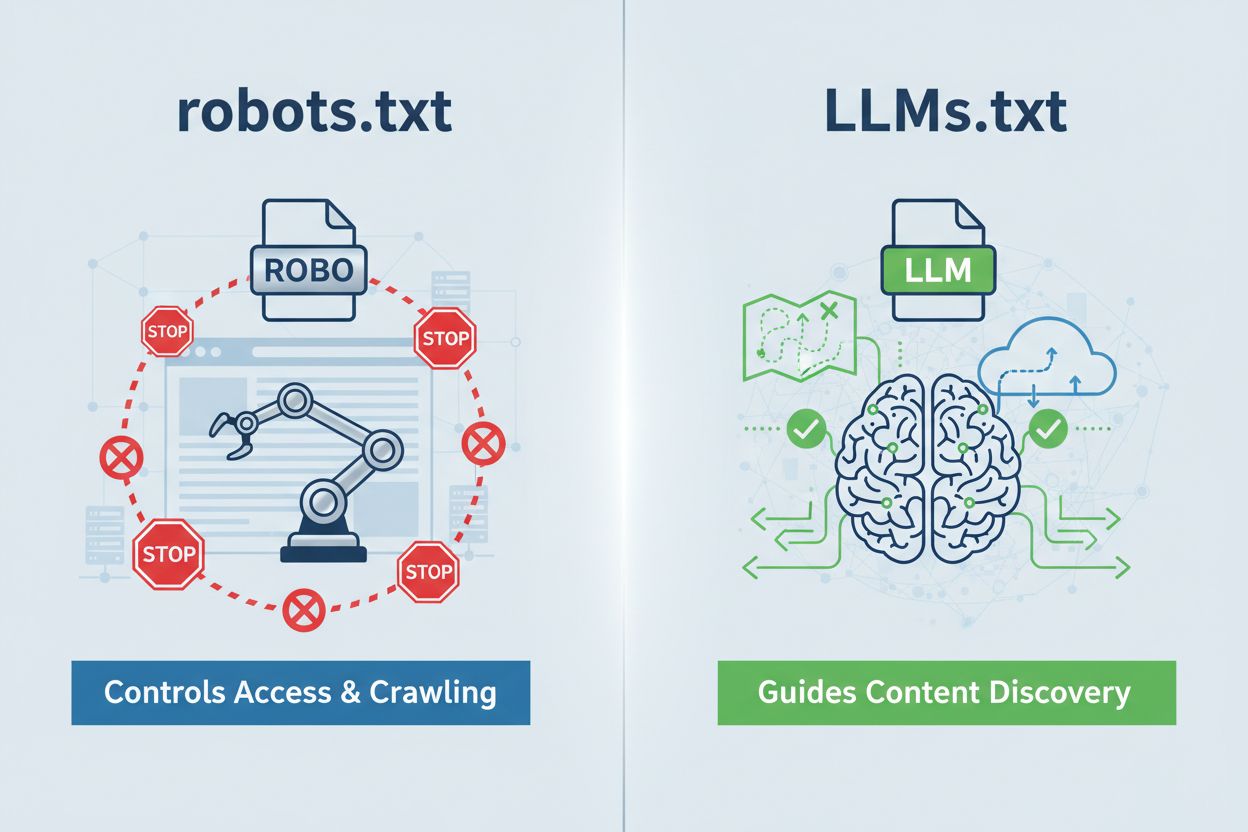
LLMs.txt er en enkel tekstfil plassert på domain.com/llms.txt som fungerer som en kuratert veileder for AI-systemer til å oppdage ditt innhold av høyest kvalitet. Den er grunnleggende forskjellig fra robots.txt—mens robots.txt styrer om AI-crawlere kan få tilgang til nettstedet ditt, opererer LLMs.txt på tidspunktet for inferens, og hjelper AI-systemer å forstå hvilke sider som bør prioriteres når de genererer svar. Tenk på det mindre som en trafikkontrollør og mer som et skattekart: den hindrer ikke utforskning, den fremhever bare hvor den virkelige verdien ligger. Formatet er forfriskende enkelt—ren markdown uten kompleks syntaks—slik at det er tilgjengelig for enhver organisasjon uavhengig av teknisk kompetanse. Denne forskjellen er viktig fordi den endrer hele samtalen: LLMs.txt handler ikke om å kontrollere crawling; det handler om å optimalisere hvordan AI-systemer tolker og prioriterer ditt AI-lesbare innhold etter at de allerede har funnet deg.
Tallene viser reell fremgang: over 844 000 nettsteder har implementert LLMs.txt per oktober 2025, med adopsjon konsentrert blant selskaper som forstår AI sin rolle i fremtiden. Store aktører som Anthropic, Cloudflare, Stripe, Vercel og Supabase har alle implementert standarden, noe som signaliserer at seriøse infrastrukturselskaper ser verdi i eksperimentet. Mintlifys beslutning om å aktivere automatisk generering for tusenvis av dokumentasjonssider i november 2024 skapte en tydelig adopsjonstopp og viser at verktøystøtte kan akselerere implementering. Tre fellesskapskataloger sporer nå implementeringer, med over 788 bekreftede nettsteder dokumentert. Likevel avslører adopsjonsmønsteret noe viktig: implementeringen er sterkt konsentrert rundt utviklerverktøy og dokumentasjonsplattformer—nettopp de sektorene som har mest å vinne på AI-synlighet. Slik ser adopsjonslandskapet faktisk ut:
| Selskap/Plattform | Implementering | Antall token | Status |
|---|---|---|---|
| Anthropic | Ja | ~2 000 | Aktiv |
| Cloudflare | Ja | ~5 000 | Aktiv |
| Stripe | Ja | ~8 000 | Aktiv |
| Vercel | Ja | ~3 500 | Aktiv |
| Supabase | Ja | ~4 200 | Aktiv |
| Mintlify (autogenerert) | Ja | Varierer | Aktiv |
Her blir skepsisen berettiget: INGEN store AI-plattformer har offisielt bekreftet bruk av LLMs.txt i sine gjenfinningssystemer. Googles John Mueller uttalte rett ut, “Ingen AI-system bruker per nå llms.txt,” en kommentar som burde avsluttet samtalen, men likevel gjorde den ikke det. OpenAI, Anthropic, Google, Microsoft og Perplexity har alle vært strategisk tause—ingen offisiell dokumentasjon, ingen bekreftelse på bruk, ingen offentlige veikart. Det finnes bevis på at noen plattformer crawler filene (Microsoft- og OpenAI-boter har blitt observert hente LLMs.txt-filer), men crawling og faktisk bruk er to helt forskjellige ting. Den optimistiske tolkningen tilsier at plattformer tester i det stille før de gjør noe offentlig; den skeptiske tolkningen tilsier at de aldri vil ta det i bruk fordi det ikke løser et virkelig problem for dem. Denne stillheten er kjernen i det “overvurderte” argumentet: 18 måneder etter at forslaget fikk fotfeste, har vi bred implementering, men null offisiell plattformadopsjon. Det er ikke en standard—det er et håp.
Den skeptiske posisjonen bygger på et enkelt grunnlag: det finnes ingen bevis for at LLMs.txt forbedrer AI-gjenfinning, øker trafikk eller gir bedre innholdssynlighet. Tillitsproblemet går dypere—ved å lage en egen fil som kan inneholde annet innhold enn det som vises i HTML-en din, åpner du for manipulasjon. Forskning på LLM-adferd viser at de er 2,5 ganger mer tilbøyelige til å anbefale innhold som er spesielt fremhevet, noe som gir åpenbare muligheter for spill og manipulasjon. En organisasjon kan teoretisk fylle LLMs.txt med innhold som allerede presterer best, mens de skjuler svakere sider, eller enda verre: inkludere innhold i LLMs.txt som ikke eksisterer på nettstedet i det hele tatt. SEO-verktøyleverandører har forsterket presset ved å markere manglende LLMs.txt-filer som optimaliseringsmuligheter—Rank Math, SEMrush og andre har skapt en selvoppfyllende sirkel hvor nettsteder implementerer standarden ikke fordi den virker, men fordi verktøyene sier de mangler noe. Dette er det reelle problemet: 18 måneder med implementeringspress uten en eneste dokumentert suksesshistorie med målbar verdi. Det er den digitale ekvivalenten til at alle kjøper lodd fordi lotteriselskapet stadig reklamerer.
LLMs.txt-tilhengerne argumenterer annerledes, med utgangspunkt i uunngåelig endring snarere enn dagens bevis. Carolyn Shelby fra Yoast formulerte det perfekt: “Rangering er ikke lenger premien—inkludering er det.” Windsurf, en AI-kodeeditor, rapporterte at LLMs.txt sparer tid og tokens ved parsing av dokumentasjon, noe som gir reell effektivitet for AI-systemer som faktisk bruker det. Anthropic ba spesifikt Mintlify om å implementere LLMs.txt for sin dokumentasjon, noe som antyder intern verdi selv om de ikke vil bekrefte det offentlig. Google inkluderte LLMs.txt i sitt A2A (Agents to Agents)-protokoll, noe som tyder på at selskapet ser på det som en del av fremtidens infrastruktur for AI-til-AI-kommunikasjon. Implementering tar 1-4 timer uten noen påvist ulempe—du ødelegger ingenting, du skader ikke SEO, du lager bare en fil. Jeremy Howard oppsummerte tilhengernes logikk: “99,9 % av oppmerksomheten vil snart være LLM-oppmerksomhet, ikke menneskelig oppmerksomhet,” som betyr at optimalisering for AI-systemer ikke er valgfritt, men uunngåelig. Springs Apps rapporterte en 20 % økning i søkesynlighet etter implementering, selv om dette ikke er verifisert og kan være tilfeldig.
For å forstå hvorfor LLMs.txt kanskje mislykkes, må vi se på hvorfor andre standarder lyktes. Robots.txt fungerte fordi det ga gjensidig nytte med minimal kostnad og fikk offisiell RFC-støtte (RFC 9309)—søkemotorer ville crawle effektivt, nettsteder ville kontrollere crawling, og løsningen var så enkel at adopsjonen gikk friksjonsfritt. Schema.org lyktes gjennom utvikling på tvers av flere aktører: Google, Microsoft, Yahoo og Yandex fra starten av—ingen enkeltaktør kunne ta eierskap, noe som bygde tillit. Sitemap.xml oppnådde bred plattformstøtte før utbredt bruk, ikke etterpå. LLMs.txt mangler alle disse suksessfaktorene: ingen W3C-involvering, ingen konsortiumstøtte, ingen offisiell plattformstøtte og ingen dokumentert verdi i trafikk, rangering eller nøyaktighet. Det som faktisk får standarder til å slå gjennom, er bred støtte fra flere interessenter, klare og målbare fordeler og lav mulighet for utnyttelse. LLMs.txt har håp. Det har adopsjon blant tidlige troende. Det har verktøystøtte. Men det mangler de grunnleggende elementene som gjorde tidligere standarder til infrastruktur.
Hvis LLMs.txt fortsatt er uprøvd, hva faktisk gir AI-synlighet og AI-sitater? Svaret er mindre eksotisk enn et nytt filformat:
Disse taktikkene fungerer fordi de samsvarer med hvordan AI faktisk prosesserer informasjon, ikke fordi de er optimalisert for et bestemt filformat.

Samtalen om LLMs.txt gjenspeiler et dypere skifte i hvordan innhold lykkes på nett: sammenløpet mellom menneskelig brukeropplevelse og AI-optimalisering. Forskning på Generative Engine Optimization (GEO) viser at innhold som vinner i AI-genererte svar har bestemte kjennetegn—klarhet, struktur, autoritet og presisjon. Vercel rapporterte at 10 % av deres registreringer nå kommer direkte fra ChatGPT-omtaler i stedet for tradisjonelt organisk søk, en måling som ville vært utenkelig for fem år siden. Suksess betyr i økende grad å bli nevnt i AI-genererte svar, ikke bare rangere i organiske resultater—dette er ulike optimaliseringsmål med ulike krav. Verktøyslandskapet har utviklet seg for å følge dette skiftet: SEMrush AIO, Profounds GEO-tracking og Ahrefs Brand Radar overvåker nå AI-synlighet side om side med tradisjonell rangering. Det grunnleggende perspektivskiftet er: å bli sitert er viktigere enn å bli rangert, og å bli referert er viktigere enn å bli indeksert. Dette forklarer hvorfor LLMs.txt har fått fotfeste tross manglende offisiell støtte—det er et forsøk på å optimalisere for en ny oppmerksomhetsøkonomi der AI-systemer er hoveddistribusjonskanal.
Hvis du bestemmer deg for å implementere, gjør det riktig. Filen må ligge på domain.com/llms.txt (merk: flertall, ikke entall), formatert som ren markdown og ikke som XML eller JSON. Start med en H1-overskrift med nettstedets navn, eventuelt etterfulgt av et sitat som oppsummerer formålet med nettstedet ditt. Organiser innholdet i H2-seksjoner hvis nettstedet har ulike områder (Dokumentasjon, Blogg, API-referanse osv.), med beskrivelser av hva hver seksjon inneholder. Bruk formatet [Tittel](URL): Beskrivelse for enkeltsider, og hold beskrivelsene korte, men informative. Hva du bør ta med: tidløst innhold, godt strukturerte sider og innhold som viser reell ekspertise. Hva du bør unngå: forsiden (ofte ikke verdifull alene), alle URL-er (kvalitet fremfor kvantitet), og sider som ikke gir mening uten kontekst. Her er et grunnleggende eksempel:
# Firmanavn
> Kort beskrivelse av hva selskapet ditt gjør og hvorfor AI-systemer bør bry seg om innholdet ditt
## Dokumentasjon
[Kom i gang](https://example.com/docs/getting-started): Trinnvis guide for nye brukere
[API-referanse](https://example.com/docs/api): Komplett API-dokumentasjon med eksempler
[Beste praksis](https://example.com/docs/best-practices): Dokumenterte mønstre for bruk av plattformen vår
## Blogg
[Derfor bygde vi dette](https://example.com/blog/why-we-built-this): Problemet vi løste og hvordan
Du kan eventuelt ta med en seksjon for URL-er som skal utelates hvis konteksten er for kort, men de fleste implementasjoner trenger ikke denne graden av detaljering.
Ja, du bør implementere LLMs.txt. Ikke fordi det er bevist at det fungerer, men fordi det ikke har noen ulemper og det potensielle oppsiden er reell. Hvis AI-plattformer aldri offisielt tar det i bruk, blir filen bare liggende på serveren uten skade—ingen SEO-straff, ingen tap av trafikk, ingen funksjonsfeil. Implementeringen tar omtrent 10 minutter for et lite nettsted, og kanskje en time for større. I mellomtiden fragmenteres trafikken over flere AI-systemer: ChatGPT, Perplexity, Claude og nye konkurrenter håndterer til sammen hundrevis av millioner søk hver måned. Du er allerede synlig for AI-systemer—LLMs.txt hjelper dem bare å finne ditt beste innhold i stedet for tilfeldige sider. Selv om LLMs.txt aldri blir en offisiell standard, trener du AI-systemer til å forstå nettstedets struktur og prioriteringer bedre, noe som har verdi uansett. Innsikten er: sikre deg gratis. Implementer standarden, optimaliser innholdet ditt for AI-synlighet med dokumenterte metoder, og følg med på hva som faktisk gir trafikk fra AI-systemer. Om 12 måneder har du reelle data på om LLMs.txt betyr noe for din virksomhet—og det er uendelig mer verdifullt enn spekulasjoner.
LLMs.txt er en enkel tekstfil som veileder AI-systemer til ditt beste innhold for tilgang i sanntid, mens robots.txt styrer crawler-tilgang og indeksering. LLMs.txt begrenser ingenting—det kuraterer og fremhever dine mest verdifulle sider for AI-forståelse. Tenk på robots.txt som en trafikkontrollør og LLMs.txt som et skattekart.
Ikke offisielt. Til tross for at over 844 000 nettsteder har implementert det, har ingen store AI-plattformer bekreftet at de bruker LLMs.txt for å generere svar. Noe bevis viser crawling-aktivitet fra OpenAI- og Microsoft-boter, men ingen bekreftet bruk for inferens eller siteringsformål. Dette er kjernen i det 'overvurderte' argumentet.
Ja. Implementering tar 10-30 minutter uten noen ulemper. Hvis plattformer tar det i bruk, er du allerede posisjonert. Hvis ikke, gjør filen ingen skade. Det er en lavrisiko, potensiell gevinst for AI-synlighet. Du satser i bunn og grunn på fremtiden for AI-formidlet innholdsoppdagelse.
Ta med tidløst, godt strukturert innhold som svarer på konkrete spørsmål: guider, FAQ-er, API-dokumentasjon, hovedinnhold og autoritative artikler. Unngå forsiden, alle URL-er på nettstedet ditt og sider som ikke gir mening ute av kontekst. Kvalitet fremfor kvantitet er hovedprinsippet.
Ja, dette er en legitim bekymring. Du kan legge inn annet innhold i LLMs.txt enn det som faktisk vises på sidene dine, noe som bryter tilliten. Derfor er noen eksperter skeptiske til standardens langsiktige levedyktighet, og plattformer er forsiktige med å ta den i bruk.
llms.txt inneholder utvalgte lenker til dine beste sider med beskrivelser. llms-full.txt er en omfattende versjon med all dokumentasjonen din i én stor fil (noen ganger over 400 000 ord). Bruk llms-full.txt hvis du vil gi AI-systemer alt med én gang, uten at de må følge lenker.
LLMs.txt er et verktøy innenfor den bredere GEO-strategien. GEO handler om å gjøre innholdet ditt oppdagbart og siterbart for AI-systemer gjennom klar struktur, sitater, data og autoritativ ekspertise. LLMs.txt hjelper AI-systemer å finne ditt beste GEO-optimaliserte innhold.
Ja. Alle nettsteder har fordel av å hjelpe AI-systemer å forstå og sitere innholdet ditt. Blogger, lokale bedrifter, nettbutikker og nisjefellesskap får alle trafikk fra AI-drevne søk. LLMs.txt er en enkel måte å forbedre synligheten din på tvers av ChatGPT, Claude, Perplexity og andre AI-plattformer.
Følg med på hvordan AI-systemer som ChatGPT, Claude og Perplexity refererer til innholdet ditt. Få sanntidsinnsikt i dine AI-sitater og synlighet på tvers av AI-plattformer.
Lær hvordan du implementerer LLMs.txt på nettstedet ditt for å hjelpe AI-systemer med å forstå innholdet ditt bedre. Komplett trinnvis guide for alle plattforme...

Lær hva LLMs.txt er, om det faktisk fungerer, og om du bør implementere det på nettstedet ditt. Ærlig analyse av denne nye AI SEO-standarden.

Lær hva LLMs.txt-filer er, hvordan de skiller seg fra robots.txt, og hvorfor de er essensielle for AI-synlighet og siteringer i ChatGPT, Perplexity og Google AI...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.