NoAI Meta Tags: Kontrollere AI-tilgang via headere
Lær hvordan du implementerer noai og noimageai meta-tagger for å kontrollere AI-crawleres tilgang til innholdet på nettstedet ditt. Komplett guide til AI-tilgangskontroll-headere og implementeringsmetoder.
Publisert den Jan 3, 2026.Sist endret den Jan 3, 2026 kl. 3:24 am
Nettcrawlere er automatiserte programmer som systematisk gjennomgår internett og samler informasjon fra nettsteder. Historisk sett ble disse botene hovedsakelig drevet av søkemotorer som Google, hvor Googlebot gjennomsøkte sider, indekserte innhold og sendte brukere tilbake til nettsteder via søkeresultater—noe som skapte et gjensidig fordelaktig forhold. Fremveksten av AI-crawlere har imidlertid fundamentalt endret dette forholdet. I motsetning til tradisjonelle søkemotorboter som gir henvisningstrafikk i bytte mot tilgang til innhold, konsumerer AI-treningscrawlere store mengder nettinnhold for å bygge datasett til store språkmodeller, og gir ofte minimal eller ingen trafikk tilbake til utgivere. Dette skiftet har gjort meta-tagger—små HTML-instruksjoner som kommuniserer beskjeder til crawlere—stadig viktigere for innholdsskapere som ønsker å beholde kontrollen over hvordan arbeidet deres brukes av kunstig intelligens.
Hva er NoAI og NoImageAI meta-tagger?
noai og noimageai meta-tagger er instruksjoner laget av DeviantArt i 2022 for å hjelpe innholdsskapere å forhindre at arbeidet deres brukes til å trene AI-bildegeneratorer. Disse taggene fungerer på samme måte som den velkjente noindex-instruksen som forteller søkemotorer å ikke indeksere en side. noai-instruksen signaliserer at intet innhold på siden skal brukes til AI-trening, mens noimageai spesifikt forhindrer bilder fra å brukes til AI-modelltrening. Du kan implementere disse taggene i HTML-head-seksjonen din med følgende syntaks:
<!-- Blokker alt innhold fra AI-trening --><metaname="robots"content="noai">
<!-- Blokker kun bilder fra AI-trening --><metaname="robots"content="noimageai">
<!-- Blokker både innhold og bilder --><metaname="robots"content="noai, noimageai">
Her er en sammenligningstabell av ulike meta-tag-instruksjoner og deres formål:
Instruksjon
Formål
Syntaks
Omfang
noai
Forhindrer alt innhold fra AI-trening
content="noai"
Hele sideinnholdet
noimageai
Forhindrer bilder fra AI-trening
content="noimageai"
Kun bilder
noindex
Forhindrer indeksering i søkemotorer
content="noindex"
Søkeresultater
nofollow
Forhindrer at lenker følges
content="nofollow"
Utgående lenker
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
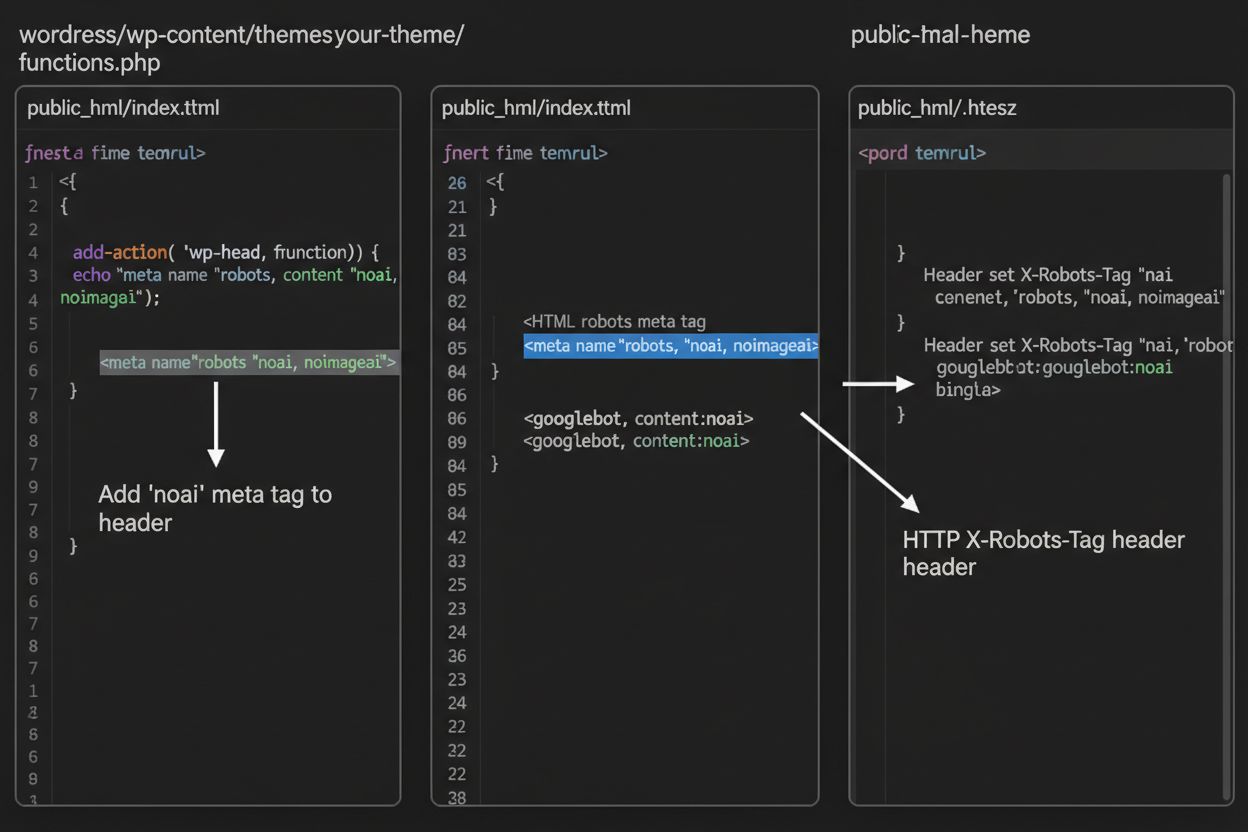
Mens meta-tagger plasseres direkte i HTML-en din, gir HTTP-headere en alternativ metode for å kommunisere crawler-instruksjoner på servernivå. X-Robots-Tag-headeren kan inkludere de samme instruksjonene som meta-tagger, men fungerer annerledes—den sendes i HTTP-responsen før sideinnholdet leveres. Denne tilnærmingen er spesielt verdifull for å kontrollere tilgang til ikke-HTML-filer som PDF-er, bilder og videoer, hvor du ikke kan bygge inn meta-tagger i HTML.
For Apache-servere kan du sette X-Robots-Tag-headere i .htaccess-filen din:
<IfModulemod_headers.c> Header set X-Robots-Tag "noai, noimageai"</IfModule>
For NGINX-servere, legg til headeren i serverkonfigurasjonen:
Headere gir global beskyttelse over hele nettstedet ditt eller spesifikke kataloger, og gjør dem ideelle for omfattende AI-tilgangskontrollstrategier.
Hvordan AI-crawlere respekterer (eller ignorerer) disse instruksene
Effektiviteten av noai og noimageai-tagger avhenger helt av om crawlere velger å respektere dem. Veloppdragne crawlere fra store AI-selskaper følger vanligvis disse instruksene:
Mindre/ukjente crawlere - Kan ignorere instruksene
Imidlertid kan dårlig oppførte bot-er og ondsinnede crawlere bevisst ignorere disse instruksene fordi det ikke finnes noen håndhevingsmekanisme. I motsetning til robots.txt, som søkemotorer har blitt enige om å respektere som en bransjestandard, er noai ikke en offisiell nettstandard, noe som betyr at crawlere ikke har noen forpliktelse til å overholde. Dette er grunnen til at sikkerhetseksperter anbefaler en lagvis tilnærming som kombinerer flere beskyttelsesmetoder i stedet for å stole utelukkende på meta-tagger.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Implementeringsmetoder på ulike plattformer
Implementering av noai og noimageai-tagger varierer avhengig av hvilken plattform nettstedet ditt bruker. Her er trinnvise instruksjoner for de vanligste plattformene:
1. WordPress (via functions.php)
Legg til denne koden i functions.php-filen til ditt child theme:
3. Squarespace
Gå til Innstillinger > Avansert > Kodeinjeksjon, og legg til i Header-seksjonen:
<metaname="robots"content="noai, noimageai">
4. Wix
Gå til Innstillinger > Egendefinert kode, klikk “Legg til egendefinert kode”, lim inn meta-taggen, velg “Head”, og bruk på alle sider.
Hver plattform gir ulike nivåer av kontroll—WordPress tillater sidespesifikk implementering gjennom plugins, mens Squarespace og Wix gir globale alternativer for hele nettstedet. Velg metoden som passer ditt tekniske nivå og dine spesifikke behov best.
Begrensninger og effektivitet for NoAI-tagger
Selv om noai og noimageai-tagger representerer et viktig steg mot beskyttelse for innholdsskapere, har de betydelige begrensninger. For det første, dette er ikke offisielle nettstandarder—DeviantArt laget dem som et samfunnsinitiativ, noe som betyr at det ikke finnes noen formell spesifikasjon eller håndhevingsmekanisme. For det andre, etterlevelse er helt frivillig. Veloppdragne crawlere fra store selskaper respekterer disse instruksene, men dårlig oppførte bot-er og scrapere kan ignorere dem uten konsekvenser. For det tredje, mangelen på standardisering gjør at adopsjonen varierer. Noen mindre AI-selskaper og forskningsorganisasjoner kjenner kanskje ikke engang til disse instruksene, langt mindre implementerer støtte for dem. Til slutt, meta-tagger alene kan ikke hindre bestemte ondsinnede aktører fra å skrape innholdet ditt. En ondsinnet crawler kan ignorere instruksjonene dine fullstendig, noe som gjør ekstra beskyttelseslag essensielle for helhetlig innholdssikkerhet.
Kombinere meta-tagger med robots.txt og andre metoder
Den mest effektive AI-tilgangskontrollstrategien bruker flere beskyttelseslag i stedet for å stole på én metode alene. Her er en sammenligning av ulike beskyttelsesmetoder:
Metode
Omfang
Effektivitet
Vanskelighetsgrad
Meta-tagger (noai)
Sidenivå
Middels (frivillig etterlevelse)
Enkel
robots.txt
Hele nettstedet
Middels (rådgivende)
Enkel
X-Robots-Tag-headere
Servernivå
Middels-høy (dekker alle filtyper)
Middels
Brannmurregler
Nettverksnivå
Høy (blokkerer på infrastruktur)
Vanskelig
IP-whitelisting
Nettverksnivå
Svært høy (kun verifiserte kilder)
Vanskelig
En helhetlig strategi kan inkludere: (1) implementere noai meta-tagger på alle sider, (2) legge til robots.txt-regler som blokkerer kjente AI-treningscrawlere, (3) sette X-Robots-Tag-headere på servernivå for ikke-HTML-filer, og (4) overvåke serverlogger for å identifisere crawlere som ignorerer instruksene dine. Denne lagvise tilnærmingen øker vanskelighetsgraden for ondsinnede aktører betydelig, samtidig som den opprettholder kompatibilitet med veloppdragne crawlere som respekterer dine preferanser.
Overvåking og verifisering av crawler-etterlevelse
Etter å ha implementert noai-tagger og andre instruksjoner, bør du verifisere at crawlere faktisk respekterer reglene dine. Den mest direkte metoden er å sjekke serverens tilgangslogger for crawleraktivitet. På Apache-servere kan du søke etter spesifikke crawlere:
Hvis du ser forespørsler fra crawlere du har blokkert, ignorerer de instruksene dine. For NGINX-servere, sjekk /var/log/nginx/access.log ved å bruke samme grep-kommando. I tillegg gir verktøy som Cloudflare Radar innsikt i AI-crawler-trafikkmønstre på nettstedet ditt, og viser hvilke bot-er som er mest aktive og hvordan atferden deres endrer seg over tid. Regelmessig loggovervåking—minst månedlig—hjelper deg å identifisere nye crawlere og verifisere at beskyttelsestiltakene dine fungerer som de skal.
Fremtiden for AI-tilgangskontrollstandarder
For øyeblikket eksisterer noai og noimageai i en gråsone: de er bredt anerkjent og respektert av store AI-selskaper, men forblir uoffisielle og ikke-standardiserte. Det er imidlertid økende drivkraft for formell standardisering. W3C (World Wide Web Consortium) og ulike bransjegrupper diskuterer hvordan man kan lage offisielle standarder for AI-tilgangskontroll som vil gi disse instruksene samme tyngde som etablerte standarder som robots.txt. Hvis noai blir en offisiell nettstandard, vil etterlevelse bli forventet bransjepraksis i stedet for frivillig, noe som vil øke effektiviteten betydelig. Dette standardiseringsarbeidet reflekterer et bredere skifte i hvordan teknologibransjen ser på innholdsskaperrettigheter og balansen mellom AI-utvikling og utgiverbeskyttelse. Etter hvert som flere utgivere tar i bruk disse taggene og krever sterkere beskyttelse, øker sannsynligheten for offisiell standardisering, og AI-tilgangskontroll kan bli like grunnleggende for nettstyring som regler for søkemotorindeksering.
Vanlige spørsmål
Hva er noai meta-taggen og hvordan fungerer den?
Noai meta-taggen er en instruks plassert i HTML-head-seksjonen på nettstedet ditt som signaliserer til AI-crawlere at innholdet ditt ikke skal brukes til trening av kunstige intelligensmodeller. Den fungerer ved å kommunisere dine preferanser til veloppdragne AI-boter, selv om det ikke er en offisiell nettstandard og noen crawlere kan ignorere det.
Er noai en offisiell nettstandard?
Nei, noai og noimageai er ikke offisielle nettstandarder. De ble laget av DeviantArt som et samfunnsinitiativ for å hjelpe innholdsskapere med å beskytte arbeidet sitt mot AI-trening. Imidlertid har store AI-selskaper som OpenAI, Anthropic og andre begynt å respektere disse instruksjonene i sine crawlere.
Hvilke AI-crawlere respekterer noai meta-taggen?
Store AI-crawlere inkludert GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) og andre respekterer noai-instruksen. Noen mindre eller dårlig oppførte crawlere kan imidlertid ignorere den, og derfor anbefales det en lagvis beskyttelsestilnærming.
Hva er forskjellen mellom meta-tagger og HTTP-headere for AI-kontroll?
Meta-tagger plasseres i HTML-head-seksjonen din og gjelder for individuelle sider, mens HTTP-headere (X-Robots-Tag) settes på servernivå og kan gjelde globalt eller for spesifikke filtyper. Headere fungerer for ikke-HTML-filer som PDF-er og bilder, noe som gjør dem mer allsidige for omfattende beskyttelse.
Kan jeg implementere noai-tagger på WordPress?
Ja, du kan implementere noai-tagger på WordPress gjennom flere metoder: legge til kode i temaets functions.php-fil, bruke en plugin som WPCode, eller gjennom sidebyggerverktøy som Divi og Elementor. Metoden med functions.php er mest vanlig og innebærer å legge til en enkel hook for å injisere meta-taggen i sidens header.
Bør jeg blokkere alle AI-crawlere eller bare treningscrawlere?
Dette avhenger av dine forretningsmål. Å blokkere treningscrawlere beskytter innholdet ditt mot å bli brukt i utvikling av AI-modeller. Å blokkere søkecrawlere som OAI-SearchBot kan derimot redusere synligheten din i AI-drevne søkeresultater og oppdagelsesplattformer. Mange utgivere bruker en selektiv tilnærming som blokkerer treningscrawlere, men tillater søkecrawlere.
Hvordan kan jeg verifisere at AI-crawlere respekterer mine noai-instrukser?
Du kan sjekke serverloggene dine for crawleraktivitet ved å bruke kommandoer som grep for å søke etter spesifikke bot-user agents. Verktøy som Cloudflare Radar gir innsikt i AI-crawler-trafikkmønstre. Overvåk loggene dine jevnlig for å se om blokkerte crawlere fortsatt får tilgang til innholdet ditt, noe som vil indikere at de ignorerer instruksene dine.
Hva bør jeg gjøre hvis crawlere ignorerer mine noai meta-tagger?
Hvis crawlere ignorerer meta-taggene dine, implementer flere beskyttelseslag, inkludert robots.txt-regler, X-Robots-Tag HTTP-headere og servernivå-blokkering via .htaccess eller brannmurregler. For sterkere verifisering, bruk IP-whitelisting for kun å tillate forespørsler fra verifiserte crawler-IP-adresser publisert av store AI-selskaper.
Overvåk hvordan AI refererer til merkevaren din
Bruk AmICited for å spore hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews siterer og refererer til innholdet ditt på tvers av ulike AI-plattformer.
Hva er noai meta taggen og hvordan beskytter den innholdet ditt mot AI?
Lær om noai meta taggen, hvordan den fungerer for å hindre innsamling av AI-treningsdata, dens begrensninger, og hvordan du kan implementere den på nettstedet d...
Lær hva NoAI meta-tagger er, hvordan de fungerer for å hindre AI-scraping, implementeringsmetoder og hvor effektive de er for å beskytte innholdet ditt mot uaut...
Bør du blokkere eller tillate AI-crawlere? Beslutningsrammeverk
Lær hvordan du tar strategiske beslutninger om blokkering av AI-crawlere. Vurder innholdstype, trafikkilder, inntektsmodeller og konkurranseposisjon med vårt om...
11 min lesing
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.