
Promptbiblioteker for Manuell AI-synlighetstesting
Lær hvordan du bygger og bruker promptbiblioteker for manuell AI-synlighetstesting. DIY-guide til å teste hvordan AI-systemer refererer til merkevaren din på tv...
10 min lesing

Lær hvordan du kan teste merkevarens synlighet i AI-motorer med prompttesting. Oppdag manuelle og automatiserte metoder for å overvåke AI-synlighet på tvers av ChatGPT, Perplexity og Google AI.
Prompttesting er prosessen med systematisk å sende inn forespørsler til AI-motorer for å måle om innholdet ditt dukker opp i deres svar. I motsetning til tradisjonell SEO-testing, som fokuserer på søkerangeringer og klikkrater, vurderer AI-synlighetstesting din tilstedeværelse på tvers av generative AI-plattformer som ChatGPT, Perplexity og Google AI Overviews. Denne forskjellen er avgjørende fordi AI-motorer bruker andre rangeringsmekanismer, hentesystemer og siteringsmønstre enn tradisjonelle søkemotorer. Å teste din tilstedeværelse i AI-svar krever en fundamentalt annerledes tilnærming—en som tar hensyn til hvordan store språkmodeller henter, syntetiserer og tilskriver informasjon fra hele nettet.
Manuell prompttesting er fortsatt den mest tilgjengelige inngangsporten for å forstå din AI-synlighet, selv om det krever disiplin og dokumentasjon. Slik fungerer testing på tvers av de største AI-plattformene:
| AI-motor | Testtrinn | Fordeler | Ulemper |
|---|---|---|---|
| ChatGPT | Send inn prompter, gjennomgå svar, noter omtaler/sitater, dokumenter resultater | Direkte tilgang, detaljerte svar, siteringssporing | Tidskrevende, inkonsistente resultater, begrenset historiske data |
| Perplexity | Skriv inn forespørsler, analyser kildehenvisninger, spor siteringsplassering | Klare kildehenvisninger, sanntidsdata, brukervennlig | Manuell dokumentasjon kreves, begrenset antall forespørsler |
| Google AI Overviews | Søk i Google, gjennomgå AI-genererte oppsummeringer, noter kildeinkludering | Integrert med søk, høyt trafikkpotensial, naturlig brukeradferd | Begrenset kontroll over variasjon i forespørsler, inkonsistent visning |
| Google AI Mode | Tilgang via Google Labs, test spesifikke forespørsler, spor featured snippets | Fremvoksende plattform, direkte testtilgang | Plattform i tidlig fase, begrenset tilgjengelighet |
ChatGPT-testing og Perplexity-testing utgjør grunnmuren i de fleste manuelle teststrategier, ettersom disse plattformene representerer de største brukerbasene og mest gjennomsiktige siteringsmekanismer.
Selv om manuell testing gir verdifulle innsikter, blir det raskt upraktisk i stor skala. Å teste selv 50 prompter manuelt på fire AI-motorer krever over 200 individuelle forespørsler, hver med manuell dokumentasjon, skjermbildeopptak og resultatanalyse—en prosess som tar 10–15 timer per testsyklus. Manuelle begrensninger går utover tidsbruken: menneskelige testere gir inkonsistente resultater, sliter med å opprettholde nødvendig testfrekvens for trendsporing og kan ikke aggregere data fra hundrevis av prompter for å avdekke mønstre. Skaleringsproblemet blir akutt når du må teste merkevarevariasjoner, ikke-merkevarevariasjoner, long-tail-forespørsler og konkurransebenchmarking samtidig. I tillegg gir manuell testing kun øyeblikksbilder; uten automatiserte systemer kan du ikke spore hvordan synligheten endres uke for uke eller identifisere hvilke innholdsoppdateringer som faktisk har forbedret din AI-tilstedeværelse.
Automatiserte AI-synlighetsverktøy fjerner det manuelle arbeidet ved å kontinuerlig sende inn prompter til AI-motorer, fange opp svar og aggregere resultater i dashbord. Disse plattformene bruker API-er og automatiserte arbeidsflyter for å teste hundrevis eller tusenvis av prompter etter dine definerte tidsplaner—daglig, ukentlig eller månedlig—uten menneskelig innblanding. Automatisert testing fanger opp strukturerte data om omtaler, sitater, attribusjonsnøyaktighet og sentiment på tvers av alle de største AI-motorene samtidig. Sanntidsovervåking gjør det mulig å oppdage synlighetsendringer umiddelbart, korrelere dem med innholdsoppdateringer eller algoritmeendringer og svare strategisk. Dataaggregasjonsevnen til disse plattformene avslører mønstre usynlige for manuell testing: hvilke temaer gir flest sitater, hvilke innholdsformater foretrekker AI-motorene, hvordan din share of voice sammenlignes med konkurrenter og om sitatene dine inneholder korrekt attribusjon og lenker. Denne systematiske tilnærmingen gjør AI-synlighet om til en kontinuerlig informasjonsstrøm som styrker innholdsstrategi og konkurranseposisjonering.
Vellykkede prompttesting-best practices krever gjennomtenkt valg av prompter og balanserte testporteføljer. Vurder disse sentrale elementene:
AI-synlighetsmålinger gir et flerdimensjonalt bilde av din tilstedeværelse på tvers av generative AI-plattformer. Siteringssporing viser ikke bare om du dukker opp, men hvor fremtredende—om du er hovedkilde, én av flere kilder eller nevnt i forbifarten. Share of voice sammenligner hvor ofte du blir sitert mot konkurrenter innen samme tema, noe som indikerer konkurranseposisjon og innholdsmessig autoritet. Sentimentanalyse, utviklet av plattformer som Profound, vurderer om dine sitater presenteres positivt, nøytralt eller negativt i AI-svar—kritisk kontekst som rene omtaletall ikke fanger. Attribusjonsnøyaktighet er like viktig: tilskriver AI-motoren innholdet ditt med lenke, eller parafraserer den uten henvisning? Å forstå disse målingene krever kontekstuell analyse—en enkelt omtale i en høyt trafikkert forespørsel kan veie tyngre enn ti omtaler i lavvolum-forespørsler. Konkurransebenchmarking gir viktig perspektiv: hvis du vises i 40 % av relevante prompter, men konkurrentene i 60 %, har du identifisert et synlighetsgap som bør adresseres.
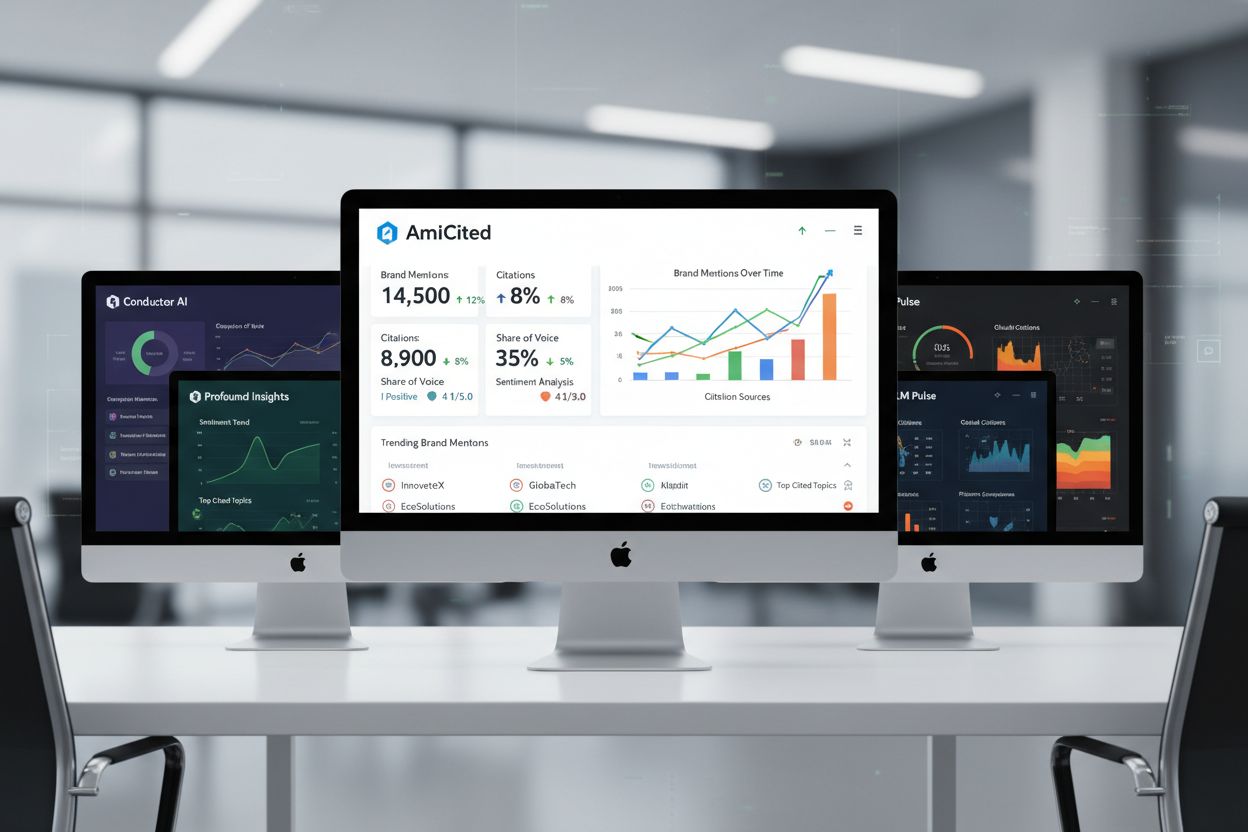
Markedet for AI-synlighetsplattformer inkluderer flere spesialiserte verktøy, alle med sine styrker. AmICited gir omfattende siteringssporing på tvers av ChatGPT, Perplexity og Google AI Overviews, med detaljert attribusjonsanalyse og konkurransebenchmarking. Conductor fokuserer på prompt-nivåsporing og temamessig autoritetskartlegging, noe som hjelper team å forstå hvilke temaer som gir mest AI-synlighet. Profound legger vekt på sentimentanalyse og nøyaktighet i kildehenvisninger, avgjørende for å forstå hvordan AI-motorer presenterer innholdet ditt. LLM Pulse tilbyr veiledning for manuell testing og dekning av nye plattformer, nyttig for team som bygger testprosesser fra bunnen av. Valget avhenger av dine prioriteringer: hvis omfattende automatisering og konkurranseanalyse er viktigst, utmerker AmICited seg; hvis temakartlegging er sentralt, passer Conductors tilnærming bedre; hvis det er kritisk å forstå hvordan AI-motorene rammer inn innholdet ditt, utmerker Profounds sentimentfunksjoner seg. De mest avanserte teamene bruker ofte flere plattformer for å få komplementære innsikter.
Organisasjoner undergraver ofte testarbeidet sitt med unngåelige feil. Overdreven bruk av merkevareprompter gir et feilaktig inntrykk av synlighet—du kan rangere godt for “Firmanavn”-søk, men forbli usynlig på de bransjetemaene som faktisk gir oppdagelse og trafikk. Ujevn testplan gir upålitelige data; testing sporadisk gjør det umulig å skille reelle synlighetstrender fra normale svingninger. Å ignorere sentimentanalyse fører til feiltolkning av resultater—å dukke opp i et AI-svar som fremstiller innholdet ditt negativt eller løfter frem konkurrenter, kan faktisk skade posisjoneringen din. Å mangle side-nivå data hindrer optimalisering: å vite at du dukker opp på et tema er verdifullt, men å vite hvilke sider som vises og hvordan de blir kreditert muliggjør målrettede innholdsforbedringer. En annen kritisk feil er å bare teste nåværende innhold; testing av historisk innhold viser om eldre sider fortsatt gir AI-synlighet, eller om de er blitt forbigått av nyere kilder. Til slutt, å ikke koble testresultater til innholdsendringer betyr at du ikke lærer hvilke oppdateringer som faktisk forbedrer AI-synligheten, og forhindrer kontinuerlig optimalisering.
Prompttesting-resultater bør direkte informere din innholdsstrategi og AI-optimaliseringsprioriteringer. Når testing viser at konkurrenter dominerer et høyt volum-tema der du har lav synlighet, blir det temaet en innholdsprioritet—enten gjennom nytt innhold eller optimalisering av eksisterende sider. Testresultater viser hvilke innholdsformater AI-motorene foretrekker: hvis konkurrentenes listeartikler vises oftere enn dine langformguider, kan formatoptimalisering forbedre synligheten. Temaautoritet fremgår av testdata—temaer der du vises konsistent på tvers av flere promptvariasjoner indikerer etablert autoritet, mens temaer der du dukker opp sporadisk tyder på innholdshull eller svak posisjonering. Bruk testing for å validere strategi før du investerer tungt: hvis du planlegger å rette deg mot et nytt tema, test nåværende synlighet først for å forstå konkurranseintensitet og realistisk synlighetspotensial. Testing avdekker også attribusjonsmønstre: hvis AI-motorene siterer innholdet ditt uten lenker, bør innholdsstrategien din vektlegge unike data, egen forskning og særpregede perspektiver som AI-motorene føler seg forpliktet til å kreditere. Til slutt—integrer testing i innholdskalenderen din—planlegg testsykluser rundt større innholdslanseringer for å måle effekt og juster strategi basert på faktisk AI-synlighet, ikke antakelser.
Manuell testing innebærer å sende inn prompter til AI-motorer én for én og dokumentere resultatene manuelt, noe som er tidkrevende og vanskelig å skalere. Automatisert testing bruker plattformer til kontinuerlig å sende inn hundrevis av prompter på tvers av flere AI-motorer etter en tidsplan, fanger opp strukturerte data og samler resultatene i dashbord for trendanalyse og konkurransebenchmarking.
Etabler en jevn testfrekvens på minst ukentlig eller annenhver uke for å spore meningsfulle trender og korrelere synlighetsendringer med innholdsoppdateringer eller algoritmeendringer. Hyppigere testing (daglig) er gunstig for høyprioriterte temaer eller konkurranseutsatte markeder, mens sjeldnere testing (månedlig) kan være tilstrekkelig for stabile, modne innholdsområder.
Følg 75/25-regelen: omtrent 75 % ikke-merkevareprompter (bransjetemaer, problemstillinger, informasjonsforespørsler) og 25 % merkevareprompter (firmanavn, produktnavn, merkevare-nøkkelord). Denne balansen hjelper deg å forstå både oppdagelsessynlighet og merkevarespesiell tilstedeværelse uten å overdrive resultatene med spørsmål du sannsynligvis allerede dominerer.
Du vil begynne å se de første signalene innen de første testsyklusene, men meningsfulle mønstre dukker vanligvis opp etter 4-6 uker med jevn sporing. Denne tidsrammen lar deg etablere et grunnlag, ta høyde for naturlige svingninger i AI-responsene og korrelere synlighetsendringer med spesifikke innholdsoppdateringer eller optimaliseringstiltak.
Ja, du kan utføre manuell testing gratis ved å gå direkte inn på ChatGPT, Perplexity, Google AI Overviews og Google AI Mode. Imidlertid er gratis manuell testing begrenset i omfang og konsistens. Automatiserte plattformer som AmICited tilbyr gratis prøveperioder eller freemium-alternativer for å teste tilnærmingen før du forplikter deg til betalte abonnementer.
De viktigste måleparametrene er sitater (når AI-motorer lenker til ditt innhold), omtaler (når merkevaren nevnes), share of voice (din synlighet sammenlignet med konkurrenter) og sentiment (om dine sitater presenteres positivt). Attribusjonsnøyaktighet – om AI-motorene gir korrekt kreditering til ditt innhold – er også kritisk for å forstå den reelle synlighetseffekten.
Effektive prompter genererer konsistente, handlingsrettede data som samsvarer med dine forretningsmål. Test om prompterne dine reflekterer reell brukeradferd ved å sammenligne dem med søkedata, kundeintervjuer og salgssamtaler. Prompter som gir synlighetsendringer etter innholdsoppdateringer er spesielt verdifulle for å validere teststrategien din.
Start med de største motorene (ChatGPT, Perplexity, Google AI Overviews) som representerer de største brukerbasene og trafikkpotensialet. Etter hvert som programmet ditt modnes, utvid til nye motorer som Gemini, Claude og andre relevante for målgruppen din. Valget avhenger av hvor målgruppen faktisk bruker tid og hvilke motorer som gir mest henvisningstrafikk til siden din.
Test merkevarens tilstedeværelse i ChatGPT, Perplexity, Google AI Overviews og mer med AmICiteds omfattende overvåking av AI-synlighet.
Lær hvordan du bygger og bruker promptbiblioteker for manuell AI-synlighetstesting. DIY-guide til å teste hvordan AI-systemer refererer til merkevaren din på tv...

Lær hvordan du lager og organiserer et effektivt promptbibliotek for å spore merkevaren din på tvers av ChatGPT, Perplexity og Google AI. Trinnvis guide med bes...

Lær hvordan du gjennomfører effektiv promptforskning for AI-synlighet. Oppdag metodikken for å forstå brukerforespørsler i LLM-er og spore merkevaren din i Chat...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.