
Hvordan får jeg produkter anbefalt av AI?
Lær hvordan AI-produktanbefalinger fungerer, algoritmene bak dem, og hvordan du kan optimalisere synligheten din i AI-drevne anbefalingssystemer på tvers av Cha...
8 min lesing
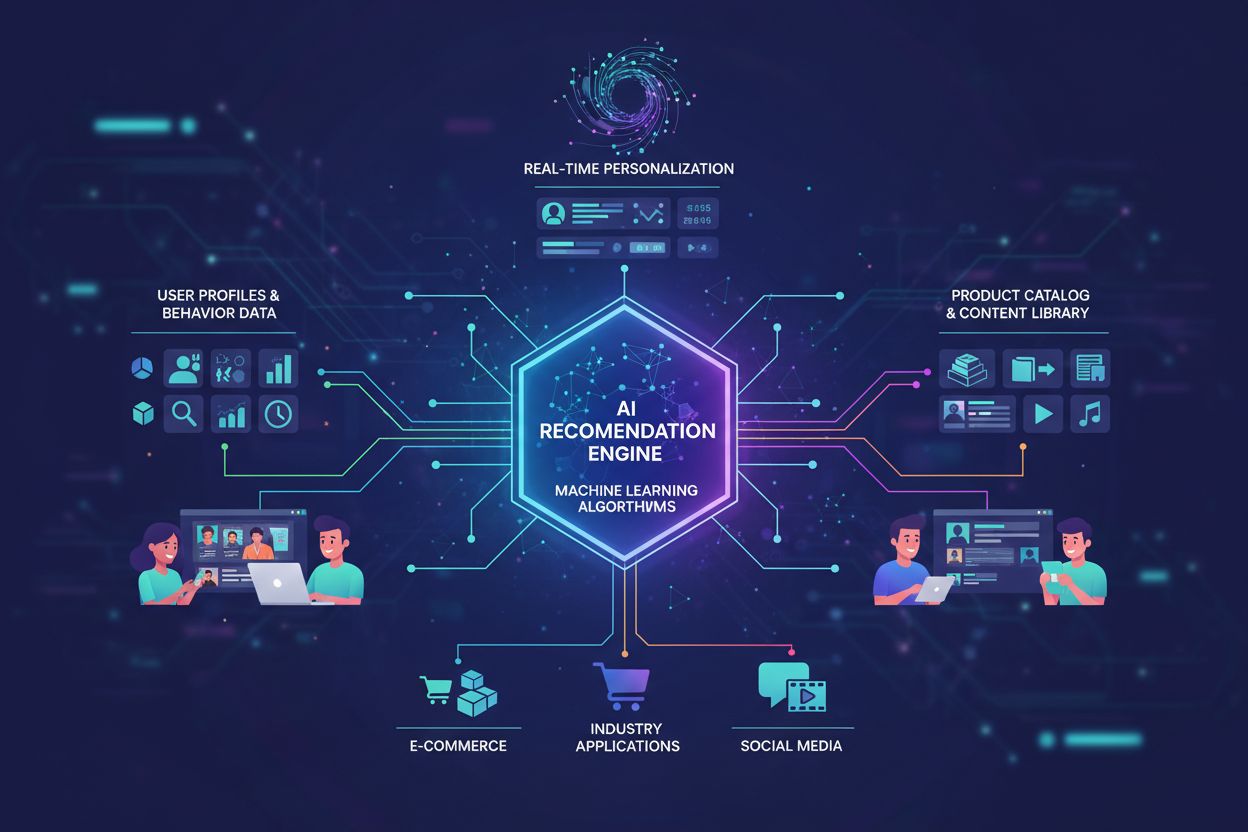
Maskinlæringssystemer som analyserer brukeradferd og preferanser for å levere personlige produkt- og innholdsanbefalinger. Disse systemene benytter algoritmer som samarbeidsfiltrering og innholdsbasert filtrering for å forutsi hva brukere kan være interessert i, noe som gjør det mulig for bedrifter å øke engasjement, salg og kundetilfredshet gjennom skreddersydde anbefalinger.
Maskinlæringssystemer som analyserer brukeradferd og preferanser for å levere personlige produkt- og innholdsanbefalinger. Disse systemene benytter algoritmer som samarbeidsfiltrering og innholdsbasert filtrering for å forutsi hva brukere kan være interessert i, noe som gjør det mulig for bedrifter å øke engasjement, salg og kundetilfredshet gjennom skreddersydde anbefalinger.
AI-drevne anbefalinger representerer en avansert teknologi som bruker maskinlæringsalgoritmer for å analysere brukeradferd og preferanser, og leverer personlige forslag tilpasset individuelle behov og interesser. En anbefalingsmotor er kjernen i dette systemet, og fungerer som et intelligent mellomledd mellom store produktkataloger og individuelle brukere, noe som muliggjør enestående grad av personalisering i stor skala. Det globale markedet for anbefalingsmotorer har opplevd eksplosiv vekst, med en verdi på rundt 2,8 milliarder dollar i 2023 og forventet å nå 8,5 milliarder dollar innen 2030, noe som reflekterer denne teknologiens kritiske betydning i den digitale økonomien. Disse AI-drevne anbefalingene har blitt uunnværlige på tvers av ulike bransjer, med fremtredende anvendelser i e-handelsplattformer som Amazon og eBay, strømmetjenester som Netflix og Spotify, sosiale medier og innholdsplattformer. Det grunnleggende prinsippet bak disse systemene er at maskinlæringsalgoritmer kan identifisere mønstre i brukeradferd som mennesker ikke lett oppdager, slik at virksomheter kan forutse kundebehov før brukerne selv er klar over dem. Ved å utnytte store datasett og beregningskraft har anbefalingssystemer forvandlet hvordan forbrukere oppdager produkter, innhold og tjenester, og fundamentalt endret strategiene for kundeengasjement på tvers av bransjer.

AI-drevne anbefalingssystemer opererer gjennom en sofistikert fem-faseprosess som forvandler rå brukerdata til handlingsrettede personlige forslag. Den første fasen innebærer omfattende datainnsamling, hvor systemene samler informasjon fra flere kontaktpunkter, inkludert brukerinteraksjoner, nettleserhistorikk, kjøpshistorikk og eksplisitte tilbakemeldingsmekanismer. Under analysefasen prosesserer systemet de innsamlede dataene for å identifisere meningsfulle mønstre og sammenhenger, og benytter maskinlæringsalgoritmer som samarbeidsfiltrering, innholdsbasert filtrering og nevrale nettverk for å trekke ut innsikt fra komplekse datasett. Mønster-gjenkjenningsfasen utgjør det beregningsmessige hjertet av systemet, hvor algoritmer identifiserer likheter mellom brukere, elementer eller begge deler, og lager matematiske representasjoner av preferanser og elementegenskaper. Prediksjonsfasen bruker disse identifiserte mønstrene til å forutsi hvilke elementer en bruker mest sannsynlig vil engasjere seg med, og tilordner tillitspoeng til potensielle anbefalinger. Til slutt presenterer leveringsfasen disse prediksjonene til brukerne gjennom personlige grensesnitt, slik at anbefalingene vises på optimale tidspunkt i brukerreisen. Sanntids prosesseringskapasitet har blitt stadig viktigere, hvor moderne systemer oppdaterer anbefalinger umiddelbart når ny brukeradferd registreres, noe som muliggjør dynamisk personalisering som tilpasser seg endrede preferanser. Avanserte anbefalingssystemer benytter ensemble-metoder som kombinerer flere algoritmer samtidig, der hver algoritme bidrar med sine prediksjoner for å generere mer robuste og nøyaktige anbefalinger enn hva én enkelt tilnærming kan oppnå alene.
Anbefalingssystemer er avhengige av to distinkte kategorier brukerdata, som hver gir unike innsikter i preferanser og adferdsmønstre:
Eksplisitte data:
Implisitte data:
Eksplisitte data gir direkte og entydige signaler om brukerpreferanser, men lider av sparsommelighet, siden de fleste brukere bare vurderer en liten andel av tilgjengelige elementer. Implisitte data, derimot, er rikelige og genereres kontinuerlig gjennom normal adferd, men krever sofistikert tolkning fordi handlinger som å se på et produkt ikke nødvendigvis betyr preferanse. De mest effektive anbefalingssystemene integrerer begge datatyper, bruker eksplisitt tilbakemelding for å validere og kalibrere implisitte signaler, og skaper omfattende brukerprofiler som fanger både uttalte og faktisk viste preferanser.
Samarbeidsfiltrering er en av de grunnleggende metodene i anbefalingssystemer, og bygger på prinsippet om at brukere med lignende preferanser tidligere sannsynligvis vil like de samme elementene i fremtiden. Denne metoden analyserer mønstre i hele brukerpopulasjonen for å identifisere fellestrekk, i motsetning til tilnærminger som undersøker individuelle elementegenskaper. Brukerbasert samarbeidsfiltrering identifiserer brukere med lignende preferansehistorikk som målbrukeren, og anbefaler deretter elementer disse lignende brukerne har likt, men som målbrukeren ennå ikke har oppdaget, og utnytter på denne måten visdommen til sammenlignbare brukere. Elementbasert samarbeidsfiltrering fokuserer derimot på likheter mellom elementer, og anbefaler produkter som ligner på elementer brukeren tidligere har vurdert høyt, basert på hvordan andre brukere har vurdert disse elementene i forhold til hverandre. Begge tilnærmingene benytter sofistikerte mål for likhet, som cosinuslikhet, Pearson-korrelasjon eller euklidisk avstand for å måle hvor tett brukere eller elementer ligner hverandre i preferanserommet. Samarbeidsfiltrering har betydelige fordeler, inkludert evnen til å anbefale elementer uten innholdsmetadata og muligheten til å oppdage uventede anbefalinger brukere ikke selv ville funnet. Metoden har imidlertid begrensninger, særlig “cold start-problemet” der nye brukere eller elementer mangler tilstrekkelig historikk for nøyaktige beregninger, samt dataskrinnhet i domener med millioner av elementer der de fleste bruker-element-interaksjoner er uobserverte.
Innholdsbasert filtrering gir anbefalinger ved å analysere de iboende egenskapene og kjennetegnene til elementene selv, og anbefaler produkter som ligner dem brukeren tidligere har foretrukket basert på målbare attributter. I stedet for å stole på kollektive brukermønstre, bygger innholdsbaserte systemer detaljerte elementprofiler med relevante trekk som sjanger, regissør og skuespillere for filmer; forfatter, emne og utgivelsesdato for bøker; eller produktkategori, merke og spesifikasjoner for e-handel. Systemet beregner likhet mellom elementer ved å sammenligne deres egenskapsvektorer med matematiske teknikker som cosinuslikhet eller euklidisk avstand, og skaper et kvantitativt mål på hvor tett elementene ligner hverandre i egenskapsrommet. Når en bruker vurderer eller engasjerer seg med et element, identifiserer systemet andre elementer med tilsvarende egenskapsprofiler og anbefaler disse, slik at forslagene blir tilpasset brukte preferanser for bestemte egenskaper. Innholdsbasert filtrering utmerker seg i scenarioer der elementmetadata er rike og godt strukturerte, og den håndterer cold start-problemet for nye elementer naturlig, siden anbefalinger er basert på elementegenskaper fremfor brukerhistorikk. Denne tilnærmingen har imidlertid begrensninger i form av uventede oppdagelser, ettersom den ofte anbefaler svært like elementer som fører til filterbobler og snevrer inn utvalget. Sammenlignet med samarbeidsfiltrering krever innholdsbaserte systemer eksplisitt feature engineering og har utfordringer med elementer som mangler klare kategorigrensene, men de gir bedre transparens fordi anbefalinger kan forklares med referanse til spesifikke attributter.
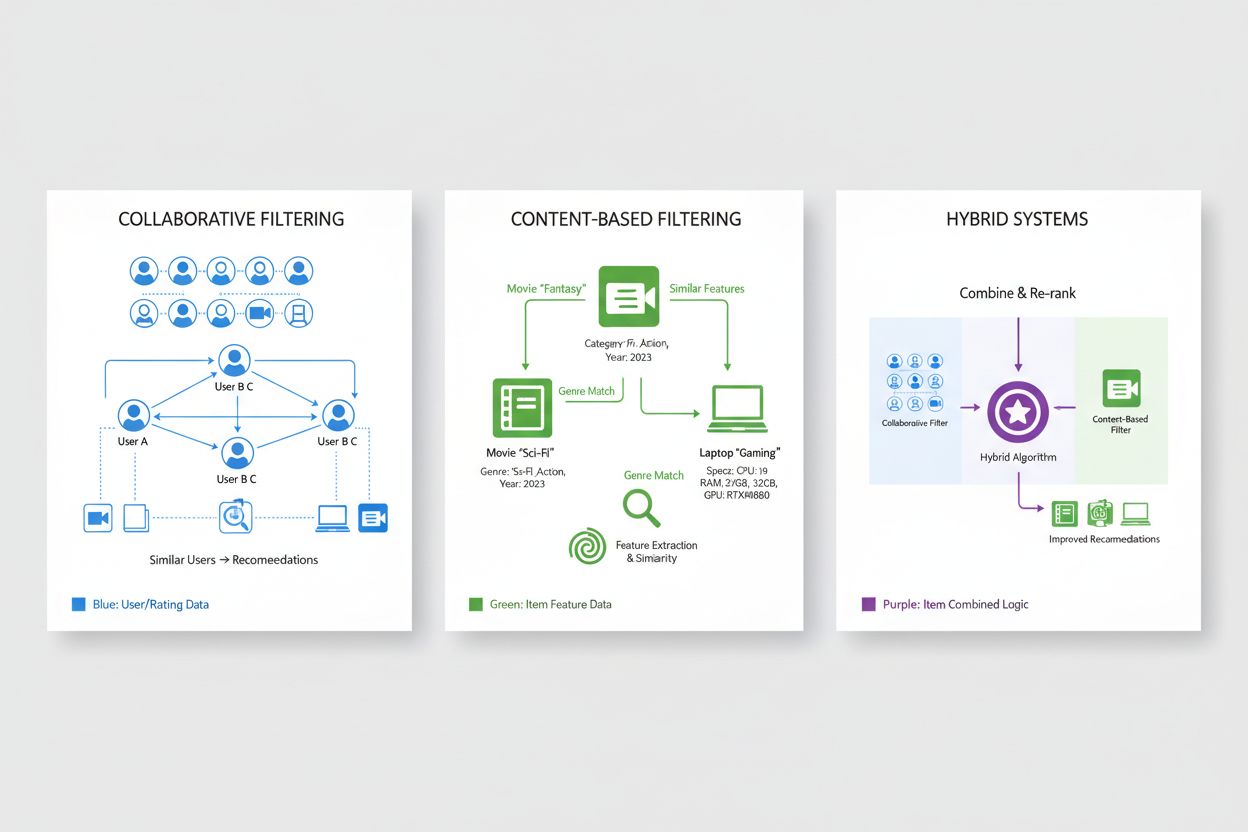
Hybride anbefalingssystemer kombinerer samarbeidsfiltrering og innholdsbasert filtrering strategisk, og utnytter de komplementære styrkene ved hver metode for å overvinne individuelle begrensninger og gi bedre anbefalingsnøyaktighet. Disse systemene benytter flere integrasjonsstrategier, inkludert vektede kombinasjoner hvor prediksjoner fra ulike algoritmer slås sammen med forhåndsbestemte eller lærte vekter, byttemekanismer som velger den mest hensiktsmessige algoritmen ut fra kontekst, eller kaskadetilnærminger der én algoritmes utdata mates inn i en annen. Ved å integrere samarbeidsfiltreringens evne til å identifisere uventede anbefalinger og fange komplekse preferansemønstre med innholdsbasert filtrerings evne til å håndtere nye elementer og gi forklarbare anbefalinger, oppnår hybride systemer mer robust ytelse i ulike scenarioer. Store teknologiselskaper har tatt i bruk hybride tilnærminger som industristandard; Netflix kombinerer samarbeidsfiltrering med innholdsbaserte metoder og kontekstuell informasjon for å levere anbefalinger som balanserer popularitet, personalisering og nyhet. Spotifys anbefalingsmotor benytter også hybride teknikker, med samarbeidsfiltrering basert på lyttevaner, innholdsbasert analyse av lydtrekk og metadata, samt naturlig språkprosessering av brukeropprettede spillelister og anmeldelser. Fordelene med hybride systemer strekker seg utover nøyaktighetsforbedringer, og omfatter bedre dekning av elementkatalogen, bedre håndtering av sparsomme data og økt robusthet mot vanlige utfordringer i anbefalinger. Disse systemene representerer det mest avanserte innen personaliseringsteknologi, og de fleste anbefalingsplattformer på bedriftsnivå implementerer hybride arkitekturer som kontinuerlig utvikles etter hvert som nye algoritmiske innovasjoner kommer til.
AI-drevne anbefalinger har blitt sentrale i forretningsmodellene til store teknologiselskaper og detaljhandel, og har fundamentalt endret hvordan kunder oppdager og kjøper produkter. Amazon, pioneren innen e-handel, genererer omtrent 35 % av sin totale omsetning fra anbefalingsdrevne kjøp, med et sofistikert system som analyserer nettleserhistorikk, kjøpsmønstre, produktvurderinger og lignende kunders atferd for å foreslå varer på viktige beslutningstidspunkter gjennom hele kjøpsreisen. Netflix analyserer visningshistorikk, vurderinger, søkeatferd og tidsmønstre for å foreslå innhold, og selskapet rapporterer at personlige anbefalinger utgjør omtrent 80 % av timer sett på plattformen, noe som viser den dype effekten av effektiv personalisering på brukerengasjement og lojalitet. Spotify bruker AI-drevne anbefalinger på flere flater, inkludert “Discover Weekly”-spillelisten, som kombinerer samarbeidsfiltrering med lydtrekkanalyse og kontekstuell informasjon, og genererer svært personlige musikkforslag som har blitt sentrale for brukerengasjement og abonnementslojalitet. Temu, den hurtigvoksende e-handelsplattformen, bruker avanserte anbefalingssystemer som analyserer brukeradferd, søk og kjøpshistorikk for å vise produkter tilpasset individuelle preferanser, noe som bidrar betydelig til selskapets eksplosive vekst og engasjementstall. Disse implementasjonene viser at anbefalingssystemer har direkte innvirkning på nøkkeltall som kundens livstidsverdi, gjentatte kjøp og engasjementstid, og at selskaper investerer tungt i anbefalingsteknologi som en kjernefordel i stadig mer konkurranseutsatte digitale markeder.
AI-drevne anbefalinger gir betydelig verdi til både virksomheter og brukere, og skaper et gjensidig fordelaktig økosystem som styrker engasjement og tilfredshet:
Fordeler for virksomheter:
Fordeler for brukere:
Den samlede effekten av disse fordelene har gjort anbefalingssystemer til grunnleggende infrastruktur i digital handel og innholdsplattformer, og brukere forventer i økende grad personaliserte opplevelser som en grunnleggende funksjon snarere enn et premiumtilbud.
Selv om AI-drevne anbefalingssystemer har hatt stor suksess, står de overfor betydelige utfordringer som forskere og praktikere fortsatt jobber med å løse. Bekymringer om personvern har økt etter hvert som regelverk som GDPR og CCPA stiller strenge krav til datainnsamling og bruk, og tvinger selskaper til å balansere effektiv personalisering med brukernes personvernrettigheter og databeskyttelse. Cold start-problemet er spesielt utfordrende for nye brukere og elementer, hvor manglende historikk hindrer nøyaktige anbefalinger og krever hybride tilnærminger eller alternative strategier for å starte personalisering. Algoritmisk skjevhet er en kritisk utfordring, da anbefalingssystemer kan opprettholde og forsterke eksisterende skjevheter i treningsdata, noe som kan innebære diskriminering av enkelte brukergrupper eller skape filterbobler som begrenser tilgang til ulike perspektiver og innhold.
Fremvoksende trender former anbefalingslandskapet, med sanntidspersonalisering som blir stadig mer avansert gjennom edge computing og strømmende databehandling som muliggjør umiddelbar tilpasning til brukeradferd. Multimodal dataintegrasjon utvider seg utover tradisjonelle atferdssignaler til også å omfatte visuelle egenskaper, lydkarakteristikker, tekstinnhold og kontekstuell informasjon, og gir en rikere og mer nyansert forståelse av brukerpreferanser. Følelsesbaserte anbefalinger representerer en ny grense innen personalisering, hvor systemer begynner å inkludere emosjonell kontekst og sentimentanalyse for å gi anbefalinger tilpasset ikke bare historiske preferanser, men også nåværende følelsesmessige tilstander og behov. Fremtidige utviklinger vil trolig vektlegge forklarbarhet og transparens, slik at brukerne forstår hvorfor bestemte anbefalinger vises, og gi kontrollmekanismer som lar brukerne forme sine anbefalingsprofiler. Sammenløpet av disse trendene antyder at neste generasjons anbefalingssystemer vil være mer personvernsbevisste, transparente, emosjonelt intelligente og i stand til å levere virkelig transformative personaliseringsopplevelser, samtidig som brukernes autonomi og datarrettigheter respekteres.
AI-drevne anbefalinger foreslår proaktivt elementer basert på brukeradferd og preferanser uten at brukeren eksplisitt søker, mens tradisjonelt søk krever at brukerne aktivt søker etter produkter. Anbefalinger bruker maskinlæring for å forutsi interesser, mens søk er basert på nøkkelordmatching. Anbefalinger er tilpasset den enkelte bruker, mens søkeresultater vanligvis er mer generiske. Moderne systemer kombinerer ofte begge tilnærmingene for optimal brukeropplevelse.
Nye brukere møter 'cold start-problemet' der systemene mangler historiske data for nøyaktige anbefalinger. Løsninger inkluderer bruk av demografiske opplysninger, vise populære elementer, innholdsbasert filtrering basert på elementegenskaper, eller å be om eksplisitte preferanser. Hybride systemer kombinerer flere tilnærminger for å starte anbefalinger for nye brukere. Noen plattformer bruker samarbeidsfiltrering med lignende brukerprofiler eller kontekstuell informasjon som enhetstype og plassering for å gi innledende forslag.
Anbefalingssystemer samler inn eksplisitte data som vurderinger, anmeldelser og brukertilbakemeldinger, samt implisitte data inkludert nettleserhistorikk, kjøpshistorikk, tid brukt på elementer, søk og klikkmønstre. De kan også samle kontekstuell informasjon som enhetstype, plassering, tid på døgnet og sesongfaktorer. Avanserte systemer integrerer demografiske data, sosiale forbindelser og atferdssignaler. All datainnsamling må overholde personvernlovgivning som GDPR og CCPA, som krever brukersamtykke og transparente retningslinjer for databruk.
Ja, anbefalingssystemer kan opprettholde og forsterke skjevheter som finnes i treningsdata, noe som potensielt kan diskriminere enkelte brukergrupper eller begrense eksponeringen for variert innhold. Algoritmisk skjevhet kan skyldes skjeve historiske data, underrepresentasjon av minoritetsgrupper eller tilbakemeldingssløyfer som forsterker eksisterende mønstre. For å motvirke skjevhet kreves mangfoldige treningsdata, regelmessige revisjoner, rettferdighetsmålinger og transparent algoritmedesign. Bedrifter må aktivt overvåke for skjevhet og implementere tiltak for rettferdige anbefalinger til alle brukersegmenter.
Hybride systemer kombinerer samarbeidsfiltreringens evne til å finne uventede anbefalinger med innholdsbasert filtrerings evne til å håndtere nye elementer og gi forklarbare forslag. Denne kombinasjonen løser individuelle begrensninger: samarbeidsfiltrering sliter med nye elementer, mens innholdsbasert filtrering mangler uventede oppdagelser. Hybride tilnærminger bruker vektede kombinasjoner, byttemekanismer eller kaskademetoder for å utnytte hver algoritmes styrker. Resultatet er bedre nøyaktighet, bedre dekning av elementkatalogen, forbedret håndtering av sparsomme data og mer robust ytelse i ulike scenarioer.
Personvernutfordringer inkluderer omfattende datainnsamling som kreves for nøyaktige anbefalinger, potensiell uautorisert bruk av data, risiko for datainnbrudd og utfordringer med overholdelse av regler som GDPR, CCPA og lignende lover. Brukere kan føle seg ukomfortable med graden av atferdssporing som trengs for personalisering. Bedrifter må sikre god datasikkerhet, innhente eksplisitt samtykke, være transparente om databruk og gi brukere mulighet til å kontrollere egne data. Å balansere effektiv personalisering med personvern er en vedvarende utfordring i bransjen.
Sanntidsanbefalinger behandler brukerdata umiddelbart etter hvert som de oppstår, og oppdaterer forslag umiddelbart basert på nåværende interaksjoner. Systemene bruker strømmende databehandling og edge computing for å analysere handlinger som klikk, visninger eller kjøp på millisekunder. Dette muliggjør dynamisk personalisering som tilpasser seg endrende preferanser gjennom hele brukersesjonen. Sanntidssystemer krever robust infrastruktur, effektive algoritmer og datarørledninger med lav forsinkelse. Eksempler inkluderer at Netflix oppdaterer anbefalinger mens du blar, eller Amazon viser nye forslag etter hvert som du legger til varer i handlekurven.
Fremtidige trender inkluderer følelsesbaserte anbefalinger som tar hensyn til brukernes følelsesmessige tilstand, multimodal dataintegrasjon som kombinerer visuell, lyd- og tekstinformasjon, forbedrede personvernmetoder, bedre forklarbarhet og transparens, samt sanntidspersonalisering i stor skala. Fremvoksende teknologier som føderert læring muliggjør anbefalinger uten sentralisering av brukerdata. Systemene vil bli mer kontekstbevisste og ta hensyn til tidsmessige og situasjonsavhengige faktorer. Sammenløpet av disse trendene vil gi mer sofistikert, transparent og personvernsbevisst personalisering, samtidig som brukernes autonomi og datarrettigheter ivaretas.
AmICited sporer hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews nevner merkevaren din i personlige anbefalinger og AI-generert innhold. Hold deg informert om merkevarens synlighet i AI-drevne systemer.
Lær hvordan AI-produktanbefalinger fungerer, algoritmene bak dem, og hvordan du kan optimalisere synligheten din i AI-drevne anbefalingssystemer på tvers av Cha...
Oppdag hvordan autentiske kundeanbefalinger øker din AI-synlighet på tvers av Google AI Overviews, ChatGPT og Perplexity. Lær hvorfor ekte kundestemmer er vikti...

Oppdag hvordan G2 og Capterra-anmeldelser påvirker AI-merkets synlighet og LLM-siteringer. Lær hvorfor vurderingsplattformer er avgjørende for oppdagelse og anb...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.