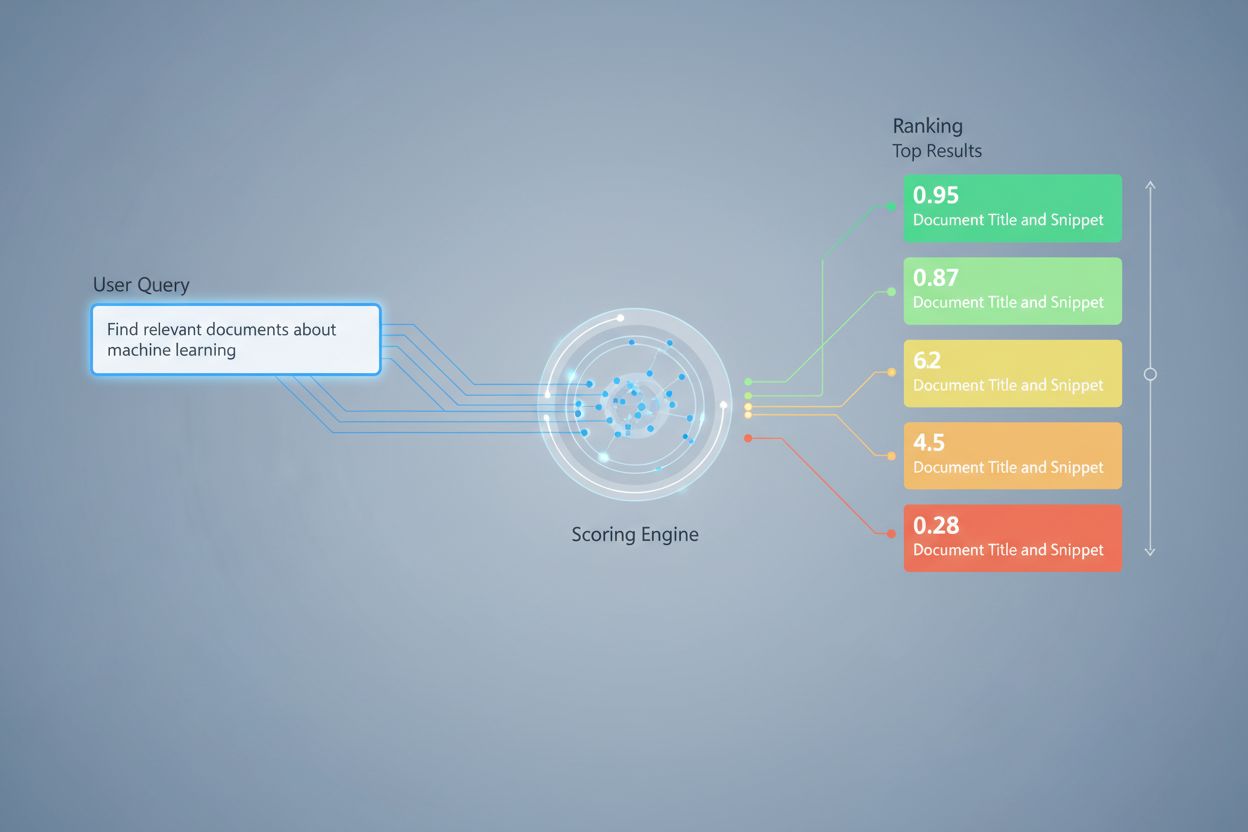
AI-hentepoeng er prosessen med å kvantifisere relevansen og kvaliteten på hentede dokumenter eller avsnitt i forhold til en brukerspørring. Det benytter sofistikerte algoritmer for å vurdere semantisk mening, kontekstuell hensiktsmessighet og informasjonskvalitet, og avgjør hvilke kilder som sendes videre til språkmodeller for svargenerering i RAG-systemer.
AI-hentepoeng
AI-hentepoeng er prosessen med å kvantifisere relevansen og kvaliteten på hentede dokumenter eller avsnitt i forhold til en brukerspørring. Det benytter sofistikerte algoritmer for å vurdere semantisk mening, kontekstuell hensiktsmessighet og informasjonskvalitet, og avgjør hvilke kilder som sendes videre til språkmodeller for svargenerering i RAG-systemer.
Hva er AI-hentepoeng
AI-hentepoeng er prosessen med å kvantifisere relevansen og kvaliteten på hentede dokumenter eller avsnitt i forhold til en brukerspørring eller oppgave. I motsetning til enkel nøkkelordmatching, som bare identifiserer overflate-likheter mellom ord, benytter hentepoeng sofistikerte algoritmer for å vurdere semantisk mening, kontekstuell hensiktsmessighet og informasjonskvalitet. Denne poengmekanismen er grunnleggende for Retrieval-Augmented Generation (RAG)-systemer, hvor den avgjør hvilke kilder som sendes videre til språkmodeller for svargenerering. I moderne LLM-applikasjoner påvirker hentepoeng direkte svarnøyaktighet, reduksjon av hallusinasjoner og brukertilfredshet ved å sikre at kun den mest relevante informasjonen når genereringsstadiet. Kvaliteten på hentepoeng er derfor en kritisk komponent for systemets totale ytelse og pålitelighet.
Metoder og algoritmer for hentepoeng
Hentepoeng benytter flere algoritmiske tilnærminger, hver med ulike styrker for ulike bruksområder. Semantisk likhetspoeng bruker innleiringsmodeller for å måle konseptuell samsvar mellom spørringer og dokumenter i vektorrom, og fanger opp mening utover overfladiske nøkkelord. BM25 (Best Matching 25) er en sannsynlighetsbasert rangeringsfunksjon som tar hensyn til termfrekvens, omvendt dokumentfrekvens og normalisering av dokumentlengde, og er svært effektiv for tradisjonell teksthenting. TF-IDF (Term Frequency-Inverse Document Frequency) vekter termer etter deres betydning i dokumentene og på tvers av samlinger, men mangler semantisk forståelse. Hybride tilnærminger kombinerer flere metoder—som å slå sammen BM25- og semantiske poeng—for å utnytte både leksikale og semantiske signaler. Utover poengmetoder gir evalueringsmålinger som Precision@k (andel av topp-k-resultater som er relevante), Recall@k (andel av alle relevante dokumenter funnet i topp-k), NDCG (Normalisert Diskontert Kumulativ Gevinst, som tar hensyn til rangeringens posisjon), og MRR (Gjennomsnittlig Omvendt Rang) kvantitative mål på kvaliteten på henting. Å forstå styrker og svakheter ved hver tilnærming—som BM25s effektivitet versus semantisk poengs dypere forståelse—er essensielt for å velge riktige metoder for spesifikke applikasjoner.
Poengmetode
Hvordan det fungerer
Best for
Hovedfordel
Semantisk likhet
Sammenligner innleiringer ved bruk av cosinus-likhet eller andre avstandsmål
Konseptuell mening, synonymer, parafraser
Fanger opp semantiske relasjoner utover nøkkelord
BM25
Sannsynlighetsbasert rangering med termfrekvens og dokumentlengde
Eksakt frasematch, nøkkelordbaserte spørringer
Rask, effektiv, utprøvd i produksjonssystemer
TF-IDF
Vekter termer etter frekvens i dokument og sjeldenhet i samlingen
Tradisjonell informasjonsgjenfinning
Enkel, tolkbar, lett
Hybridpoeng
Kombinerer semantiske og nøkkelordbaserte tilnærminger med vektet sammenslåing
Allmenn henting, komplekse spørringer
Utnytter styrker fra flere metoder
LLM-basert poeng
Bruker språkmodeller til å vurdere relevans med tilpassede spørsmål
Kompleks kontekstevaluering, domenespesifikke oppgaver
Fanger opp nyanserte semantiske relasjoner
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
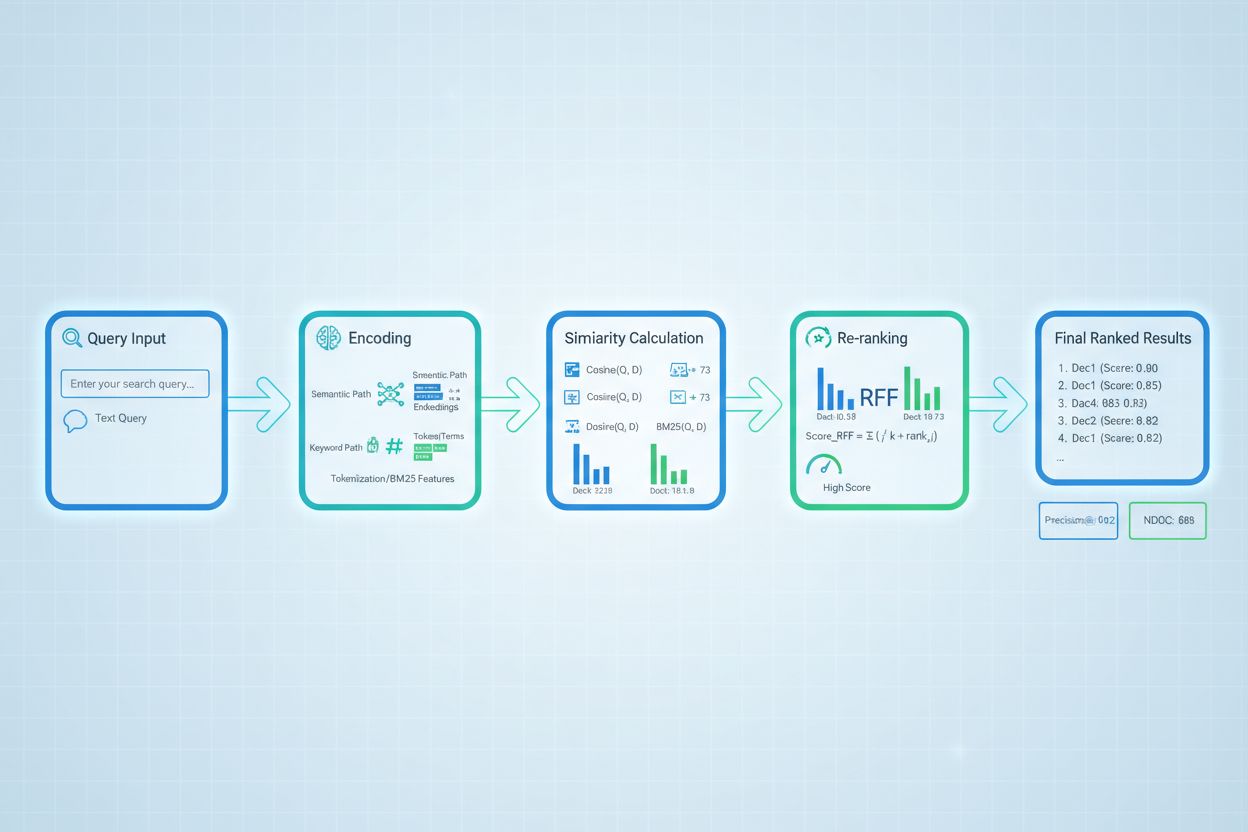
I RAG-systemer fungerer hentepoeng på flere nivåer for å sikre genereringskvalitet. Systemet poengsetter typisk individuelle biter eller avsnitt i dokumenter, slik at det er mulig med finmasket relevansevurdering fremfor å behandle hele dokumenter som enhet. Denne per-bit relevanspoengsettingen gjør det mulig for systemet å hente ut kun de mest relevante informasjonsdelene, og redusere støy og irrelevant kontekst som kan forvirre språkmodellen. RAG-systemer implementerer ofte poengterskler eller avskjæringsmekanismer som filtrerer ut lavt poengsatte resultater før de når genereringsstadiet, for å hindre at kilder av dårlig kvalitet påvirker sluttresultatet. Kvaliteten på hentet kontekst henger direkte sammen med genereringskvalitet—høyt poengsatte, relevante avsnitt gir mer nøyaktige og forankrede svar, mens lavkvalitets henting gir hallusinasjoner og faktafeil. Overvåking av hente-poeng gir tidlige varsler om systemforringelse, og er en sentral måling for AI-svarovervåking og kvalitetskontroll i produksjonssystemer.
Re-rangering og poengforbedring
Re-rangering fungerer som et andre filter som forbedrer de første henteresultatene, ofte med betydelig økt rangeringsnøyaktighet. Etter at en førstehenter har generert kandidatresultater med foreløpige poeng, bruker en re-ranker mer sofistikert poenglogikk for å omorganisere eller filtrere kandidatene, vanligvis med mer beregningskrevende modeller som kan analysere dypere. Reciprocal Rank Fusion (RRF) er en populær teknikk som kombinerer rangeringer fra flere hentere ved å gi poeng basert på resultatposisjon, og deretter flette disse poengene for å lage en samlet rangering som ofte overgår enkeltstående hentere. Poengnormalisering blir kritisk når man kombinerer resultater fra ulike hentemetoder, siden råpoeng fra BM25, semantisk likhet og andre tilnærminger opererer på ulike skalaer og må kalibreres til sammenlignbare områder. Ensemble-hentetilnærminger bruker flere hentestrategier samtidig, hvor re-rangering avgjør endelig rekkefølge basert på samlet bevis. Denne flerstegsprosessen forbedrer nøyaktighet og robusthet betydelig sammenlignet med enkeltstående henting, særlig i komplekse domener hvor ulike metoder fanger opp utfyllende relevanssignaler.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Viktige evalueringsmålinger for hentepoeng
Precision@k: Måler andelen relevante dokumenter blant de k toppresultatene; nyttig for å vurdere om de hentede resultatene er pålitelige (f.eks. Precision@5 = 4/5 betyr 80 % av topp 5-resultatene er relevante)
Recall@k: Beregner prosentandelen av alle relevante dokumenter som finnes blant de topp k-resultatene; viktig for å sikre fullstendig dekning av relevant informasjon
Hit Rate: Binær måling som viser om minst ett relevant dokument er blant topp k-resultatene; nyttig for raske kvalitetskontroller i produksjonssystemer
NDCG (Normalisert Diskontert Kumulativ Gevinst): Tar hensyn til rangposisjon ved å gi høyere verdi til relevante dokumenter som vises tidlig; går fra 0-1 og er ideell for å evaluere rangeringskvalitet
MRR (Gjennomsnittlig Omvendt Rang): Måler gjennomsnittlig posisjon for første relevante resultat på tvers av flere spørringer; spesielt nyttig for å vurdere om det mest relevante dokumentet rangeres høyt
F1-score: Harmonisk gjennomsnitt av presisjon og recall; gir balansert evaluering når både falske positive og negative har lik betydning
MAP (Mean Average Precision): Gjennomsnittlig presisjon på hver posisjon der et relevant dokument er funnet; omfattende måling for total rangeringskvalitet på tvers av flere spørringer
LLM-basert relevanspoeng
LLM-basert relevanspoeng bruker språkmodeller selv som dommere for dokumentrelevans, og gir et fleksibelt alternativ til tradisjonelle algoritmiske tilnærminger. I denne modellen gir nøye utformede spørsmål LLM-en instruks om å vurdere om et hentet avsnitt besvarer en gitt spørring, og gir enten binære relevanspoeng (relevant/ikke relevant) eller numeriske poeng (f.eks. 1-5-skala for relevansstyrke). Denne tilnærmingen fanger opp nyanserte semantiske relasjoner og domenespesifikk relevans som tradisjonelle algoritmer kan overse, særlig for komplekse spørringer som krever dyp forståelse. LLM-basert poengsetting gir imidlertid utfordringer som beregningskostnad (infernser med LLM er dyrt sammenlignet med innleiringslikhet), potensiell inkonsistens på tvers av spørsmål og modeller, og behovet for kalibrering med menneskelige etiketter for å sikre at poengene samsvarer med faktisk relevans. Til tross for begrensningene har LLM-basert poengsetting vist seg verdifull for evaluering av RAG-systemkvalitet og for å lage treningsdata for spesialiserte poengmodeller, og er et viktig verktøy i AI-overvåkingsverktøykassen for vurdering av svar-kvalitet.
Praktiske hensyn ved implementering
Effektiv implementering av hentepoeng krever nøye vurdering av flere praktiske faktorer. Metodevalg avhenger av kravene til brukstilfellet: semantisk poengsetting er best på å fange mening, men krever innleiringsmodeller, mens BM25 gir fart og effektivitet for leksikalsk matching. Avveiningen mellom fart og nøyaktighet er viktig—innleiringsbasert poengsetting gir overlegen forståelse av relevans, men gir ventetidskostnader, mens BM25 og TF-IDF er raskere, men mindre semantisk sofistikerte. Beregningkostnad inkluderer modellens inferenstid, minnebehov og behov for infrastrukturskalering, særlig viktig for produksjonssystemer med høyt volum. Parameterjustering innebærer å tilpasse terskler, vekter i hybride tilnærminger og re-rangeringsavskjæringer for å optimalisere ytelse for spesifikke domener og brukstilfeller. Kontinuerlig overvåking av poengytelse med målinger som NDCG og Precision@k hjelper med å oppdage forringelse over tid, muliggjør proaktive systemforbedringer og sikrer konsistent svarkvalitet i produksjons-RAG-systemer.
Avanserte poengteknikker
Avanserte teknikker for hentepoeng går utover enkel relevansvurdering for å fange komplekse kontekstuelle relasjoner. Omskriving av spørringer kan forbedre poeng ved å omformulere brukerspørringer til flere semantisk likevarende former, slik at henteren finner relevante dokumenter som ellers kunne blitt oversett ved bokstavelig spørringsmatching. Hypotetiske dokumentinnleiringer (HyDE) genererer syntetiske relevante dokumenter fra spørringer, og bruker disse hypotetiske til å forbedre hentepoeng ved å finne faktiske dokumenter som ligner det idealiserte relevante innholdet. Multispørrings-tilnærminger sender flere spørringsvarianter til henterne og aggregerer poengene, noe som gir bedre robusthet og dekning enn enkeltspørringshenting. Domenespesifikke poengmodeller trent på merkede data fra bestemte bransjer eller kunnskapsområder kan oppnå bedre ytelse enn generelle modeller, spesielt verdifullt for spesialiserte applikasjoner som medisinske eller juridiske AI-systemer. Kontekstuelle poengjusteringer tar hensyn til faktorer som dokumentets aktualitet, kildeautoritet og brukerkontekst, og muliggjør en mer avansert relevansevurdering som går utover ren semantisk likhet for å inkludere virkelige relevansfaktorer som er kritiske i produksjons-AI.
Vanlige spørsmål
Hva er forskjellen på hentepoeng og rangering?
Hentepoeng tildeler numeriske relevansverdier til dokumenter basert på deres forhold til en spørring, mens rangering ordner dokumenter ut fra disse poengene. Poeng er evalueringsprosessen, rangering er resultatet av sorteringen. Begge er essensielle for at RAG-systemer skal levere nøyaktige svar.
Hvorfor er hentepoeng viktig for RAG-systemer?
Hentepoeng avgjør hvilke kilder som når språkmodellen for svargenerering. Høy kvalitet på poeng sikrer at relevant informasjon velges, noe som reduserer hallusinasjoner og forbedrer svarnøyaktighet. Dårlig poeng gir irrelevant kontekst og upålitelige AI-svar.
Hvordan skiller semantisk og nøkkelordbasert poengsetting seg?
Semantisk poengsetting bruker innleiringer for å forstå konseptuell mening og fanger opp synonymer og relaterte begreper. Nøkkelordbasert poengsetting (som BM25) matcher eksakte ord og fraser. Semantisk poengsetting er bedre for å forstå hensikt, mens nøkkelordpoengsetting er best for å finne spesifikk informasjon.
Hvilke målinger bør jeg bruke for å evaluere hentepoeng?
Viktige målinger inkluderer Precision@k (nøyaktighet på toppresultater), Recall@k (dekning av relevante dokumenter), NDCG (rangeringens kvalitet), og MRR (posisjon for første relevante resultat). Velg målinger ut fra ditt brukstilfelle: Precision@k for kvalitet, Recall@k for fullstendighet.
Kan LLM-er brukes til å poengsette henteresultater?
Ja, LLM-basert poengsetting bruker språkmodeller som dommere for å vurdere relevans. Denne tilnærmingen fanger opp nyanserte semantiske relasjoner, men er beregningsmessig kostbar. Det er verdifullt for å evaluere RAG-kvalitet og lage treningsdata, men krever kalibrering med menneskelige etiketter.
Hvordan forbedrer re-rangering hentepoeng?
Re-rangering bruker en andre gjennomgang med mer sofistikerte modeller for å forbedre de første resultatene. Teknikker som Reciprocal Rank Fusion kombinerer flere hentemetoder og øker nøyaktighet og robusthet. Re-rangering overgår enkeltstadie-henting betydelig i komplekse domener.
Hva er den beregningsmessige kostnaden ved ulike poengmetoder?
BM25 og TF-IDF er raske og lette, egnet for sanntidssystemer. Semantisk poengsetting krever innleiringsmodell-inferens, som gir noe ventetid. LLM-basert poengsetting er dyrest. Velg ut fra dine ventetidskrav og tilgjengelige ressurser.
Hvordan velger jeg riktig poengmetode for mitt brukstilfelle?
Vurder dine prioriteringer: semantisk poengsetting for meningsfokuserte oppgaver, BM25 for fart og effektivitet, hybride tilnærminger for balansert ytelse. Evaluer på ditt domene med målinger som NDCG og Precision@k. Test flere metoder og mål effekten på sluttkvaliteten.
Overvåk AI-ens kildekvalitet med AmICited
Følg med på hvordan AI-systemer som ChatGPT, Perplexity og Google AI refererer til din merkevare og vurderer kvaliteten på deres kildehenting og rangering. Sørg for at innholdet ditt blir korrekt sitert og rangert av AI-systemer.
Lesbarhetspoengsum for AI-søk: Hvordan optimalisere innhold for AI-svar
Lær hva lesbarhetspoengsummer betyr for synlighet i AI-søk. Oppdag hvordan Flesch-Kincaid, setningsstruktur og innholdsformatering påvirker AI-siteringer i Chat...
Hvordan måle AI-søkeytelse: Viktige måleparametere og KPI-er
Lær hvordan du måler AI-søkeytelse på tvers av ChatGPT, Perplexity og Google AI Overviews. Oppdag nøkkelindikatorer, KPI-er og overvåkingsstrategier for å spore...
AI-synlighetspoeng: Hva det er og hvordan du forbedrer det
Lær hva AI-synlighetspoeng er, hvorfor det er viktig for merkevaren din, og oppdag velprøvde strategier for å forbedre synligheten din på tvers av ChatGPT, Gemi...
8 min lesing
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.