
Opphavsrettslige konsekvenser for AI-søkemotorer og generativ AI
Forstå opphavsrettslige utfordringer for AI-søkemotorer, begrensninger for rimelig bruk, nylige søksmål og juridiske konsekvenser for AI-genererte svar og innho...
8 min lesing
Tekniske og juridiske mekanismer som lar innholdsprodusenter og rettighetshavere forhindre at deres verk brukes i treningsdatasett for store språkmodeller. Disse inkluderer robots.txt-direktiver, juridiske reservasjonserklæringer og kontraktsmessige beskyttelser under reguleringer som EUs AI-forordning.
Tekniske og juridiske mekanismer som lar innholdsprodusenter og rettighetshavere forhindre at deres verk brukes i treningsdatasett for store språkmodeller. Disse inkluderer robots.txt-direktiver, juridiske reservasjonserklæringer og kontraktsmessige beskyttelser under reguleringer som EUs AI-forordning.
AI-treningsreservasjon viser til de tekniske og juridiske mekanismene som lar innholdsprodusenter, rettighetshavere og nettsideeier forhindre at deres verk brukes i treningsdatasett for store språkmodeller (LLM). Etter hvert som AI-selskaper henter inn store mengder data fra internett for å trene stadig mer avanserte modeller, har muligheten til å styre om innholdet ditt deltar i denne prosessen blitt essensiell for å beskytte immaterielle rettigheter og bevare kreativ kontroll. Disse reservasjonene skjer på to nivåer: tekniske direktiver som instruerer AI-crawlere om å hoppe over innholdet ditt, og juridiske rammeverk som etablerer kontraktsfestede rettigheter til å ekskludere verk fra treningsdatasett. Forståelse av begge dimensjoner er avgjørende for alle som er opptatt av hvordan innholdet deres brukes i AI-tidsalderen.

Den vanligste tekniske metoden for å reservere seg mot AI-trening er gjennom robots.txt-filen, en enkel tekstfil plassert i rotkatalogen på et nettsted som kommuniserer tillatelser til automatiserte roboter. Når en AI-crawler besøker nettstedet ditt, sjekker den først robots.txt for å se om den har tilgang til innholdet. Ved å legge til spesifikke disallow-direktiver for bestemte brukeragenter, kan du instruere AI-roboter om å hoppe over hele nettstedet. Hvert AI-selskap opererer med flere crawlere med forskjellige brukeragent-identifikatorer – dette er i praksis «navnene» som botene bruker for å identifisere seg når de gjør forespørsler. For eksempel identifiserer OpenAIs GPTBot seg med brukeragentstrengen “GPTBot”, mens Anthropics Claude bruker “ClaudeBot”. Syntaksen er enkel: du spesifiserer brukeragentens navn og deklarerer hvilke stier som er blokkert, som “Disallow: /” for å blokkere hele nettstedet.
| AI-selskap | Crawler-navn | Brukeragent-token | Formål |
|---|---|---|---|
| OpenAI | GPTBot | GPTBot | Innsamling av treningsdata til modeller |
| OpenAI | OAI-SearchBot | OAI-SearchBot | ChatGPT-søk indeksering |
| Anthropic | ClaudeBot | ClaudeBot | Henting av chat-sitater |
| Google-Extended | Google-Extended | Gemini AI treningsdata | |
| Perplexity | PerplexityBot | PerplexityBot | AI-søk indeksering |
| Meta | Meta-ExternalAgent | Meta-ExternalAgent | AI-modelltrening |
| Common Crawl | CCBot | CCBot | Åpent datasett for LLM-trening |
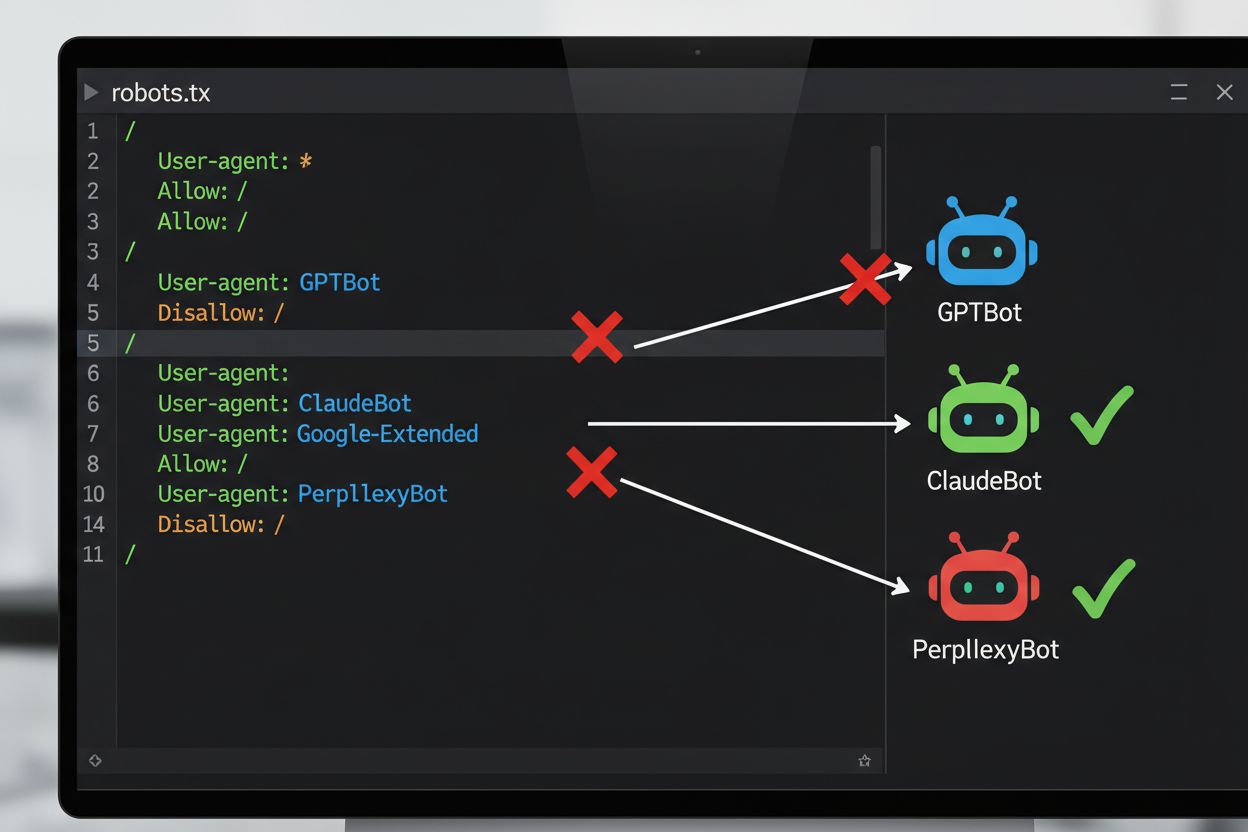
Det juridiske landskapet for AI-treningsreservasjon har utviklet seg betydelig med innføringen av EUs AI-forordning, som trådte i kraft i 2024 og inkorporerer bestemmelser fra tekstavdatautvinningsdirektivet (TDM). I henhold til disse reglene kan AI-utviklere kun bruke opphavsrettslig beskyttede verk til maskinlæringsformål dersom de har lovlig tilgang til innholdet og rettighetshaveren ikke eksplisitt har reservert retten til å ekskludere sitt verk fra tekstavdatautvinning. Dette skaper en formell juridisk mekanisme for reservasjon: rettighetshavere kan sende inn reservasjonserklæringer for sine verk, noe som effektivt hindrer bruk i AI-trening uten eksplisitt tillatelse. EUs AI-forordning markerer et betydelig skifte fra tidligere «move fast and break things»-tilnærming, ved å etablere at selskaper som trener AI-modeller må verifisere om rettighetshavere har reservert sitt innhold, og implementere tekniske og organisatoriske sikkerhetstiltak for å forhindre utilsiktet bruk av reserverte verk. Dette juridiske rammeverket gjelder i hele EU og påvirker hvordan globale AI-selskaper håndterer datainnsamling og treningspraksis.
Implementering av reservasjonsmekanismer innebærer både teknisk konfigurasjon og juridisk dokumentasjon. På den tekniske siden legger nettsideeieren inn disallow-direktiver i robots.txt-filen for spesifikke AI-brukeragenter, som kompatible crawlere vil respektere når de besøker siden. På den juridiske siden kan rettighetshavere sende inn reservasjonserklæringer til opphavsrettsorganisasjoner og forvaltningsselskaper – for eksempel har det nederlandske forvaltningsselskapet Pictoright og det franske musikkselskapet SACEM etablert formelle reservasjonsprosedyrer som lar skapere reservere sine rettigheter mot AI-treningsbruk. Mange nettsteder og innholdsprodusenter inkluderer nå eksplisitte reservasjonserklæringer i sine bruksvilkår eller metadata, hvor de erklærer at innholdet ikke skal brukes til AI-modelltrening. Effektiviteten av disse tiltakene avhenger imidlertid av at crawlerne etterlever direktivene: mens store selskaper som OpenAI, Google og Anthropic offentlig har uttalt at de respekterer robots.txt-direktiver og reservasjoner, betyr fraværet av en sentral håndhevingsmekanisme at det å fastslå hvorvidt en reservasjon faktisk er fulgt, krever kontinuerlig overvåking og verifisering.
Til tross for at reservasjonsmekanismer finnes, er det betydelige utfordringer som begrenser effektiviteten:
For organisasjoner som krever sterkere beskyttelse enn robots.txt alene gir, kan flere ekstra tekniske metoder benyttes. Brukeragentfiltrering på server- eller brannmurnivå kan blokkere forespørsler fra bestemte crawler-identifikatorer før de når applikasjonen, selv om dette fortsatt er sårbart for spoofing. IP-adresseblokkering kan rettes mot kjente IP-områder publisert av store AI-selskaper, selv om bestemte skrapere kan omgå dette via proxy-nettverk. Rate limiting og struping kan bremse skrapere ved å begrense antall forespørsler per sekund, slik at skraping ikke blir økonomisk levedyktig, selv om avanserte roboter kan fordele forespørsler over flere IP-er for å omgå dette. Autentiseringskrav og betalingsmurer gir sterk beskyttelse ved å begrense tilgangen til innloggede brukere eller betalende kunder, og hindrer dermed automatisk skraping. Enhetsfingerprinting og atferdsanalyse kan avsløre roboter ved å analysere mønstre som nettleser-API-er, TLS-håndtrykk og interaksjonsmønstre som skiller seg fra menneskelige brukere. Noen organisasjoner har til og med implementert honeypots og tarpits – skjulte lenker eller uendelige lenkemazinger som bare roboter følger – for å sløse bort crawler-ressurser og potensielt forurense treningsdatasett med søppeldata.
Spenningsforholdet mellom AI-selskaper og innholdsprodusenter har ført til flere høyprofilerte konfrontasjoner som illustrerer praktiske utfordringer ved reservasjonsoppfølging. Reddit tok i 2023 i bruk aggressive tiltak ved å øke API-prisene dramatisk for å kreve betaling fra AI-selskaper for data, noe som effektivt priset ut uautoriserte skrapere og tvang selskaper som OpenAI og Anthropic til å forhandle om lisensavtaler. Twitter/X innførte enda strengere tiltak, blant annet midlertidig blokkering av all ikke-autentisert tilgang til tweets og begrensning av hvor mange tweets innloggede brukere kunne lese, eksplisitt for å ramme dataskrapere. Stack Overflow blokkerte opprinnelig OpenAIs GPTBot i sin robots.txt, med henvisning til lisensbekymringer rundt brukergenerert kode, men fjernet senere blokkeringen – muligens etter forhandlinger med OpenAI. Nyhetsmedieorganisasjoner svarte samlet: over 50 % av store nyhetssider blokkerte AI-crawlere innen 2023, med aktører som The New York Times, CNN, Reuters og The Guardian som la GPTBot til på sine disallow-lister. Noen nyhetsorganisasjoner tok i stedet rettslige skritt, blant annet The New York Times som saksøkte OpenAI for opphavsrettsbrudd, mens andre som Associated Press forhandlet frem lisensavtaler for å tjene penger på sitt innhold. Disse eksemplene viser at selv om reservasjonsmekanismer finnes, avhenger effektiviteten av både teknisk implementering og vilje til å gå til rettslige skritt når overtredelser skjer.
Å implementere reservasjonsmekanismer er bare halve jobben; å verifisere at de faktisk fungerer krever kontinuerlig overvåking og testing. Flere verktøy kan hjelpe deg å validere konfigurasjonen: Google Search Console har en robots.txt-tester spesielt for Googlebot, mens Merkles Robots.txt Tester og TechnicalSEO.coms verktøy tester individuell crawler-adferd mot bestemte brukeragenter. For mer omfattende overvåking av om AI-selskaper faktisk respekterer reservasjonene dine, tilbyr plattformer som AmICited.com spesialisert overvåking som sporer hvordan AI-systemer refererer til merkevaren og innholdet ditt på tvers av GPT-er, Perplexity, Google AI Overviews og andre AI-plattformer. Denne typen overvåking er særlig nyttig fordi du ikke bare ser om crawlere besøker nettstedet ditt, men også om innholdet faktisk dukker opp i AI-genererte svar – noe som indikerer om reservasjonen har effekt i praksis. Regelmessig analyse av serverlogger kan også avdekke hvilke crawlere som forsøker å få tilgang til nettstedet ditt og om de respekterer robots.txt-direktivene, men dette krever teknisk kompetanse å tolke korrekt.
For å effektivt beskytte innholdet ditt mot uautorisert AI-treningsbruk, bør du benytte en lagvis tilnærming som kombinerer tekniske og juridiske tiltak. Først, implementer robots.txt-direktiver for alle store AI-treningscrawlere (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot og andre) – dette gir et grunnleggende forsvar mot kompatible selskaper. Dernest, legg til eksplisitte reservasjonserklæringer i nettsidens bruksvilkår og metadata, der du tydelig erklærer at innholdet ikke skal brukes til AI-modelltrening – dette styrker din juridiske posisjon ved overtredelser. For det tredje, overvåk konfigurasjonen regelmessig med testverktøy og serverlogger for å verifisere at crawlere respekterer direktivene, og oppdater robots.txt kvartalsvis ettersom nye AI-crawlere stadig dukker opp. For det fjerde, vurder ytterligere tekniske tiltak som brukeragentfiltrering eller rate limiting dersom du har tekniske ressurser – dette gir trinnvis beskyttelse mot mer avanserte skrapere. Til slutt, dokumenter reservasjonstiltakene dine grundig, da denne dokumentasjonen blir avgjørende hvis du må gå til rettslige skritt mot selskaper som ignorerer direktivene dine. Husk at reservasjon ikke er en engangskonfigurasjon, men en kontinuerlig prosess som krever årvåkenhet og tilpasning etter hvert som AI-landskapet utvikler seg.
robots.txt er en teknisk, frivillig standard som instruerer crawlere om å hoppe over innholdet ditt, mens juridisk reservasjon innebærer å sende inn formelle reservasjoner til opphavsrettsorganisasjoner eller inkludere kontraktsklausuler i dine bruksvilkår. robots.txt er enklere å implementere, men mangler håndhevelse, mens juridisk reservasjon gir sterkere juridisk beskyttelse, men krever mer formelle prosedyrer.
Store AI-selskaper som OpenAI, Google, Anthropic og Perplexity har offentlig uttalt at de respekterer robots.txt-direktiver. Imidlertid er robots.txt en frivillig standard uten håndhevingsmekanisme, så ikke-kompatible crawlere og useriøse skrapere kan ignorere direktivene dine fullstendig.
Nei. Blokkering av AI-treningscrawlere som GPTBot og ClaudeBot vil ikke påvirke dine Google- eller Bing-søkerangeringer fordi tradisjonelle søkemotorer bruker andre crawlere (Googlebot, Bingbot) som opererer uavhengig. Blokker kun disse hvis du ønsker å forsvinne helt fra søkeresultatene.
EUs AI-forordning krever at AI-utviklere har lovlig tilgang til innhold og må respektere rettighetshaveres reservasjoner. Rettighetshavere kan sende inn reservasjonserklæringer for sine verk, noe som effektivt forhindrer bruk i AI-trening uten eksplisitt tillatelse. Dette skaper en formell juridisk mekanisme for å beskytte innhold mot uautorisert treningsbruk.
Det avhenger av den spesifikke mekanismen. Blokkering av alle AI-crawlere vil forhindre at innholdet ditt vises i AI-søkeresultater, men dette fjerner deg også helt fra AI-drevne søkeplattformer. Noen utgivere foretrekker selektiv blokkering – å tillate søkefokuserte crawlere, men blokkere treningsfokuserte, for å opprettholde synlighet i AI-søk samtidig som innholdet beskyttes mot modelltrening.
Hvis et AI-selskap ignorerer dine reservasjoner, har du juridiske muligheter gjennom opphavsrettskrav eller kontraktsbrudd, avhengig av jurisdiksjon og omstendigheter. Juridiske skritt er imidlertid kostbare og tidkrevende, med usikre utfall. Derfor er overvåking og dokumentasjon av reservasjonstiltakene dine avgjørende.
Gå gjennom og oppdater robots.txt-konfigurasjonen minst kvartalsvis. Nye AI-crawlere dukker stadig opp, og selskaper introduserer ofte nye brukeragenter. For eksempel slo Anthropic sammen sine 'anthropic-ai'- og 'Claude-Web'-roboter til 'ClaudeBot', noe som ga den nye boten midlertidig ubegrenset tilgang til nettsteder som ikke hadde oppdatert reglene sine.
Reservasjon er effektivt mot seriøse, kompatible AI-selskaper som respekterer robots.txt og juridiske rammeverk. Det er imidlertid mindre effektivt mot useriøse crawlere og ikke-kompatible skrapere som opererer i juridiske gråsoner. robots.txt stopper omtrent 40–60 % av AI-boter, og derfor anbefales en lagvis tilnærming med flere tekniske og juridiske tiltak.
Spor om innholdet ditt dukker opp i AI-genererte svar på ChatGPT, Perplexity, Google AI Overviews og andre AI-plattformer med AmICited.
Forstå opphavsrettslige utfordringer for AI-søkemotorer, begrensninger for rimelig bruk, nylige søksmål og juridiske konsekvenser for AI-genererte svar og innho...

Utforsk det komplekse juridiske landskapet rundt eierskap til AI-treningsdata. Lær hvem som kontrollerer innholdet ditt, opphavsrettslige implikasjoner og hvilk...
Fullstendig guide til hvordan du reserverer deg mot innsamling av AI-treningsdata på tvers av ChatGPT, Perplexity, LinkedIn og andre plattformer. Lær trinn-for-...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.