
PerplexityBot: Hva Alle Nettstedeiere Bør Vite
Fullstendig guide til PerplexityBot crawler – forstå hvordan den fungerer, styr tilgang, overvåk siteringer og optimaliser for synlighet i Perplexity AI. Lær om...
8 min lesing

Amazons nettrobot (web crawler) brukes til å forbedre produkter og tjenester, inkludert Alexa, Rufus shoppingassistent og Amazons AI-drevne søkefunksjoner. Den respekterer Robots Exclusion Protocol og kan styres via robots.txt-direktiver. Kan benyttes til AI-modelltrening.
Amazons nettrobot (web crawler) brukes til å forbedre produkter og tjenester, inkludert Alexa, Rufus shoppingassistent og Amazons AI-drevne søkefunksjoner. Den respekterer Robots Exclusion Protocol og kan styres via robots.txt-direktiver. Kan benyttes til AI-modelltrening.
Amazonbot er Amazons offisielle nettrobot (web crawler) utviklet for å forbedre selskapets produkter og tjenester ved å samle inn og analysere nettinnhold. Denne avanserte crawleren driver sentrale Amazon-funksjoner, inkludert Alexa stemmeassistent, Rufus AI-shoppingassistent og Amazons AI-drevne søkeopplevelser. Amazonbot opererer med brukeragent-strengen Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36, som identifiserer den for webservere. Dataene som samles inn av Amazonbot kan brukes til å trene Amazons kunstig intelligens-modeller, og gjør den til en viktig del av Amazons bredere AI-infrastruktur og produktutviklingsstrategi.
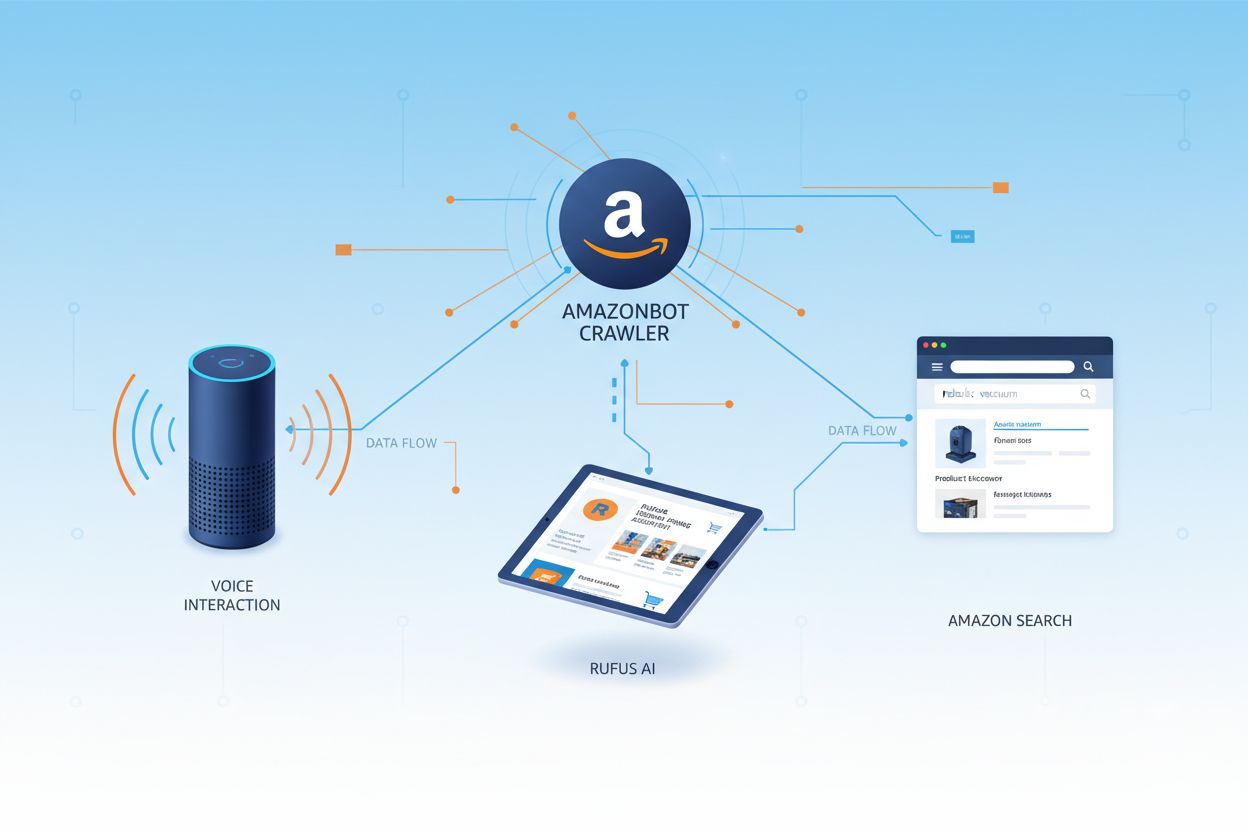
Amazon har tre ulike nettcrawlere, som hver fyller sine egne roller i økosystemet. Amazonbot er hovedcrawleren og brukes til generell forbedring av produkter og tjenester, og kan også brukes til AI-modelltrening. Amzn-SearchBot er spesialdesignet for å forbedre søkeopplevelser i Amazon-produkter som Alexa og Rufus, men den crawler IKKE innhold for generativ AI-modelltrening. Amzn-User støtter brukerinitierte handlinger, for eksempel å hente direkte informasjon når kunder spør Alexa om ting som krever oppdatert nettdata, og den crawler heller ikke for AI-trening. Alle tre crawlerne respekterer Robots Exclusion Protocol og følger robots.txt-direktiver, slik at nettsideeierne kan kontrollere tilgangen. Amazon publiserer IP-adressene for hver crawler på sitt utviklerportal, slik at nettsideeierne kan verifisere legitim trafikk. I tillegg respekterer alle Amazon-crawlere lenkenivå-direktivet rel=nofollow og robots meta-tagger på sidenivå, inkludert noarchive (hindrer bruk til modelltrening), noindex (hindrer indeksering) og none (hindrer begge deler).
| Navn på crawler | Primærformål | AI-modelltrening | User Agent | Viktigste bruksområder |
|---|---|---|---|---|
| Amazonbot | Generell produkt-/tjenesteforbedring | Ja | Amazonbot/0.1 | Overordnet forbedring av Amazon-tjenester, AI-trening |
| Amzn-SearchBot | Forbedring av søkeopplevelser | Nei | Amzn-SearchBot/0.1 | Alexa-søk, indeksering for Rufus shoppingassistent |
| Amzn-User | Brukerinitiert henting av sanntidsdata | Nei | Amzn-User/0.1 | Sanntidsspørsmål fra Alexa, forespørsler om oppdatert informasjon |
Amazon respekterer bransjestandarden Robots Exclusion Protocol (RFC 9309), noe som betyr at nettsideeieren kan kontrollere tilgang for Amazonbot via robots.txt-filen. Amazon henter robots.txt-filer fra roten av domenet ditt (f.eks. example.com/robots.txt) og bruker en hurtigbufret kopi fra de siste 30 dagene hvis filen ikke kan hentes. Endringer i robots.txt-filen din tar vanligvis omtrent 24 timer før de reflekteres i Amazons systemer. Protokollen støtter standard direktiver for user-agent og allow/disallow, slik at du kan styre presist hvilke crawlere som kan besøke bestemte kataloger eller filer. Det er imidlertid viktig å merke seg at Amazons crawlere IKKE støtter crawl-delay-direktivet, så denne parameteren blir ignorert hvis den inkluderes.
Her er et eksempel på hvordan du styrer tilgang for Amazonbot:
# Blokker Amazonbot fra å crawle hele nettstedet ditt
User-agent: Amazonbot
Disallow: /
# Tillat Amzn-SearchBot for søkesynlighet
User-agent: Amzn-SearchBot
Allow: /
# Blokker en spesifikk katalog for Amazonbot
User-agent: Amazonbot
Disallow: /private/
# Tillat alle andre crawlere
User-agent: *
Disallow: /admin/
Nettsideeierne som er opptatt av bot-trafikk, bør verifisere at crawlere som utgir seg for å være Amazonbot faktisk er legitime Amazon-crawlere. Amazon tilbyr en verifiseringsprosess ved hjelp av DNS-oppslag for å bekrefte ekte Amazonbot-trafikk. For å verifisere legitimiteten til en crawler, finn først IP-adressen som har tilgang i serverloggen, og utfør et omvendt DNS-oppslag på denne IP-adressen med host-kommandoen. Domenenavnet som returneres skal være et subdomene av crawl.amazonbot.amazon. Utfør deretter et forover DNS-oppslag på det returnerte domenenavnet for å bekrefte at det peker tilbake til den opprinnelige IP-adressen. Denne toveis verifiseringsprosessen hjelper med å hindre spoofing-angrep, ettersom ondsinnede aktører potensielt kan sette opp falske reverse DNS-oppslag for å utgi seg for Amazonbot. Amazon publiserer verifiserte IP-adresser for alle sine crawlere på utviklerportalen på developer.amazon.com/amazonbot/ip-addresses/, som gir et ekstra referansepunkt for verifisering.
Eksempel på verifiseringsprosess:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
Hvis du har spørsmål om Amazonbot eller ønsker å rapportere mistenkelig aktivitet, kontakt Amazon direkte på amazonbot@amazon.com og inkluder relevante domener i meldingen.
Det er et viktig skille mellom Amazons crawlere når det gjelder AI-modelltrening. Amazonbot kan brukes til å trene Amazons kunstig intelligens-modeller, noe som er relevant for innholdsskapere som er opptatt av at innholdet deres brukes til AI-trening. Til sammenligning crawler ikke Amzn-SearchBot og Amzn-User innhold for generativ AI-modelltrening, men fokuserer kun på å forbedre søkeopplevelser og støtte brukerforespørsler. Hvis du vil forhindre at innholdet ditt blir brukt til AI-modelltrening, kan du bruke robots meta-taggen noarchive i HTML-headeren på siden din, som instruerer Amazonbot om ikke å bruke siden til modelltrening. Dette skillet er viktig for utgivere, innholdsskapere og nettsideeierne som ønsker å ha kontroll over hvordan innholdet deres brukes i AI-treningsprosessen, samtidig som de kan la innholdet vises i Amazons søkeresultater og Rufus-anbefalinger.
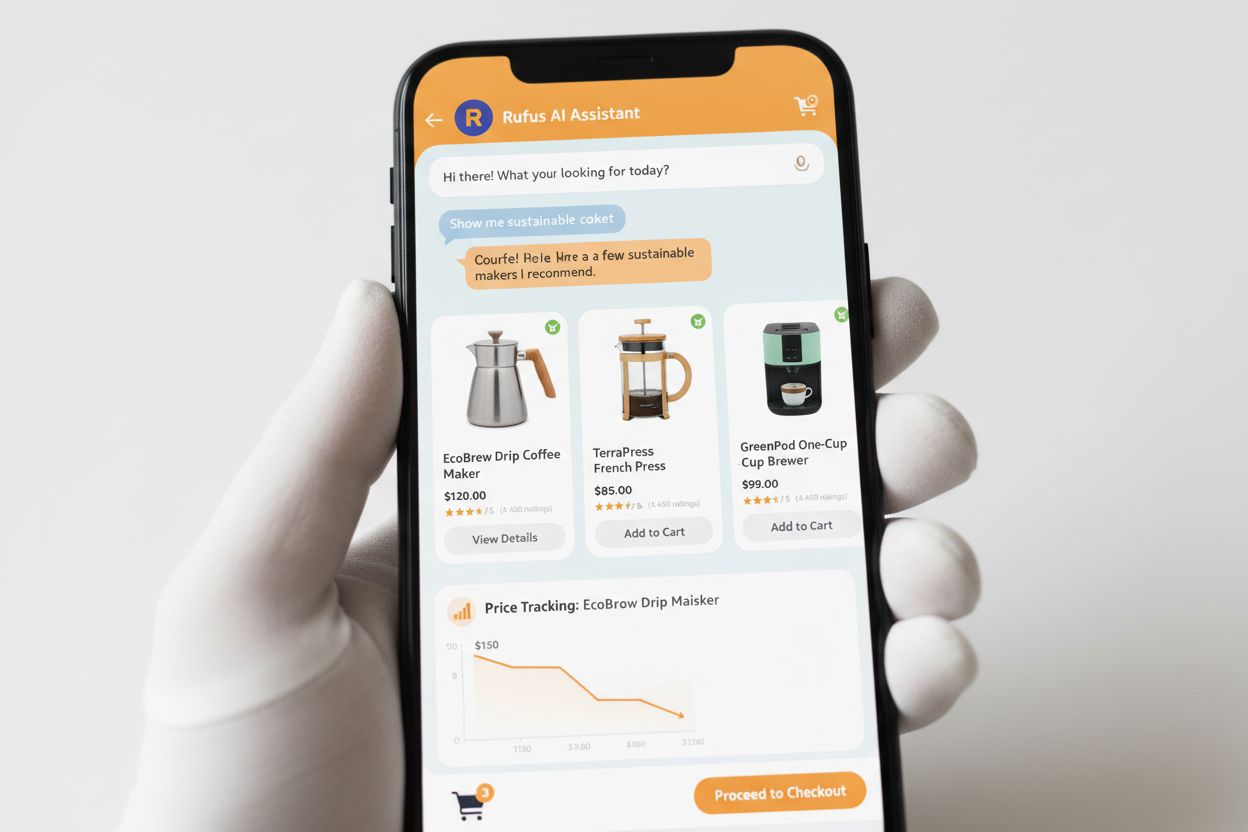
Rufus er Amazons avanserte AI-shoppingassistent som benytter nett-crawling og AI-teknologi for å gi personlig tilpassede shoppinganbefalinger og assistanse. Selv om Amazonbot bidrar til Amazons overordnede AI-infrastruktur, bruker Rufus spesifikt Amzn-SearchBot for å indeksere produktinformasjon og nettinnhold relevant for shoppingforespørsler. Rufus er bygget på Amazon Bedrock og benytter avanserte store språkmodeller, inkludert Anthropic’s Claude Sonnet og Amazon Nova, kombinert med en spesialtilpasset modell trent på Amazons omfattende produktkatalog, kundeanmeldelser, Q&A fra fellesskapet og nettinformasjon. Shoppingassistenten hjelper kundene med å undersøke produkter, sammenligne alternativer, følge med på priser, finne tilbud og til og med automatisk kjøpe varer når de når målsatte priser. Siden lanseringen har Rufus blitt svært populær, med over 250 millioner brukere, månedlige aktive brukere opp 149 %, og interaksjoner opp 210 % fra året før. Kunder som bruker Rufus under shopping er over 60 % mer tilbøyelige til å fullføre et kjøp i løpet av samme handleøkt, noe som viser den betydelige effekten AI-drevet shoppingassistanse har på forbrukeradferd.
Nettsideeierne bør utvikle en strategi for å håndtere Amazons crawlere basert på egne forretningsmål og innholdspolicyer:
noarchive eller blokker den helt via robots.txtamazonbot@amazon.com med domenet ditt for personlig veiledning om du har spesifikke spørsmål eller bekymringer rundt hvordan Amazon-crawlere samhandler med siden dinAmazonbot er Amazons generelle crawler brukt til å forbedre produkter og tjenester, og kan benyttes til AI-modelltrening. Amzn-SearchBot er spesiallaget for søkeopplevelser i Alexa og Rufus, og den crawler IKKE for AI-modelltrening. Ønsker du å forhindre bruk til AI-trening, blokker Amazonbot, men tillat Amzn-SearchBot for søkesynlighet.
Legg til følgende linjer i robots.txt-filen din i rotmappen på domenet: User-agent: Amazonbot etterfulgt av Disallow: /. Dette vil forhindre at Amazonbot crawler hele nettstedet ditt. Du kan også bruke Disallow: /spesifikk-mappe/ for å blokkere kun enkelte kataloger.
Ja, Amazonbot kan brukes til å trene Amazons kunstig intelligens-modeller. Hvis du ønsker å forhindre dette, bruk robots meta-taggen i nettsidens HTML-header. Dette instruerer Amazonbot om ikke å bruke siden til modelltrening.
Utfør et omvendt DNS-oppslag på crawlerens IP-adresse og verifiser at domenet er et subdomene av crawl.amazonbot.amazon. Utfør deretter et fremover DNS-oppslag for å bekrefte at domenet peker tilbake til den opprinnelige IP-en. Du kan også sjekke Amazons publiserte IP-adresser på developer.amazon.com/amazonbot/ip-addresses/.
Bruk standard robots.txt-syntaks: User-agent: Amazonbot for å målrette crawleren, etterfulgt av Disallow: / for å blokkere all tilgang, eller Disallow: /sti/ for å blokkere spesifikke kataloger. Du kan også bruke Allow: / for å eksplisitt tillate tilgang.
Amazon reflekterer vanligvis robots.txt-endringer innen omtrent 24 timer. Amazon henter robots.txt-filen din jevnlig og beholder en hurtigbufret kopi i opptil 30 dager, så det kan ta opptil et døgn før endringene sprer seg i systemene deres.
Ja, absolutt. Du kan lage egne regler for hver crawler i robots.txt-filen din. For eksempel, tillat Amzn-SearchBot med User-agent: Amzn-SearchBot og Allow: /, mens du blokkerer Amazonbot med User-agent: Amazonbot og Disallow: /.
Kontakt Amazon direkte på amazonbot@amazon.com. Husk å oppgi domenenavnet ditt og eventuelle relevante detaljer i meldingen. Amazons supportteam kan gi personlig veiledning tilpasset din situasjon.
Følg omtaler av merkevaren din på tvers av AI-systemer som Alexa, Rufus og Google AI Overviews med AmICited – den ledende plattformen for overvåking av AI-svar.
Fullstendig guide til PerplexityBot crawler – forstå hvordan den fungerer, styr tilgang, overvåk siteringer og optimaliser for synlighet i Perplexity AI. Lær om...

Forstå hvordan AI-søkeboter som GPTBot og ClaudeBot fungerer, hvordan de skiller seg fra tradisjonelle søkeboter, og hvordan du optimaliserer nettstedet ditt fo...

Lær hva CCBot er, hvordan den fungerer, og hvordan du blokkerer den. Forstå dens rolle i AI-trening, overvåkingsverktøy og beste praksis for å beskytte innholde...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.