
Hva er Burstiness i AI-innhold og Hvordan Påvirker Det Deteksjon
Lær hva burstiness betyr i AI-generert innhold, hvordan det skiller seg fra menneskelig skrive-mønster, og hvorfor det er viktig for AI-deteksjon og innholdsaut...
8 min lesing
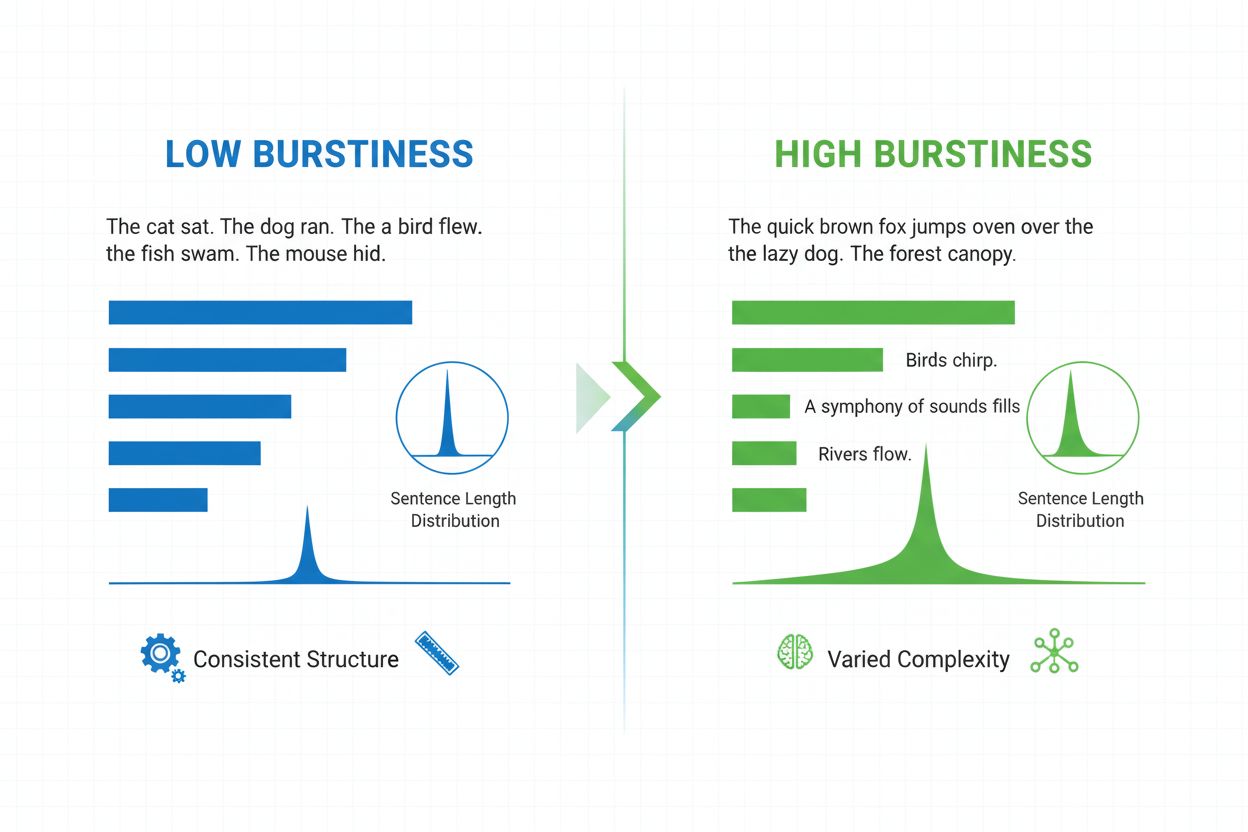
Burstiness er et lingvistisk mål som måler variasjonen i setningslengde, struktur og kompleksitet gjennom et dokument. Det kvantifiserer hvor mye en forfatter veksler mellom korte, konsise setninger og lengre, mer komplekse, og fungerer som en nøkkelindikator i AI-generert innholdsdeteksjon og språkanalyse.
Burstiness er et lingvistisk mål som måler variasjonen i setningslengde, struktur og kompleksitet gjennom et dokument. Det kvantifiserer hvor mye en forfatter veksler mellom korte, konsise setninger og lengre, mer komplekse, og fungerer som en nøkkelindikator i AI-generert innholdsdeteksjon og språkanalyse.
Burstiness er et målbar lingvistisk mål som måler variasjon og svingning i setningslengde, struktur og kompleksitet gjennom et skriftlig dokument eller tekstutdrag. Begrepet stammer fra konseptet om “utbrudd” av ulike setningsmønstre—veksling mellom korte, konsise setninger og lengre, mer intrikate. I sammenheng med naturlig språkprosessering og AI-innholdsdeteksjon fungerer burstiness som en sentral indikator på om teksten er skrevet av et menneske eller generert av et kunstig intelligenssystem. Menneskelige forfattere produserer naturlig tekst med høy burstiness fordi de instinktivt varierer setningsoppbyggingen basert på vektlegging, tempo og stilistisk hensikt. Omvendt har AI-generert tekst vanligvis lav burstiness fordi språkmodeller trenes på statistiske mønstre som favoriserer konsistens og forutsigbarhet. Å forstå burstiness er essensielt for innholdsprodusenter, undervisere, forskere og organisasjoner som overvåker AI-generert innhold på plattformer som ChatGPT, Perplexity, Google AI Overviews og Claude.
Konseptet burstiness oppstod fra forskning innen datalingvistikk og informasjonsteori, hvor forskere ønsket å kvantifisere de statistiske egenskapene ved naturlig språk. Tidlig arbeid innen stilometri—statistisk analyse av skrivestil—avdekket at menneskelig skriving har karakteristiske variasjonsmønstre som fundamentalt skiller seg fra maskinskrevet tekst. Etter hvert som store språkmodeller (LLM-er) ble mer sofistikerte tidlig på 2020-tallet, innså forskere at burstiness, kombinert med perpleksitet (et mål på ordforutsigbarhet), kunne tjene som en pålitelig indikator på AI-generert innhold. Ifølge forskning fra QuillBot og akademiske institusjoner bruker omtrent 78 % av virksomheter nå AI-drevne innholdsovervåkningsverktøy som har burstiness-analyse som del av sine deteksjonsalgoritmer. Stanford Universitys 2023-studie på TOEFL-oppgaver viste at burstiness-baserte deteksjonsmetoder, selv om de er nyttige, har betydelige begrensninger—spesielt når det gjelder falske positive for ikke-engelsktalende skriving. Denne forskningen har drevet utviklingen av mer sofistikerte, flerlags AI-deteksjonssystemer som vurderer burstiness sammen med andre språklige markører, semantisk sammenheng og kontekstuell hensiktsmessighet.
Burstiness beregnes ved å analysere den statistiske fordelingen av setningslengder og strukturelle mønstre i en tekst. Målingen kvantifiserer varians—altså hvor mye individuelle setninger avviker fra gjennomsnittlig setningslengde i et dokument. Et dokument med høy burstiness inneholder setninger som varierer betydelig i lengde; for eksempel kan en forfatter følge en tre-ords setning (“Ser du?”) med en tjuefem ord lang setning med flere ledd og underordnede fraser. Omvendt indikerer lav burstiness at de fleste setninger samler seg rundt en lignende lengde, typisk mellom tolv og atten ord, noe som skaper en monoton rytme. Beregningen involverer flere steg: først måles lengden på hver setning i ord; deretter beregnes gjennomsnittlig setningslengde; til slutt beregnes standardavviket for å se hvor mye individuelle setninger avviker fra snittet. Høyere standardavvik indikerer større variasjon og dermed høyere burstiness. Moderne AI-detektorer som Winston AI og Pangram bruker avanserte algoritmer som ikke bare teller ord, men også analyserer syntaktisk kompleksitet—den strukturelle oppbyggingen av leddsetninger, fraser og grammatiske elementer. Denne dypere analysen viser at mennesker bruker ulike setningsstrukturer (enkle, sammensatte, komplekse og sammensatt-komplekse setninger) i uforutsigbare mønstre, mens AI-modeller har en tendens til å foretrekke bestemte strukturelle maler som er vanlige i treningsdataene.
| Mål | Burstiness | Perpleksitet | Målingsfokus |
|---|---|---|---|
| Definisjon | Variasjon i setningslengde og struktur | Forutsigbarhet av enkeltord | Setningsnivå vs. ordnivå |
| Menneskelig skriving | Høy (varierte strukturer) | Høy (uforutsigbare ord) | Naturlig rytme og ordforråd |
| AI-generert tekst | Lav (ensartede strukturer) | Lav (forutsigbare ord) | Statistisk konsistens |
| Anvendelse i deteksjon | Avdekker strukturell monotoni | Avdekker ordvalgsmønstre | Utfyllende deteksjonsmetoder |
| Falsk positiv-risiko | Høyere for ESL-forfattere | Høyere for teknisk/akademisk skriving | Begge har begrensninger |
| Beregning | Standardavvik i setningslengder | Sannsynlighetsfordelingsanalyse | Ulike matematiske tilnærminger |
| Pålitelighet alene | Ikke tilstrekkelig for sikker deteksjon | Ikke tilstrekkelig for sikker deteksjon | Mest effektiv i kombinasjon |
Store språkmodeller som ChatGPT, Claude og Google Gemini trenes gjennom en prosess kalt neste-token-forutsigelse, hvor modellen lærer å forutsi det mest sannsynlige ordet som bør følge en gitt sekvens. Under treningen optimaliseres disse modellene eksplisitt for å minimere perpleksitet på treningsdatasettene, noe som utilsiktet gir lav burstiness som et biprodukt. Når en modell møter en bestemt setningsstruktur gjentatte ganger i treningsdataene, lærer den å reprodusere denne strukturen med høy sannsynlighet, noe som gir konsistente, forutsigbare setningslengder. Forskning fra Netus AI og Winston AI viser at AI-modeller har et karakteristisk stilometrisk fingeravtrykk preget av ensartet setningsoppbygging, overbruk av overgangsord (som “Videre”, “Derfor”, “I tillegg”) og en preferanse for passiv stemme over aktiv. Modellenes avhengighet av sannsynlighetsfordelinger gjør at de trekkes mot de mest vanlige mønstrene i treningsdataene i stedet for å utforske hele spekteret av mulige setningskonstruksjoner. Dette gir en paradoksal situasjon: jo mer data en modell trenes på, desto mer lærer den å reprodusere vanlige mønstre, og jo lavere blir burstiness. I tillegg mangler AI-modeller spontanitet og emosjonell variasjon som kjennetegner menneskelig skriving—de skriver ikke annerledes når de er entusiastiske, frustrerte eller ønsker å understreke et poeng. I stedet opprettholder de en konsistent stilistisk grunnlinje som reflekterer det statistiske sentrum av treningsfordelingen.
AI-deteksjonsplattformer har inkorporert burstiness-analyse som en kjernekomponent i sine deteksjonsalgoritmer, dog med varierende grad av sofistikasjon. Tidlige deteksjonssystemer var sterkt avhengige av burstiness og perpleksitet som primære mål, men forskning har avdekket betydelige begrensninger med denne tilnærmingen. Ifølge Pangram Labs gir perpleksitet- og burstiness-baserte detektorer falske positive når man analyserer tekst fra treningsdataene til språkmodeller—spesielt blir Uavhengighetserklæringen ofte flagget som AI-generert fordi den forekommer så ofte i treningsdataene at modellen gir den gjennomgående lav perpleksitet. Moderne deteksjonssystemer som Winston AI og Pangram bruker nå hybridtilnærminger som kombinerer burstiness-analyse med dype læringsmodeller trent på varierte menneske- og AI-genererte tekstprøver. Disse systemene analyserer flere språklige dimensjoner samtidig: variasjon i setningsstruktur, leksikalsk mangfold (ordforrådsrikdom), tegnsettingsmønstre, kontekstuell sammenheng og semantisk samsvar. Integreringen av burstiness i bredere deteksjonsrammeverk har forbedret nøyaktigheten betydelig—Winston AI rapporterer 99,98 % nøyaktighet i å skille AI-generert fra menneskeskrevet innhold ved å analysere flere markører fremfor å kun stole på burstiness. Likevel er målet verdifullt som én komponent i en helhetlig deteksjonsstrategi, spesielt i kombinasjon med analyse av perpleksitet, stilometriske mønstre og semantisk konsistens.
Forholdet mellom burstiness og lesbarhet er godt dokumentert i lingvistisk forskning. Flesch Reading Ease og Flesch-Kincaid Grade Level-skårene, som måler tekstens tilgjengelighet, har sterk sammenheng med burstiness-mønstre. Tekst med høyere burstiness oppnår ofte bedre lesbarhet fordi variert setningslengde forhindrer kognitiv tretthet og opprettholder leserens oppmerksomhet. Når lesere møter en jevn rytme av setninger med lik lengde, tilpasser hjernen seg et forutsigbart mønster, noe som kan føre til manglende engasjement og redusert forståelse. Omvendt skaper høy burstiness en bølgeeffekt som holder leseren mentalt engasjert ved å variere den kognitive belastningen—korte setninger gir rask, lettfordøyelig informasjon, mens lengre gir rom for komplekse ideer og nyanser. Forskning fra Metrics Masters viser at høy burstiness gir omtrent 15–20 % bedre hukommelsesretensjon sammenlignet med tekst med lav burstiness, da den varierte rytmen hjelper informasjonen å feste seg i langtidsminnet. Dette prinsippet gjelder for alle innholdstyper: blogginnlegg, akademiske artikler, markedsføringstekster og teknisk dokumentasjon drar alle nytte av strategisk burstiness. Forholdet er imidlertid ikke lineært—overdreven burstiness som prioriterer variasjon fremfor klarhet kan gjøre teksten hakkete og vanskelig å følge. Den optimale tilnærmingen er målrettet variasjon hvor setningsvalg støtter innholdets mening og forfatterens kommunikative hensikt, ikke bare for å øke en måleverdi.
Til tross for utstrakt bruk i AI-deteksjonssystemer har burstiness-basert deteksjon betydelige begrensninger som forskere og brukere må kjenne til. Pangram Labs har publisert omfattende forskning som viser fem hovedutfordringer: for det første blir tekst fra AI-treningsdata feilaktig klassifisert som AI-generert fordi modeller er optimalisert for å minimere perpleksitet på treningsdata; for det andre er burstiness-verdier relative til spesifikke språkmodeller, så ulike modeller gir ulike perpleksitetsprofiler; for det tredje eksponerer ikke kommersielle lukkede modeller som ChatGPT token-sannsynligheter, noe som gjør perpleksitetsberegning umulig; for det fjerde blir ikke-engelsktalende uforholdsmessig ofte flagget som AI-generert på grunn av deres mer ensartede setningsstruktur; og for det femte kan ikke burstiness-baserte detektorer selvforbedres iterativt med mer data. Stanford 2023-studien på TOEFL-oppgaver fant at omtrent 26 % av ikke-engelskspråklige tekster feilaktig ble flagget som AI-generert av perpleksitet- og burstiness-baserte detektorer, sammenlignet med kun 2 % falske positive for morsmålstalende. Denne skjevheten reiser alvorlige etiske spørsmål i utdanningssammenheng der AI-deteksjon brukes til vurdering. I tillegg har malbasert innhold i markedsføring, akademisk skriving og teknisk dokumentasjon naturlig lav burstiness på grunn av stilkrav og strukturelle konvensjoner, noe som gir falske positive i disse sjangrene. Disse begrensningene har ført til utviklingen av mer sofistikerte deteksjonsmetoder som ser på burstiness som ett signal blant flere, ikke som en endelig indikator på AI-generering.
Burstiness-mønstre varierer betydelig mellom ulike sjangre og kontekster, og reflekterer de ulike kommunikative formål og publikumsforventninger i hvert domene. Akademisk skriving, spesielt innen STEM-fag, har gjerne lavere burstiness fordi forfattere følger strenge stilkrav og bruker konsistente strukturelle maler for klarhet og presisjon. Juridiske dokumenter, tekniske spesifikasjoner og vitenskapelige artikler prioriterer konsistens og forutsigbarhet fremfor stilistisk variasjon, noe som gir naturlig lave burstiness-verdier. Derimot har kreativ skriving, journalistikk og markedsføringstekst ofte høy burstiness fordi disse sjangrene prioriterer engasjement og emosjonell effekt gjennom variert tempo og rytme. Skjønnlitteratur bruker spesielt dramatiske skift i setningslengde for å skape vekt, bygge spenning og styre fortellerflyt. Forretningskommunikasjon ligger midt imellom—profesjonelle e-poster og rapporter opprettholder moderat burstiness for å balansere klarhet og engasjement. Flesch-Kincaid Grade Level-målet viser at akademisk tekst for høyt utdannede ofte har lengre, mer komplekse setninger, noe som kan redusere burstiness; men variasjon i leddsetningsstruktur og underordning gir fortsatt meningsfull burstiness. Å forstå disse kontekstuelle variasjonene er avgjørende for AI-deteksjonssystemer, som må ta hensyn til sjangerspesifikke skriveregler for å unngå falske positive. En teknisk manual med jevnt lange setninger bør ikke flagges som AI-generert bare fordi den har lav burstiness—den lave burstinessen reflekterer riktige stilvalg for sjangeren, ikke maskinskriving.
Fremtiden for burstiness-analyse i AI-deteksjon utvikler seg mot mer sofistikerte, kontekstbevisste tilnærminger som både anerkjenner målets begrensninger og utnytter innsikten det gir. Etter hvert som store språkmodeller blir mer avanserte, begynner de å innføre burstiness-variasjon i utdataene, noe som gjør det mindre pålitelig å basere deteksjon kun på dette målet. Forskere utvikler adaptive deteksjonssystemer som analyserer burstiness sammen med semantisk sammenheng, faktuell nøyaktighet og kontekstuell hensiktsmessighet. Fremveksten av AI-humaniseringsteknologier som bevisst øker burstiness og andre menneskelignende trekk, gir en pågående kappløp mellom deteksjon og unnvikelsesteknologi. Eksperter spår imidlertid at virkelig pålitelig AI-deteksjon til slutt vil avhenge av kryptografiske verifikasjonsmetoder og opprinnelsessporing snarere enn kun språkanalyse. For innholdsprodusenter og organisasjoner er den strategiske implikasjonen klar: i stedet for å se burstiness som et mål å manipulere, bør forfattere fokusere på å utvikle autentiske, varierte skrivestiler som naturlig reflekterer menneskelig kommunikasjon. AmICiteds overvåkningsplattform representerer et nytt grensesnitt i dette feltet, ved å spore hvordan merkevarer nevnes i AI-genererte svar og analysere de språklige trekkene i disse nevningene. Etter hvert som AI-systemer blir mer utbredt i innholdsproduksjon og -distribusjon, blir forståelse av burstiness og relaterte mål stadig viktigere for å opprettholde merkevareautentisitet, sikre akademisk integritet og bevare skillet mellom menneske- og maskinskrevet innhold. Utviklingen mot multi-signal deteksjonstilnærminger antyder at burstiness vil forbli relevant som ett element i omfattende AI-overvåkningssystemer, selv om rollen blir mer nyansert og kontekstavhengig.
Burstiness og perpleksitet er utfyllende måleverdier brukt i AI-deteksjon. Perpleksitet måler hvor forutsigbare enkeltord er i en tekst, mens burstiness måler variasjonen i setningsstruktur og lengde gjennom et helt dokument. Menneskelig skriving viser vanligvis høyere perpleksitet (mer uforutsigbare ordvalg) og høyere burstiness (mer varierte setningsstrukturer), mens AI-generert tekst har en tendens til å vise lavere verdier for begge mål, grunnet avhengigheten av statistiske mønstre fra treningsdata.
Høy burstiness skaper en rytmisk flyt som øker leserens engasjement og forståelse. Når forfattere veksler mellom korte, slagkraftige setninger og lengre, komplekse, opprettholdes leserens interesse og monotoni unngås. Forskning viser at variert setningsstruktur forbedrer hukommelsen og får innholdet til å føles mer autentisk og samtalepreget. Lav burstiness, preget av jevn setningslengde, kan gjøre teksten robotaktig og vanskelig å følge, noe som reduserer både lesbarhet og publikumsengasjement.
Selv om burstiness kan økes med vilje gjennom bevisst variasjon i setningsstruktur, vil dette ofte gi en unaturlig tekst som kan trigge andre deteksjonsmekanismer. Moderne AI-detektorer analyserer flere lingvistiske trekk utover burstiness, inkludert semantisk sammenheng, kontekstuell hensiktsmessighet og stilometriske mønstre. Autentisk burstiness oppstår naturlig i ekte menneskelig skriving og reflekterer forfatterens unike stemme, mens tvungen variasjon vanligvis mangler den organiske kvaliteten som kjennetegner virkelig menneskeskrevet innhold.
Ikke-engelsktalende skribenter viser ofte lavere burstiness fordi skrivevanene deres reflekterer et mer begrenset ordforråd og enklere setningsoppbygging. Språklærende benytter vanligvis mer ensartede, forutsigbare setningsstrukturer mens de utvikler ferdighetene, og unngår komplekse leddsetninger og varierte syntaktiske mønstre. Dette gir en stilometrisk profil som ligner AI-generert tekst, og fører til falske positive i AI-deteksjonssystemer. Forskning fra Stanford Universitys 2023-studie på TOEFL-oppgaver bekreftet denne skjevheten, og fremhever en viktig begrensning ved burstiness-baserte deteksjonsmetoder.
Store språkmodeller trenes på enorme datasett hvor de lærer å forutsi neste ord basert på statistiske mønstre. Under treningen optimaliseres modellene for å minimere perpleksitet på treningsdataen, noe som utilsiktet gir ensartede setningsstrukturer og forutsigbare ordsekvenser. Dette resulterer i gjennomgående lav burstiness fordi modellene genererer tekst ved å velge statistisk sannsynlige ordkombinasjoner i stedet for å bruke varierende, spontane setningskonstruksjoner som kjennetegner menneskelig skriving. Modellenes avhengighet av sannsynlighetsfordelinger gir et homogent stilistisk preg.
AmICited sporer hvordan merkevarer og domener nevnes i AI-genererte svar på plattformer som ChatGPT, Perplexity og Google AI Overviews. Å forstå burstiness hjelper AmICiteds overvåkningssystem med å skille mellom autentiske menneskeskrevne siteringer og AI-generert innhold som nevner merkevaren din. Ved å analysere burstiness-mønstre sammen med andre språklige markører kan AmICited gi mer presise innblikk i om merkevaren din siteres i ekte menneskeskrevet innhold eller i AI-genererte svar, noe som gjør det enklere å styre omdømmet.
Forfattere kan forbedre burstiness organisk ved bevisst å variere setningsoppbyggingen samtidig som de opprettholder klarhet og hensikt. Teknikker inkluderer å veksle mellom enkle, påstandssetninger og komplekse setninger med flere ledd, bruke retoriske virkemidler som fragmenter og tankestreker for å skape vekt, og variere avsnittslengder. Nøkkelen er at variasjonen skal tjene innholdets mening, ikke bare oppstå for variasjonens skyld. Å lese høyt, studere ulike skrivestiler og revidere med fokus på rytme utvikler naturlig evnen til å skrive tekster med høy burstiness som låter ekte og engasjerende.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Lær hva burstiness betyr i AI-generert innhold, hvordan det skiller seg fra menneskelig skrive-mønster, og hvorfor det er viktig for AI-deteksjon og innholdsaut...
Diskusjon i fellesskapet om burstiness i AI-innholddeteksjon – hva det betyr, hvordan det påvirker AI-synlighet, og om innholdsskapere bør optimalisere for det....
Lær hva innholdsferskhet betyr, hvorfor det er viktig for SEO og AI-søkemotorer som ChatGPT og Perplexity, og hvordan du holder innholdet ditt oppdatert for bed...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.