
Enhetsgjenkjenning
Enhetsgjenkjenning er en AI NLP-funksjon som identifiserer og kategoriserer navngitte enheter i tekst. Lær hvordan det fungerer, dets bruksområder innen AI-over...
9 min lesing

Enhetsdisambiguering er prosessen med å avgjøre hvilken spesifikk enhet en gitt omtale refererer til når flere enheter deler samme navn. Det hjelper AI-systemer å forstå og sitere innhold nøyaktig ved å løse tvetydighet i navngitte enhetsreferanser, slik at omtaler av ‘Apple’ korrekt identifiserer om referansen gjelder Apple Inc., frukten eller en annen enhet med samme navn.
Enhetsdisambiguering er prosessen med å avgjøre hvilken spesifikk enhet en gitt omtale refererer til når flere enheter deler samme navn. Det hjelper AI-systemer å forstå og sitere innhold nøyaktig ved å løse tvetydighet i navngitte enhetsreferanser, slik at omtaler av 'Apple' korrekt identifiserer om referansen gjelder Apple Inc., frukten eller en annen enhet med samme navn.
Enhetsdisambiguering er prosessen med å avgjøre hvilken spesifikk enhet en gitt omtale refererer til når flere enheter deler samme navn eller lignende referanser. I sammenheng med kunstig intelligens og naturlig språkprosessering (NLP) sikrer enhetsdisambiguering at når et AI-system møter en navngitt enhet i tekst, identifiserer det korrekt hvilket virkelig objekt, person, organisasjon eller sted det refereres til. Dette er grunnleggende forskjellig fra navngitt enhetsgjenkjenning (NER), som bare identifiserer at en enhet eksisterer og klassifiserer den i en kategori som “person,” “organisasjon” eller “sted.” Mens NER svarer på spørsmålet “Finnes det en enhet her?”, svarer enhetsdisambiguering på “Hvilken spesifikk enhet er dette?” For eksempel, når man behandler setningen “Apple was the brain-child of Steve Jobs,” identifiserer NER “Apple” som en organisasjon, men enhetsdisambiguering avgjør om dette refererer til Apple Inc., teknologiselskapet, eller potensielt en annen enhet med samme navn. Dette skillet er kritisk for AI-systemer som må forstå og sitere innhold nøyaktig, og derfor overvåker AmICited.com hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews håndterer enhetsdisambiguering når de genererer svar om merkevarer og organisasjoner.
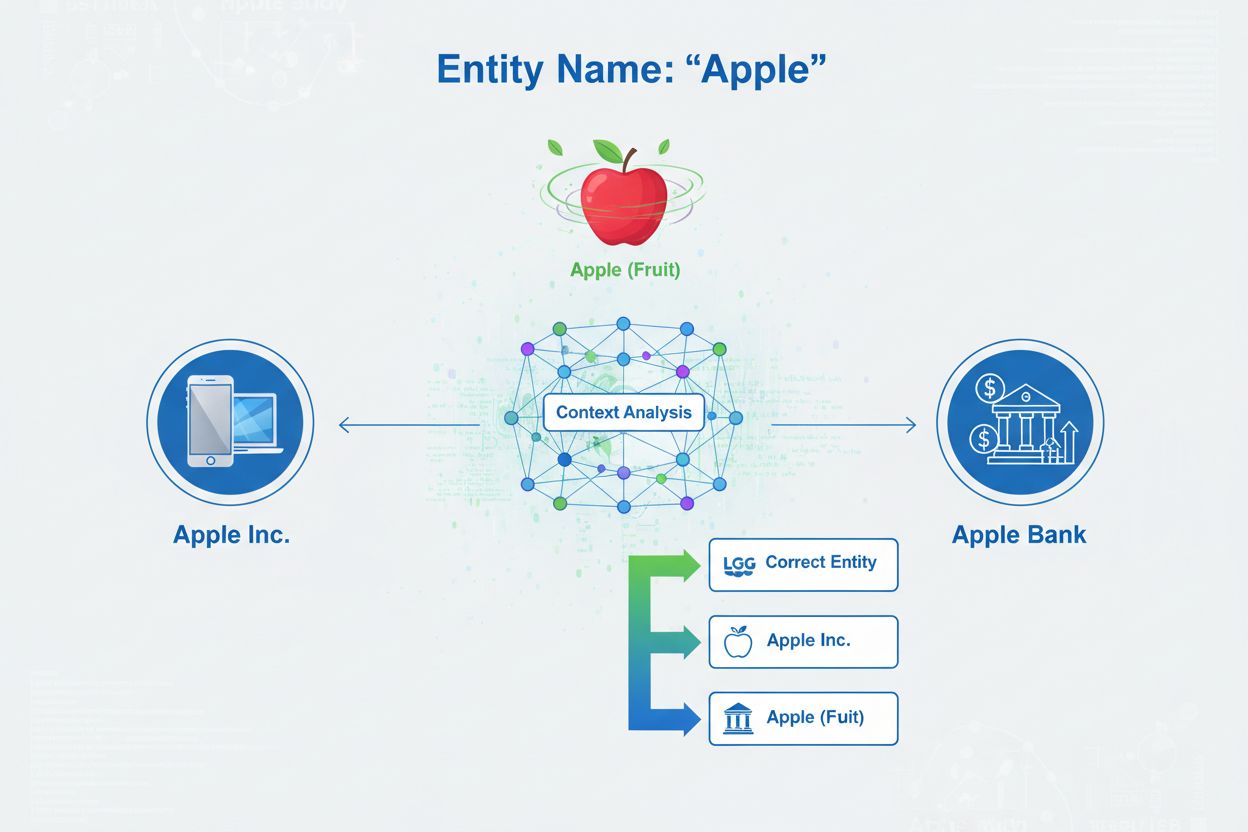
Det grunnleggende problemet som enhetsdisambiguering løser er tvetydighet—faktumet at mange enhetsnavn kan referere til flere ulike virkelige objekter. Denne tvetydigheten skaper betydelige utfordringer for AI-systemer som prøver å forstå og generere nøyaktig innhold. Ifølge Stanford AI Index 2024 inneholder over 18 % av LLM-utdata som involverer merkeenheter enten hallusinasjoner eller feilattribusjoner, noe som betyr at AI-systemer ofte forveksler en enhet med en annen eller genererer feilaktig informasjon om enheter. Denne feilraten har alvorlige konsekvenser for merkevarerepresentasjon og innholdsnøyaktighet. Når et AI-system feiltolker en enhet, kan det gi feil informasjon, tilskrive utsagn til feil organisasjon eller unnlate å sitere riktig kilde til informasjonen.
| Enhetsnavn | Mulige betydninger | AI-forvirringsrate |
|---|---|---|
| Apple | Teknologiselskap / Frukt / Bank | Høy |
| Delta | Flyselskap / Kranprodusent / Gresk bokstav | Høy |
| Jaguar | Bilprodusent / Dyreart | Middels |
| Amazon | E-handelselskap / Regnskog / Elv | Høy |
| Orange | Farge / Frukt / Telekomselskap | Middels |
Konsekvensene av dårlig enhetsdisambiguering strekker seg utover enkle faktiske feil. For innholdsprodusenter og merkevarer kan feilidentifikasjon i AI-genererte svar føre til tapt synlighet, feil attribusjon og skade på merkevarens omdømme. Når en bruker spør et AI-system om “Delta,” kan de søke informasjon om Delta Airlines, men hvis systemet forveksler det med Delta Faucet Company, får brukeren irrelevant informasjon. Dette er nettopp grunnen til at AmICited.com overvåker hvordan AI-systemer disambiguere enheter—for å hjelpe merkevarer å forstå om de blir korrekt identifisert og sitert i AI-generert innhold på tvers av flere plattformer.
Enhetsdisambiguering opererer gjennom en systematisk prosess som kombinerer flere NLP-teknikker for å løse tvetydighet og korrekt identifisere enheter. Å forstå denne prosessen forklarer hvorfor noen AI-systemer presterer bedre enn andre når det gjelder å opprettholde siteringsnøyaktighet.
Navngitt enhetsgjenkjenning (NER): Første steg innebærer å identifisere og klassifisere navngitte enheter i teksten. NER-systemer skanner gjennom tekstdata og lokaliserer omtaler av enheter, og tildeler dem forhåndsdefinerte kategorier som person, organisasjon, sted, produkt eller dato. For eksempel, i setningen “Apple was the brain-child of Steve Jobs,” identifiserer NER både “Apple” og “Steve Jobs” som enheter og klassifiserer dem som henholdsvis organisasjon og person. Dette grunnleggende steget er essensielt fordi disambiguering ikke kan skje uten først å identifisere hvilke enheter som er til stede i teksten.
Enhetskategorisering: Når enheter er identifisert, må de kategoriseres mer presist. Dette involverer ikke bare bred klassifisering, men også å forstå den spesifikke typen og konteksten til hver enhet. Systemet analyserer omkringliggende tekst for å forstå om “Apple” fremstår i en teknologikontekst (Apple Inc.), en matkontekst (frukten) eller en finansiell sammenheng (Apple Bank). Denne kontekstanalysen hjelper med å snevre inn mulighetene før selve disambigueringen.
Disambiguering: Dette er kjernesteget der systemet avgjør hvilken spesifikk enhet det refereres til. Systemet vurderer flere kandidat-enheter som matcher det identifiserte navnet, og bruker ulike signaler—inkludert kontekst, enhetsbeskrivelser, semantiske relasjoner og kunnskapsgrafinformasjon—for å velge den mest sannsynlige riktige enheten. For “Apple was the brain-child of Steve Jobs” gjenkjenner systemet at Steve Jobs er sterkt assosiert med Apple Inc., og velger dermed det som korrekt disambiguering.
Kunnskapsbaselinking: Det siste steget innebærer å knytte den disambiguerte enheten til en unik identifikator i en ekstern kunnskapsbase eller kunnskapsgraf, som Wikidata, Wikipedia eller en proprietær database. Denne koblingen bekrefter enhetens identitet og beriker teksten med semantisk informasjon som kan brukes til videre prosessering og analyse. Enheten får tildelt en unik URI (Uniform Resource Identifier) som fungerer som et definitivt referansepunkt.
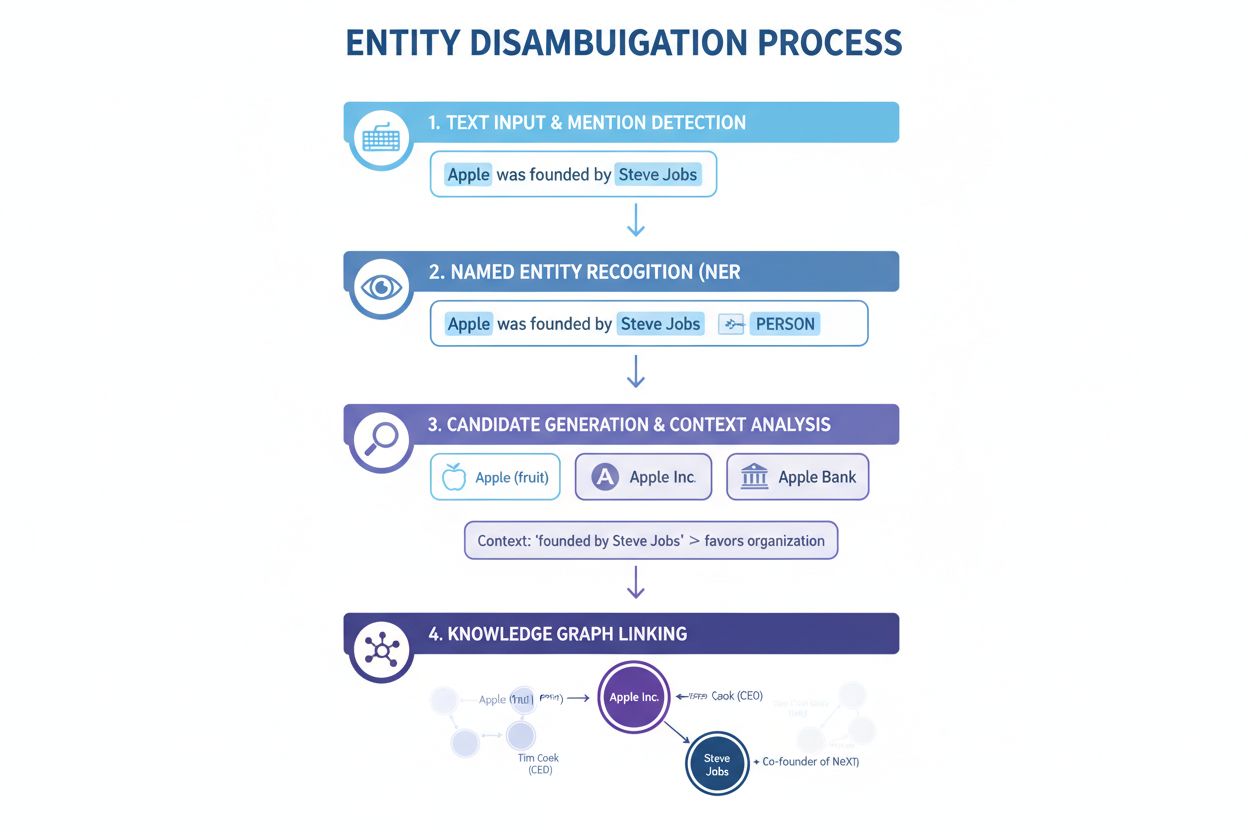
Ulike tilnærminger til enhetsdisambiguering har utviklet seg over tid, hver med ulike fordeler og begrensninger. Å forstå disse tilnærmingene forklarer hvorfor moderne AI-systemer varierer i disambigueringens nøyaktighet.
Regelbaserte tilnærminger: Disse systemene bruker forhåndsdefinerte språklige regler og heuristiske mønstre for å disambiguere enheter. De kan anvende regler som “hvis ‘Apple’ forekommer nær ‘iPhone’ eller ‘MacBook’, gjelder det Apple Inc.” eller “hvis ‘Delta’ forekommer nær ‘airline’ eller ‘flight’, gjelder det Delta Airlines.” Regelbaserte systemer er tolkbare og krever ikke store treningsdatasett, men de sliter med nye kontekster og kan ikke tilpasse seg nye betydninger uten manuell regeloppdatering.
Maskinlæringstilnærminger: Supervised maskinlæringsmodeller lærer fra annoterte treningsdata for å forutsi riktig enhet basert på kontekstuelle trekk. Systemene trekker ut trekk fra omkringliggende tekst og bruker algoritmer som Support Vector Machines eller Random Forests for å klassifisere hvilken enhet som er mest sannsynlig. Maskinlæringstilnærminger er mer fleksible enn regelbaserte systemer, men krever store mengder merket treningsdata og kan ha utfordringer med å generalisere til ukjente enheter.
Dyp læring og transformerbaserte modeller: Moderne enhetsdisambiguering baseres i økende grad på transformerarkitekturer som BERT, RoBERTa og spesialiserte modeller som GENRE og BLINK. Disse modellene bruker nevrale nettverk for å forstå kontekst på et dypere nivå, og fanger opp semantiske relasjoner og nyanserte språkmønstre. Transformermodeller når høy ytelse på standardbenchmarks og kan bedre håndtere komplekse disambigueringstilfeller. For eksempel bruker Ontotext sin CEEL (Common English Entity Linking) et transformerbasert system optimalisert for CPU-effektivitet med høy nøyaktighet, og oppnår 96 % enhetsgjenkjenning og 76 % enhetslinking på standardbenchmarks.
Kunnskapsgrafintegrasjon: Moderne systemer kombinerer maskinlæring med kunnskapsgrafer—strukturerte databaser som representerer enheter og deres relasjoner. Kunnskapsgrafer gir rik kontekstuell informasjon om enheter, deres egenskaper og hvordan de er relatert til andre enheter. Ved å slå opp i kunnskapsgrafer under disambiguering kan systemene hente metadata, beskrivelser og relasjonsinformasjon som hjelper til med å løse tvetydighet mer nøyaktig.
Enhetsdisambiguering har blitt essensiell på tvers av mange bransjer og bruksområder, som alle nyter godt av nøyaktig enhetsidentifikasjon og sitering.
Søkemotorer: Google, Bing og andre søkemotorer er avhengige av enhetsdisambiguering for å gi relevante resultater. Når en bruker søker etter “Apple”, må søkemotoren avgjøre om brukeren er interessert i Apple Inc., frukten eller en annen enhet med det navnet. Søkemotorer bruker søkekontekst, brukerhistorikk og kunnskapsgrafer for å disambiguere og vise de mest relevante resultatene. Derfor viser søkeresultater for “Apple” vanligvis teknologiselskapet først—systemet har lært at dette oftest er den tiltenkte enheten.
Media og publisering: Nyhetsorganisasjoner og innholdsplattformer bruker enhetsdisambiguering for å øke oppdagbarheten av innhold og lenke til relaterte artikler. Når en nyhetsartikkel nevner “Apple”, kan systemet automatisk lenke til Apple Inc.s kunnskapsbaseoppføring, og gi leserne mer kontekst og relaterte artikler. Dette forbedrer brukerengasjement og hjelper lesere å forstå den bredere sammenhengen i nyhetssaker.
Helsevesen: Medisinske institusjoner bruker enhetsdisambiguering for å identifisere legemidler, sykdommer og prosedyrer korrekt i pasientjournaler og klinisk litteratur. Disambiguering av legemiddelnavn er spesielt kritisk—“aspirin” kan referere til det generiske legemidlet, et spesifikt merkenavn eller en doseringsvariant. Nøyaktig disambiguering sikrer at helsepersonell får tilgang til riktig informasjon og at pasientjournaler er korrekt organisert.
Finansielle tjenester: Investeringsselskaper og finansanalytikere bruker enhetsdisambiguering for å spore selskapsomtaler i nyheter, resultatrapporter og markedsdata. Ved markedsanalyse må et firma identifisere alle omtaler av et spesifikt selskap på tvers av ulike datakilder. Enhetsdisambiguering sikrer at “Apple”-referanser tilskrives Apple Inc. og ikke andre enheter, og muliggjør nøyaktig risikovurdering og porteføljeanalyse.
E-handel: Nettforhandlere bruker enhetsdisambiguering for å matche produktomtaler med faktiske produkter i katalogene sine. Når en kunde søker etter “Apple laptop”, må systemet disambiguere “Apple” som selskapet og matche det til relevante produkter. Dette forbedrer søkenøyaktigheten og hjelper kundene å finne det de leter etter mer effektivt.
AmICited.com anvender prinsippene for enhetsdisambiguering for å overvåke hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews håndterer merkevareomtaler. Ved å spore om disse systemene korrekt disambiguere merkevarenheter og siterer dem riktig, hjelper AmICited merkevarer å forstå sin synlighet og representasjon i AI-generert innhold.
Kunnskapsgrafer har blitt grunnleggende i moderne enhetsdisambigueringssystemer, og gir strukturerte representasjoner av enheter og deres relasjoner. En kunnskapsgraf er i bunn og grunn en database av enheter (noder) og relasjoner mellom dem (kanter). Hver enhetsnode inneholder metadata som navn, beskrivelse, type og egenskaper. For eksempel kan “Apple Inc.” i en kunnskapsgraf ha egenskaper som “grunnlagt i 1976,” “hovedkontor i Cupertino,” “bransje: teknologi,” og relasjoner som “grunnlagt av Steve Jobs” og “produserer iPhone.”
Når et enhetsdisambigueringssystem møter en tvetydig enhetsomtale, kan det søke i kunnskapsgrafen for å hente rik kontekstuell informasjon om mulige enheter. Denne informasjonen hjelper systemet å ta mer informerte beslutninger om disambiguering. For eksempel, om systemet prøver å disambiguere “Apple” og finner at teksten nevner “Steve Jobs,” kan det søke i kunnskapsgrafen og se at Steve Jobs er sterkt knyttet til Apple Inc., og dermed velge dette som riktig enhet. Kunnskapsgrafer som Wikidata og Wikipedia gir offentlig tilgjengelig enhetsinformasjon som mange AI-systemer bruker under inferens. Proprietære kunnskapsgrafer bygget av selskaper som Google og Microsoft gir ytterligere domenespesifikk informasjon. Integrasjonen av kunnskapsgrafer med maskinlæringsmodeller har betydelig forbedret nøyaktigheten på enhetsdisambiguering, fordi systemene nå kan kombinere lærte mønstre med strukturerte fakta.
Til tross for betydelige fremskritt, møter enhetsdisambigueringssystemer flere vedvarende utfordringer som begrenser nøyaktighet og anvendelighet.
Polysemi og tvetydighet: Mange enhetsnavn har flere legitime betydninger, og kontekst alene er ikke alltid nok for å disambiguere dem. “Bank” kan bety en finansinstitusjon eller elvebredden. “Crane” kan være en fugl eller en kranmaskin. Enkelte enhetsnavn er så tvetydige at selv mennesker sliter med å avgjøre betydningen uten mer kontekst. AI-systemer må lære å kjenne igjen når konteksten ikke er tilstrekkelig og håndtere slike tilfeller hensiktsmessig.
Nye og fremvoksende enheter: Kunnskapsbaser og treningsdatasett blir utdaterte etter hvert som nye enheter dukker opp. Når et nytt selskap opprettes eller et nytt produkt lanseres, har kanskje ikke disambigueringssystemene informasjon om det i kunnskapsbasen. Zero-shot entity linking—evnen til å disambiguere enheter som ikke er sett i treningen—er fortsatt en utfordring. Systemene må kunne gjenkjenne at en enhet er ny og håndtere det riktig i stedet for å matche den feilaktig til en eksisterende enhet med lignende navn.
Navnevarianter og stavefeil: Enheter har ofte flere navn, forkortelser og varianter. “United States,” “USA,” “U.S.” og “America” refererer alle til samme enhet. Stavefeil og skrivefeil kompliserer disambiguering ytterligere. Systemene må gjenkjenne disse variantene og korrekt matche dem til den kanoniske enheten. Dette er spesielt utfordrende i brukergenerert innhold hvor stavefeil er vanlige.
Ufullstendig eller utdatert data: Kunnskapsbaser kan inneholde ufullstendig informasjon om enheter, eller informasjonen kan bli utdatert etter hvert som enhetene endres. Et selskaps hovedkontor kan flyttes, ledelsen kan skifte eller selskapet kan overtas. Hvis kunnskapsbasen ikke oppdateres raskt nok, kan disambigueringssystemer bruke utdatert informasjon til å ta avgjørelser.
Skalerbarhet og ytelse: Behandling av store tekstmengder med høy presisjon i enhetsdisambiguering krever betydelige datakraftressurser. Sanntidsdisambiguering for webskala applikasjoner er ressurskrevende. Systemene må balansere nøyaktighet med hastighet og kostnad, noe som ofte innebærer kompromisser som kan redusere kvaliteten på disambigueringen.
For merkevarer og innholdsprodusenter er forståelse av enhetsdisambiguering avgjørende for å sikre nøyaktig representasjon i AI-generert innhold. Etter hvert som AI-systemer får større innflytelse på hvordan informasjon oppdages og konsumeres, må merkevarer ta proaktive grep for å sikre at de blir korrekt disambiguert og sitert.
Strategier før disambiguering: Merkevarer kan gjennomføre tiltak som gjør det lettere for AI-systemer å disambiguere deres enhet korrekt. Dette innebærer å skape tydelige, distinkte digitale signaler som hjelper AI-systemer å identifisere merkevaren entydig. En nøkkelstrategi er å implementere strukturert data med Schema.org-markering og JSON-LD-format på merkevarens nettsider. Denne strukturerte dataen forteller AI-systemer eksplisitt om merkevarens identitet, inkludert offisielt navn, beskrivelse, logo, hovedkontor og andre kjennetegn. Når AI-systemer møter merkevarenavnet, kan de referere til denne strukturerte dataen for å bekrefte riktig enhet.
Optimalisering for kunnskapsgrafer: Merkevarer bør sørge for at de har en sterk tilstedeværelse i sentrale kunnskapsgrafer som Wikidata og Wikipedia. Dette innebærer å lage eller oppdatere nøyaktige Wikipedia-artikler, sørge for at Wikidata-oppføringer er komplette og oppdaterte, og bygge relasjoner mellom merkevaren og relaterte enheter. Jo mer omfattende og presis en merkevares tilstedeværelse i kunnskapsgrafer er, jo mer informasjon har AI-systemene tilgjengelig for disambiguering.
Kontekstuell innholdsstrategi: Merkevarer kan produsere innhold som gir tydelig kontekst om deres identitet og skiller dem fra andre enheter med lignende navn. Innhold som eksplisitt nevner merkevarens bransje, produkter, grunnleggere og unike egenskaper hjelper AI-systemer å forstå merkevarens særegenheter. Dette kontekstuelle innholdet blir en del av treningsdataene og konteksten AI-systemer bruker for disambiguering.
Siteringsovervåkning: Verktøy som AmICited.com gjør det mulig for merkevarer å overvåke hvordan AI-systemer disambiguere og siterer deres merkevare på ulike plattformer. Ved å følge med på om ChatGPT, Perplexity, Google AI Overviews og andre systemer korrekt identifiserer merkevaren og siterer den nøyaktig, kan merkevarer oppdage feil i disambiguering og iverksette korrigerende tiltak. Denne overvåkingen er avgjørende for å forstå merkevarens synlighet i den generative AI-tidsalderen.
Generative Engine Optimization (GEO): Etter hvert som enhetsdisambiguering blir viktigere for AI-synlighet, bør merkevarer inkludere enhetsoptimalisering i sin bredere Generative Engine Optimization-strategi. Dette innebærer å sørge for at merkevaren er tydelig definert, godt dokumentert og lett å skille fra konkurrerende enheter. GEO omfatter ikke bare tradisjonell SEO, men også optimalisering for hvordan AI-systemer forstår og representerer merkevarer.
Enhetsdisambiguering utvikler seg videre i takt med fremskritt innen AI-teknologi og nye utfordringer. Flere trender former fremtiden for denne viktige kapasiteten.
Flerspråklig enhetsdisambiguering: Etter hvert som AI-systemene blir mer globale, blir evnen til å disambiguere enheter på tvers av språk stadig viktigere. Et navn kan staves forskjellig på ulike språk, og samme enhet kan omtales med ulike navn i ulike språklige kontekster. Avanserte flerspråklige modeller utvikles for å håndtere enhetsdisambiguering på tvers av språkgrenser, og muliggjøre virkelig globale AI-systemer.
Sanntidsdisambiguering i store språkmodeller: Moderne store språkmodeller som GPT-4 og Claude integrerer i økende grad sanntids enhetsdisambiguering under tekstgenerering. I stedet for å bare stole på treningsdata, kan disse modellene søke i kunnskapsgrafer og eksterne databaser under inferens for å verifisere enhetsinformasjon og sikre nøyaktig disambiguering. Denne kapasiteten forbedrer siteringsnøyaktigheten og reduserer hallusinasjoner.
Bedre zero-shot læring: Fremtidige enhetsdisambigueringssystemer vil trolig oppnå bedre resultater på enheter som ikke er sett i treningen. Fremskritt innen få-skudd- og zero-shot-læring vil gjøre systemene i stand til å disambiguere nye enheter mer effektivt, redusere behovet for hyppig retrening og gjøre systemene mer tilpasningsdyktige for nye enheter.
Integrasjon med Retrieval-Augmented Generation (RAG): Systemer for retrieval-augmented generation, som kombinerer språkmodeller med informasjonsgjenfinning, blir stadig mer populære. Disse systemene kan hente relevant enhetsinformasjon fra kunnskapsbaser under tekstgenerering, noe som forbedrer disambigueringens nøyaktighet og kvaliteten på sitering. Denne integrasjonen representerer et viktig skritt fremover for å sikre at AI-systemer siterer kilder korrekt.
Standardisering og interoperabilitet: Etter hvert som enhetsdisambiguering blir mer kritisk i AI-systemer, vil bransjestandarder for enhetsrepresentasjon og disambiguering sannsynligvis dukke opp. Disse standardene vil muliggjøre bedre interoperabilitet mellom ulike systemer og kunnskapsbaser, og gjøre det enklere for AI-systemer å få tilgang til og bruke enhetsinformasjon konsekvent på tvers av plattformer.
Enhetsdisambiguering har utviklet seg fra en nisjeoppgave innen NLP til en kritisk kapasitet for å sikre at AI-systemer forstår og representerer informasjon nøyaktig. Etter hvert som AI får større innflytelse på hvordan informasjon oppdages og konsumeres, vil viktigheten av nøyaktig enhetsdisambiguering bare øke. For merkevarer, innholdsprodusenter og organisasjoner er forståelse og optimalisering for enhetsdisambiguering essensielt for å opprettholde synlighet og sikre korrekt representasjon i den generative AI-tidsalderen.
Navngitt enhetsgjenkjenning identifiserer at en enhet finnes i teksten og klassifiserer den i kategorier som person, organisasjon eller sted. Enhetsdisambiguering går lenger ved å avgjøre hvilken spesifikk enhet det refereres til når flere enheter deler samme navn. For eksempel identifiserer NER 'Apple' som en organisasjon, mens enhetsdisambiguering avgjør om det gjelder Apple Inc., Apple Bank eller en annen enhet.
Enhetsdisambiguering sikrer at AI-systemer forstår nøyaktig hvilken enhet det snakkes om, og siterer den korrekt. Ifølge Stanford AI Index 2024 inneholder over 18 % av LLM-utdata som involverer merkeenheter hallusinasjoner eller feilattribusjoner. Nøyaktig enhetsdisambiguering forhindrer at AI-systemer forveksler en enhet med en annen, noe som er avgjørende for å opprettholde merkevarens omdømme og siteringsnøyaktighet.
Kunnskapsgrafer gir strukturert informasjon om enheter og deres relasjoner. Når et AI-system støter på en tvetydig enhetsomtale, kan det søke i kunnskapsgrafen for å få tilgang til metadata, beskrivelser og relasjonsinformasjon om mulige enheter. Denne kontekstuelle informasjonen hjelper systemet med å ta mer informerte avgjørelser om disambiguering og velge riktig enhet.
Ja, gjennom zero-shot entity linking-metoder. Moderne systemer kan gjenkjenne når en enhet er ny og håndtere det riktig, i stedet for å feilaktig matche den til en eksisterende enhet. Dette er imidlertid fortsatt en utfordrende problemstilling, og systemene presterer bedre når nye enheter har klare kontekstsignaler som skiller dem fra eksisterende enheter.
Nøyaktig enhetsdisambiguering sikrer at merkevaren din blir korrekt identifisert og sitert i AI-genererte svar. Når AI-systemer disambiguere merkevaren din riktig, får brukerne nøyaktig informasjon om organisasjonen din, noe som forbedrer synlighet og omdømme. Dårlig disambiguering kan føre til at merkevaren din forveksles med konkurrenter eller andre enheter, noe som reduserer synligheten og potensielt skader omdømmet.
Viktige utfordringer inkluderer polysemi (flere betydninger for samme navn), nye enheter som ikke finnes i treningsdataene, navnevarianter og stavefeil, ufullstendige eller utdaterte kunnskapsbaser og skalerbarhetsproblemer. I tillegg er noen enhetsnavn iboende tvetydige, og kontekst alene er kanskje ikke tilstrekkelig for å bestemme riktig enhet.
Merkevarer kan implementere strukturert data ved hjelp av Schema.org-markering, holde Wikipedia- og Wikidata-oppføringer oppdaterte, lage kontekstuelt innhold som tydelig skiller deres merkevare, og overvåke hvordan AI-systemer disambiguere merkevaren deres ved hjelp av verktøy som AmICited. Disse strategiene hjelper AI-systemer å identifisere og sitere merkevaren din korrekt.
Kontekst er avgjørende for enhetsdisambiguering. Den omkringliggende teksten, relaterte enheter og semantiske relasjoner gir signaler som hjelper AI-systemer å avgjøre hvilken enhet som refereres til. For eksempel, hvis 'Apple' står i nærheten av 'Steve Jobs' og 'teknologi', kan systemet bruke denne konteksten til å korrekt disambiguere det som Apple Inc. i stedet for frukten.
Følg med på nøyaktigheten av enhetsdisambiguering på tvers av AI-plattformer og sørg for at merkevaren din blir korrekt identifisert og sitert i AI-genererte svar.
Enhetsgjenkjenning er en AI NLP-funksjon som identifiserer og kategoriserer navngitte enheter i tekst. Lær hvordan det fungerer, dets bruksområder innen AI-over...

Utforsk hvordan AI-systemer gjenkjenner og behandler enheter i tekst. Lær om NER-modeller, transformer-arkitekturer og virkelige applikasjoner av enhetsforståel...
Lær hva AI-enhetsmerking er, hvordan det hjelper AI-systemer å forstå og sitere innholdet ditt, og beste praksis for å implementere Schema.org-strukturert data ...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.