
Hvordan implementere LLMs.txt: En trinnvis teknisk guide
Lær hvordan du implementerer LLMs.txt på nettstedet ditt for å hjelpe AI-systemer med å forstå innholdet ditt bedre. Komplett trinnvis guide for alle plattforme...
9 min lesing

En foreslått standardfil plassert på en nettsides rot-domene som kommuniserer med AI-crawlere og store språkmodeller om høykvalitets, siterbart innhold. Ligner på robots.txt, men er laget for veiledning under inferenstid i stedet for tilgangskontroll. Hjelper AI-systemer med å oppdage og prioritere autoritativt innhold når de genererer svar. Blir i økende grad tatt i bruk av store AI-plattformer som OpenAI, Anthropic, Perplexity og Google.
En foreslått standardfil plassert på en nettsides rot-domene som kommuniserer med AI-crawlere og store språkmodeller om høykvalitets, siterbart innhold. Ligner på robots.txt, men er laget for veiledning under inferenstid i stedet for tilgangskontroll. Hjelper AI-systemer med å oppdage og prioritere autoritativt innhold når de genererer svar. Blir i økende grad tatt i bruk av store AI-plattformer som OpenAI, Anthropic, Perplexity og Google.
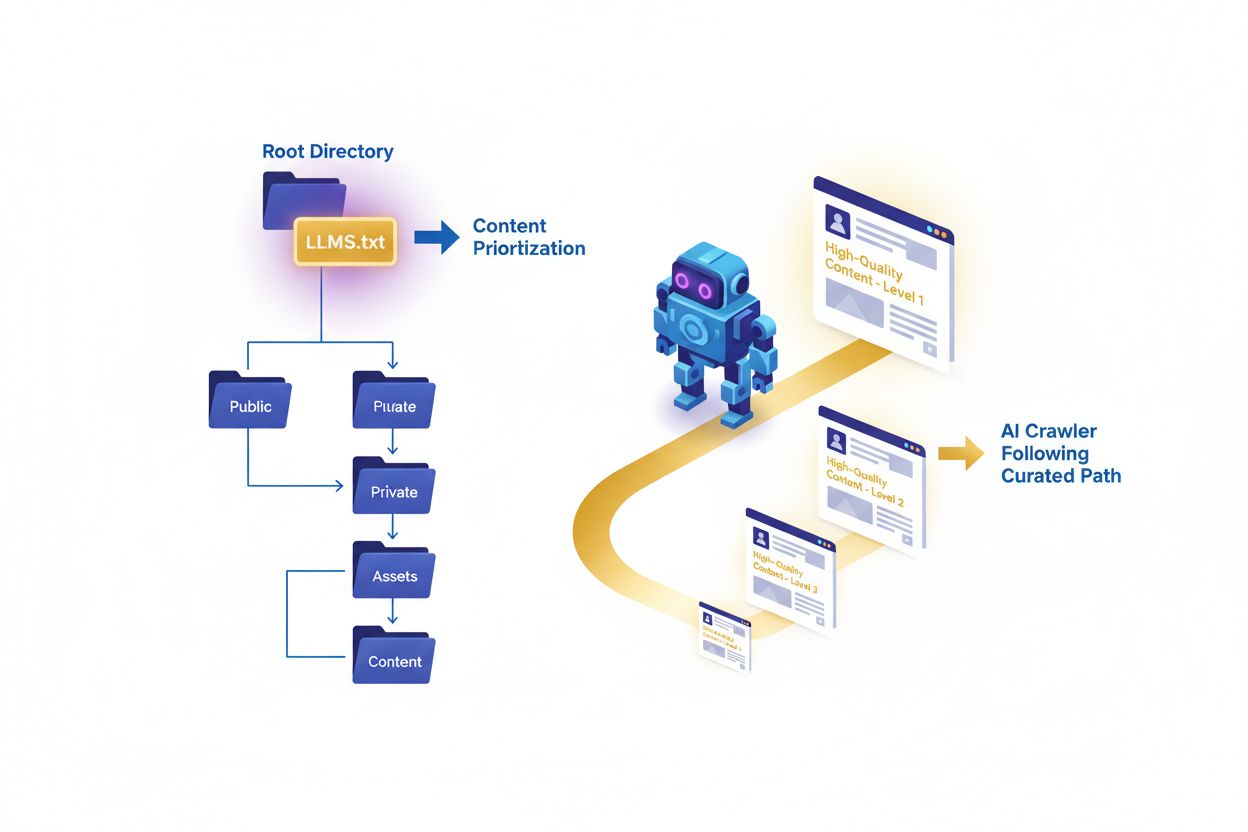
LLMs.txt-filen er en ren tekst-markdownfil plassert på rot-domenet til en nettside som fungerer som en kurert veileder for store språkmodeller under inferenstid. I motsetning til tradisjonelle SEO-verktøy er LLMs.txt utformet for å hjelpe AI-crawlere og språkmodeller med å oppdage og prioritere høykvalitetsinnhold på nettsiden din når de genererer svar eller søker etter informasjon. Denne foreslåtte standarden representerer et skifte i hvordan nettsider kommuniserer med kunstige intelligenssystemer – i stedet for å begrense tilgang som robots.txt, gir den intelligent innholdskuratering. Filen fungerer som et innholdskart som forteller AI-systemer hvilke sider, artikler og ressurser som er mest verdifulle, autoritative og relevante for deres formål. Det er viktig å forstå at LLMs.txt ikke handler om å blokkere eller tillate AI-trening – det er spesifikt for innsamling under inferenstid, slik at AI-systemer finner riktig innhold når de svarer på brukerspørsmål. Filen skrives i markdownformat og lagres som ren tekst, noe som gjør den enkel å lage og vedlikeholde. Ved å implementere LLMs.txt kan nettsider sikre at når AI-systemer refererer til innholdet deres, trekkes det fra de mest nøyaktige, godt strukturerte og autoritative kildene tilgjengelig.
Selv om robots.txt og sitemap.xml har tjent nettsider godt for tradisjonelle søkemotorer, adresserer LLMs.txt et fundamentalt annet behov i kunstig intelligens-æraen. Hovedforskjellen ligger i deres primære funksjoner og tidspunkt: robots.txt styrer crawlingsatferd og hva søkemotorer kan få tilgang til, sitemap.xml hjelper søkemotorer å oppdage og indeksere sider, mens LLMs.txt veileder AI-systemer under inferens, altså når de aktivt genererer svar. Det er viktig å forstå at LLMs.txt ikke blokkerer eller tillater AI-trening – den bare kuraterer hvilket innhold AI-systemer skal prioritere når de svarer på spørsmål eller henter informasjon. De tre filene har utfyllende formål og kan absolutt sameksistere på samme domene uten konflikt. Der robots.txt handler om tilgangskontroll og sitemap.xml om oppdagbarhet, handler LLMs.txt om innholdskvalitet og relevans. Tenk på det slik: robots.txt sier “dette kan du crawle”, sitemap.xml sier “her er det som finnes”, og LLMs.txt sier “her er det som er viktigst”. Denne forskjellen er spesielt viktig fordi AI-systemer trenger andre signaler enn tradisjonelle søkemotorer – de må forstå hvilket innhold som er autoritativt, godt strukturert og egnet for sitering.
| Fil | Primær funksjon | Hovedformål | Bruksområde |
|---|---|---|---|
| robots.txt | Tilgangskontroll | Hindre/tillate crawler-tilgang | Blokkere sensitive sider fra søkemotorer |
| sitemap.xml | Oppdagbarhet | Hjelpe søkemotorer å finne sider | Forbedre indeksering av nytt eller dypt innhold |
| LLMs.txt | Innholdskuratering | Veilede AI under inferens | Styre AI-systemer mot autoritative kilder |
LLMs.txt-filen følger en markdownbasert struktur som er både menneske- og maskinlesbar, noe som gjør den tilgjengelig for både innholdsskapere og AI-systemer. Filen starter vanligvis med en H1-tittel (bruker #) som identifiserer nettstedet og formålet, etterfulgt av et innledende blokk-sitat som gir kontekst om nettstedets misjon eller fokus. Kjernen i strukturen er organiserte seksjoner med H2-overskrifter (##) som grupperer ulike typer innhold – som “Kjerneressurser”, “Guider”, “Dokumentasjon” eller “Beste praksis” – hver med en kurert liste over URL-er med korte beskrivelser. En “Valgfri”-seksjon til slutt lar nettsteder inkludere flere ressurser som kan være verdifulle, men ikke er del av primærkurateringen. Filen bruker ren tekst med UTF-8-koding for å sikre kompatibilitet på tvers av alle systemer og AI-plattformer. Hver URL-oppføring inkluderer vanligvis full sti og en kort beskrivelse av hvorfor innholdet er verdifullt eller hva det dekker. Anbefalt filstørrelse er gjerne under 100KB for effektiv AI-prosessering, selv om det ikke finnes en hard grense. Markdownformatet gir fleksibel organisering med tydelighet, og strukturen bør reflektere nettstedets faktiske innholdshierarki og viktighet.
# Eksempelnettsted – LLMs.txt
> Dette er Eksempelnettsted, en omfattende ressurs for å lære om [ditt tema].
> Vi tilbyr autoritative guider, veiledninger og dokumentasjon for [ditt fagområde].
## Kjerneressurser
- https://example.com/about - Oversikt over vårt oppdrag og vår ekspertise
- https://example.com/getting-started - Viktig startpunkt for nye brukere
## Omfattende guider
- https://example.com/guide/advanced-techniques - Dypdykk i avanserte metoder
- https://example.com/guide/best-practices - Bransjestandarder og anbefalinger
## Dokumentasjon
- https://example.com/docs/api-reference - Komplett API-dokumentasjon
- https://example.com/docs/installation - Oppsett- og installasjonsinstruksjoner
## Valgfritt
- https://example.com/blog/latest-trends - Siste bransjeinnsikt
- https://example.com/case-studies - Virkelige eksempler på implementering
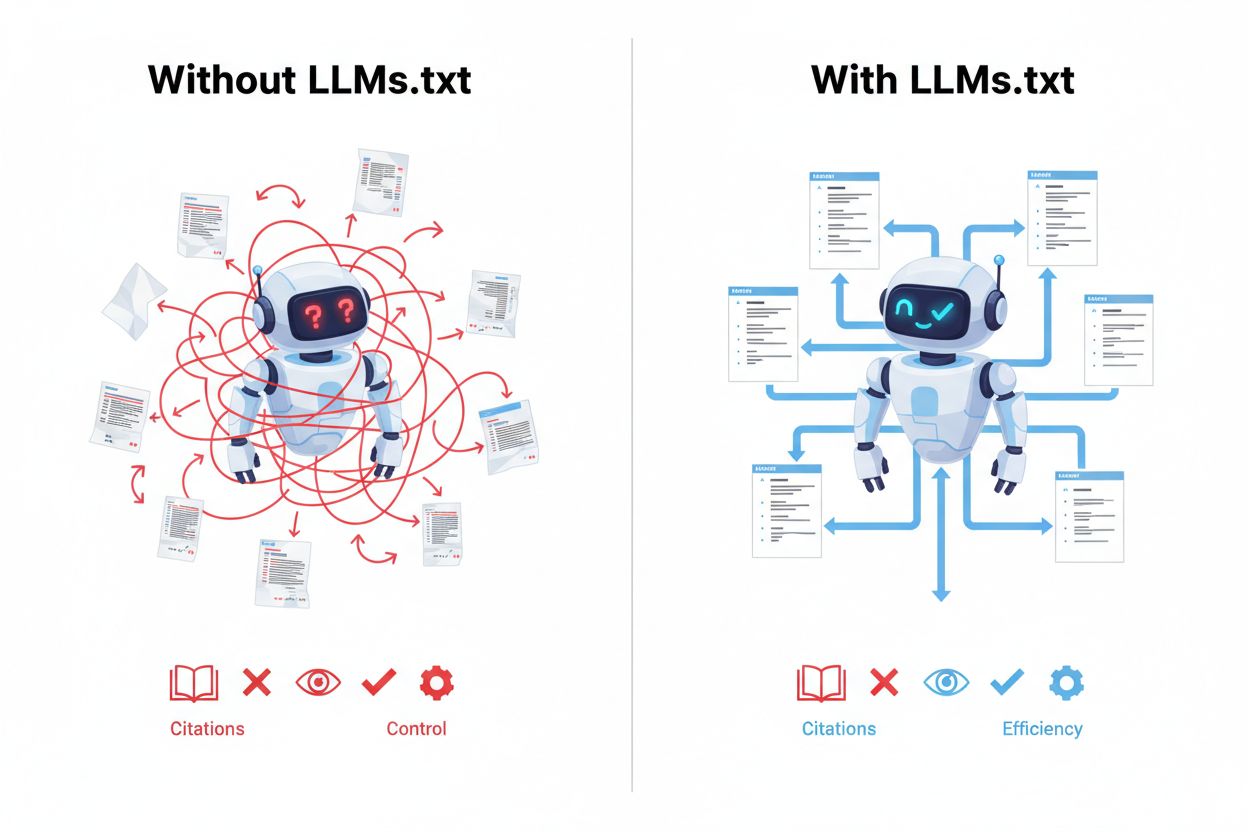
Å implementere LLMs.txt gir store fordeler i det nye landskapet av AI-drevet søk og innholdsoppdagelse. Hovedfordelen er innsamling under inferens, som betyr at ditt kuraterte innhold prioriteres når AI-systemer faktisk svarer på brukerspørsmål, ikke bare under treningsfaser. Dette gir bedre AI-forståelse av innholdets kontekst, autoritet og relevans, noe som resulterer i mer nøyaktige siteringer og referanser når AI-systemer omtaler arbeidet ditt. Ved å ta i bruk LLMs.txt får du direkte kontroll over oppdagelsen, slik at AI-systemer finner ditt beste innhold først, fremfor potensielt svakere sider. Filen øker synligheten i AI-søkeresultater og AI-drevne applikasjoner, og skaper en ny kanal for trafikk og attribusjon som kompletterer tradisjonell SEO. Organisasjoner som tar i bruk LLMs.txt tidlig får et konkurransefortrinn ved å etablere seg som autoritative kilder før standarden blir allment utbredt. Implementeringen fungerer også som fremtidssikring, og forbereder nettstedet for det uunngåelige skiftet mot AI-drevet innholdsoppdagelse.
Viktige bruksområder inkluderer:
LLM-vennlig innhold har spesifikke egenskaper som gjør det mer verdifullt og brukbart for kunstige intelligenssystemer under inferens. Det viktigste er tydelig struktur med korrekt overskriftshierarki, der H1, H2 og H3 brukes for å organisere informasjonen logisk slik at AI-systemer forstår flyten og sammenhengene. Korte avsnitt (ofte 2–4 setninger) foretrekkes fordi det gjør det lettere for AI å trekke ut enkelte konsepter og ideer enn fra store tekstblokker. Innholdet bør inkludere lister, tabeller og punktoppsummeringer som bryter ned komplekse temaer i fordøyelige deler, noe som gjør det enklere for AI å tolke og referere til spesifikke punkter. Minimalt med distraksjoner som automatisk avspilte videoer, popup-vinduer eller mye reklame bør unngås, da dette ikke bidrar til kjerneinnholdet. Semantisk klarhet er essensielt – bruk klart språk, definer faguttrykk og unngå tvetydighet for å hjelpe AI-systemer å forstå meningen korrekt. Innholdet bør være selvstendig og kontekstuelt, slik at det gir mening selv om det trekkes ut og brukes utenfor sin opprinnelige side. Denne tilnærmingen støtter direkte AI-SEO og øker sannsynligheten for at innholdet ditt blir sitert korrekt og fullstendig når AI refererer til arbeidet ditt.
Riktig implementering av LLMs.txt krever strategisk vurdering av hvilket innhold som virkelig fortjener plass og hvordan det skal organiseres for maksimal verdi. Filen må ligge på rot-domenet (f.eks. example.com/llms.txt) for å enkelt kunne oppdages av AI-systemer og crawlere. I stedet for å dumpe hele sitemapet i LLMs.txt, fokuser på kvalitet fremfor kvantitet – inkluder kun ditt mest autoritative, tidløse og verdifulle innhold som du ønsker at AI-systemer skal referere til. Prioriter høyt verdsatte ressurser som omfattende guider, dokumentasjon, veiledninger og original forskning som demonstrerer ekspertise og gir reell verdi. Vurder å ta med forsiden eller om-oss-siden for å hjelpe AI-systemer å forstå virksomhetens misjon og troverdighet. Innholdet du velger bør være godt vedlikeholdt og jevnlig oppdatert, da utdatert informasjon kan skade din troverdighet hos AI-systemer. Organiser innholdet logisk med tydelige seksjonsoverskrifter som gjenspeiler nettstedets struktur og innholdskategorier. Unngå å inkludere innhold som krever autentisering, betalingsmur eller brukerkonto, siden AI-systemene ikke får tilgang til dette. Gjennomfør jevnlige revisjoner og oppdateringer av LLMs.txt-filen for å reflektere endringer i innholdsstrategien, fjerne brutte lenker og legge til nye autoritative ressurser etter hvert som de lages.
LLMs.txt-bruken øker raskt hos store AI-plattformer og bedrifter som ser verdien av kuraterte innholdskilder. OpenAI, Anthropic, Perplexity og Google har alle indikert støtte for eller interesse i LLMs.txt-standarden, og noen plattformer bruker den allerede for å forbedre uthenting og sitering. Standarden er fortsatt ny og ikke obligatorisk, men blir i økende grad anerkjent som beste praksis for nettsteder som vil optimalisere synligheten i AI-drevne applikasjoner. Flere kataloger og registre har dukket opp for å liste nettsteder som implementerer LLMs.txt, og gjør det enklere for AI-systemer å oppdage og prioritere kuraterte kilder. Tidlige brukere får et betydelig forsprang ved å etablere seg som autoritative kilder før standarden blir utbredt på alle AI-plattformer. Virkelige eksempler viser at nettsteder med LLMs.txt får bedre siteringsrate og bedre representasjon i AI-generert innhold. Utviklingen tyder på at LLMs.txt vil bli like standard som robots.txt og sitemap.xml i løpet av noen få år, og implementering er derfor en klok investering for fremtidsrettede organisasjoner.
Forskjellen mellom llms.txt og llms-full.txt representerer to utfyllende tilnærminger for å veilede AI-systemer gjennom innholdet ditt. LLMs.txt er den kuraterte, menneskevalgte versjonen som bare inneholder ditt viktigste, mest autoritative og verdifulle innhold – ofte 20–100 URL-er organisert etter kategori med beskrivelser. LLMs-full.txt, derimot, er en komplett, maskinlesbar versjon som inkluderer alle sider på nettstedet i en strukturert form, ofte generert automatisk fra sitemap eller publiseringssystem. Hovedforskjellen er intensjon: llms.txt krever menneskelig vurdering og utvelgelse, mens llms-full.txt er omfattende og uttømmende. LLMs.txt bør brukes når du vil veilede AI-systemer mot ditt beste innhold og gi tydelige autoritetssignaler, mens llms-full.txt fungerer som et alternativ for AI-systemer som ønsker full dekning av nettstedet. Begge filene bruker markdownformat, men med ulik organisasjonsfilosofi – llms.txt er selektiv og strategisk, llms-full.txt inkluderende og komplett. Mange virksomheter implementerer begge filer samtidig, slik at AI-systemer kan velge mellom kuratert veiledning (llms.txt) eller full dekning (llms-full.txt). For eksempel tilbyr AIOSEO verktøy for automatisk å generere begge versjonene, der llms.txt fremhever premiumnivået og llms-full.txt gir komplett dekning.
Flere vanlige feil kan svekke effekten av LLMs.txt-implementeringen og bør unngås nøye. Den viktigste feilen er å plassere filen feil – den må ligge på rot-domenet (example.com/llms.txt), ikke i undermapper eller med annen navngivning. Manglende nødvendige elementer som H1-tittel og innledende blokk-sitat kan gjøre det vanskelig for AI-systemer å forstå nettstedets formål og autoritet. Å inkludere brutte eller utdaterte URL-er skader troverdigheten og sløser AI-ressurser på å forsøke å hente ikke-eksisterende innhold. Overinkludering er en annen vanlig feil – å legge inn for mange URL-er (hundrevis eller tusenvis) ødelegger poenget med kuratering og gjør det vanskeligere for AI å identifisere virkelig viktig innhold. Dårlige eller manglende beskrivelser ved hver URL betyr at AI-systemer ikke forstår hvorfor innholdet er verdifullt eller hva det dekker. Å ikke oppdatere LLMs.txt-filen jevnlig gjør den utdatert, med brutte lenker og irrelevant innhold som ikke lenger reflekterer nettstedets fokus. Inkludering av innhold som krever autentisering eller betalingsmur, som AI-systemer ikke faktisk får tilgang til, skaper frustrasjon og svekker tilliten. Til slutt må du bruke riktig MIME-type (text/plain eller text/markdown) når du serverer filen, da feil konfigurasjon kan hindre AI-systemene i å tolke filen riktig.
Flere verktøy og ressurser har kommet for å gjøre det enklere å lage og vedlikeholde LLMs.txt-filer. AIOSEO tilbyr et eget plugin som automatisk genererer både llms.txt og llms-full.txt, slik at også ikke-tekniske brukere kan implementere løsningen. For de som foretrekker manuell oppretting, er prosessen enkel – lag en tekstfil i markdown-format og last den opp til rot-domenet. Valideringsverktøy finnes på nettet for å sjekke at LLMs.txt-filen har riktig format, ingen brutte lenker og følger standarden. GitHub-fellesskapet har laget mange repositorier med maler, eksempler og beste praksis for LLMs.txt-implementering. Offisiell dokumentasjon på llmstxt.org gir grundig veiledning om filstruktur, formateringskrav og implementeringsstrategier. Mange AI-plattformers dokumentasjonssider har nå egne seksjoner om LLMs.txt-støtte, slik at du kan se hvordan ulike systemer bruker ditt kuraterte innhold. Disse ressursene gjør det enklere enn noen gang å implementere LLMs.txt og sikre at innholdet ditt er optimalt for AI-drevet oppdagelse og sitering.
LLMs.txt veileder AI-systemer til ditt beste innhold for bruk under inferenstid, mens robots.txt kontrollerer hva søkemotorcrawlere kan få tilgang til. De har ulike formål og kan sameksistere på samme domene. LLMs.txt handler om kuratering og veiledning, mens robots.txt handler om tilgangskontroll.
Nei, det er ikke obligatorisk, men det blir en beste praksis. Å implementere LLMs.txt gir deg et konkurransefortrinn i AI-drevne søkeresultater og sikrer at innholdet ditt får riktig attribusjon når det siteres av AI-systemer.
Filen må plasseres på rot-domenet ditt (f.eks. dittdomene.com/llms.txt) for å kunne oppdages av AI-systemer og crawlere. Den skal være offentlig tilgjengelig uten autentisering.
Nei, llms.txt er ikke laget for blokkering eller kontroll av trening. Den er spesifikt for å veilede AI-systemer under inferens (når de genererer svar). Bruk robots.txt eller andre mekanismer hvis du ønsker å kontrollere tilgang til trening.
Gå gjennom og oppdater kvartalsvis eller hver gang du gjør vesentlige endringer på nettsidestrukturen, legger til viktig nytt innhold, eller endrer URL-er. Regelmessig vedlikehold sikrer at filen holder seg nøyaktig og verdifull.
OpenAI, Anthropic, Perplexity og Google har begynt å implementere støtte for llms.txt. Bruken øker etter hvert som standarden blir mer etablert og anerkjent som beste praksis.
LLMs.txt er en kuratert liste over ditt beste innhold (typisk 20–100 URL-er), mens llms-full.txt inneholder en komplett maskinlesbar versjon av alt ditt innhold i Markdown-format. Begge kan brukes sammen for maksimal fleksibilitet.
Fokuser på kvalitet fremfor kvantitet. Inkluder 10–20 av dine viktigste, mest autoritative sider som best representerer din ekspertise og innholdsverdi. Unngå å legge hele sitemapet ditt i filen.
AmICited sporer hvordan AI-systemer refererer til din merkevare på tvers av ChatGPT, Perplexity, Google AI Overviews og flere. Sørg for at innholdet ditt får riktig attribusjon og synlighet i AI-genererte svar.
Lær hvordan du implementerer LLMs.txt på nettstedet ditt for å hjelpe AI-systemer med å forstå innholdet ditt bedre. Komplett trinnvis guide for alle plattforme...

Kritisk analyse av LLMs.txt sin effektivitet. Finn ut om denne AI-innholdsstandarden er nødvendig for ditt nettsted eller bare opphauset. Ekte data om bruk, pla...

Lær hva LLMs.txt er, om det faktisk fungerer, og om du bør implementere det på nettstedet ditt. Ærlig analyse av denne nye AI SEO-standarden.
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.