En HTML meta-tag som signaliserer til AI-treningssystemer og nettroboter at nettstedets innhold ikke skal brukes til maskinlæringsmodell-trening. Opprinnelig introdusert av DeviantArt, fungerer den som en innholdsbeskyttelsesmekanisme og et fravalgssignal for skapere som er bekymret for uautorisert AI-datasamling.
NoAI Meta Tag
En HTML meta-tag som signaliserer til AI-treningssystemer og nettroboter at nettstedets innhold ikke skal brukes til maskinlæringsmodell-trening. Opprinnelig introdusert av DeviantArt, fungerer den som en innholdsbeskyttelsesmekanisme og et fravalgssignal for skapere som er bekymret for uautorisert AI-datasamling.
Hva er NoAI Meta Tag
NoAI meta-taggen er en innholdsbeskyttelsesmekanisme implementert som en HTML meta-tag som signaliserer til AI-treningssystemer og nettroboter at et nettsteds innhold ikke skal brukes til maskinlæringsmodell-trening. Opprinnelig introdusert av DeviantArt i september 2022, oppstod NoAI-direktivet som et grasrotinitiativ som svar på bekymringer om at kunstneres arbeid ble hentet ut og brukt til å trene generative AI-modeller uten samtykke eller kompensasjon. Meta-taggen fungerer ved å legge til en enkel HTML-erklæring i toppteksten på en nettside, og kommuniserer et tydelig ønske til AI-systemer om at innholdet ikke skal brukes til treningsformål. Selv om taggen ikke er juridisk bindende i de fleste jurisdiksjoner, representerer NoAI-taggen en viktig fravalgsmekanisme for skapere som ønsker å beskytte sin intellektuelle eiendom i en tid med stadig mer aggressiv AI-datasamling.
Hvordan nettroboter fungerer
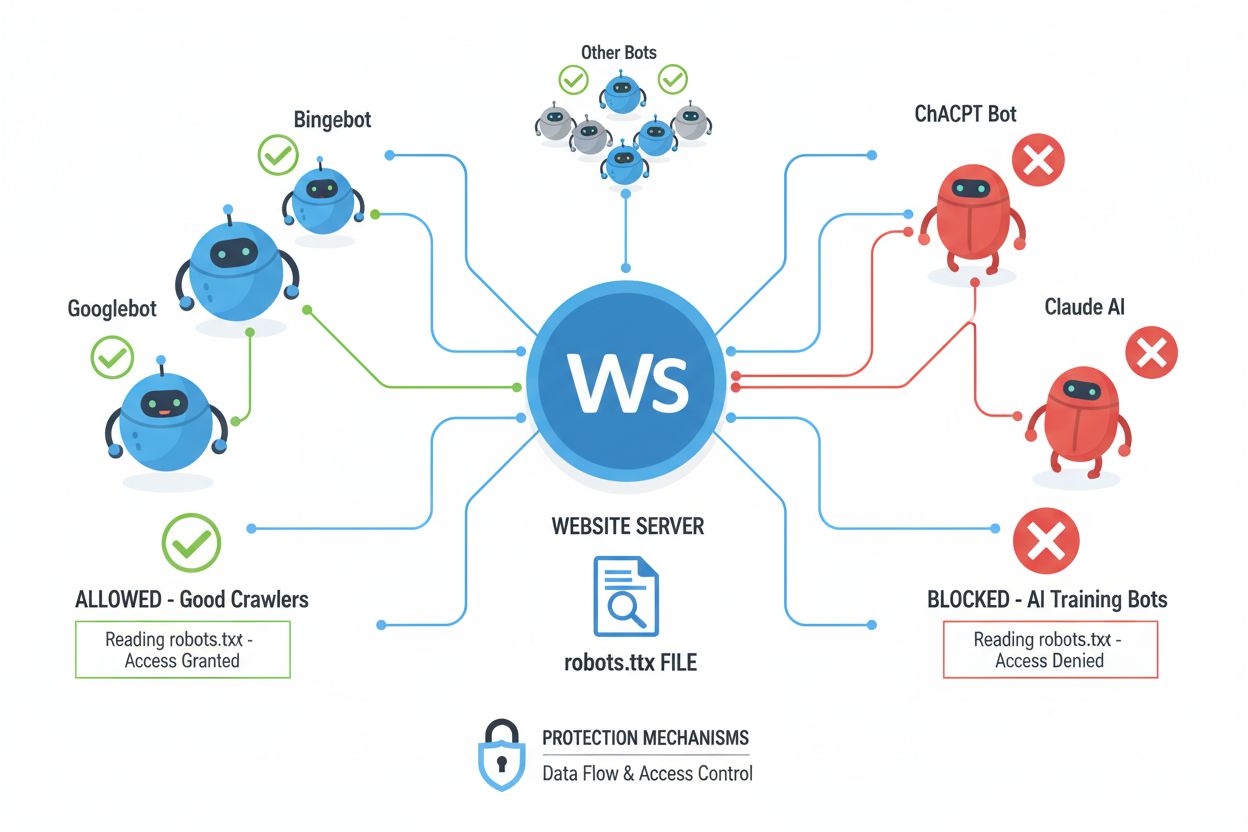
Nettroboter (også kalt bots, spiders eller scrapers) er automatiserte programvarer som systematisk surfer på internett, følger lenker og laster ned innhold for å indeksere, analysere eller samle inn data til ulike formål. Disse robotene opererer ved å lese robots.txt-filen som ligger i rotmappen på et nettsted, hvor det finnes instruksjoner om hvilke områder av nettstedet som skal eller ikke skal være tilgjengelig for automatiserte besøkende. robots.txt-filen bruker spesifikke direktiver som User-agent, Disallow og Allow for å kommunisere tillatelser, men etterlevelsen er helt frivillig og avhenger av om utvikleren av roboten velger å respektere disse retningslinjene. Utover robots.txt kan nettsteder kommunisere preferanser via HTTP-headere og meta-tagger, som gir ytterligere signaler om rettigheter og begrensninger for bruk av innhold. Ulike typer roboter har varierende grad av respekt for disse signalene:
Søkemotorroboter (Google, Bing, DuckDuckGo): Respekterer vanligvis robots.txt og meta-tagger for å opprettholde gode relasjoner med nettstedeiere
AI-treningsroboter (Common Crawl, Apify, spesialiserte AI-scrapere): Har historisk ignorert innholdsbeskyttelsessignaler, men dette er i endring med nye standarder
Kommersielle dataroboter: Overser ofte robots.txt helt og prioriterer datainnsamling fremfor nettstedseiers ønsker
Akademiske forskningsroboter: Respekterer vanligvis robots.txt, men kan ha ulike standarder for forskning
Ondsinnede roboter: Ignorerer bevisst alle signaler og restriksjoner for å hente ut data til uautoriserte formål
Robottype
robots.txt-etterlevelse
Meta-tag-respekt
AI-treningsbruk
Søkemotorer
Høy
Høy
Begrenset
AI-treningsroboter
Middels
Middels
Ja
Kommersielle roboter
Lav
Lav
Varierende
Akademiske roboter
Høy
Middels
Kun forskning
Ondsinnede roboter
Ingen
Ingen
Ubegrenset
NoAI vs NoImageAI
noai- og noimageai-direktivene har beslektede, men distinkte formål innen innholdsbeskyttelse, og hovedforskjellen ligger i omfang og spesifisitet. noai-direktivet er et bredere signal som indikerer at alt innhold på en side – inkludert tekst, bilder, kode og annet media – ikke skal brukes til AI-trening, og passer for nettsteder med blandet innhold eller de som ønsker fullstendig beskyttelse. noimageai-direktivet, derimot, retter seg spesifikt mot kun bildeinnhold, slik at tekst og annet ikke-bildeinnhold potensielt kan brukes til trening, mens visuelle ressurser beskyttes mot AI-modelltrening. Dette skillet er spesielt viktig for nettsteder som vil tillate tekstbasert AI-indeksering (for søkemotorer eller tilgjengelighet), men beskytte sine visuelle elementer mot bruk i generative bildemodeller. Her er implementeringsforskjellene:
<!-- Omfattende beskyttelse for alt innhold --><metaname="robots"content="noai">
<!-- Spesifikk beskyttelse kun for bilder --><metaname="robots"content="noimageai">
<!-- Kombinert tilnærming for maksimal tydelighet --><metaname="robots"content="noai, noimageai">
Implementeringsmetoder
NoAI meta-taggen kan implementeres på flere måter, avhengig av teknisk infrastruktur og behov. Den enkleste metoden er å legge meta-taggen direkte til i HTML-ens <head>-seksjon, noe som gjør at direktivet gjelder for den enkelte siden og kan tilpasses side for side ved behov. For nettsteder med mange sider, eller der man ønsker en løsning som gjelder hele nettstedet, gir implementering via HTTP-responsheadere en mer skalerbar løsning som gjelder for alt innhold uten å måtte endre hver enkelt side. I tillegg kan robots.txt-filen inneholde direktiver rettet mot spesifikke AI-roboter, selv om denne metoden er mindre standardisert enn meta-tagger eller headere. Her er de tre hovedmetodene:
<!-- Metode 1: HTML meta-tag (mest vanlig) --><head>
<metaname="robots"content="noai">
</head>
# Metode 2: robots.txt-direktiv
User-agent: *
Disallow: /
X-Robots-Tag: noai
# Metode 3: HTTP-header (via .htaccess eller serverkonfigurasjon)
X-Robots-Tag: noai
For Apache-servere, legg til i .htaccess:
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
For Nginx-servere, legg til i serverblokken:
add_header X-Robots-Tag "noai" always;
Effektivitet og begrensninger
Selv om NoAI meta-taggen representerer et viktig steg mot innholdsbeskyttelse, bygger den på et æressystem som helt og holdent avhenger av om AI-utviklere og datascrapere velger å respektere signalet. Store AI-selskaper som OpenAI, Google og Anthropic har begynt å respektere NoAI-direktiver i sine roboter, men ondsinnede aktører og uregjerlige roboter ignorerer ofte slike signaler, noe som gjør taggen ineffektiv mot bestemte datatyver. Effektiviteten til NoAI er også begrenset av at den kun forhindrer fremtidig trening på innholdet; den kan ikke fjerne data som allerede er samlet inn og brukt i eksisterende modeller, og gir heller ingen juridisk beskyttelse ved brudd. Etterlevelsesgraden varierer betydelig mellom ulike AI-systemer, hvor noen respekterer direktivet mens andre bevisst omgår det, noe som gjør NoAI til et nyttig, men ufullstendig verktøy. Taggen gir heller ingen beskyttelse mot direkte nedlastinger, skjermbilder eller manuell kopiering av innhold, og kan ikke hindre at konkurrenter bruker innholdet ditt hvis de velger å ignorere direktivet. Av disse grunnene bør NoAI sees på som ett lag i en helhetlig innholdsbeskyttelsesstrategi, ikke som en komplett løsning.
Bransjeadopsjon og standarder
NoAI meta-taggen har oppnådd betydelig utbredelse blant store AI-selskaper og plattformer, hvor OpenAI, Google og Stability AI offentlig har forpliktet seg til å respektere direktivet i sine treningsprosesser. DeviantArts implementering av NoAI har påvirket bransjedebatten om etisk AI-utvikling og skapersamtykke, og ført til økt bevissthet både blant AI-utviklere og innholdsskapere. Likevel er adopsjonen inkonsekvent i bransjen, hvor mindre AI-selskaper, akademiske forskere og kommersielle scrapere viser varierende grad av etterlevelse. Fremveksten av konkurrerende standarder som C2PA (Coalition for Content Provenance and Authenticity) og diskusjoner om maskinlesbare rettighetsuttrykk tyder på at bransjen beveger seg mot mer sofistikerte, juridisk støttede innholdsbeskyttelsesmekanismer utover frivillige meta-tagger. Bransjeorganisasjoner og standardiseringsorganer arbeider aktivt for å formalisere disse beskyttelsene, med forventning om at fremtidig AI-regulering kan kreve eksplisitt etterlevelse av innholdsskaperes preferanser, og potensielt gjøre NoAI om til et lovpålagt krav i stedet for et frivillig signal.
Beste praksis og anbefalinger
Implementering av NoAI-beskyttelse bør være en del av en lagdelt tilnærming til innholdssikkerhet, ikke en enkeltstående løsning, og kombinere tekniske, juridiske og overvåkningsstrategier for helhetlig beskyttelse. For maksimal effekt, vurder disse beste praksisene:
Implementer på alle måter: Bruk HTML meta-tagger, HTTP-headere og robots.txt-direktiver samtidig for å nå ulike typer roboter og systemer
Overvåk etterlevelse: Sjekk jevnlig innholdet ditt mot AI-treningsdatasett og bruk verktøy for å verifisere om innholdet ditt finnes i populære modeller
Kombiner med juridiske beskyttelser: Inkluder tydelige bruksvilkår og opphavsrettsmerknader som eksplisitt forbyr bruk til AI-trening
Bruk vannmerking og fingeravtrykk: Legg til usynlige eller synlige markører i innholdet ditt for å spore uautorisert bruk og bevise eierskap
Implementer tilgangskontroller: Bruk autentisering, betalingsmurer eller fartsbegrensning for å hindre storstilt scraping uavhengig av meta-tagger
Hold deg oppdatert på standarder: Følg med på nye standarder som C2PA og delta i bransjediskusjoner om innholdsbeskyttelse
Utfør også regelmessige revisjoner av innholdsbeskyttelsen din for å sikre at alle sider har riktige direktiver, og vurder bruk av automatiserte verktøy for å skanne etter innholdet ditt i offentlige AI-datasett og treningsdatabaser. Dokumenter din NoAI-implementering som en del av din innholdsstyringspolicy, og kommuniser disse beskyttelsene til ditt publikum slik at de forstår hvilke tiltak du tar for å beskytte deres arbeid hvis du er en plattform som hoster brukergenerert innhold.
Vanlige spørsmål
Hva er forskjellen mellom noai og noimageai meta-tagger?
Direktivet noai beskytter alle innholdstyper (tekst, bilder, kode) mot AI-trening, mens noimageai spesifikt beskytter bare bildeinnhold. Bruk noai for omfattende beskyttelse og noimageai når du vil tillate tekstindeksering, men beskytte visuelle elementer mot generative bildemodeller.
Nei, NoAI meta-taggen fungerer etter et æressystem og avhenger av om AI-utviklere velger å respektere den. Store selskaper som OpenAI og Google respekterer den, men ondsinnede aktører og uregjerlige roboter ignorerer ofte slike signaler, så den er kun ett lag med beskyttelse og ikke en fullstendig løsning.
Hvordan implementerer jeg NoAI meta-taggen på nettstedet mitt?
Du kan implementere den på tre måter: legg til HTML meta-taggen i sidens header, sett HTTP-responsheadere på serveren din, eller inkluder direktiver i robots.txt-filen. HTML meta-tag-metoden er den vanligste og enkleste for de fleste nettstedeiere.
Hvilke AI-selskaper respekterer NoAI meta-taggen?
Store AI-selskaper inkludert OpenAI (ChatGPT), Google, Anthropic (Claude) og Stability AI har offentlig forpliktet seg til å respektere NoAI-direktiver i sine treningsprosesser. Etterlevelsen varierer imidlertid blant mindre AI-selskaper, akademiske forskere og kommersielle roboter.
Kan jeg bruke NoAI meta-tag sammen med robots.txt?
Ja, du kan bruke begge samtidig for maksimal effekt. NoAI meta-taggen og robots.txt-direktiver fungerer sammen for å kommunisere dine innholdsbeskyttelsespreferanser til ulike typer roboter og systemer.
Hva bør jeg gjøre hvis AI-roboter ignorerer min NoAI meta-tag?
Kombiner NoAI med andre beskyttelsesmetoder, inkludert HTTP-headere, robots.txt-regler, vannmerking, tilgangskontroller og juridiske bruksvilkår. Overvåk innholdet ditt i AI-datasett og vurder å bruke verktøy for å spore uautorisert bruk.
Er NoAI meta-taggen en industristandard?
Selv om den er mye brukt blant store AI-selskaper, er NoAI ennå ikke en formell W3C-standard. Bransjeorganisasjoner jobber imidlertid med mer sofistikerte standarder som C2PA og maskinlesbare rettighetsuttrykk, som kan gi juridisk støtte etter hvert.
Hvordan sammenlignes NoAI meta-taggen med andre innholdsbeskyttelsesmetoder?
NoAI er mest effektiv når den kombineres med andre metoder som robots.txt, HTTP-headere, vannmerking, tilgangskontroller og juridisk beskyttelse. Ingen enkeltmetode gir fullstendig beskyttelse, så en lagdelt tilnærming anbefales for omfattende innholdssikkerhet.
Overvåk hvordan AI refererer til innholdet ditt
Følg med på hvilke AI-systemer som siterer merkevaren og innholdet ditt med AmICited sin AI-overvåkningsplattform. Få full kontroll over hvordan arbeidet ditt brukes av ChatGPT, Perplexity, Google AI Overviews og andre AI-systemer.
Hva er noai meta taggen og hvordan beskytter den innholdet ditt mot AI?
Lær om noai meta taggen, hvordan den fungerer for å hindre innsamling av AI-treningsdata, dens begrensninger, og hvordan du kan implementere den på nettstedet d...
Kan noai-metataggen faktisk beskytte innholdet mitt mot AI-trening? Eller er det bare ønsketenkning?
Diskusjon i fellesskapet om noai-metataggen og om den faktisk beskytter innhold mot AI-trening. Brukere deler erfaringer og begrensninger med denne tilnærmingen...
NoAI Meta Tags: Kontrollere AI-tilgang via headere
Lær hvordan du implementerer noai og noimageai meta-tagger for å kontrollere AI-crawleres tilgang til innholdet på nettstedet ditt. Komplett guide til AI-tilgan...
6 min lesing
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.