Audyt Dostępu dla AI Crawlerów: Czy Właściwe Boty Widzą Twoje Treści?
Dowiedz się, jak przeprowadzić audyt dostępu AI crawlerów do swojej strony. Odkryj, które boty widzą Twoje treści i napraw blokady ograniczające widoczność w ChatGPT, Perplexity i innych AI wyszukiwarkach.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
Krajobraz wyszukiwania i odkrywania treści zmienia się radykalnie. Wraz z dynamicznym wzrostem narzędzi wyszukiwania opartych na AI, takich jak ChatGPT, Perplexity i Google AI Overviews, widoczność Twoich treści dla crawlerów AI staje się równie istotna, jak tradycyjne pozycjonowanie SEO. Jeśli boty AI nie mają dostępu do Twoich treści, Twoja strona staje się niewidoczna dla milionów użytkowników korzystających z tych platform w poszukiwaniu odpowiedzi. Stawka jest wyższa niż kiedykolwiek: podczas gdy Google może powrócić na Twoją stronę, jeśli coś pójdzie nie tak, crawlery AI działają według innego paradygmatu—a utrata tego pierwszego, kluczowego crawla może oznaczać miesiące braku widoczności i stracone szanse na cytowania, ruch i budowanie autorytetu marki.
Jak AI Crawlery Różnią się od Tradycyjnych Botów
Crawlery AI działają według zupełnie innych zasad niż boty Google czy Bing, dla których optymalizowałeś przez lata. Najważniejsza różnica: crawlery AI nie renderują JavaScriptu, co oznacza, że treści dynamiczne ładowane przez skrypty po stronie klienta są dla nich niewidoczne—w przeciwieństwie do zaawansowanych możliwości renderowania Google. Dodatkowo, crawlery AI odwiedzają strony z dużo większą częstotliwością, czasami nawet 100 razy częściej niż tradycyjne wyszukiwarki, co daje zarówno nowe możliwości, jak i wyzwania dla zasobów serwera. W przeciwieństwie do modelu indeksowania Google, crawlery AI nie utrzymują stałego indeksu, który jest odświeżany; zamiast tego przeszukują strony na żądanie, gdy użytkownicy zadają pytania w ich systemach. Oznacza to brak kolejki do reindeksacji, brak Search Console do proszenia o ponowne crawlowanie i brak drugiej szansy, jeśli Twoja strona zawiedzie przy pierwszym wrażeniu. Zrozumienie tych różnic jest kluczowe dla optymalizacji strategii treści.
Funkcja
AI Crawlery
Tradycyjne Boty
Renderowanie JavaScript
Nie (tylko statyczny HTML)
Tak (pełne renderowanie)
Częstotliwość crawlów
Bardzo wysoka (100x+ częściej)
Umiarkowana (tygodniowo/miesięcznie)
Możliwość reindeksacji
Brak (tylko na żądanie)
Tak (ciągłe aktualizacje)
Wymagania dotyczące treści
Czysty HTML, oznaczenia schema
Elastyczne (obsługuje treści dynamiczne)
Blokowanie User-Agent
Szczegółowe dla każdego bota (GPTBot, ClaudeBot itd.)
Ogólne (Googlebot, Bingbot)
Strategia cache’owania
Krótkoterminowe snapshoty
Długoterminowe utrzymanie indeksu
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
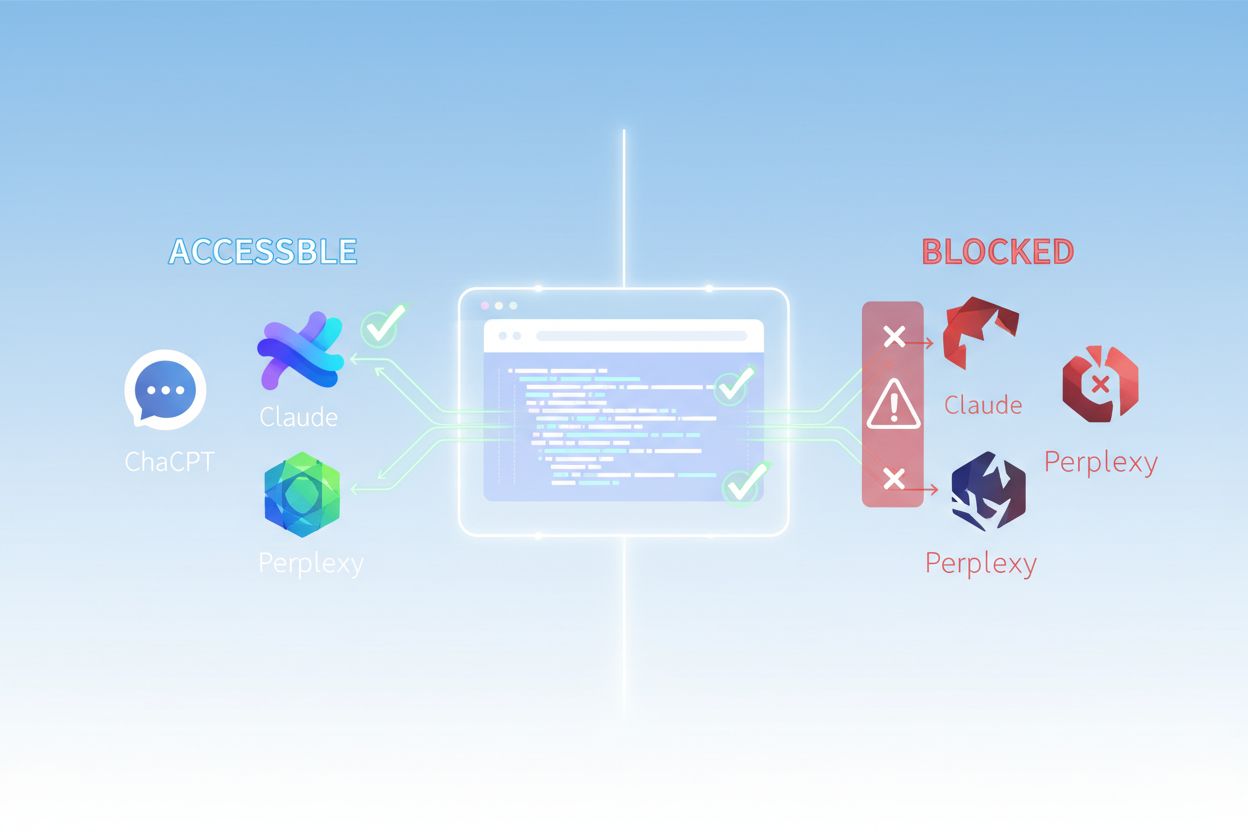
Twoje treści mogą być niewidoczne dla crawlerów AI z powodów, o których nigdy nie pomyślałeś. Oto główne przeszkody uniemożliwiające botom AI dostęp i zrozumienie Twoich treści:
Treści oparte na JavaScript: Jeśli Twoja strona polega na JavaScript po stronie klienta do wyświetlania tekstu, obrazów lub danych strukturalnych, crawlery AI ich nie zobaczą—przetwarzają wyłącznie statyczny HTML
Brak oznaczeń schema: Bez odpowiednich danych strukturalnych (JSON-LD, microdata) crawlery AI mają trudności ze zrozumieniem kontekstu, autorstwa, dat publikacji i relacji między treściami
Problemy z infrastrukturą techniczną: Wolny czas odpowiedzi serwera, błędy 5xx, łańcuchy przekierowań i słabe Core Web Vitals mogą sprawić, że crawlery opuszczą Twoją stronę w trakcie crawla
Treści za paywallem lub logowaniem: Treści za ścianą logowania, paywallem lub zabezpieczone CAPTCHA są całkowicie niedostępne dla crawlerów AI
Zbyt restrykcyjne reguły robots.txt: Blokowanie całych katalogów lub user-agentów uniemożliwia crawlerom dostęp do treści, które chcesz udostępnić
Blokady firewalli i zabezpieczeń: Reguły WAF (Web Application Firewall), blokowanie IP czy limity żądań mogą błędnie uznać crawlery AI za zagrożenie i całkowicie je zablokować
Zrozumienie robots.txt i Reguł User-Agent
Twój plik robots.txt to podstawowy mechanizm kontrolowania, które boty AI mają dostęp do Twoich treści i działa poprzez szczegółowe reguły User-Agent, skierowane do konkretnych crawlerów. Każda platforma AI używa własnych ciągów user-agent—GPTBot OpenAI, ClaudeBot Anthropic, PerplexityBot Perplexity—i możesz pozwolić lub zablokować każdemu z nich niezależnie. Taka szczegółowa kontrola pozwala zdecydować, które systemy AI mogą trenować na Twoich treściach lub je cytować, co jest kluczowe dla ochrony informacji zastrzeżonych lub zarządzania konkurencją. Niestety, wiele stron nieświadomie blokuje crawlerów AI przez zbyt szerokie reguły, napisane z myślą o starszych botach, lub w ogóle nie wdraża odpowiednich reguł.
Oto przykład konfiguracji robots.txt dla różnych botów AI:
# Zezwól GPTBot OpenAI
User-agent: GPTBot
Allow: /
# Zablokuj ClaudeBot Anthropic
User-agent: ClaudeBot
Disallow: /
# Zezwól Perplexity, ale ogranicz dostęp do niektórych katalogów
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# Domyślna reguła dla pozostałych botów
User-agent: *
Allow: /
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Kluczowe Pierwsze Wrażenie
W przeciwieństwie do Google, który stale crawluje i reindeksuje Twoją stronę, crawlery AI działają jednorazowo—odwiedzają stronę, gdy użytkownik zada pytanie w ich systemie, i jeśli Twoje treści nie są wtedy dostępne, tracisz szansę. Ta podstawowa różnica oznacza, że Twoja strona musi być technicznie przygotowana od pierwszego dnia; nie ma okresu karencji ani drugiej szansy na poprawki, zanim stracisz widoczność. Słabe pierwsze wrażenie—czy to z powodu błędów renderowania JavaScript, brakujących oznaczeń schema, czy błędów serwera—może skutkować wykluczeniem Twoich treści z AI-generowanych wyników na tygodnie lub miesiące. Nie ma opcji ręcznego zgłoszenia reindeksacji, nie ma przycisku „Poproś o indeksowanie” w konsoli, dlatego proaktywne monitorowanie i optymalizacja są niezbędne. Presja, by od razu zrobić wszystko dobrze, nigdy nie była większa.
Monitoring w Czasie Rzeczywistym vs. Zaplanowane Crawlery
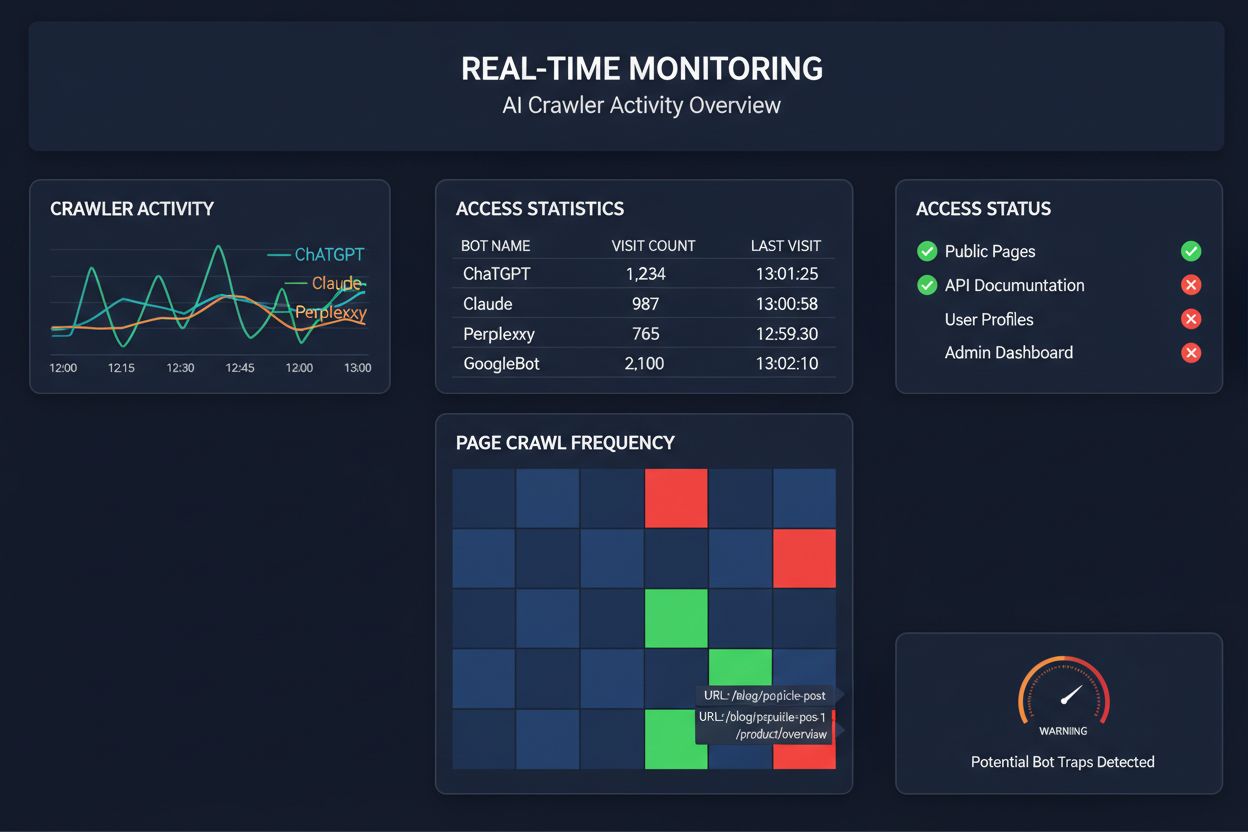
Poleganie na zaplanowanych crawlach, by monitorować dostęp crawlerów AI, to jak sprawdzanie domu pod kątem pożaru raz w miesiącu—przegapisz kluczowe momenty, gdy pojawią się problemy. Monitoring w czasie rzeczywistym wykrywa problemy natychmiast, pozwalając zareagować, zanim Twoje treści staną się niewidoczne dla systemów AI. Zaplanowane audyty, wykonywane zwykle tygodniowo lub miesięcznie, tworzą niebezpieczne luki, w których Twoja strona może nie spełniać wymogów AI przez wiele dni bez Twojej wiedzy. Rozwiązania w czasie rzeczywistym śledzą zachowanie crawlerów nieprzerwanie, informując o błędach renderowania JavaScript, problemach z oznaczeniami schema, blokadach firewalli czy błędach serwera w momencie ich wystąpienia. Takie proaktywne podejście zmienia audyt z reaktywnej kontroli zgodności w aktywne zarządzanie widocznością. Przy ruchu crawlerów AI nawet 100 razy większym niż tradycyjnych wyszukiwarek, koszt utraty nawet kilku godzin dostępności może być znaczny.
Narzędzia i Rozwiązania do Audytu AI Crawlerów
Obecnie dostępnych jest kilka platform oferujących specjalistyczne narzędzia do monitorowania i optymalizacji dostępu crawlerów AI. Cloudflare AI Crawl Control zapewnia zarządzanie ruchem botów AI na poziomie infrastruktury, pozwalając ustalać limity żądań i polityki dostępu. Conductor oferuje rozbudowane panele monitoringu, śledzące interakcje różnych crawlerów AI z Twoimi treściami. Elementive specjalizuje się w technicznych audytach SEO z naciskiem na wymagania crawlerów AI. AdAmigo i MRS Digital świadczą specjalistyczne konsultacje i monitoring widoczności AI. Jednak w przypadku ciągłego, monitoringu w czasie rzeczywistym, stworzonego specjalnie do śledzenia wzorców dostępu crawlerów AI i ostrzegania o problemach zanim wpłyną one na widoczność, AmICited wyróżnia się jako dedykowane rozwiązanie. AmICited specjalizuje się w monitorowaniu, które systemy AI mają dostęp do Twoich treści, jak często crawlowały i czy napotykają bariery techniczne. Ta specjalizacja w zachowaniach crawlerów AI—zamiast tradycyjnych metryk SEO—czyni z niego niezbędne narzędzie dla organizacji poważnie podchodzących do widoczności w AI.
Proces Audytu Krok po Kroku
Przeprowadzenie kompleksowego audytu AI crawlera wymaga systematycznego podejścia. Krok 1: Ustal stan wyjściowy sprawdzając obecny plik robots.txt i identyfikując, którym botom AI obecnie pozwalasz lub blokujesz dostęp. Krok 2: Audyt infrastruktury technicznej poprzez testowanie dostępności strony dla crawlerów nieobsługujących JavaScript, sprawdzenie czasów odpowiedzi serwera i weryfikację, czy kluczowe treści są serwowane w statycznym HTML. Krok 3: Wdrożenie i walidacja oznaczeń schema w całej treści, upewniając się, że autorstwo, daty publikacji, typ treści i inne metadane są prawidłowo ustrukturyzowane w formacie JSON-LD. Krok 4: Monitoring zachowania crawlerów za pomocą narzędzi takich jak AmICited, aby śledzić, które boty AI odwiedzają stronę, jak często i czy napotykają błędy. Krok 5: Analiza wyników przez przegląd logów crawlów, identyfikację wzorców awarii i priorytetyzację poprawek według wpływu. Krok 6: Wdrażanie poprawek zaczynając od najważniejszych problemów, takich jak błędy renderowania JavaScript czy brakujące oznaczenia schema, a następnie przechodząc do optymalizacji drugiego rzędu. Krok 7: Ustanowienie stałego monitoringu, aby wychwytywać nowe problemy, zanim wpłyną na widoczność, ustawiając alerty dla błędów crawlów lub blokad dostępu.
Szybkie Sposoby na Poprawę Crawlability AI
Nie musisz całkowicie przebudowywać strony, by poprawić dostęp crawlerów AI—kilka zmian o dużym wpływie możesz wdrożyć szybko. Serwuj kluczowe treści w czystym HTML, zamiast polegać na renderowaniu JavaScript; jeśli musisz korzystać z JavaScriptu, zadbaj, by ważne teksty i metadane były również dostępne w początkowym ładunku HTML. Dodaj kompletne oznaczenia schema w formacie JSON-LD, w tym schema artykułu, informacje o autorze, daty publikacji i relacje między treściami—ułatwia to crawlerom AI zrozumienie kontekstu i prawidłowe przypisanie treści. Zapewnij wyraźne informacje o autorstwie poprzez schema i podpisy, ponieważ systemy AI coraz częściej preferują cytowanie autorytatywnych źródeł. Monitoruj i optymalizuj Core Web Vitals (Largest Contentful Paint, First Input Delay, Cumulative Layout Shift), ponieważ wolno ładujące się strony mogą być opuszczane przez crawlery, zanim je przetworzą. Sprawdź i zaktualizuj swój robots.txt, by przypadkowo nie blokować botów AI, którym chcesz udostępnić treści. Napraw problemy techniczne takie jak łańcuchy przekierowań, niedziałające linki czy błędy serwera, które mogą powodować porzucenie crawla w połowie.
Monitoring Różnych Botów AI
Nie wszystkie crawlery AI mają ten sam cel, a zrozumienie tych różnic pozwala lepiej zarządzać dostępem. GPTBot (OpenAI) służy głównie do zbierania danych treningowych i ulepszania modeli, więc jest istotny, jeśli chcesz, by Twoje treści wpływały na odpowiedzi ChatGPT. OAI-SearchBot (OpenAI) crawl’uje wyłącznie na potrzeby cytowań w wynikach wyszukiwania, czyli odpowiada za pojawianie się Twoich treści w zintegrowanych wynikach wyszukiwania ChatGPT. ClaudeBot (Anthropic) pełni podobną rolę dla Claude, asystenta AI firmy Anthropic. PerplexityBot (Perplexity) crawl’uje na potrzeby cytowania w wyszukiwarce Perplexity, która stała się ważnym źródłem ruchu dla wielu wydawców. Każdy bot ma inne wzorce crawlów, częstotliwość i cele—niektóre skupiają się na danych treningowych, inne na cytowaniach w czasie rzeczywistym. Decyzja, którym botom pozwolić, a które blokować, powinna być zgodna z Twoją strategią treści: jeśli zależy Ci na cytowaniach w wynikach AI, pozwól na dostęp botom wyszukiwania; jeśli martwisz się wykorzystaniem treści do trenowania modeli, możesz blokować boty zbierające dane, a pozwalać wyszukiwawczym. Takie zniuansowane zarządzanie botami jest dużo bardziej zaawansowane niż tradycyjne „pozwól wszystkim” lub „blokuj wszystkich”.
Najczęściej zadawane pytania
Czym jest audyt AI crawlera?
Audyt AI crawlera to kompleksowa ocena dostępności Twojej strony dla botów AI takich jak ChatGPT, Claude i Perplexity. Identyfikuje techniczne blokady, problemy z renderowaniem JavaScript, brakujące oznaczenia schema oraz inne czynniki uniemożliwiające crawlerom AI dostęp i zrozumienie Twoich treści. Audyt dostarcza praktycznych rekomendacji poprawiających widoczność w wyszukiwarkach i silnikach odpowiedzi opartych na AI.
Jak często powinienem przeprowadzać audyt dostępu AI crawlerów na mojej stronie?
Zalecamy przeprowadzanie kompleksowego audytu co najmniej raz na kwartał lub za każdym razem, gdy wprowadzasz istotne zmiany w infrastrukturze technicznej strony, strukturze treści lub pliku robots.txt. Jednak idealnym rozwiązaniem jest stałe monitorowanie w czasie rzeczywistym, aby natychmiast wychwytywać pojawiające się problemy. Wiele organizacji korzysta z automatycznych narzędzi monitorujących, które na bieżąco powiadamiają o błędach w crawlach, uzupełnianych kwartalnymi, pogłębionymi audytami.
Jaka jest różnica między blokowaniem a zezwalaniem crawlerom AI?
Zezwolenie crawlerom AI oznacza, że Twoje treści mogą być dostępne, analizowane i potencjalnie cytowane przez systemy AI, co zwiększa Twoją widoczność w AI-generowanych odpowiedziach i rekomendacjach. Blokowanie crawlerów AI uniemożliwia im dostęp do Twoich treści, chroniąc informacje zastrzeżone, ale jednocześnie potencjalnie ograniczając widoczność w wynikach wyszukiwania AI. Właściwy wybór zależy od celów biznesowych, wrażliwości treści i pozycji konkurencyjnej.
Czy mogę zablokować wybrane boty AI, a innym pozwolić na dostęp?
Tak, jak najbardziej. Twój plik robots.txt pozwala na szczegółową kontrolę przez reguły User-Agent. Możesz zablokować GPTBot, zezwalając jednocześnie PerplexityBot, albo zezwolić na dostęp botom ukierunkowanym na wyszukiwanie (takim jak OAI-SearchBot), jednocześnie blokując boty zbierające dane (jak GPTBot). Takie zniuansowane podejście pozwala zoptymalizować strategię treści w zależności od tego, które platformy AI są najważniejsze dla Twojego biznesu.
Co oznacza, jeśli crawlerzy AI nie mają dostępu do moich treści?
Jeśli crawlerzy AI nie mają dostępu do Twoich treści, oznacza to, że Twoja strona jest praktycznie niewidoczna dla wyszukiwarek i platform odpowiedzi opartych na AI. Twoje treści nie będą cytowane, polecane ani uwzględniane w AI-generowanych odpowiedziach, nawet jeśli są bardzo wartościowe. Może to skutkować utratą ruchu, zmniejszoną widocznością marki i utraconymi szansami na budowanie autorytetu w wynikach AI.
Jak sprawdzić, które boty AI odwiedzają moją stronę?
Możesz przejrzeć logi serwera pod kątem User-Agent znanych crawlerów AI (GPTBot, ClaudeBot, PerplexityBot itp.) lub skorzystać ze specjalistycznych narzędzi monitorujących, takich jak AmICited, które śledzą aktywność AI crawlerów w czasie rzeczywistym. Narzędzia te pokazują, które boty odwiedzają Twoją stronę, jak często crawlowały, które podstrony przeglądały i czy napotkały błędy lub blokady.
Czy powinienem blokować crawlerów AI na mojej stronie?
To zależy od Twojej sytuacji. Jeśli Twoje treści są zastrzeżone, wrażliwe lub obawiasz się wykorzystania ich do trenowania modeli, blokowanie może być odpowiednie. Jednak jeśli zależy Ci na widoczności w wynikach AI i cytacjach przez systemy AI, zezwolenie crawlerom jest kluczowe. Wiele organizacji wybiera rozwiązanie pośrednie: pozwalają na dostęp botom wyszukiwawczym, które generują cytowania, blokując jednocześnie boty zbierające dane.
Jaki wpływ ma JavaScript na dostęp crawlerów AI?
Crawlerzy AI nie renderują JavaScript, co oznacza, że wszelkie treści ładowane dynamicznie przez skrypty po stronie klienta są dla nich niewidoczne. Jeśli Twoja strona w dużej mierze polega na JavaScript do wyświetlania kluczowych treści, nawigacji czy danych strukturalnych, crawlerzy AI zobaczą jedynie surowy HTML i pominą istotne informacje. Może to znacząco wpłynąć na sposób, w jaki Twoje treści są rozumiane i prezentowane w odpowiedziach AI. Dostarczanie kluczowych treści w statycznym HTML jest niezbędne dla crawlability AI.
Monitoruj Dostęp AI Crawlerów z AmICited
Uzyskaj wgląd w czasie rzeczywistym w to, które boty AI mają dostęp do Twoich treści i jak widzą Twoją stronę. Rozpocznij darmowy audyt już dziś i zapewnij widoczność swojej marki we wszystkich platformach wyszukiwania AI.
Śledzenie aktywności AI crawlerów: Kompletny przewodnik monitorowania
Dowiedz się, jak śledzić i monitorować aktywność AI crawlerów na swojej stronie za pomocą logów serwera, narzędzi i najlepszych praktyk. Rozpoznawaj GPTBot, Cla...
Dowiedz się, jak identyfikować i monitorować AI crawler’y, takie jak GPTBot, ClaudeBot i PerplexityBot, w logach serwera. Kompletny przewodnik z przykładami use...
Jak zidentyfikować crawlery AI w logach serwera: Kompletny przewodnik po wykrywaniu
Dowiedz się, jak identyfikować i monitorować crawlery AI takie jak GPTBot, PerplexityBot i ClaudeBot w logach serwera. Poznaj ciągi user-agent, metody weryfikac...
8 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.