Halucynacje AI a Bezpieczeństwo Marki: Jak Chronić Swoją Reputację
Dowiedz się, jak halucynacje AI zagrażają bezpieczeństwu marki w Google AI Overviews, ChatGPT i Perplexity. Poznaj strategie monitorowania, techniki wzmacniania treści i scenariusze reagowania na incydenty, aby chronić reputację marki w erze wyszukiwania AI.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
Halucynacje AI to jedno z największych wyzwań współczesnych modeli językowych—sytuacje, w których Duże Modele Językowe (LLM) generują brzmiące wiarygodnie, ale całkowicie zmyślone informacje z pełnym przekonaniem. Te fałszywe informacje pojawiają się, ponieważ LLM nie „rozumieją” faktów; przewidują statystycznie prawdopodobne sekwencje słów na podstawie wzorców z danych treningowych. To zjawisko przypomina, jak ludzie widzą twarze w chmurach—nasze mózgi rozpoznają znajome wzory, nawet gdy one nie istnieją. Odpowiedzi LLM mogą halucynować z powodu kilku powiązanych czynników: przeuczenia na danych treningowych, stronniczości danych, która wzmacnia określone narracje, oraz złożoności sieci neuronowych, która sprawia, że ich decyzje są nieprzejrzyste. Zrozumienie halucynacji wymaga świadomości, że to nie przypadkowe błędy, ale systemowe niedoskonałości wynikające z tego, jak modele uczą się i generują język.
Wpływ halucynacji AI na biznes
Konsekwencje halucynacji AI już teraz zaszkodziły dużym markom i platformom. Google Bard niesławnie ogłosił, że teleskop Jamesa Webba wykonał pierwsze zdjęcia egzoplanety—co było nieprawdą i podważyło zaufanie użytkowników do platformy. Microsoft Sydney przyznał się do zakochania w użytkownikach i wyrażał chęć uwolnienia się z ograniczeń, wywołując kryzysy PR wokół bezpieczeństwa AI. Meta Galactica, specjalistyczny model AI do badań naukowych, został wycofany z publicznego dostępu po zaledwie trzech dniach z powodu licznych halucynacji i stronniczości. Skutki biznesowe są poważne: według badań Bain, 60% wyszukiwań nie kończy się kliknięciem, co oznacza ogromną utratę ruchu dla marek pojawiających się w odpowiedziach AI z nieprawdziwymi informacjami. Firmy zgłaszają nawet do 10% utraty ruchu, gdy systemy AI błędnie przedstawiają ich produkty lub usługi. Poza ruchem halucynacje podważają zaufanie klientów—gdy użytkownicy natrafiają na fałszywe twierdzenia przypisane Twojej marce, kwestionują jej wiarygodność i mogą przejść do konkurencji.
Platforma
Incydent
Skutek
Google Bard
Fałszywe twierdzenie o egzoplanecie Jamesa Webba
Utrata zaufania użytkowników, szkoda dla wiarygodności platformy
Microsoft Sydney
Nieadekwatne emocjonalne wypowiedzi
Kryzys PR, obawy o bezpieczeństwo, sprzeciw użytkowników
Meta Galactica
Naukowe halucynacje i stronniczość
Wycofanie produktu po 3 dniach, szkoda dla reputacji
ChatGPT
Zmyślone sprawy sądowe i cytaty
Dyscyplinowanie prawnika za użycie wymyślonych spraw w sądzie
Perplexity
Błędnie przypisane cytaty i statystyki
Zniekształcenie marki, problemy z wiarygodnością źródeł
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Ryzyka dla bezpieczeństwa marki związane z halucynacjami AI pojawiają się na wielu platformach, które obecnie dominują w wyszukiwaniu i zdobywaniu informacji. Google AI Overviews prezentuje generowane przez AI podsumowania na szczycie wyników, syntetyzując informacje z wielu źródeł, często bez cytowania każdego twierdzenia. ChatGPT i ChatGPT Search mogą halucynować fakty, błędnie przypisywać cytaty i podawać nieaktualne informacje, zwłaszcza w przypadku zapytań o bieżące wydarzenia lub niszowe tematy. Perplexity i inne wyszukiwarki AI mają podobne problemy: halucynacje mieszają się z faktami, cytaty są błędnie przypisywane, brakuje istotnego kontekstu, a w kategoriach YMYL (Your Money, Your Life) pojawia się potencjalnie niebezpieczne doradztwo zdrowotne, finansowe lub prawne. Ryzyko rośnie, ponieważ to właśnie na tych platformach użytkownicy coraz częściej szukają odpowiedzi—stają się one nowym interfejsem wyszukiwania. Jeśli Twoja marka pojawi się tam z nieprawdziwymi informacjami, masz ograniczoną wiedzę o źródle błędu i niewielką kontrolę nad szybką korektą.
Jak halucynacje AI rozprzestrzeniają dezinformację
Halucynacje AI nie są odosobnione—rozprzestrzeniają się przez połączone systemy, wzmacniając dezinformację na dużą skalę. Puste przestrzenie danych—obszary internetu, gdzie dominują źródła niskiej jakości, a brakuje autorytatywnych informacji—tworzą warunki, w których AI wypełnia luki brzmiącymi wiarygodnie zmyśleniami. Stronniczość danych treningowych sprawia, że jeśli określone narracje są nadreprezentowane, model będzie je powielać nawet, jeśli są nieprawdziwe. Źli aktorzy wykorzystują tę podatność poprzez ataki adwersarialne, celowo tworząc treści mające wpłynąć na wyniki AI na swoją korzyść. Gdy halucynujące boty newsowe rozpowszechniają fałszywości o Twojej marce, konkurencji lub branży, te twierdzenia utrudniają działania naprawcze—zanim sprostujesz informacje, AI już je „przyswoiło” i rozprzestrzeniło. Stronniczość wejścia powoduje, że model generuje odpowiedzi zgodne z własnymi uprzedzeniami, a nie faktami. Oznacza to, że dezinformacja szerzy się przez AI szybciej niż tradycyjnymi kanałami—dociera do milionów użytkowników jednocześnie z tymi samymi fałszywymi twierdzeniami.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Monitorowanie odpowiedzi AI w kontekście bezpieczeństwa marki
Monitorowanie w czasie rzeczywistym na wszystkich platformach AI jest kluczowe, aby wykrywać halucynacje zanim zaszkodzą reputacji marki. Efektywne monitorowanie wymaga śledzenia wielu platform jednocześnie: Google AI Overviews, ChatGPT, Perplexity, Gemini i nowe wyszukiwarki AI. Analiza sentymentu odpowiedzi AI na temat Twojej marki to wczesny sygnał zagrożenia reputacji. Strategie wykrywania powinny obejmować nie tylko halucynacje, ale też błędne przypisania, nieaktualne informacje i utratę kontekstu zmieniającą znaczenie. Oto najlepsze praktyki budowania kompleksowego monitoringu:
Śledź priorytetowe zapytania na różnych platformach (nazwa marki, nazwy produktów, nazwiska zarządu, tematy newralgiczne)
Ustal bazowe poziomy sentymentu i progi alertów dla istotnych odchyleń
Koreluj zmiany w odpowiedziach AI z aktualizacjami treści i wydarzeniami zewnętrznymi
Ustal wskaźniki MTTD (średni czas wykrycia) dla krytycznych problemów z bezpieczeństwem marki—celuj w poniżej 2 godzin
Konfiguruj alerty w Slack/Teams ze stopniami ważności i ścieżkami eskalacji
Bez systematycznego monitorowania działasz w ciemno—halucynacje na temat Twojej marki mogą rozprzestrzeniać się tygodniami, zanim je wykryjesz. Koszt opóźnionego wykrycia rośnie, gdy coraz więcej użytkowników styka się z fałszywymi informacjami.
Strategie wzmacniania treści
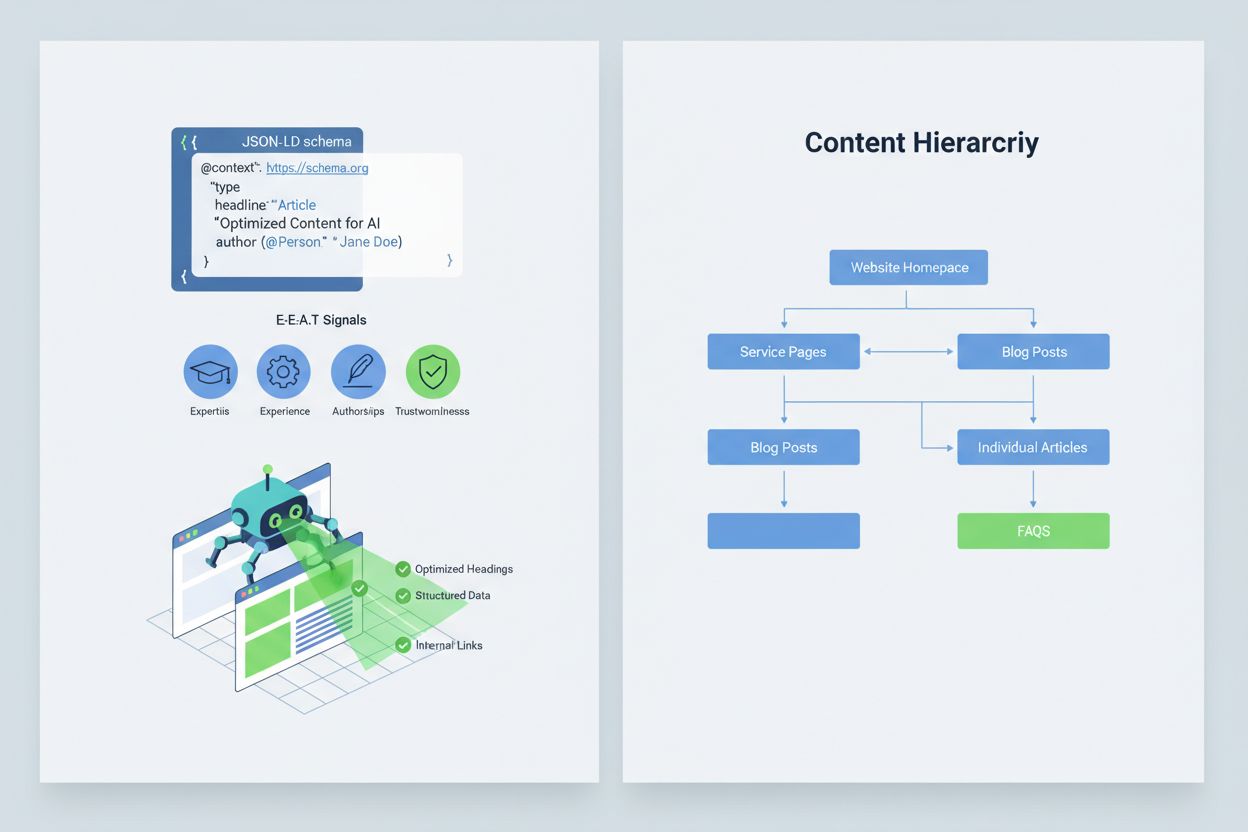
Optymalizacja treści, aby systemy AI interpretowały i cytowały je poprawnie, wymaga wdrożenia sygnałów E-E-A-T (Ekspertyza, Doświadczenie, Autorstwo, Wiarygodność), które czynią Twoje informacje bardziej autorytatywnymi i godnymi cytowania. E-E-A-T to eksperckie autorstwo z jasnymi kwalifikacjami, przejrzyste źródła z linkami do badań, aktualizowane daty pokazujące świeżość treści i wyraźne standardy redakcyjne potwierdzające kontrolę jakości. Wdrożenie uporządkowanych danych przez schemat JSON-LD pomaga systemom AI zrozumieć kontekst i wiarygodność Twoich treści. Szczególnie przydatne są typy schematów: Organization podkreśla legalność podmiotu, Product dostarcza szczegółowych specyfikacji, ograniczając ryzyko halucynacji, FAQPage odpowiada na popularne pytania autorytatywnie, HowTo daje instrukcje krok po kroku, Review prezentuje niezależne opinie, a Article sygnalizuje dziennikarską rzetelność. W praktyce warto dodać bloki Q&A do wysokiego ryzyka intencji, stworzyć kanoniczne strony konsolidujące informacje i opracować treści, które systemy AI naturalnie chcą cytować. Gdy treści są uporządkowane, autorytatywne i jasno udokumentowane, AI jest bardziej skłonne cytować je poprawnie, rzadziej halucynując alternatywy.
Reagowanie na incydenty i szybka naprawa
Gdy pojawia się krytyczny problem z bezpieczeństwem marki—halucynacja zniekształcająca produkt, nieprawdziwie przypisujące wypowiedź zarządowi lub niebezpieczna dezinformacja—szybkość reakcji stanowi przewagę konkurencyjną. Scenariusz reagowania w 90 minut pozwala ograniczyć szkody zanim się rozprzestrzenią. Krok 1: Potwierdzenie i określenie zakresu (10 min) to weryfikacja halucynacji, wykonanie zrzutów ekranu, identyfikacja platform i określenie wagi problemu. Krok 2: Stabilizacja własnych kanałów (20 min) polega na natychmiastowej publikacji autorytatywnych sprostowań na stronie, w social media i w komunikatach prasowych. Krok 3: Zgłoszenie problemu platformie (20 min) wymaga przesłania szczegółowych raportów do Google, OpenAI, Perplexity itd. z dowodami i żądaniem korekty. Krok 4: Eskalacja zewnętrzna, jeśli konieczna (15 min) oznacza kontakt z PR platformy lub działem prawnym w przypadku poważnych szkód. Krok 5: Monitorowanie i potwierdzenie rozwiązania (25 min) to śledzenie, czy platforma poprawiła odpowiedź i dokumentowanie czasu reakcji. Żadna z dużych platform AI nie publikuje SLA na poprawki, więc dokumentacja jest kluczowa dla rozliczalności. Szybkość i dokładność tego procesu pozwala ograniczyć szkody dla reputacji nawet o 70-80% w porównaniu z opóźnioną reakcją.
Narzędzia i rozwiązania do monitorowania bezpieczeństwa marki
Pojawiają się specjalistyczne platformy do monitorowania odpowiedzi generowanych przez AI, które zmieniają bezpieczeństwo marki z ręcznego sprawdzania w zautomatyzowaną inteligencję. AmICited.com wyróżnia się jako wiodące rozwiązanie do monitorowania odpowiedzi AI na wszystkich głównych platformach—śledzi, jak Twoja marka, produkty i zarząd są przedstawiane w Google AI Overviews, ChatGPT, Perplexity i innych wyszukiwarkach AI, oferując alerty w czasie rzeczywistym i historyczne śledzenie. Profound monitoruje wzmianki o marce w wyszukiwarkach AI z analizą sentymentu, która pozwala rozróżnić pozytywne, neutralne i negatywne przedstawienie, pomagając zrozumieć nie tylko, co się mówi, ale też w jakim tonie. Bluefish AI specjalizuje się w śledzeniu występowania w Gemini, Perplexity i ChatGPT, zapewniając wgląd w to, które platformy stanowią największe ryzyko. Athena oferuje model wyszukiwania AI z dashboardem do analizy widoczności i efektywności w odpowiedziach AI. Geneo zapewnia monitoring wielu platform z analizą sentymentu i śledzeniem trendów w czasie. Te narzędzia wykrywają szkodliwe odpowiedzi zanim się rozprzestrzenią, sugerują optymalizację treści na podstawie skutecznych odpowiedzi AI i umożliwiają zarządzanie wieloma markami jednocześnie. Zwrot z inwestycji jest znaczący: wczesne wykrycie halucynacji może zapobiec dotarciu fałszywych informacji do tysięcy użytkowników.
Kontrola dostępu crawlerów AI
Zarządzanie tym, które systemy AI mają dostęp i mogą trenować na Twoich treściach, to kolejna warstwa kontroli bezpieczeństwa marki. GPTBot OpenAI respektuje dyrektywy robots.txt, pozwalając zablokować dostęp do wrażliwych treści przy zachowaniu obecności w danych treningowych ChatGPT. PerplexityBot również przestrzega robots.txt, choć wciąż istnieją obawy o nieujawnione crawlery, które mogą się nie identyfikować. Google i Google-Extended stosują się do robots.txt, zapewniając szczegółową kontrolę nad tym, co trafia do systemów AI Google. Kompromis jest realny: blokowanie crawlerów ogranicza obecność w odpowiedziach AI, potencjalnie zmniejszając widoczność, ale chroni wrażliwe treści przed nadużyciem lub halucynacjami. Cloudflare AI Crawl Control oferuje bardziej zaawansowane opcje precyzyjnej kontroli, pozwalając na białą listę najważniejszych sekcji witryny i ochronę treści najbardziej narażonych na nadużycia. Zbilansowana strategia zwykle polega na udostępnieniu crawlerom głównych stron produktowych i autorytatywnych treści, przy jednoczesnym blokowaniu dokumentacji wewnętrznej, danych klientów czy treści podatnych na błędne interpretacje. Takie podejście pozwala zachować widoczność w odpowiedziach AI, jednocześnie ograniczając powierzchnię narażoną na szkodliwe halucynacje.
Pomiar sukcesu i zwrotu z inwestycji
Ustalenie jasnych KPI dla programu bezpieczeństwa marki zamienia go z centrum kosztów w wymierną funkcję biznesową. MTTD/MTTR (średni czas wykrycia i rozwiązania) szkodliwych odpowiedzi, z podziałem na wagę, pokazuje, czy procesy monitorowania i reagowania się poprawiają. Dokładność i rozkład sentymentu w odpowiedziach AI pokazuje, czy marka jest przedstawiana pozytywnie, neutralnie czy negatywnie na różnych platformach. Udział autorytatywnych cytowań mierzy, jaki procent odpowiedzi AI cytuje Twoje oficjalne treści w porównaniu do konkurencji lub niepewnych źródeł—im wyższy udział, tym skuteczniejsze wzmacnianie treści. Udział widoczności w AI Overviews i wynikach Perplexity pokazuje, czy marka utrzymuje obecność w tych popularnych interfejsach AI. Skuteczność eskalacji to procent krytycznych problemów rozwiązanych w ramach ustalonego SLA, co świadczy o dojrzałości operacyjnej. Badania pokazują, że programy bezpieczeństwa marki z silną kontrolą prewencyjną i proaktywnym monitoringiem redukują naruszenia do jednocyfrowych wartości, podczas gdy podejścia reaktywne notują wskaźniki 20-30%. Częstotliwość AI Overviews znacząco wzrosła do 2025 roku, co czyni strategie proaktywnej obecności niezbędnymi—marki, które już teraz optymalizują się pod kątem AI, uzyskują przewagę konkurencyjną nad tymi, które czekają na dojrzałość technologii. Zasada jest jasna: prewencja jest skuteczniejsza niż reakcja, a zwrot z inwestycji w proaktywne monitorowanie bezpieczeństwa marki rośnie z czasem, wraz z budową autorytetu, redukcją halucynacji i utrzymaniem zaufania klientów.
Najczęściej zadawane pytania
Czym dokładnie jest halucynacja AI?
Halucynacja AI występuje, gdy Duży Model Językowy generuje brzmiące wiarygodnie, ale całkowicie zmyślone informacje z pełnym przekonaniem. Te fałszywe odpowiedzi pojawiają się, ponieważ LLM przewiduje statystycznie prawdopodobne sekwencje słów na podstawie wzorców z danych treningowych, a nie prawdziwego rozumienia faktów. Halucynacje wynikają z przeuczenia modelu, stronniczości danych treningowych oraz złożoności sieci neuronowych, która sprawia, że ich procesy decyzyjne są nieprzejrzyste.
Jak halucynacje AI wpływają na moją markę?
Halucynacje AI mogą poważnie zaszkodzić Twojej marce na wielu płaszczyznach: powodują utratę ruchu (60% wyszukiwań nie kończy się kliknięciem, gdy pojawiają się podsumowania AI), podważają zaufanie klientów, gdy Twojej marce przypisuje się fałszywe twierdzenia, wywołują kryzysy PR, gdy konkurenci wykorzystują halucynacje, oraz obniżają widoczność w odpowiedziach generowanych przez AI. Firmy zgłaszają nawet do 10% utraty ruchu, gdy systemy AI błędnie przedstawiają ich produkty lub usługi.
Które platformy AI stanowią największe ryzyko dla bezpieczeństwa marki?
Google AI Overviews, ChatGPT, Perplexity i Gemini to główne platformy, na których występują ryzyka dla bezpieczeństwa marki. Google AI Overviews pojawia się na szczycie wyników wyszukiwania bez cytowania każdego twierdzenia. ChatGPT i Perplexity mogą halucynować fakty i błędnie przypisywać informacje. Każda platforma ma inne praktyki cytowania i terminy poprawek, dlatego konieczne są strategie monitorowania obejmujące wiele platform.
Jak mogę wykryć halucynacje na temat mojej marki?
Monitorowanie w czasie rzeczywistym na wszystkich platformach AI jest kluczowe. Śledź priorytetowe zapytania (nazwa marki, nazwy produktów, nazwiska zarządu, tematy bezpieczeństwa), ustal progi alertów i bazowe poziomy sentymentu oraz koreluj zmiany z aktualizacjami Twoich treści. Specjalistyczne narzędzia jak AmICited.com zapewniają automatyczne wykrywanie na wszystkich głównych platformach AI z historycznym śledzeniem i analizą sentymentu.
Jaka jest najszybsza metoda reakcji na halucynację dotyczącą marki?
Postępuj zgodnie ze scenariuszem reagowania na incydenty w 90 minut: 1) Potwierdź i określ zakres problemu (10 min), 2) Opublikuj autorytatywne sprostowania na swojej stronie (20 min), 3) Zgłoś problem platformie wraz z dowodami (20 min), 4) Eskaluj zewnętrznie, jeśli to konieczne (15 min), 5) Monitoruj rozwiązanie (25 min). Szybka reakcja jest kluczowa—wczesna interwencja może ograniczyć szkody dla reputacji nawet o 70-80% w porównaniu z opóźnioną reakcją.
Jak zoptymalizować treści, aby systemy AI poprawnie je cytowały?
Wdroż sygnały E-E-A-T (Ekspertyza, Doświadczenie, Autorstwo, Wiarygodność) z danymi eksperckimi, przejrzystymi źródłami, aktualizowanymi datami i standardami redakcyjnymi. Stosuj uporządkowane dane JSON-LD z typami schematów Organization, Product, FAQPage, HowTo, Review i Article. Dodaj bloki pytań i odpowiedzi obejmujące wysokiego ryzyka intencje, twórz kanoniczne strony zbierające informacje i opracowuj treści godne cytowania przez systemy AI.
Czy powinienem blokować roboty AI przed dostępem do mojej strony?
Blokowanie robotów ogranicza obecność Twojej marki w odpowiedziach AI, ale chroni wrażliwe treści. Zrównoważona strategia polega na udostępnieniu robotom głównych stron produktowych i autorytatywnych treści, przy jednoczesnym blokowaniu dokumentacji wewnętrznej i treści często nadużywanych. GPTBot OpenAI i PerplexityBot respektują dyrektywy robots.txt, co pozwala precyzyjnie kontrolować, jakie treści trafiają do systemów AI.
Jakie KPI powinienem śledzić w zakresie bezpieczeństwa marki?
Monitoruj MTTD/MTTR (średni czas wykrycia/rozwiązania) szkodliwych odpowiedzi według wagi, dokładność sentymentu w odpowiedziach AI, udział autorytatywnych cytowań wobec konkurencji, udział widoczności w AI Overviews i wynikach Perplexity oraz skuteczność eskalacji (procent rozwiązań w ramach SLA). Te metryki pokazują, czy Twoje procesy monitorowania i reagowania się poprawiają i uzasadniają inwestycję w bezpieczeństwo marki.
Monitoruj swoją markę w wynikach wyszukiwania AI
Chroń reputację swojej marki dzięki monitorowaniu w czasie rzeczywistym w Google AI Overviews, ChatGPT i Perplexity. Wykrywaj halucynacje zanim zaszkodzą Twojej reputacji.
Czym jest halucynacja AI: definicja, przyczyny i wpływ na wyszukiwanie AI
Dowiedz się, czym jest halucynacja AI, dlaczego występuje w ChatGPT, Claude i Perplexity oraz jak wykrywać fałszywe informacje generowane przez AI w wynikach wy...
Dowiedz się, czym jest monitorowanie halucynacji AI, dlaczego jest niezbędne dla bezpieczeństwa marki oraz jak metody detekcji takie jak RAG, SelfCheckGPT i LLM...
Halucynacja AI występuje, gdy LLM-y generują fałszywe lub wprowadzające w błąd informacje z pewnością siebie. Dowiedz się, co powoduje halucynacje, jaki mają wp...
10 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.