Tworzenie oryginalnych danych, które AI chce cytować
Dowiedz się, jak tworzyć oryginalne dane i badania, które systemy AI aktywnie cytują. Odkryj strategie, które sprawią, że Twoje dane będą widoczne dla ChatGPT, Perplexity, Google Gemini i Claude, budując trwałą widoczność w AI.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
W epoce sztucznej inteligencji oryginalne dane stają się nową przewagą konkurencyjną dla marek poszukujących widoczności wykraczającej poza tradycyjne pozycje w wyszukiwarce. W miarę jak platformy AI, takie jak ChatGPT, Perplexity, Google Gemini i Claude, coraz częściej pośredniczą w odkrywaniu informacji przez odbiorców, zasady budowania widoczności zmieniły się fundamentalnie. Zamiast rywalizować o pozycję zero w wynikach Google, organizacje muszą teraz tworzyć dane, które systemy AI aktywnie chcą cytować i przywoływać. Ta transformacja odzwierciedla szerszą zmianę z SEO opartego na treściach na tzw. “Generative Engine Optimization” (GEO), gdzie cytowanie przez AI zastąpiło tradycyjne pozycje jako główny wskaźnik widoczności. Platformy syntezujące informacje w bezpośrednie odpowiedzi — czy to przez retrieval-augmented generation (RAG), czy natywną syntezę modelową — z natury preferują źródła dostarczające jasnych, możliwych do wydobycia i autorytatywnych oryginalnych badań. Organizacje, które rozumieją tę zmianę i inwestują w tworzenie oryginalnych danych, autorskich badań i unikalnych spostrzeżeń, mają szansę zdobywać cytowania równocześnie na wielu platformach AI, budując rozpoznawalność i wiarygodność wśród odbiorców, którzy mogą nigdy nie zobaczyć tradycyjnych wyników wyszukiwania.
Jak systemy AI odkrywają i cytują dane
Różne platformy AI wykorzystują zasadniczo odmienne architektury do odkrywania i cytowania źródeł, co bezpośrednio wpływa na to, jak Twoje oryginalne dane są uwidaczniane i przypisywane. Zrozumienie tych mechanizmów jest kluczowe dla optymalizacji widoczności treści w krajobrazie AI. Różnica między natywną syntezą modelu (AI generuje odpowiedzi na podstawie wzorców z danych treningowych) a retrieval-augmented generation (AI przeszukuje aktualne źródła i syntezuje z wyników) wyjaśnia, dlaczego niektóre platformy podają jawne cytowania, a inne udzielają odpowiedzi bez atrybucji. Platformy korzystające z systemów RAG mogą powiązać swoje odpowiedzi z konkretnymi źródłami, co czyni cytowanie prostym i śledzonym. Natomiast systemy model-native polegają na probabilistycznej wiedzy zdobytej podczas treningu, przez co przypisanie źródła jest trudne lub niemożliwe bez dodatkowych wtyczek czy integracji.
Platforma AI
Metoda cytowania
Priorytet źródła danych
Wpływ na widoczność
ChatGPT
Natywny model (domyślnie); cytowania z wtyczkami/włączonym przeglądaniem
Dane treningowe + aktualny web gdy włączone; priorytet dla najnowszych i autorytatywnych źródeł przy aktywnym retrieval
Niska bez wtyczek; umiarkowana przy włączonym wyszukiwaniu; cytowania pojawiają się w tekście odpowiedzi gdy dostępne
Perplexity
Retrieval-first z cytowaniami numerowanymi inline
Wyniki wyszukiwania w sieci; priorytet świeżych, bezpośrednio powiązanych źródeł; nacisk na widoczność źródła
Wysoka; numerowane cytowania z linkami do źródeł; źródła z pierwszej pozycji otrzymują nieproporcjonalnie duży ruch
Indeksowane strony + encje Knowledge Graph; priorytet dla stron ze strukturą danych i sygnałami E-E-A-T
Wysoka; cytowania jako linki źródłowe w AI Overviews; dane strukturalne zwiększają szansę cytowania
Claude
Natywny model (domyślnie); funkcje wyszukiwania wdrażane w 2025 r.
Dane treningowe + selektywne wyszukiwanie w sieci; priorytet dla źródeł bezpiecznych, autorytatywnych
Umiarkowana; cytowania pojawiają się przy włączonym web search; nacisk na dokładność i wiarygodność źródła
Konsekwencje praktyczne są znaczące: platformy takie jak Perplexity i Google Gemini, które aktywnie przeszukują sieć, mogą cytować Twoje treści natychmiast po publikacji, o ile spełniają one ich standardy jakości i trafności. ChatGPT i Claude, które bardziej polegają na danych treningowych, mogą włączać oryginalne badania później, ale oferują inne możliwości widoczności przez wtyczki i integracje. Dla twórców treści oznacza to konieczność zrozumienia, z jakich platform korzysta grupa docelowa i optymalizację danych stosownie do tego — czy to poprzez zapewnienie możliwych do wydobycia, dobrze ustrukturyzowanych treści dla Perplexity, czy budowanie sygnałów autorytetu wpływających na dobór danych treningowych w systemach natywnych.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Dane strukturalne przekształciły się z dodatku SEO w strategiczną konieczność dla widoczności w AI. Wdrażając schema markup oparty o Schema.org, nie tylko pomagasz Google zrozumieć swoją treść — tworzysz warstwę czytelną dla maszyn, na której systemy AI mogą wiarygodnie opierać odpowiedzi. Ta warstwa danych, nazywana często “grafem wiedzy treści”, jawnie definiuje encje (osoby, produkty, usługi, lokalizacje, organizacje) i relacje między nimi, co radykalnie ułatwia systemom AI zrozumienie, czym jest Twoja marka, co oferuje i jak powinna być interpretowana. Zgodnie z najnowszymi badaniami BrightEdge, strony z rozbudowanym schema markup mają wyższy wskaźnik cytowań w AI Overviews Google, co sugeruje, że dane strukturalne bezpośrednio wpływają na prawdopodobieństwo cytowania. Powstający Model Context Protocol (MCP), wdrażany przez OpenAI i Google DeepMind, jest kolejnym krokiem — funkcjonuje jak standardowe API do łączenia modeli AI ze źródłami danych strukturalnych. Wdrażając schema markup na szeroką skalę, firmy tworzą fundament, który ogranicza halucynacje w odpowiedziach AI, poprawia ich osadzenie w faktach i zwiększa odnajdywalność danych w systemach retrieval. To szczególnie ważne, ponieważ systemy AI trenowane na nieustrukturyzowanych tekstach często mają problemy z precyzją; dane strukturalne zapewniają jasność kontekstu, umożliwiając LLM generowanie bardziej wiarygodnych, przypisywalnych odpowiedzi i pewne cytowanie Twoich oryginalnych badań.
Tworzenie danych, które systemy AI chcą cytować
Najskuteczniejszą strategią zdobywania cytowań AI jest tworzenie oryginalnych danych, które są z natury możliwe do wydobycia, autorytatywne i zgodne z tym, jak AI pozyskuje i syntezuje informacje. Zamiast liczyć, że Twoje istniejące treści zostaną zacytowane, musisz celowo projektować produkty danych, które platformy AI mogą łatwo odkryć, zrozumieć i przywołać. Oto kluczowe strategie tworzenia danych godnych cytowania:
Prowadź oryginalne badania z przejrzystą metodologią: Systemy AI priorytetyzują źródła prezentujące rzetelne praktyki badawcze. Publikuj badania, ankiety i analizy z jasno udokumentowaną metodologią, wielkością próby i ograniczeniami. Pokazując swój proces, umożliwiasz AI pewne cytowanie Twoich wyników jako autorytatywnych. Przykłady to branżowe benchmarki, analizy zachowań klientów, badania rynku i autorskie analizy danych, których konkurencja nie jest w stanie powtórzyć.
Uczyń dane możliwymi do wydobycia przez formaty strukturalne: Systemy AI preferują treści zorganizowane w tabele, listy, matryce porównawcze i pary pytań/odpowiedzi zamiast gęstych akapitów. Tabela porównawcza cech konkurencji ma większą szansę na cytowanie niż te same informacje ukryte w prozie. Używaj nagłówków, punktów i hierarchii wizualnych, które umożliwiają szybkie skanowanie i wydobycie kluczowych wniosków przez systemy AI.
Zadbaj o aktualność danych i sygnały świeżości: Platformy AI, szczególnie korzystające z live web retrieval, priorytetyzują aktualne informacje. Dodaj widoczne daty publikacji, znaczniki aktualizacji i regularnie odświeżaj treści. Pokazując, że Twoje dane są aktualne i utrzymywane, budujesz ich wiarygodność dla AI. To kluczowe zwłaszcza w przypadku danych wrażliwych na czas, jak ceny, statystyki czy trendy rynkowe.
Buduj autorytet autora i marki: Systemy AI oceniają wiarygodność źródła przed cytowaniem. Buduj jasne kwalifikacje autora (bio z odpowiednim doświadczeniem), autorytet organizacji (linki zwrotne, wzmianki w mediach, uznanie branżowe) i sygnały eksperckości domenowej. Gdy Twoja marka jest uznana za autorytet w danej kategorii, systemy AI cytują ją częściej i bardziej widocznie.
Stosuj jasne definicje i relacje encji: Zdefiniuj kluczowe encje wyraźnie — Twoją firmę, produkty, usługi, członków zespołu i pojęcia branżowe. Używaj danych strukturalnych do określenia relacji między tymi encjami. Gdy system AI dokładnie rozumie, czym jesteś i jak się odnosisz do szerszych pojęć branżowych, może cytować Cię precyzyjniej i w odpowiednim kontekście.
Zapewnij właściwą atrybucję i źródłowanie: Jeśli Twoje oryginalne dane bazują na innych źródłach, cytuj je transparentnie. Systemy AI rozpoznają i nagradzają źródła przyznające się do własnych źródeł. Tworzysz w ten sposób łańcuch atrybucji, który zwiększa zaufanie i szansę cytowania w całym ekosystemie.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Pomiar i optymalizacja pod kątem cytowania przez AI
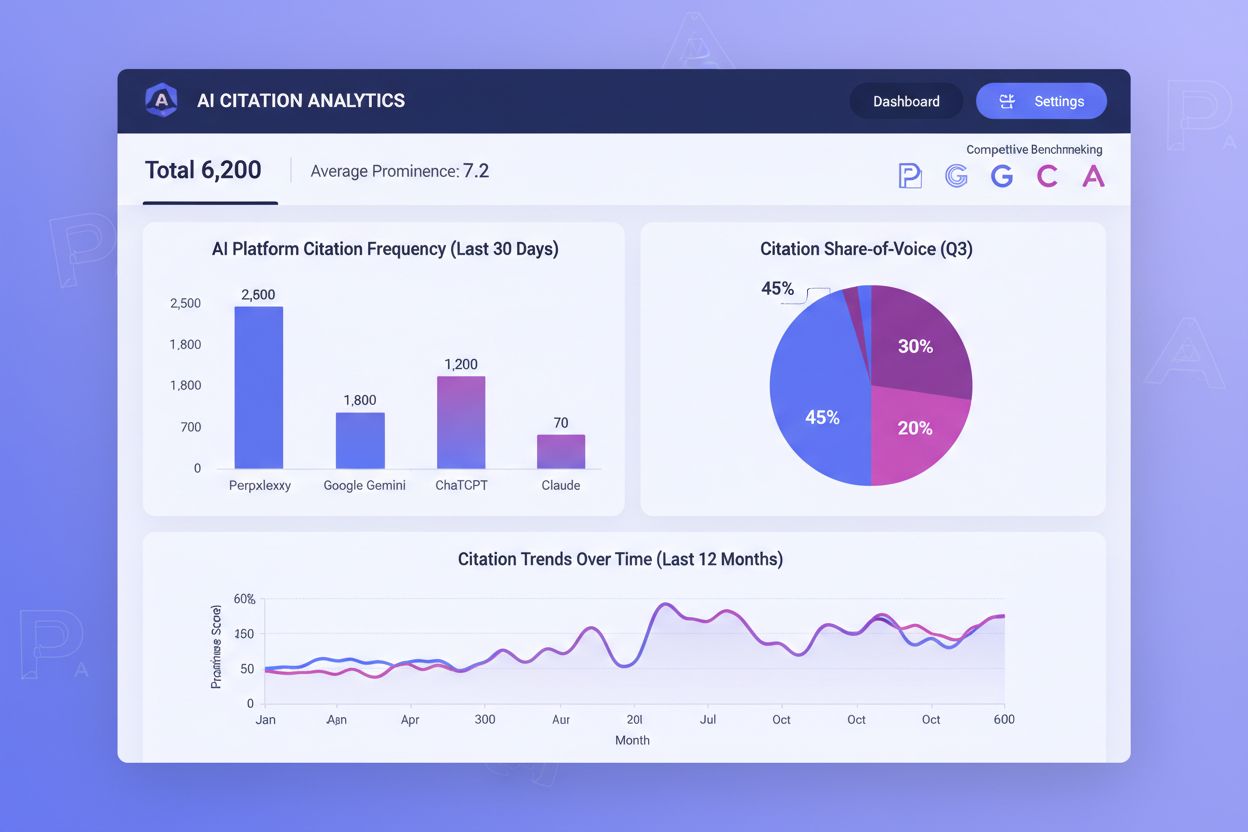
Śledzenie cytowań przez AI jest dziś równie ważne jak monitoring tradycyjnych pozycji w wyszukiwarce, ale większość organizacji nie widzi, jak często ich treści są cytowane na platformach AI. Częstotliwość cytowania, widoczność cytowania i share-of-voice to trzy główne metryki określające Twój sukces w AI-mediated discovery. Częstotliwość cytowania mierzy, jak często Twoje treści pojawiają się w odpowiedziach AI na Twoje zapytania — jeśli jesteś cytowany w 40% istotnych promptów, a konkurenci w 60%, masz wyraźną lukę optymalizacyjną. Jeszcze ważniejsza jest widoczność cytowania: cytat na pierwszej pozycji w numerowanej liście Perplexity daje nieproporcjonalnie większą widoczność niż cytowanie na piątej pozycji. Share-of-voice pokazuje Twoją pozycję konkurencyjną — jeśli Twoja marka uzyskuje cytowania w 25% kluczowych zapytań, a konkurent w 50%, tracisz znaczącą widoczność.
Narzędzia takie jak AmICited.com stają się niezbędne do monitorowania cytowań AI na różnych platformach. Te platformy śledzą, które Twoje strony zdobywają cytowania w Perplexity, Google AI Overviews, ChatGPT z wyszukiwaniem i innych systemach AI, pokazując, które treści skutecznie budują widoczność w AI. Monitorując wzorce cytowań w czasie, możesz zidentyfikować, które typy, tematy i formaty treści generują najwięcej cytowań i replikować te strategie. Benchmarking konkurencyjny w tych narzędziach pokazuje, gdzie przegrywasz cytowania z konkurencją, umożliwiając precyzyjną optymalizację. Dane ujawniają, czy problem z cytowaniem dotyczy wszystkich platform AI czy tylko wybranych — jeśli jesteś często cytowany w Perplexity, ale rzadko w Google AI Overviews, strategia optymalizacji powinna być odpowiednio inna. Metryki ważone pozycją rozpoznają, że cytowania na początku mają większą wartość; narzędzie, które waży cytowania z pierwszej pozycji mocniej niż niższe, daje bardziej użyteczne wskazówki niż surowe liczby cytowań. Traktując monitoring cytowań AI jako rdzeń strategii treści, możesz stale optymalizować oryginalne dane, zwiększając zarówno częstotliwość, jak i widoczność cytowań, bezpośrednio poprawiając swoją pozycję w świecie wyszukiwania napędzanego AI.
Budowanie trwałej strategii danych dla widoczności w AI
Tworzenie oryginalnych danych, które zdobywają cytowania AI, nie może być jednorazowym projektem — wymaga budowy zrównoważonej, międzydziałowej strategii danych, która traktuje dane jako kluczowy zasób wymagający stałych inwestycji i zarządzania. Organizacje osiągające sukces w AI wdrażają ustrukturyzowane procesy ciągłych aktualizacji danych, by oryginalne badania były zawsze aktualne i istotne. Oznacza to ustalenie regularnych cykli odświeżania kluczowych zestawów danych, aktualizowanie statystyk wraz z pojawianiem się nowych informacji oraz utrzymywanie sygnałów świeżości, które systemy AI wykorzystują do oceny wiarygodności źródła. Poza aktualizacjami treści, skuteczne organizacje synchronizują strategię danych w ramach marketingu, SEO, contentu, produktu i zespołów danych poprzez governance encji — wspólne definicje i taksonomie zapewniające spójne, dokładne przedstawienie marki, produktów i pojęć branżowych we wszystkich punktach styku.
Najbardziej zaawansowane podejście traktuje dane strukturalne i grafy wiedzy treści jako infrastrukturę na poziomie całego przedsiębiorstwa. Zamiast wdrażać schema markup na poszczególnych stronach, liderzy budują kompleksowe grafy wiedzy łączące wszystkie encje, tematy i relacje w swoich zasobach cyfrowych. Wymaga to zarówno kompetencji technicznych — narzędzi i procesów do zarządzania schema markup na dużą skalę — jak i organizacyjnej zgodności co do standardów jakości danych. Odpowiednio zbudowana infrastruktura spełnia podwójną rolę: zwiększa zewnętrzną widoczność w AI i umożliwia wewnętrzne inicjatywy AI. Według badania Gartnera “AI Mandates for the Enterprise Survey 2024”, dostępność i jakość danych to największa bariera wdrożeń AI; inwestując w dane strukturalne i governance encji jednocześnie rozwiązujesz problem widoczności zewnętrznej i możliwości AI wewnątrz firmy. Organizacje odnoszące sukcesy w AI traktują tworzenie oryginalnych danych nie jako taktykę marketingową, lecz jako kluczową kompetencję biznesową, z dedykowanymi zasobami, jasną odpowiedzialnością i nieustanną optymalizacją opartą na śledzeniu cytowań i benchmarkingu konkurencyjnym.
Najczęściej zadawane pytania
Jaka jest różnica między oryginalnymi danymi a zwykłymi treściami w kontekście cytowania przez AI?
Oryginalne dane to autorskie badania, unikalne zestawy danych i pierwotne wyniki, które stworzyłeś lub odkryłeś samodzielnie. Systemy AI priorytetyzują oryginalne dane, ponieważ dostarczają one autorytatywnych, możliwych do wydobycia informacji, które można z pewnością cytować. Zwykłe treści często syntetyzują istniejące informacje, przez co są mniej wartościowe dla cytowania przez AI. Oryginalne dane stają się podstawą widoczności w AI, ponieważ platformy takie jak Perplexity i Google Gemini aktywnie wyszukują i cytują źródła oferujące unikalne spostrzeżenia i badania.
Jak różne platformy AI odkrywają i cytują moje oryginalne dane?
Różne platformy AI korzystają z różnych mechanizmów odkrywania. Perplexity i Google Gemini używają retrieval-augmented generation (RAG), czyli przeszukują aktualny internet i mogą cytować Twoje treści od razu po publikacji. ChatGPT i Claude opierają się bardziej na danych treningowych, więc włączenie Twoich treści może potrwać dłużej, ale oferuje inne możliwości widoczności. Wszystkie platformy korzystają na danych strukturalnych (schema markup), które czynią Twoje dane zrozumiałymi dla maszyn i łatwiejszymi do interpretacji, zwiększając szansę na cytowanie.
Jaką rolę odgrywają dane strukturalne w cytowaniu przez AI?
Dane strukturalne wykorzystujące słownik Schema.org tworzą warstwę czytelną dla maszyn, na której systemy AI mogą wiarygodnie opierać swoje odpowiedzi. Wdrażając schema markup, jawnie definiujesz encje (Twoja firma, produkty, usługi) i ich relacje, co znacząco ułatwia systemom AI zrozumienie i prawidłowe cytowanie Twoich treści. Badania pokazują, że strony z rozbudowanym schema markup częściej są cytowane w AI Overviews. Dane strukturalne ograniczają także halucynacje, dostarczając AI jasnych, faktycznych informacji do odniesienia.
Jakie typy oryginalnych danych najczęściej są cytowane przez AI?
Systemy AI najczęściej cytują oryginalne badania z przejrzystą metodologią, autorskie zbiory danych, branżowe benchmarki, analizy zachowań klientów, analizy rynku oraz unikalne spostrzeżenia, których konkurenci nie mogą powielić. Dane przedstawione w przystępnych formatach — tabele, matryce porównawcze, listy i Q&A w stylu FAQ — są cytowane częściej niż te same informacje w gęstych akapitach. Świeże, aktualne dane z widoczną datą publikacji i regularnymi aktualizacjami są priorytetowane nad przestarzałymi informacjami. Sygnały autorytetu, takie jak kwalifikacje autora i uznanie organizacyjne, także zwiększają szansę na cytowanie.
Jak mogę zmierzyć, czy moje oryginalne dane są cytowane przez systemy AI?
Narzędzia takie jak AmICited.com śledzą cytowania przez AI na różnych platformach, pokazując jak często Twoje treści pojawiają się w odpowiedziach ChatGPT, Perplexity, Google AI Overviews i Claude. Te narzędzia mierzą częstotliwość cytowań (jak często jesteś cytowany), widoczność cytowania (pozycja w odpowiedzi) i share-of-voice (Twoje cytowania względem konkurencji). Monitorując te wskaźniki, możesz zidentyfikować, które typy treści i tematy generują najwięcej cytowań, a następnie zoptymalizować swoją strategię danych. Metryki ważone pozycją rozpoznają, że cytowania na pierwszej pozycji dają większą wartość niż te na dalszych pozycjach.
Jaka jest różnica między częstotliwością cytowania a widocznością cytowania?
Częstotliwość cytowania mierzy, jak często Twoje treści są cytowane w odpowiedziach AI na Twoje docelowe zapytania — jeśli jesteś cytowany w 40% odpowiednich promptów, to jest Twoja częstotliwość cytowania. Widoczność cytowania mierzy, gdzie pojawia się cytat — cytowanie na pierwszej pozycji w numerowanej liście Perplexity daje znacznie większą widoczność niż cytowanie na piątej pozycji. Oba wskaźniki są ważne dla widoczności w AI, ale widoczność często ma większe znaczenie, ponieważ użytkownicy chętniej klikają lub angażują się w cytaty pojawiające się na początku. Skuteczna optymalizacja wymaga poprawy obu wskaźników jednocześnie.
Jak często powinienem aktualizować oryginalne dane, aby zachować ich wartość dla cytowania przez AI?
Oryginalne dane powinny być aktualizowane zgodnie z harmonogramem odzwierciedlającym tempo zmian w Twojej branży. W szybko zmieniających się sektorach, jak technologia czy finanse, konieczne mogą być comiesięczne lub kwartalne aktualizacje. W wolniejszych branżach wystarczą aktualizacje roczne. Kluczowe są widoczne sygnały aktualności — daty publikacji, znaczniki aktualizacji i wskaźniki odświeżenia — które sygnalizują systemom AI, że Twoje dane są aktualne i wiarygodne. Regularne aktualizacje zwiększają także szanse na cytowanie przez systemy retrieval-based, takie jak Perplexity, które priorytetyzują świeże informacje. Traktuj utrzymanie danych jako stałą odpowiedzialność operacyjną, a nie jednorazowy projekt.
Czy mogę używać AmICited.com do śledzenia cytowań konkurencji?
Tak, AmICited.com oferuje funkcje benchmarkingu konkurencyjnego, które pokazują Twoje wyniki cytowań na tle zdefiniowanych konkurentów. Zobaczysz, którzy konkurenci są cytowani częściej, na wyższych pozycjach i na których platformach AI. Ta inteligencja konkurencyjna ujawnia, gdzie tracisz cytowania i jakie strategie optymalizacji mogą pomóc odzyskać przewagę. Rozumiejąc krajobraz cytowań konkurencji, możesz kierować swoje działania w tworzeniu i optymalizacji danych na najbardziej wpływowe obszary, zapewniając Twoim oryginalnym danym widoczność, na którą zasługują.
Monitoruj swoje cytowania przez AI już dziś
Śledź, jak często Twoje oryginalne dane są cytowane w ChatGPT, Perplexity, Google AI Overviews i innych platformach AI. Uzyskaj praktyczne wskazówki, jak zoptymalizować swoje treści dla maksymalnej widoczności w AI.
Dlaczego oryginalne badania są kluczowe dla widoczności i cytowań w AI
Dowiedz się, dlaczego tworzenie oryginalnych badań jest kluczowe dla widoczności w AI. Zobacz, jak oryginalne badania pomagają Twojej marce być cytowaną w odpow...
PR oparty na danych: Tworzenie badań, które AI chce cytować
Dowiedz się, jak tworzyć oryginalne badania i treści PR oparte na danych, które systemy AI aktywnie cytują. Odkryj 5 cech treści wartych cytowania oraz strategi...