
Ocena Trafności Treści
Dowiedz się, jak ocena trafności treści wykorzystuje algorytmy AI do mierzenia zgodności treści z zapytaniami i intencją użytkownika. Poznaj BM25, TF-IDF oraz j...
7 min czytania

AI Retrieval Scoring to proces ilościowego określania trafności i jakości wyszukanych dokumentów lub fragmentów w odniesieniu do zapytania użytkownika. Wykorzystuje zaawansowane algorytmy do oceny znaczenia semantycznego, kontekstowej adekwatności oraz jakości informacji, decydując, które źródła są przekazywane do modeli językowych w celu generowania odpowiedzi w systemach RAG.
AI Retrieval Scoring to proces ilościowego określania trafności i jakości wyszukanych dokumentów lub fragmentów w odniesieniu do zapytania użytkownika. Wykorzystuje zaawansowane algorytmy do oceny znaczenia semantycznego, kontekstowej adekwatności oraz jakości informacji, decydując, które źródła są przekazywane do modeli językowych w celu generowania odpowiedzi w systemach RAG.
AI Retrieval Scoring to proces ilościowego określania trafności i jakości wyszukanych dokumentów lub fragmentów w odniesieniu do zapytania lub zadania użytkownika. W przeciwieństwie do prostego dopasowania słów kluczowych, które rozpoznaje jedynie powierzchowne pokrycie terminów, ocenianie wyszukiwania wykorzystuje zaawansowane algorytmy do oceny znaczenia semantycznego, kontekstowej adekwatności oraz jakości informacji. Ten mechanizm oceniania jest podstawą systemów Retrieval-Augmented Generation (RAG), gdzie decyduje, które źródła są przekazywane do modeli językowych w celu generowania odpowiedzi. W nowoczesnych aplikacjach LLM ocenianie wyszukiwania bezpośrednio wpływa na dokładność odpowiedzi, ograniczenie halucynacji i satysfakcję użytkownika, zapewniając, że do etapu generowania trafiają tylko najbardziej relewantne informacje. Jakość procesu oceniania wyszukiwania stanowi zatem kluczowy element ogólnej wydajności i niezawodności systemu.
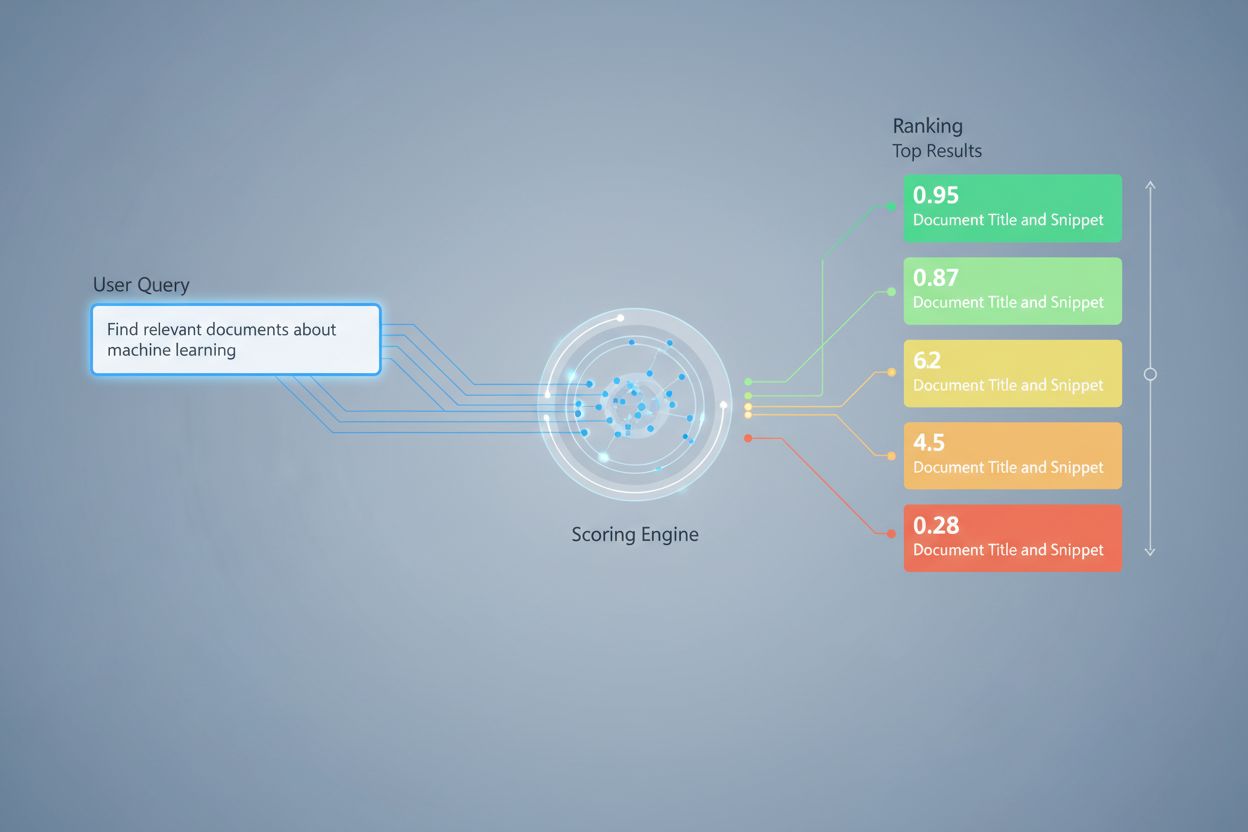
Ocenianie wyników wyszukiwania wykorzystuje wiele podejść algorytmicznych, z których każde ma inne mocne strony w różnych zastosowaniach. Ocenianie podobieństwa semantycznego używa modeli embeddingowych do pomiaru zgodności koncepcyjnej między zapytaniami a dokumentami w przestrzeni wektorowej, wychwytując sens poza dosłownymi słowami kluczowymi. BM25 (Best Matching 25) to probabilistyczna funkcja rankingowa, która uwzględnia częstotliwość terminów, odwrotną częstość dokumentów i normalizację długości dokumentu, przez co jest bardzo skuteczna w tradycyjnym wyszukiwaniu tekstu. TF-IDF (Term Frequency-Inverse Document Frequency) waży terminy na podstawie ich istotności w dokumentach i w całych zbiorach, choć nie rozumie semantyki. Podejścia hybrydowe łączą kilka metod—np. łącząc wyniki BM25 i ocen semantycznych—by wykorzystać zarówno sygnały leksykalne, jak i semantyczne. Poza metodami oceniania, metryki ewaluacyjne, takie jak Precision@k (odsetek trafnych wyników w top-k), Recall@k (odsetek wszystkich trafnych dokumentów znalezionych w top-k), NDCG (znormalizowany skumulowany zysk zdyskontowany, uwzględniający pozycję rankingową) oraz MRR (średnia odwrotna pozycja) dostarczają ilościowych miar jakości wyszukiwania. Zrozumienie mocnych i słabych stron każdego podejścia—np. wydajności BM25 kontra głębsze rozumienie ocen semantycznych—jest kluczowe przy wyborze odpowiednich metod do konkretnych zastosowań.
| Metoda oceniania | Jak działa | Najlepsza do | Kluczowa zaleta |
|---|---|---|---|
| Podobieństwo semantyczne | Porównuje embeddingi za pomocą cosinusowej lub innej miary odległości | Znaczenie koncepcyjne, synonimy, parafrazy | Wychwytuje relacje semantyczne poza słowami kluczowymi |
| BM25 | Probabilistyczny ranking uwzględniający częstotliwość terminów i długość dokumentu | Dopasowanie fraz, zapytania słów kluczowych | Szybka, wydajna, sprawdzona w produkcji |
| TF-IDF | Waży terminy według częstotliwości w dokumencie i rzadkości w kolekcji | Tradycyjne wyszukiwanie informacji | Prosta, interpretowalna, lekka |
| Ocenianie hybrydowe | Łączy podejścia semantyczne i słów kluczowych z ważonym połączeniem | Wyszukiwanie ogólne, złożone zapytania | Wykorzystuje zalety wielu metod |
| Ocenianie LLM | Wykorzystuje modele językowe do oceny trafności za pomocą promptów | Złożona ocena kontekstu, zadania domenowe | Wychwytuje niuanse semantyczne |
W systemach RAG ocenianie wyszukiwania działa na wielu poziomach, by zapewnić jakość generowanych odpowiedzi. System najczęściej ocenia indywidualne fragmenty lub akapity dokumentów, umożliwiając szczegółową ocenę trafności zamiast traktowania całych dokumentów jako jednostek. Takie ocenianie trafności na poziomie fragmentu pozwala wyodrębnić jedynie najbardziej istotne segmenty informacji, redukując szum i nieistotny kontekst, który mógłby zmylić model językowy. Systemy RAG często wdrażają progi ocen lub mechanizmy odcięcia, które filtrują wyniki o niskiej ocenie zanim trafią do etapu generowania, zapobiegając wpływowi źródeł niskiej jakości na ostateczną odpowiedź. Jakość pozyskanego kontekstu jest bezpośrednio skorelowana z jakością generowanej odpowiedzi—wysoko ocenione, relewantne fragmenty skutkują dokładniejszymi, ugruntowanymi odpowiedziami, podczas gdy słaba selekcja prowadzi do halucynacji i błędów merytorycznych. Monitorowanie ocen wyszukiwania daje wczesne sygnały degradacji systemu, przez co stanowi kluczową metrykę monitorowania odpowiedzi AI i zapewnienia jakości w środowiskach produkcyjnych.
Re-ranking to drugi etap filtrowania, który doprecyzowuje początkowe wyniki wyszukiwania, często znacząco poprawiając dokładność rankingu. Po wygenerowaniu przez retrievera kandydatów z wstępnymi ocenami, re-ranker stosuje bardziej zaawansowaną logikę oceniania, by przeorganizować lub przefiltrować te kandydaty, zwykle wykorzystując bardziej wymagające obliczeniowo modele pozwalające na głębszą analizę. Reciprocal Rank Fusion (RRF) to popularna technika, która łączy rankingi z wielu retrieverów, przypisując oceny na podstawie pozycji wyniku, a następnie łącząc je w jeden ranking, często przewyższający pojedyncze metody. Normalizacja ocen staje się kluczowa przy łączeniu rezultatów z różnych metod, gdyż surowe oceny BM25, podobieństwa semantycznego i innych podejść są w różnych skalach i muszą być dopasowane do porównywalnych zakresów. Podejścia zespołowe retrieverów wykorzystują wiele strategii wyszukiwania równocześnie, a re-ranking decyduje o ostatecznym ułożeniu na podstawie łącznych dowodów. Wieloetapowa strategia znacząco poprawia trafność i odporność rankingów w porównaniu do pojedynczego etapu, zwłaszcza w złożonych dziedzinach, gdzie różne metody uchwytują komplementarne sygnały trafności.
Precision@k: Mierzy odsetek trafnych dokumentów wśród top-k wyników; przydatna do oceny, czy wyniki są godne zaufania (np. Precision@5 = 4/5 oznacza, że 80% top-5 wyników jest trafnych)
Recall@k: Oblicza procent wszystkich trafnych dokumentów znalezionych w top-k; ważna dla zapewnienia pełnego pokrycia dostępnych istotnych informacji
Hit Rate: Metryka binarna wskazująca, czy przynajmniej jeden trafny dokument pojawił się w top-k wyników; użyteczna do szybkiej kontroli jakości w systemach produkcyjnych
NDCG (Normalized Discounted Cumulative Gain): Uwzględnia pozycję rankingową, przypisując wyższą wartość dokumentom trafnym pojawiającym się wcześniej; zakres od 0 do 1, idealna do oceny jakości rankingów
MRR (Mean Reciprocal Rank): Mierzy średnią pozycję pierwszego trafnego wyniku dla wielu zapytań; szczególnie przydatna do oceny, czy najbardziej trafny dokument jest wysoko w rankingu
F1 Score: Średnia harmoniczna precyzji i recall; zapewnia zbalansowaną ocenę, gdy fałszywie pozytywne i negatywne mają takie samo znaczenie
MAP (Mean Average Precision): Uśrednia precyzję dla każdej pozycji, gdzie znaleziono trafny dokument; kompleksowa metryka ogólnej jakości rankingów dla wielu zapytań
Ocenianie trafności oparte na LLM wykorzystuje same modele językowe jako sędziów trafności dokumentów, oferując elastyczną alternatywę dla tradycyjnych metod algorytmicznych. W tym podejściu starannie przygotowane prompty instruują LLM, by ocenił, czy pozyskany fragment odpowiada na dane zapytanie, generując oceny binarne (trafny/nietrafny) lub numeryczne (np. skala 1-5 określająca poziom trafności). Metoda ta wychwytuje niuanse semantyczne i specyficzną dla domeny trafność, które mogą umknąć tradycyjnym algorytmom, szczególnie przy złożonych zapytaniach wymagających głębokiego zrozumienia. Jednak ocenianie oparte na LLM wiąże się z wyzwaniami, takimi jak koszt obliczeniowy (wnioskowanie LLM jest droższe niż porównanie embeddingów), potencjalna niekonsekwencja między promptami i modelami oraz konieczność kalibracji z etykietami ludzkimi, by oceny odpowiadały rzeczywistej trafności. Mimo ograniczeń, ocenianie LLM jest cennym narzędziem do ewaluacji jakości systemów RAG i tworzenia danych treningowych dla specjalistycznych modeli oceniania, stanowiąc istotny element monitorowania jakości odpowiedzi AI.
Skuteczne wdrożenie oceniania wyników wyszukiwania wymaga uwzględnienia wielu praktycznych czynników. Wybór metody zależy od wymagań zastosowania: ocenianie semantyczne najlepiej wychwytuje znaczenie, lecz wymaga modeli embeddingowych, podczas gdy BM25 zapewnia szybkość i wydajność dla dopasowań leksykalnych. Kompromis między szybkością a dokładnością ma kluczowe znaczenie—ocenianie embeddingowe daje lepsze rozumienie trafności, ale wiąże się z większym opóźnieniem, zaś BM25 i TF-IDF są szybsze, ale mniej zaawansowane semantycznie. Koszty obliczeniowe obejmują czas inferencji modelu, zapotrzebowanie na pamięć oraz skalowanie infrastruktury, co jest szczególnie istotne w produkcyjnych systemach o wysokim wolumenie. Dostrajanie parametrów polega na regulacji progów, wag w podejściach hybrydowych i cutoffów re-rankingu, aby zoptymalizować wydajność dla określonych domen i zastosowań. Ciągłe monitorowanie wydajności oceniania za pomocą metryk takich jak NDCG i Precision@k pozwala wykryć degradację w czasie, umożliwiając proaktywne udoskonalenia systemu i zapewnienie stabilnej jakości odpowiedzi w produkcyjnych systemach RAG.
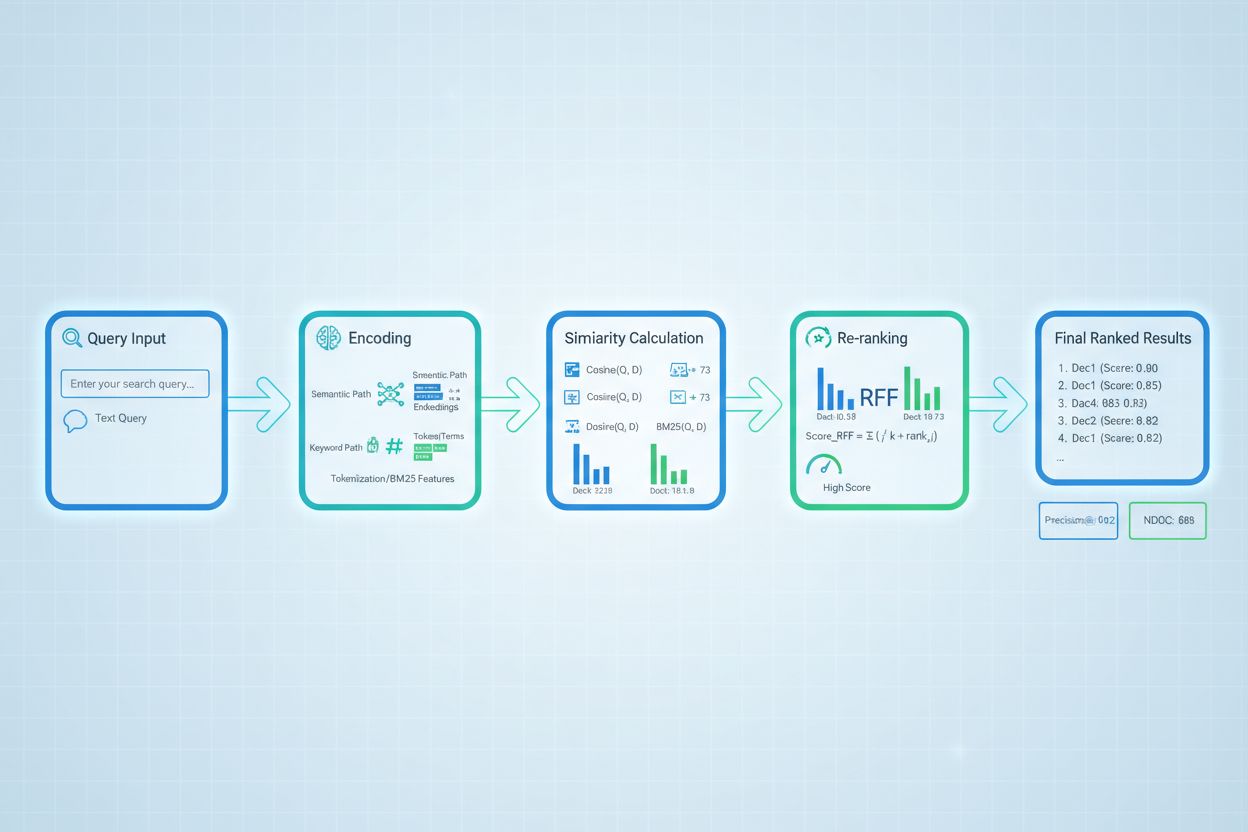
Zaawansowane techniki oceniania wyników wyszukiwania wykraczają poza podstawową ocenę trafności, by uchwycić złożone relacje kontekstowe. Przekształcanie zapytań może poprawić ocenianie poprzez reformulację pytań użytkownika w wiele semantycznie równoważnych wersji, co pozwala retrieverowi znaleźć istotne dokumenty, które mogłyby zostać pominięte przy dosłownym dopasowaniu. Hypothetical Document Embeddings (HyDE) generują syntetyczne, trafne dokumenty na podstawie zapytania, a następnie wykorzystują je do poprawy oceniania przez wyszukiwanie rzeczywistych dokumentów podobnych do idealizowanej, relewantnej treści. Podejścia wielozapytaniowe przesyłają do retrieverów kilka wariantów tego samego pytania i agregują ich wyniki, zwiększając odporność i pokrycie w porównaniu do pojedynczego zapytania. Modele oceniania dopasowane do domeny, wytrenowane na oznaczonych danych z określonych branż lub dziedzin wiedzy, osiągają lepsze wyniki od modeli ogólnego przeznaczenia, szczególnie w zastosowaniach specjalistycznych, takich jak systemy AI dla medycyny czy prawa. Kontekstowe modyfikacje ocen uwzględniają takie czynniki jak aktualność dokumentu, autorytet źródła czy kontekst użytkownika, umożliwiając bardziej zaawansowaną ocenę trafności, która wychodzi poza czystą semantykę i uwzględnia realne czynniki istotne dla AI produkcyjnego.
Ocena wyszukiwania przypisuje dokumentom numeryczne wartości trafności na podstawie ich powiązania z zapytaniem, natomiast ranking porządkuje dokumenty według tych ocen. Ocenianie to proces ewaluacji, ranking to rezultat uporządkowania. Oba są kluczowe dla systemów RAG, aby dostarczać precyzyjne odpowiedzi.
Ocena wyszukiwania decyduje, które źródła trafiają do modelu językowego w celu generowania odpowiedzi. Wysokiej jakości ocenianie zapewnia wybór istotnych informacji, ogranicza halucynacje i poprawia precyzję odpowiedzi. Słabe ocenianie prowadzi do nieistotnego kontekstu i zawodnych odpowiedzi AI.
Ocenianie semantyczne wykorzystuje embeddingi do zrozumienia znaczenia pojęciowego, wychwytuje synonimy i powiązane koncepcje. Ocenianie oparte na słowach kluczowych (np. BM25) dopasowuje dokładne terminy i frazy. Ocenianie semantyczne lepiej rozumie intencję, a ocenianie słów kluczowych sprawdza się przy wyszukiwaniu konkretnych informacji.
Kluczowe metryki to Precision@k (dokładność najlepszych wyników), Recall@k (pokrycie wszystkich istotnych dokumentów), NDCG (jakość rankingowa) i MRR (pozycja pierwszego istotnego wyniku). Wybierz metryki według zastosowania: Precision@k dla systemów nastawionych na jakość, Recall@k dla pełnego pokrycia.
Tak, ocenianie oparte na LLM wykorzystuje modele językowe jako sędziów trafności. Podejście to wychwytuje niuanse semantyczne, ale jest kosztowne obliczeniowo. Jest wartościowe przy ewaluacji jakości RAG i tworzeniu danych treningowych, choć wymaga kalibracji z etykietami ludzkimi.
Re-ranking stosuje drugie filtrowanie z użyciem bardziej zaawansowanych modeli, aby doprecyzować początkowe wyniki. Techniki takie jak Reciprocal Rank Fusion łączą wiele metod wyszukiwania, poprawiając trafność i odporność. Re-ranking znacząco przewyższa jednoetapowe wyszukiwanie w złożonych dziedzinach.
BM25 i TF-IDF są szybkie i lekkie, odpowiednie dla systemów czasu rzeczywistego. Ocenianie semantyczne wymaga inferencji modelu embeddingowego, co zwiększa opóźnienie. Ocenianie oparte na LLM jest najdroższe. Wybierz metodę w zależności od wymagań czasowych i dostępnych zasobów obliczeniowych.
Weź pod uwagę priorytety: ocenianie semantyczne dla zadań skupionych na znaczeniu, BM25 dla szybkości i efektywności, podejścia hybrydowe dla zrównoważonej wydajności. Oceń metody w swojej dziedzinie używając metryk takich jak NDCG i Precision@k. Testuj różne metody i mierz wpływ na jakość końcowej odpowiedzi.
Śledź, jak systemy AI, takie jak ChatGPT, Perplexity i Google AI, odnoszą się do Twojej marki i oceniają jakość pozyskiwania i oceniania źródeł. Upewnij się, że Twoje treści są prawidłowo cytowane i oceniane przez systemy AI.
Dowiedz się, jak ocena trafności treści wykorzystuje algorytmy AI do mierzenia zgodności treści z zapytaniami i intencją użytkownika. Poznaj BM25, TF-IDF oraz j...

Dowiedz się, co oznaczają wyniki czytelności dla widoczności w wyszukiwarkach AI. Poznaj wpływ Flesch-Kincaid, struktury zdań i formatowania treści na cytowania...

Dowiedz się, czym jest szacowanie wolumenu zapytań AI, czym różni się od tradycyjnego wolumenu wyszukiwania i dlaczego jest kluczowe dla optymalizacji widocznoś...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.