
Licencjonowanie treści dla AI
Dowiedz się więcej o umowach licencyjnych na treści dla AI, które regulują wykorzystanie chronionych prawem autorskim materiałów przez systemy sztucznej intelig...
8 min czytania
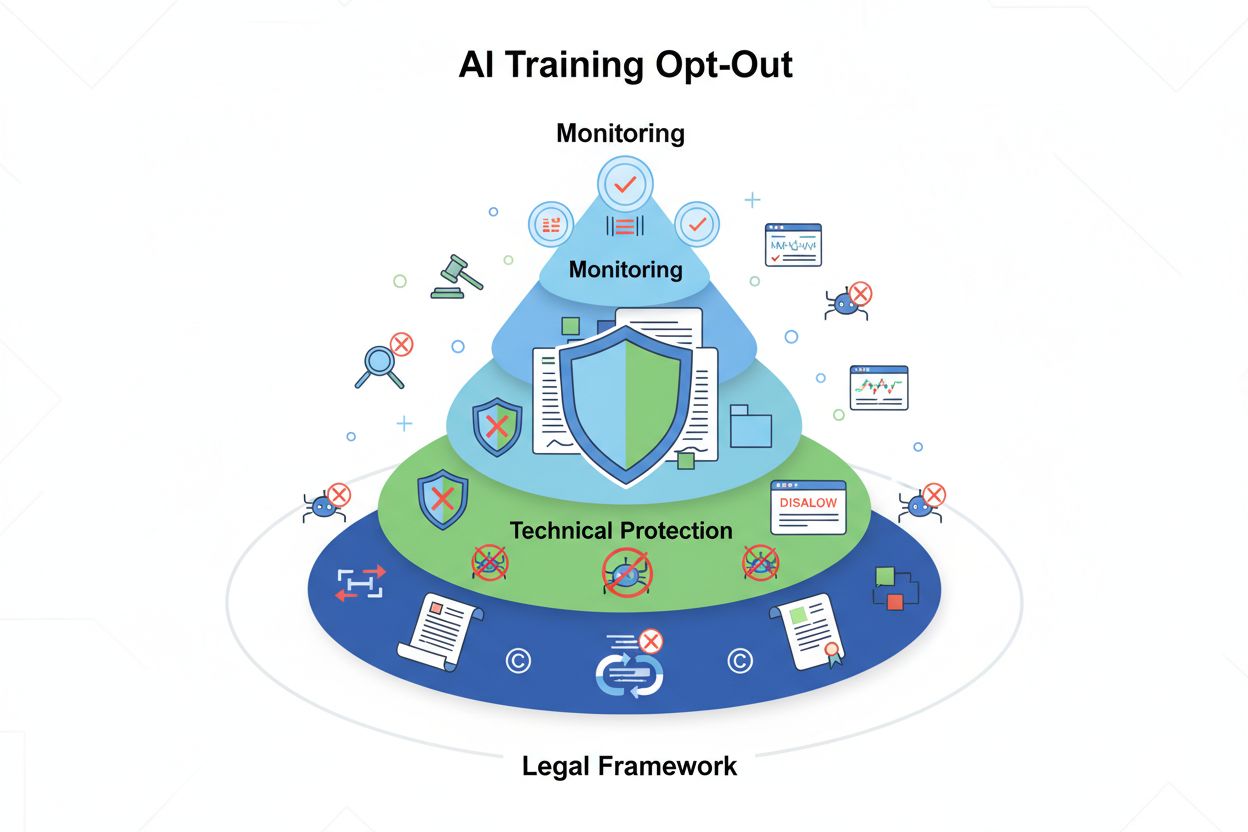
Techniczne i prawne mechanizmy umożliwiające twórcom treści i posiadaczom praw autorskich uniemożliwienie wykorzystania ich dzieł w zbiorach danych do trenowania dużych modeli językowych. Obejmują one dyrektywy robots.txt, prawne oświadczenia o rezygnacji oraz ochronę kontraktową wynikającą z takich regulacji jak unijna AI Act.
Techniczne i prawne mechanizmy umożliwiające twórcom treści i posiadaczom praw autorskich uniemożliwienie wykorzystania ich dzieł w zbiorach danych do trenowania dużych modeli językowych. Obejmują one dyrektywy robots.txt, prawne oświadczenia o rezygnacji oraz ochronę kontraktową wynikającą z takich regulacji jak unijna AI Act.
Rezygnacja z wykorzystania treści do szkolenia AI odnosi się do technicznych i prawnych mechanizmów pozwalających twórcom treści, posiadaczom praw autorskich i właścicielom stron internetowych uniemożliwić wykorzystanie ich pracy w zbiorach danych do trenowania dużych modeli językowych (LLM). W miarę jak firmy AI pozyskują ogromne ilości danych z internetu, by trenować coraz bardziej zaawansowane modele, możliwość kontroli nad tym, czy Twoje treści biorą udział w tym procesie, staje się kluczowa dla ochrony własności intelektualnej i zachowania kontroli twórczej. Mechanizmy rezygnacji działają na dwóch poziomach: technicznych dyrektyw nakazujących robotom AI omijanie Twoich treści oraz ram prawnych ustanawiających uprawnienia kontraktowe do wyłączenia Twojej pracy ze zbiorów treningowych. Zrozumienie obu tych wymiarów jest niezbędne dla każdego, kto martwi się o wykorzystanie swoich treści w erze AI.

Najczęściej stosowaną metodą techniczną rezygnacji ze szkolenia AI jest plik robots.txt – prosty plik tekstowy umieszczany w katalogu głównym witryny, określający, do jakich zasobów mają dostęp zautomatyzowane roboty. Gdy robot AI odwiedza Twoją stronę, najpierw sprawdza robots.txt, by dowiedzieć się, czy wolno mu uzyskać dostęp do treści. Dodając odpowiednie dyrektywy disallow dla konkretnych agentów użytkownika, możesz nakazać botom AI całkowite pominięcie Twojej witryny. Każda firma AI używa kilku robotów z różnymi identyfikatorami agentów użytkownika – to zasadniczo „nazwy”, jakimi boty przedstawiają się podczas wysyłania żądań. Na przykład, GPTBot od OpenAI identyfikuje się jako “GPTBot”, a Claude od Anthropic – jako “ClaudeBot”. Składnia jest prosta: podajesz nazwę agenta i deklarujesz, które ścieżki są zabronione, np. “Disallow: /” by zablokować całą stronę.
| Firma AI | Nazwa robota | Token agenta użytkownika | Cel |
|---|---|---|---|
| OpenAI | GPTBot | GPTBot | Pozyskiwanie danych do treningu modelu |
| OpenAI | OAI-SearchBot | OAI-SearchBot | Indeksowanie wyszukiwania ChatGPT |
| Anthropic | ClaudeBot | ClaudeBot | Pobieranie cytowań do chatu |
| Google-Extended | Google-Extended | Dane treningowe Gemini AI | |
| Perplexity | PerplexityBot | PerplexityBot | Indeksowanie wyszukiwania AI |
| Meta | Meta-ExternalAgent | Meta-ExternalAgent | Szkolenie modelu AI |
| Common Crawl | CCBot | CCBot | Otwarty zbiór danych dla LLM |
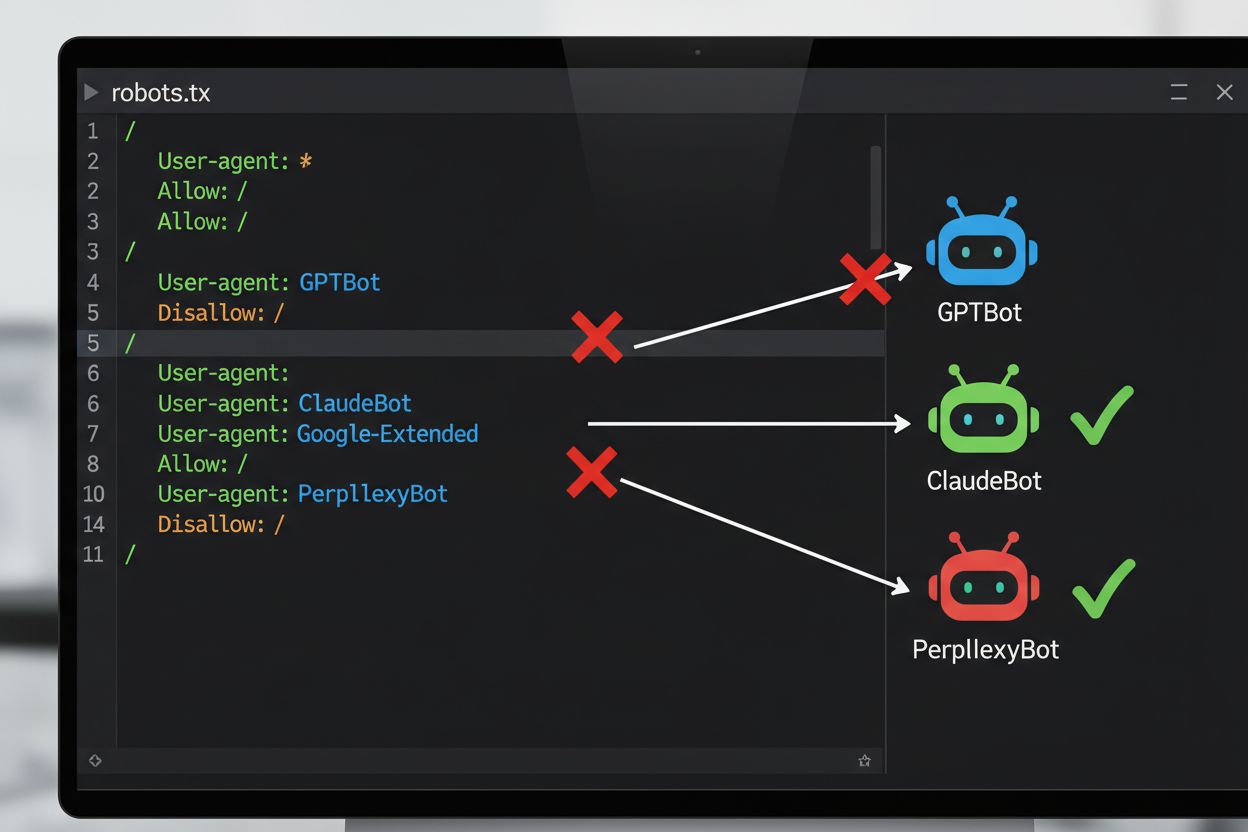
Sytuacja prawna dotycząca rezygnacji ze szkolenia AI znacząco się rozwinęła wraz z wejściem w życie unijnej AI Act w 2024 roku, która uwzględnia także zapisy Dyrektywy o tekstach i wydobywaniu danych (TDM Directive). Zgodnie z tymi regulacjami twórcy AI mogą korzystać z utworów objętych prawem autorskim do celów uczenia maszynowego tylko wtedy, gdy mają legalny dostęp do treści i posiadacz praw autorskich nie zastrzegł wyraźnie prawa do wyłączenia swojego utworu z wydobywania tekstu i danych. Tworzy to formalny mechanizm prawny rezygnacji: posiadacze praw mogą składać zastrzeżenia do swoich utworów, efektywnie uniemożliwiając ich wykorzystanie do szkolenia AI bez wyraźnej zgody. AI Act stanowi odejście od dotychczasowego podejścia „działaj szybko i łam zasady” i nakłada na firmy szkolące modele AI obowiązek weryfikacji, czy prawa zostały zastrzeżone, a także wdrożenia zabezpieczeń technicznych i organizacyjnych zapobiegających przypadkowemu wykorzystaniu zastrzeżonych treści. Ramy te obowiązują w całej Unii Europejskiej i wpływają na praktyki zbierania danych i szkolenia modeli przez globalne firmy AI.
Wdrożenie mechanizmu rezygnacji wymaga zarówno konfiguracji technicznej, jak i dokumentacji prawnej. Po stronie technicznej właściciele stron dodają dyrektywy disallow do robots.txt dla konkretnych agentów AI, które są respektowane przez zgodne z zasadami roboty podczas odwiedzania witryny. Po stronie prawnej posiadacze praw autorskich mogą składać oświadczenia o rezygnacji do organizacji zbiorowego zarządzania, np. holenderskiej Pictoright czy francuskiego stowarzyszenia muzycznego SACEM, które mają formalne procedury umożliwiające twórcom zastrzeżenie praw wobec szkolenia AI. Coraz więcej stron internetowych i twórców umieszcza też wyraźne oświadczenia o rezygnacji w regulaminach lub metadanych, deklarując zakaz wykorzystywania treści do szkolenia modeli AI. Skuteczność tych mechanizmów zależy jednak od zgodności robotów: choć główne firmy jak OpenAI, Google czy Anthropic deklarują respektowanie robots.txt i rezygnacji, brak centralnego systemu egzekwowania oznacza, że potwierdzenie skuteczności rezygnacji wymaga stałego monitoringu i weryfikacji.
Pomimo dostępności mechanizmów rezygnacji ich skuteczność ograniczają poważne wyzwania:
Organizacje wymagające silniejszej ochrony niż daje sam robots.txt mogą wdrożyć dodatkowe środki techniczne. Filtrowanie agentów użytkownika na poziomie serwera lub firewalla może blokować żądania od konkretnych robotów zanim dotrą do aplikacji, choć można to obejść przez podszywanie się. Blokowanie adresów IP pozwala odcinać znane zakresy adresów używane przez duże firmy AI, lecz zdeterminowani scraperzy ominą to przez sieci proxy. Ograniczanie liczby żądań (rate limiting) może spowolnić roboty, czyniąc scraping nieopłacalnym, choć zaawansowane boty rozpraszają ruch na wiele IP. Wymogi logowania i paywalle dają silną ochronę, ograniczając dostęp do zalogowanych użytkowników lub płatników. Fingerprinting urządzeń i analiza zachowań wykrywają boty na podstawie nietypowych wzorców API, TLS czy interakcji. Niektóre organizacje wdrażają nawet honeypoty i tarpity – ukryte linki lub nieskończone labirynty, które tylko boty by podążały, marnując ich zasoby i zaśmiecając ich zbiory treningowe bezwartościowymi danymi.
Napięcie między firmami AI i twórcami treści doprowadziło do licznych głośnych konfliktów, które ilustrują realne trudności egzekwowania rezygnacji. Reddit w 2023 roku znacząco podniósł ceny dostępu do API, by pobierać opłaty od firm AI i zniechęcić do nieautoryzowanego scrapingu, zmuszając OpenAI i Anthropic do negocjowania licencji. Twitter/X poszedł jeszcze dalej, czasowo blokując niezalogowany dostęp do tweetów i ograniczając liczbę tweetów czytanych przez użytkowników, celując bezpośrednio w scraperów. Stack Overflow początkowo zablokował GPTBot od OpenAI w robots.txt z powodu obaw o licencjonowanie kodu użytkowników, jednak później usunął blokadę – być może po negocjacjach z OpenAI. Wydawcy medialni masowo zareagowali: ponad 50% dużych portali informacyjnych zablokowało roboty AI do 2023 roku – m.in. The New York Times, CNN, Reuters i The Guardian dodały GPTBot do listy zabronionych. Niektóre redakcje poszły drogą sądową, jak The New York Times pozywając OpenAI o naruszenie praw autorskich, inne – np. Associated Press – wynegocjowały umowy licencyjne na monetyzację treści. Przykłady te pokazują, że skuteczność rezygnacji zależy zarówno od wdrożenia technicznego, jak i gotowości do egzekwowania praw na drodze prawnej.
Wdrożenie rezygnacji to dopiero połowa sukcesu – potwierdzenie jej skuteczności wymaga ciągłego monitorowania i testowania. Pomocne są tu narzędzia takie jak Google Search Console z testerem robots.txt dla Googlebota czy Merkle’s Robots.txt Tester i narzędzie TechnicalSEO.com testujące zachowanie wybranych agentów użytkownika. W celu kompleksowego monitoringu, czy firmy AI rzeczywiście respektują rezygnację, platformy takie jak AmICited.com oferują wyspecjalizowane rozwiązania śledzące, jak systemy AI cytują Twoją markę i treści w GPT, Perplexity, Google AI Overviews i innych. Takie monitorowanie jest szczególnie cenne, bo pokazuje nie tylko, czy roboty odwiedzają Twoją stronę, ale też, czy Twoje treści pojawiają się w odpowiedziach generowanych przez AI – czyli czy rezygnacja działa w praktyce. Regularna analiza logów serwera pozwala wykryć, które roboty próbują uzyskać dostęp do witryny i czy respektują robots.txt, choć wymaga to wiedzy technicznej.
Aby skutecznie chronić swoje treści przed nieautoryzowanym wykorzystaniem do szkolenia AI, stosuj podejście warstwowe, łącząc środki techniczne i prawne. Po pierwsze, wdrażaj dyrektywy robots.txt dla wszystkich głównych robotów szkoleniowych AI (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot i inne) – zapewnia to podstawową ochronę przed firmami przestrzegającymi zasad. Po drugie, dodaj wyraźne oświadczenia o rezygnacji do regulaminu strony i metadanych, jasno deklarując zakaz używania treści do trenowania modeli AI – to wzmocni Twoją pozycję prawną w razie naruszeń. Po trzecie, regularnie monitoruj konfigurację za pomocą narzędzi i logów serwera, weryfikując respektowanie dyrektyw przez roboty, oraz aktualizuj robots.txt kwartalnie, bo nowe roboty AI pojawiają się nieustannie. Po czwarte, rozważ dodatkowe środki techniczne jak filtrowanie agentów czy rate limiting, jeśli masz zasoby techniczne – to dodatkowa warstwa ochrony przed zaawansowanymi scraperami. Na koniec, dokumentuj wszystkie działania związane z rezygnacją – taka dokumentacja jest kluczowa w przypadku konieczności podjęcia kroków prawnych wobec firm ignorujących Twoje dyrektywy. Pamiętaj, że rezygnacja to nie jednorazowa konfiguracja, ale proces wymagający ciągłej czujności i dostosowywania się do zmian w ekosystemie AI.
robots.txt to techniczny, dobrowolny standard, który instruuje roboty o pomijaniu Twoich treści, podczas gdy rezygnacja prawna polega na złożeniu formalnych zastrzeżeń w organizacjach zbiorowego zarządzania prawami autorskimi lub zawarciu odpowiednich klauzul w regulaminie. robots.txt jest łatwiejszy do wdrożenia, ale nie ma mechanizmu egzekwowania, natomiast rezygnacja prawna zapewnia silniejszą ochronę prawną, lecz wymaga formalnych procedur.
Główne firmy AI, takie jak OpenAI, Google, Anthropic i Perplexity, publicznie zadeklarowały respektowanie dyrektyw robots.txt. Jednak robots.txt to dobrowolny standard bez mechanizmu egzekwowania, więc nieuczciwe roboty i scraperzy mogą całkowicie zignorować Twoje dyrektywy.
Nie. Blokowanie robotów szkoleniowych AI, takich jak GPTBot czy ClaudeBot, nie ma wpływu na pozycję w Google ani Bing, ponieważ tradycyjne wyszukiwarki używają innych robotów (Googlebot, Bingbot), które działają niezależnie. Blokuj je tylko wtedy, jeśli chcesz całkowicie zniknąć z wyników wyszukiwania.
Unijna AI Act wymaga, aby twórcy AI mieli legalny dostęp do treści i musieli respektować rezygnacje zgłoszone przez posiadaczy praw autorskich. Posiadacze praw mogą składać oświadczenia o rezygnacji wraz ze swoimi utworami, efektywnie uniemożliwiając ich wykorzystanie do szkolenia AI bez wyraźnej zgody. To tworzy formalny mechanizm prawny ochrony treści przed nieautoryzowanym wykorzystaniem w szkoleniu modeli.
To zależy od konkretnego mechanizmu. Blokowanie wszystkich robotów AI uniemożliwi pojawianie się Twoich treści w wynikach wyszukiwania AI, ale jednocześnie usunie Cię z takich platform całkowicie. Niektórzy wydawcy wolą selektywne blokowanie—zezwalając robotom wyszukiwawczym, blokując szkoleniowe—by zachować widoczność w AI, jednocześnie chroniąc treść przed szkoleniem modeli.
Jeśli firma AI zignoruje Twoje dyrektywy rezygnacji, przysługuje Ci ochrona prawna w postaci roszczenia o naruszenie praw autorskich lub naruszenie umowy, w zależności od jurysdykcji i okoliczności. Jednak postępowanie prawne jest kosztowne i powolne, a jego wynik niepewny. Dlatego tak ważne jest dokumentowanie i monitorowanie swoich działań związanych z rezygnacją.
Przeglądaj i aktualizuj konfigurację robots.txt przynajmniej raz na kwartał. Nowe roboty AI pojawiają się nieustannie, a firmy często wprowadzają nowe identyfikatory agentów. Na przykład Anthropic połączył swoje boty 'anthropic-ai' i 'Claude-Web' w 'ClaudeBot', dając nowemu botowi tymczasowo nieograniczony dostęp do witryn bez zaktualizowanych reguł.
Rezygnacja jest skuteczna wobec renomowanych firm AI, które respektują robots.txt i ramy prawne. Jednak jest mniej skuteczna wobec nieuczciwych robotów i scraperów działających w szarej strefie prawnej. robots.txt zatrzymuje około 40–60% botów AI, dlatego zalecane jest łączenie różnych technicznych i prawnych środków ochrony.
Śledź, czy Twoje treści pojawiają się w odpowiedziach generowanych przez AI w ChatGPT, Perplexity, Google AI Overviews i innych platformach AI dzięki AmICited.
Dowiedz się więcej o umowach licencyjnych na treści dla AI, które regulują wykorzystanie chronionych prawem autorskim materiałów przez systemy sztucznej intelig...
Dowiedz się, czym jest uziemienie treści, jak zapobiega halucynacjom AI i dlaczego jest niezbędne dla wiarygodnych systemów AI. Poznaj techniki, narzędzia i naj...

Dowiedz się, czym jest zanik treści w wyszukiwarce AI, czym różni się od tradycyjnego zaniku SEO i dlaczego systemy AI faworyzują świeże, autorytatywne treści. ...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.