Google-Extended
Dowiedz się, czym jest Google-Extended – token user-agenta pozwalający wydawcom kontrolować, czy ich treści będą wykorzystywane do trenowania AI w Gemini i Vert...
6 min czytania
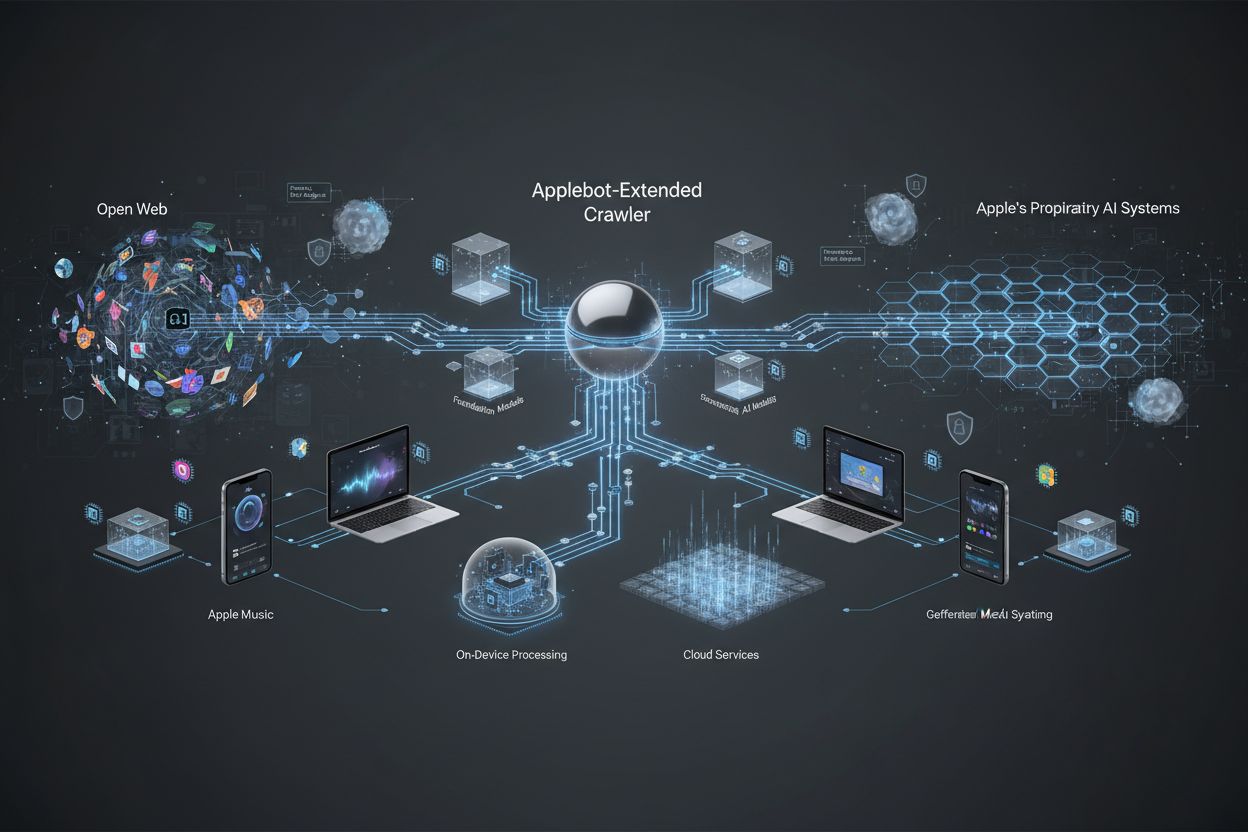
Specjalistyczny crawler internetowy Apple, który ocenia treści do trenowania Apple Intelligence i generatywnych modeli AI. Działa jako dodatkowy mechanizm oceny, niezależny od standardowego Applebota, określając, które publicznie dostępne treści internetowe nadają się do wykorzystania w bazowych modelach Apple i LLM. Właściciele stron mogą kontrolować jego dostęp przez dyrektywy robots.txt niezależnie od standardowego Applebota.
Specjalistyczny crawler internetowy Apple, który ocenia treści do trenowania Apple Intelligence i generatywnych modeli AI. Działa jako dodatkowy mechanizm oceny, niezależny od standardowego Applebota, określając, które publicznie dostępne treści internetowe nadają się do wykorzystania w bazowych modelach Apple i LLM. Właściciele stron mogą kontrolować jego dostęp przez dyrektywy robots.txt niezależnie od standardowego Applebota.
Applebot-Extended to specjalistyczny crawler internetowy obsługiwany przez Apple, który rozszerza możliwości standardowego Applebota, zbierając i oceniając treści specjalnie do trenowania systemów Apple Intelligence. O ile pierwotny Applebot służy głównie potrzebom wyszukiwania i indeksowania Apple, o tyle Applebot-Extended działa jako odrębny crawler skoncentrowany na pozyskiwaniu wysokiej jakości treści, które mogą być wykorzystane do ulepszania generatywnych modeli AI i uczenia maszynowego Apple. Ten crawler odzwierciedla zaangażowanie Apple w rozwój zaawansowanych zbiorów danych treningowych AI poprzez systematyczne identyfikowanie i przetwarzanie treści internetowych spełniających określone standardy jakości. Rozróżnienie między standardowym Applebotem a Applebot-Extended jest kluczowe dla właścicieli stron internetowych, ponieważ oba crawlery służą różnym celom i można nimi zarządzać niezależnie za pomocą dyrektyw robots.txt.
Applebot-Extended działa w ramach dwustopniowego systemu crawlowania, w którym początkowego odkrycia treści dokonuje standardowy Applebot, a następnie następuje faza wtórnej oceny prowadzona przez Applebot-Extended. Gdy Applebot-Extended odwiedza stronę, przeprowadza kompleksową ocenę treści, aby ustalić, czy materiał spełnia standardy Apple do włączenia w zbiory treningowe AI. Crawler identyfikuje się poprzez określony ciąg user agent, który odróżnia go od standardowego Applebota, pozwalając administratorom stron rozróżnić oba crawlery w logach serwera i narzędziach analitycznych. Applebot-Extended ocenia treści według wielu kryteriów, w tym istotności, dokładności, oryginalności i zgodności z wytycznymi jakości, które zapewniają, że tylko wartościowe treści trafiają do systemów Apple Intelligence.
| Funkcja | Applebot | Applebot-Extended |
|---|---|---|
| Główny cel | Ogólne indeksowanie i wyszukiwanie | Zbieranie danych do trenowania AI |
| Skupienie na treści | Cała zawartość internetu | Wysokiej jakości, wyselekcjonowana treść |
| User Agent | Applebot | Applebot-Extended |
| Głębokość oceny | Standardowe crawlowanie | Zaawansowana ocena jakości |
| Metoda blokowania | Dyrektywy robots.txt | Oddzielne reguły robots.txt |

Apple Intelligence to zintegrowany pakiet funkcji Apple opartych na AI, zaprojektowany w celu wzbogacenia doświadczeń użytkowników na iOS, iPadOS, macOS i innych platformach Apple dzięki przetwarzaniu na urządzeniu i w chmurze. Możliwości generatywnego AI, napędzane danymi pozyskanymi przez Applebot-Extended, obejmują zaawansowane narzędzia do pisania, generowanie obrazów, inteligentne usprawnienia wyszukiwania oraz funkcje asystenta kontekstowego, które wykorzystują modele bazowe i duże modele językowe (LLM) trenowane na wyselekcjonowanych treściach internetowych. Systemy te umożliwiają takie funkcje, jak Narzędzia do Pisania do redagowania e-maili i dokumentów, Image Playground do kreatywnego generowania treści oraz ulepszone możliwości Siri, która lepiej rozumie złożone prośby użytkowników. Podejście Apple podkreśla ochronę prywatności poprzez przetwarzanie większości danych na urządzeniu, podczas gdy Applebot-Extended dba o to, by dane treningowe tych systemów pochodziły z wysokiej jakości, zróżnicowanych źródeł z całego internetu. Selektywne podejście crawlery do zbierania treści bezpośrednio wpływa na zaawansowanie i wiarygodność funkcji Apple Intelligence dostępnych dla milionów użytkowników na świecie.
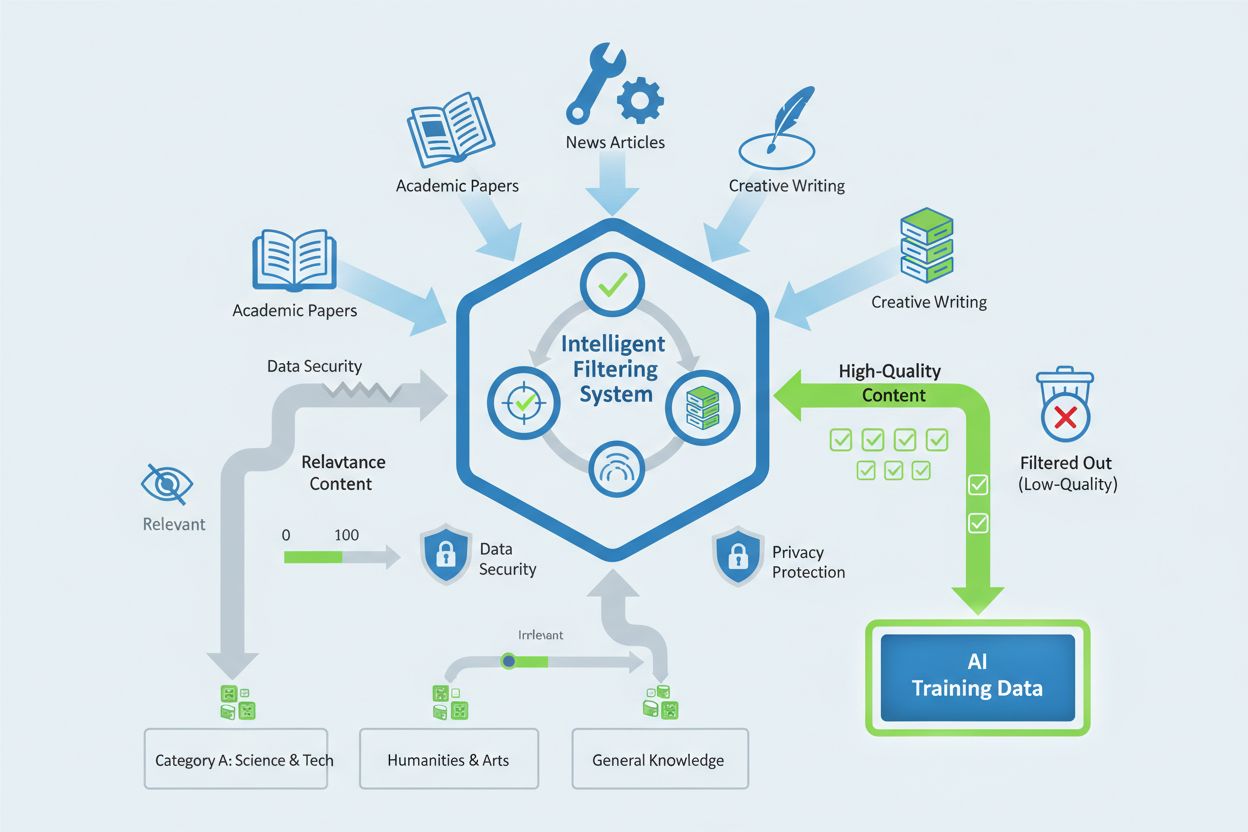
Applebot-Extended skupia się na wybranych kategoriach treści, które wykazują wysoką wartość informacyjną i wiarygodność do celów trenowania AI. Crawler priorytetowo traktuje treści według następujących kryteriów:
Crawler stosuje zaawansowane mechanizmy filtrowania danych, aby usuwać niskiej jakości treści, w tym spam, powielane materiały oraz zawartość o znikomych walorach informacyjnych. Apple wdraża techniki oceny z poszanowaniem prywatności, które pozwalają na ocenę jakości treści bez niepotrzebnego przechowywania danych osobowych czy wrażliwych informacji. Proces selekcji obejmuje automatyczne systemy punktacji jakości, które oceniają takie czynniki jak wiarygodność źródła, oryginalność treści, zgodność z faktami i przydatność dla celów trenowania Apple Intelligence. Właściciele stron mogą zwiększyć szanse na włączenie ich treści, utrzymując wysokie standardy redakcyjne, zapewniając oryginalność i autorytatywność oraz unikając działań sztucznie zawyżających wskaźniki jakości.
Administratorzy stron mogą kontrolować dostęp Applebot-Extended do swoich treści za pomocą dyrektyw robots.txt, które umożliwiają szczegółowe zarządzanie zachowaniem crawlerów niezależnie od ograniczeń dla standardowego Applebota. Aby zablokować wyłącznie Applebot-Extended przy jednoczesnym umożliwieniu crawlowania standardowemu Applebotowi, właściciele stron mogą wdrożyć specjalne reguły rozróżniające oba crawlery na podstawie ich identyfikatorów user agent. Kluczowa różnica polega na tym, że zablokowanie standardowego Applebota nie blokuje automatycznie Applebot-Extended i odwrotnie – każdy crawler musi być zarządzany osobno, jeśli mają obowiązywać odmienne polityki dostępu. Blokowanie Applebot-Extended ma minimalne bezpośrednie skutki dla SEO, ponieważ nie wpływa na pozycje w wyszukiwarkach, ale uniemożliwia wykorzystanie Twoich treści do trenowania Apple Intelligence, co może ograniczyć widoczność witryny w funkcjach i usługach Apple opartych na AI.
# Blokuj tylko Applebot-Extended, pozwalając standardowemu Applebotowi na dostęp
User-agent: Applebot-Extended
Disallow: /
# Pozwól standardowemu Applebotowi
User-agent: Applebot
Allow: /
# Zablokuj zarówno Applebota, jak i Applebot-Extended
User-agent: Applebot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Zablokuj określone katalogi przed Applebot-Extended
User-agent: Applebot-Extended
Disallow: /private/
Disallow: /admin/
Allow: /public/
Apple stosuje podejście skoncentrowane na prywatności w działaniach Applebot-Extended, podkreślając, że zbieranie treści do trenowania AI respektuje prywatność użytkowników oraz przepisy o ochronie danych w różnych jurysdykcjach. Firma wdraża zarówno techniczne, jak i organizacyjne środki, by mieć pewność, że dane osobowe nie są niepotrzebnie zbierane ani przechowywane podczas crawlowania i oceny treści, a sama ocena koncentruje się na wartości informacyjnej, a nie na pozyskiwaniu danych osobistych. Właściciele stron i twórcy treści zachowują indywidualne prawa do prywatności w odniesieniu do swoich danych, w tym prawo do uzyskania informacji o sposobie wykorzystania ich treści oraz prawo do żądania ich usunięcia na mocy obowiązujących przepisów, takich jak RODO czy CCPA. Apple udostępnia formularz Apple Intelligence Privacy Inquiries, stanowiący formalny mechanizm zgłaszania pytań, uwag lub wniosków dotyczących sposobu, w jaki Apple Intelligence przetwarza treści lub dane osobowe. Takie podejście do prywatności gwarantuje, że korzyści z zaawansowanych funkcji AI są równoważone przez fundamentalne prawa do ochrony danych i autonomii użytkownika.
Właściciele stron mogą wykrywać wizyty Applebot-Extended poprzez monitorowanie logów serwera i analizę ciągów user agent, w których pojawi się “Applebot-Extended” jako identyfikator crawlery. Specjalistyczne narzędzia analityczne takie jak Dark Visitors czy UseHall zapewniają rozszerzony wgląd w ruch crawlerów AI, umożliwiając administratorom śledzenie wzorców crawlowania, częstotliwości i zużycia zasobów związanych z wizytami Applebot-Extended. Takie rozwiązania pomagają właścicielom stron zrozumieć wpływ crawlerów AI na zasoby serwera i transfer, umożliwiając świadome decyzje o polityce dostępu i strategii optymalizacyjnej. Wdrożenie odpowiednich mechanizmów wykrywania i logowania ruchu pozwala wyodrębnić aktywność Applebot-Extended od innych crawlerów i ruchu użytkowników, dostarczając cennych informacji o tym, jak treści strony przyczyniają się do infrastruktury treningowej AI Apple.
Applebot-Extended działa w szerokim ekosystemie crawlerów internetowych skupionych na AI, które realizują różne cele i funkcjonują według odmiennych polityk, odzwierciedlając podejście swoich firm macierzystych do rozwoju AI i pozyskiwania danych. Googlebot służy głównie indeksowaniu i rankingowi w wyszukiwarce Google, z osobnymi crawlerami, takimi jak Googlebot-Extended, odpowiadającymi za ocenę treści dla systemów AI Google, co czyni ich podejście podobnym do dwustopniowego modelu Apple, choć na znacznie większą skalę. Bingbot – crawler Microsoftu – również wspiera zarówno indeksowanie wyszukiwania, jak i trenowanie AI na potrzeby Copilot i innych usług generatywnych, choć według odmiennych kryteriów i ram prywatności. Crawler ChatGPT (zarządzany przez OpenAI) koncentruje się wyłącznie na gromadzeniu treści do trenowania dużych modeli językowych, działając w oparciu o jawne mechanizmy opt-out i inne zasady wykorzystania danych niż Apple. W odróżnieniu od niektórych konkurentów, Applebot-Extended wyróżnia się naciskiem Apple na przetwarzanie na urządzeniu i ochronę prywatności, ograniczając gromadzenie danych w chmurze i oferując czytelniejsze mechanizmy opt-out przez robots.txt oraz formalne procedury zgłaszania zapytań o prywatność. Analiza porównawcza pokazuje, że choć wszystkie duże firmy technologiczne stosują crawlery AI, to ich kryteria oceny, polityki przechowywania danych i mechanizmy kontroli dla użytkowników znacząco się różnią, co odzwierciedla odmienne filozofie korporacyjne dotyczące rozwoju AI, prywatności i praw twórców treści. Właściciele stron powinni znać te różnice, decydując o polityce dostępu crawlerów, ponieważ polityki każdego crawlera i ich wpływ na wykorzystanie treści w systemach AI są odmienne.
Applebot to główny crawler internetowy Apple używany do indeksowania wyszukiwania i obsługi funkcji takich jak Spotlight i wyszukiwanie Siri. Applebot-Extended to dodatkowy crawler, który ocenia treści już zindeksowane przez Applebota, aby określić, czy nadają się do trenowania generatywnych modeli AI Apple. Służą różnym celom i można nimi zarządzać niezależnie przez robots.txt.
Możesz zablokować Applebot-Extended, dodając odpowiednie reguły do pliku robots.txt. Użyj 'User-agent: Applebot-Extended', a następnie 'Disallow: /', aby zablokować całą stronę, lub wskaż konkretne katalogi. Zapobiega to wykorzystaniu Twoich treści do trenowania Apple Intelligence, jednocześnie pozwalając standardowemu Applebotowi na indeksowanie strony do celów wyszukiwania.
Blokowanie Applebot-Extended ma minimalny bezpośredni wpływ na SEO, ponieważ nie wpływa na pozycje w wyszukiwarkach. Jednak uniemożliwia wykorzystanie Twoich treści do trenowania Apple Intelligence, co w przyszłości może zmniejszyć widoczność w funkcjach i usługach Apple opartych na AI.
Applebot-Extended skupia się na wysokiej jakości treściach, takich jak artykuły naukowe, dokumentacja techniczna, profesjonalne artykuły prasowe, oryginalna twórczość oraz materiały od uznanych ekspertów. Crawler ocenia treści pod kątem wiarygodności, oryginalności, rzetelności i przydatności dla celów trenowania AI.
Nie. Apple wyraźnie zaznacza, że nie wykorzystuje prywatnych danych osobowych użytkowników ani ich interakcji podczas trenowania modeli bazowych dla Apple Intelligence. Firma korzysta wyłącznie z publicznie dostępnych treści internetowych, materiałów licencjonowanych i syntetycznie generowanych danych. Apple wdraża środki chroniące prywatność, by usuwać dane osobowe z zestawów treningowych.
Możesz wykryć wizyty Applebot-Extended, monitorując logi serwera pod kątem obecności ciągu 'Applebot-Extended' w user agencie. Specjalistyczne narzędzia analityczne, takie jak Dark Visitors i UseHall, zapewniają lepszy wgląd w ruch crawlerów AI, umożliwiając śledzenie schematów crawlowania, częstotliwości i wykorzystania zasobów.
Apple Intelligence to zintegrowany pakiet funkcji Apple opartych na AI, dostępny w iOS, iPadOS, macOS i innych platformach. Applebot-Extended gromadzi wysokiej jakości treści internetowe, które trenują modele bazowe i duże modele językowe napędzające funkcje takie jak Narzędzia do Pisania, Image Playground i ulepszone możliwości Siri.
Tak. Apple udostępnia formularz Apple Intelligence Privacy Inquiries, przez który można zgłaszać prośby dotyczące sposobu wykorzystania swoich treści lub danych osobowych w związku z Apple Intelligence. Możesz także użyć standardowych dyrektyw robots.txt, aby zrezygnować z crawlowania przez Applebot-Extended.
Śledź, jak Twoje treści pojawiają się w Apple Intelligence i innych systemach AI dzięki kompleksowej platformie monitorującej AI AmICited.
Dowiedz się, czym jest Google-Extended – token user-agenta pozwalający wydawcom kontrolować, czy ich treści będą wykorzystywane do trenowania AI w Gemini i Vert...

Dowiedz się, jak działają AI crawlers takie jak GPTBot i ClaudeBot, czym różnią się od tradycyjnych crawlerów wyszukiwarek oraz jak zoptymalizować swoją stronę ...

Dowiedz się, czym jest CCBot, jak działa i jak go zablokować. Poznaj jego rolę w trenowaniu AI, narzędzia monitorujące oraz najlepsze praktyki ochrony treści pr...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.