Czym jest Burstiness w Treściach AI i Jak Wpływa na Wykrywanie
Dowiedz się, czym jest burstiness w treściach generowanych przez AI, jak różni się od wzorców pisania ludzi i dlaczego jest ważny dla wykrywania AI oraz autenty...
7 min czytania
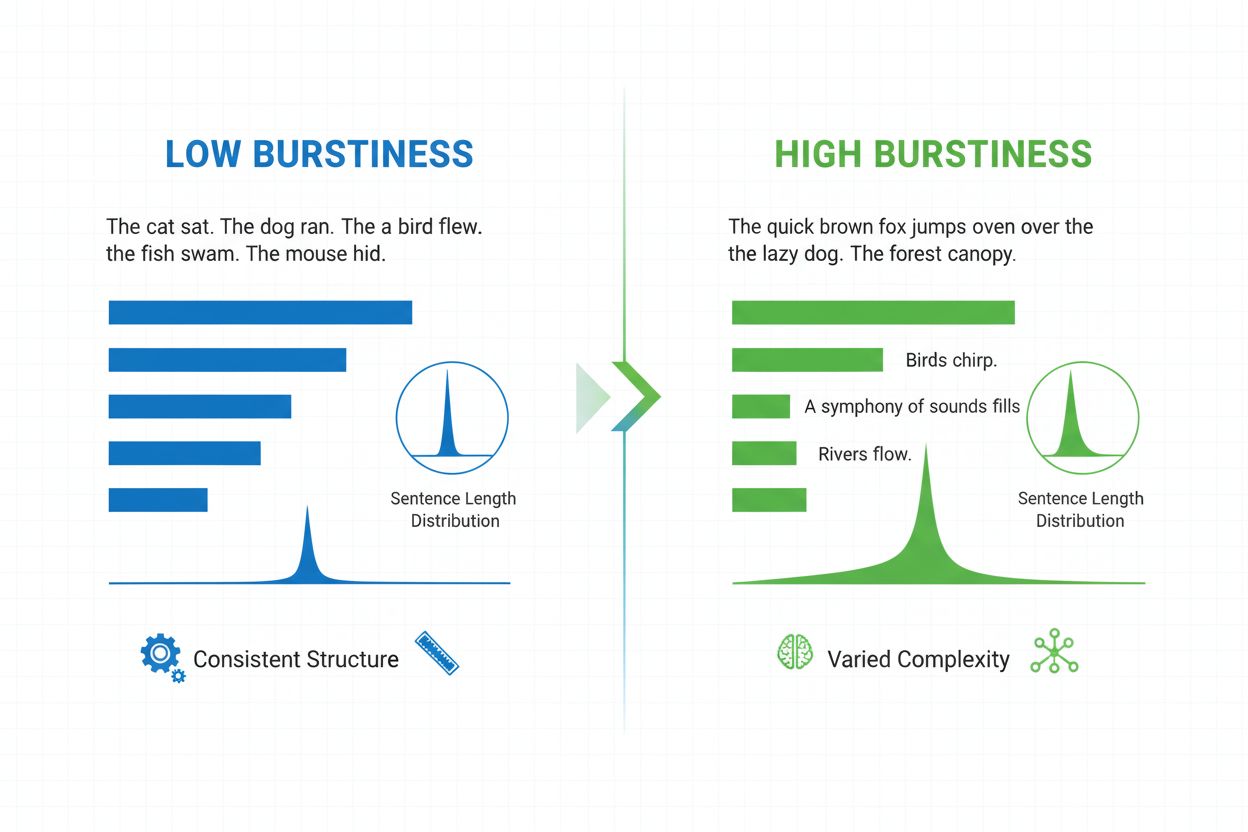
Burstiness to lingwistyczna miara określająca zmienność długości, struktury i złożoności zdań w dokumencie. Określa, jak bardzo autor przeplata krótkie, treściwe zdania z dłuższymi, bardziej złożonymi, będąc kluczowym wskaźnikiem w detekcji treści generowanych przez AI i analizie języka naturalnego.
Burstiness to lingwistyczna miara określająca zmienność długości, struktury i złożoności zdań w dokumencie. Określa, jak bardzo autor przeplata krótkie, treściwe zdania z dłuższymi, bardziej złożonymi, będąc kluczowym wskaźnikiem w detekcji treści generowanych przez AI i analizie języka naturalnego.
Burstiness to mierzalny wskaźnik lingwistyczny określający zmienność i fluktuacje długości, struktury oraz złożoności zdań w całym dokumencie lub fragmencie tekstu. Termin ten wywodzi się z koncepcji “wybuchów” różnych wzorców zdań — naprzemiennego stosowania krótkich, zwięzłych zdań oraz dłuższych, bardziej złożonych. W kontekście przetwarzania języka naturalnego i detekcji treści generowanych przez AI, burstiness pełni rolę kluczowego wskaźnika pozwalającego stwierdzić, czy tekst został napisany przez człowieka, czy przez system sztucznej inteligencji. Ludzie naturalnie tworzą teksty o wysokim burstiness, ponieważ spontanicznie różnicują budowę zdań w zależności od akcentu, tempa i zamierzonego stylu. Z kolei teksty generowane przez AI zwykle wykazują niski burstiness, ponieważ modele językowe uczą się na wzorcach statystycznych, które sprzyjają spójności i przewidywalności. Zrozumienie burstiness jest niezbędne dla twórców treści, nauczycieli, badaczy i organizacji monitorujących treści AI na platformach takich jak ChatGPT, Perplexity, Google AI Overviews czy Claude.
Koncepcja burstiness wyłoniła się z badań nad lingwistyką komputerową i teorią informacji, gdzie naukowcy dążyli do ilościowego opisu właściwości statystycznych języka naturalnego. Wczesne prace w dziedzinie stylometrii — statystycznej analizy stylu pisania — wykazały, że pisanie ludzkie wyróżnia się charakterystycznymi wzorcami zmienności, które zasadniczo różnią się od tekstów generowanych przez maszyny. Wraz z rozwojem dużych modeli językowych (LLM) na początku lat 20. XXI wieku, badacze odkryli, że burstiness, w połączeniu z perpleksją (miarą przewidywalności słów), może być skutecznym wskaźnikiem treści AI. Według badań QuillBot i instytucji naukowych około 78% przedsiębiorstw obecnie korzysta z narzędzi monitoringu treści opartych na AI, które wykorzystują analizę burstiness w swoich algorytmach wykrywania. Badanie Stanford University z 2023 roku dotyczące esejów TOEFL wykazało, że metody detekcji oparte na burstiness, choć użyteczne, mają istotne ograniczenia — szczególnie jeśli chodzi o fałszywe alarmy w przypadku tekstów pisanych przez osoby niebędące rodzimymi użytkownikami angielskiego. Badania te przyczyniły się do rozwoju bardziej zaawansowanych, wielowarstwowych systemów detekcji AI, które uwzględniają burstiness obok innych markerów lingwistycznych, spójności semantycznej i adekwatności kontekstowej.
Burstiness oblicza się poprzez analizę statystycznego rozkładu długości zdań oraz wzorców strukturalnych w tekście. Wskaźnik ten mierzy wariancję — czyli określa, jak mocno poszczególne zdania odbiegają od średniej długości w dokumencie. Dokument o wysokim burstiness zawiera zdania znacznie różniące się długością; autor może na przykład po trzywyrazowym zdaniu (“Widzisz?”) użyć dwudziestopięciowyrazowego, wieloczłonowego zdania z podrzędnymi frazami. Z kolei niski burstiness oznacza, że większość zdań oscyluje wokół podobnej długości (zazwyczaj 12–18 słów), co prowadzi do monotonii. Obliczenia składają się z kilku etapów: najpierw system mierzy długość każdego zdania w słowach; następnie wyznacza średnią długość zdania; na końcu oblicza odchylenie standardowe, by określić, jak bardzo poszczególne zdania odbiegają od tej średniej. Wyższe odchylenie standardowe oznacza większą zmienność, a tym samym wyższy burstiness. Współczesne detektory AI, takie jak Winston AI i Pangram, stosują zaawansowane algorytmy, które nie ograniczają się do zliczania słów, lecz analizują też złożoność składniową — układ zdań, fraz i elementów gramatycznych. Ta głębsza analiza pokazuje, że pisarze stosują różnorodne struktury zdań (proste, złożone, współrzędnie złożone itd.) w nieprzewidywalnych wzorcach, podczas gdy modele AI preferują określone szablony strukturalne często spotykane w danych treningowych.
| Wskaźnik | Burstiness | Perpleksja | Zakres pomiaru |
|---|---|---|---|
| Definicja | Zmienność długości i struktury zdań | Przewidywalność pojedynczych słów | Poziom zdań vs. słów |
| Pisanie ludzkie | Wysokie (zróżnicowane struktury) | Wysokie (nieprzewidywalne słowa) | Naturalny rytm i słownictwo |
| Tekst AI | Niskie (jednolite struktury) | Niskie (przewidywalne słowa) | Spójność statystyczna |
| Zastosowanie w detekcji | Identyfikuje monotonię strukturalną | Identyfikuje wzorce doboru słów | Metody uzupełniające się |
| Ryzyko fałszywych alarmów | Wyższe dla piszących po angielsku jako obcym | Wyższe dla tekstów technicznych/naukowych | Oba mają ograniczenia |
| Metoda obliczania | Odchylenie standardowe długości zdań | Analiza rozkładu prawdopodobieństwa | Różne podejścia matematyczne |
| Samodzielna wiarygodność | Niewystarczające do jednoznacznej detekcji | Niewystarczające do jednoznacznej detekcji | Najskuteczniejsze w połączeniu |
Duże modele językowe takie jak ChatGPT, Claude czy Google Gemini są trenowane w procesie zwanym predykcją kolejnego tokena, gdzie model uczy się przewidywać najbardziej prawdopodobne słowo następujące po danej sekwencji. W trakcie treningu modele te są celowo optymalizowane, by minimalizować perpleksję na danych uczących, co niezamierzenie skutkuje niskim burstiness jako produktem ubocznym. Gdy model wielokrotnie napotyka określoną strukturę zdania w danych treningowych, uczy się ją odtwarzać z wysokim prawdopodobieństwem, co prowadzi do spójnych, przewidywalnych długości zdań. Badania Netus AI i Winston AI pokazują, że modele AI wykazują charakterystyczny stylometryczny odcisk palca, na który składają się jednolite konstrukcje zdań, nadużywanie wyrażeń łączących (takich jak “Ponadto”, “Dlatego”, “Dodatkowo”) oraz preferowanie strony biernej nad czynną. Oparcie modeli na rozkładach prawdopodobieństwa powoduje, że dążą one do najczęstszych wzorców z danych treningowych, a nie eksplorują pełnego wachlarza konstrukcji zdań. Powoduje to paradoks: im więcej danych model przyswaja, tym bardziej odtwarza powszechne schematy, a więc jego burstiness maleje. Dodatkowo modele AI nie wykazują spontaniczności ani zmienności emocjonalnej charakterystycznej dla pisania ludzkiego — nie piszą inaczej, gdy są podekscytowane, sfrustrowane czy chcą coś zaakcentować. Utrzymują raczej jednolity poziom stylistyczny, odzwierciedlający statystyczny środek rozkładu treningowego.
Platformy detekcji AI wprowadziły analizę burstiness jako kluczowy element swoich algorytmów rozpoznawania, choć na różnym poziomie zaawansowania. Wczesne systemy detekcji mocno opierały się na burstiness i perpleksji jako podstawowych miarach, lecz badania wykazały istotne ograniczenia tego podejścia. Według Pangram Labs detektory oparte na perpleksji i burstiness wykazują fałszywe alarmy podczas analizy tekstów z danych treningowych modeli językowych — przykładowo Deklaracja Niepodległości często jest oznaczana jako generowana przez AI, gdyż występuje tak często w danych treningowych, że model przypisuje jej jednolicie niską perpleksję. Współczesne systemy, takie jak Winston AI i Pangram, stosują hybrydowe podejścia, łącząc analizę burstiness z modelami głębokiego uczenia wytrenowanymi na szerokim zbiorze tekstów ludzkich i AI. Analizują one jednocześnie wiele wymiarów lingwistycznych: zmienność struktury zdań, bogactwo słownictwa, wzorce interpunkcji, spójność kontekstową i zgodność semantyczną. Włączenie burstiness do szerszych ram detekcyjnych znacząco poprawiło trafność — Winston AI deklaruje 99,98% skuteczności w odróżnianiu treści AI od ludzkich dzięki analizie wielu markerów, a nie wyłącznie burstiness. Niemniej wskaźnik ten pozostaje wartościowy jako jeden z elementów całościowej strategii detekcyjnej, zwłaszcza w połączeniu z analizą perpleksji, wzorców stylometrycznych i spójności semantycznej.
Związek między burstiness a czytelnością jest dobrze udokumentowany w badaniach lingwistycznych. Wyniki Flesch Reading Ease i Flesch-Kincaid Grade Level, mierzące przystępność tekstu, silnie korelują z wzorcami burstiness. Teksty o wyższym burstiness zwykle osiągają lepsze wyniki czytelności, gdyż zróżnicowana długość zdań zapobiega zmęczeniu poznawczemu i utrzymuje uwagę odbiorcy. Gdy odbiorca napotyka powtarzalny rytm podobnych zdań, jego mózg adaptuje się do przewidywalnego schematu, co prowadzi do spadku zaangażowania i zrozumienia. Z kolei wysoki burstiness wywołuje efekt przypływów i odpływów, który utrzymuje uwagę czytelnika, różnicując obciążenie poznawcze — krótkie zdania dostarczają szybkich, łatwo przyswajalnych informacji, a dłuższe pozwalają na rozwinięcie złożonych idei. Badania Metrics Masters wskazują, że wysoki burstiness zapewnia ok. 15–20% lepszą retencję pamięciową w porównaniu z tekstami o niskiej zmienności, ponieważ zróżnicowany rytm skuteczniej koduje informacje w pamięci długotrwałej. Zasada ta dotyczy wszystkich typów treści: blogów, prac naukowych, tekstów marketingowych i dokumentacji technicznej. Jednak zależność ta nie jest liniowa — nadmierny burstiness, stawiający zmienność ponad klarowność, może sprawić, że tekst będzie rwany i trudny do śledzenia. Optymalnym rozwiązaniem jest celowa zmienność, gdzie wybór struktur zdań służy sensowi treści i intencji komunikacyjnej autora, a nie wyłącznie podnoszeniu wskaźnika.
Pomimo szerokiego zastosowania w systemach detekcji AI, detekcja oparta na burstiness ma istotne ograniczenia, które powinni znać badacze i praktycy. Pangram Labs opublikowało szczegółowe badania wskazujące pięć głównych wad: po pierwsze, teksty z danych treningowych AI są błędnie klasyfikowane jako generowane przez AI, gdyż modele optymalizowane są pod kątem niskiej perpleksji na tych danych; po drugie, wartości burstiness są względne względem danego modelu, więc różne modele tworzą różne profile perpleksji; po trzecie, zamknięte modele komercyjne, jak ChatGPT, nie udostępniają prawdopodobieństw tokenów, co uniemożliwia kalkulację perpleksji; po czwarte, osoby niebędące rodzimymi użytkownikami angielskiego są nadmiernie oznaczane jako AI z powodu bardziej jednolitych struktur zdań; po piąte, detektory oparte na burstiness nie potrafią iteracyjnie się doskonalić wraz z napływem nowych danych. Badanie Stanford 2023 na esejach TOEFL wykazało, że około 26% tekstów osób niebędących rodzimymi użytkownikami angielskiego zostało błędnie oznaczonych jako AI przez detektory oparte na perpleksji i burstiness, podczas gdy dla rodzimych użytkowników wskaźnik ten wynosił tylko 2%. Ta stronniczość rodzi poważne dylematy etyczne w edukacji, gdzie detekcja AI jest używana do oceny prac studentów. Ponadto szablonowe treści w marketingu, publikacjach naukowych i dokumentacji technicznej naturalnie wykazują niski burstiness z powodu wymogów stylu i struktury, co prowadzi do fałszywych alarmów w tych dziedzinach. Ograniczenia te skłoniły do rozwoju bardziej wyrafinowanych metod detekcji, traktujących burstiness jako jeden z wielu sygnałów, a nie ostateczny wskaźnik generacji AI.
Wzorce burstiness znacznie różnią się w zależności od gatunku i kontekstu pisania, odzwierciedlając odmienne cele komunikacyjne i oczekiwania odbiorców. Pisanie akademickie, szczególnie w naukach ścisłych, charakteryzuje się niższym burstiness, ponieważ autorzy stosują ścisłe wytyczne i szablony dla jasności i precyzji. Dokumenty prawne, specyfikacje techniczne i artykuły naukowe stawiają na spójność i przewidywalność zamiast stylistycznej zmienności, co skutkuje naturalnie niższymi wskaźnikami burstiness. Z kolei pisarstwo kreatywne, dziennikarstwo i copywriting marketingowy wykazują zazwyczaj wysoki burstiness, ponieważ te gatunki stawiają na angażowanie odbiorcy i efekt emocjonalny poprzez zróżnicowane tempo i rytm. Literatura piękna szczególnie często stosuje dramatyczne zmiany długości zdań, by budować napięcie i kontrolować tempo narracji. Komunikacja biznesowa zajmuje pozycję pośrednią — profesjonalne e-maile i raporty utrzymują umiarkowany burstiness, by zachować równowagę między jasnością a zaangażowaniem. Wskaźnik Flesch-Kincaid Grade Level pokazuje, że teksty akademickie dla odbiorców z wyższym wykształceniem często wykorzystują dłuższe i bardziej złożone zdania, co może pozornie obniżać burstiness; jednak zmienność w budowie zdań podrzędnych i współrzędnych nadal generuje istotny burstiness. Zrozumienie tych różnic kontekstowych jest kluczowe dla systemów detekcji AI, które powinny uwzględniać konwencje gatunkowe, by unikać fałszywych alarmów. Instrukcja techniczna o jednolicie długich zdaniach nie powinna być oznaczona jako AI tylko z powodu niskiego burstiness — niska zmienność odzwierciedla bowiem właściwy wybór stylistyczny dla tej formy, a nie dowód generacji maszynowej.
Przyszłość analizy burstiness w detekcji AI zmierza w kierunku bardziej zaawansowanych, kontekstowych rozwiązań, które uznają ograniczenia tego wskaźnika, jednocześnie wykorzystując jego zalety. W miarę jak duże modele językowe stają się coraz bardziej zaawansowane, zaczynają one uwzględniać zmienność burstiness w swoich generowanych tekstach, przez co detekcja oparta wyłącznie na tym wskaźniku staje się mniej skuteczna. Badacze rozwijają adaptacyjne systemy detekcji, łączące analizę burstiness ze spójnością semantyczną, poprawnością merytoryczną i adekwatnością kontekstową. Pojawienie się narzędzi humanizujących AI, które celowo zwiększają burstiness i inne cechy ludzkie, świadczy o nieustannym wyścigu pomiędzy technikami detekcji a metodami omijania wykrywania. Eksperci przewidują jednak, że naprawdę skuteczna detekcja AI będzie oparta na metodach kryptograficznej weryfikacji i śledzeniu pochodzenia, a nie wyłącznie na analizie lingwistycznej. Dla twórców treści i organizacji wniosek jest jasny: zamiast traktować burstiness jako wskaźnik do manipulacji, należy rozwijać autentyczny, zróżnicowany styl pisania naturalnie odzwierciedlający ludzką komunikację. Platforma monitorująca AmICited wyznacza nowy standard w tej dziedzinie, analizując obecność marek w odpowiedziach AI oraz cechy językowe tych cytowań. W miarę jak AI zyskuje na popularności w generowaniu i dystrybucji treści, rozumienie burstiness i pokrewnych wskaźników staje się coraz istotniejsze dla zachowania autentyczności marek, uczciwości akademickiej i rozróżnienia między tekstem ludzkim a maszynowym. Ewolucja w stronę wielosygnałowych systemów detekcyjnych sugeruje, że burstiness pozostanie ważnym elementem zaawansowanych narzędzi monitorujących AI, choć jego rola stanie się bardziej zniuansowana i zależna od kontekstu.
Burstiness i perpleksja to uzupełniające się wskaźniki wykorzystywane w detekcji AI. Perpleksja mierzy przewidywalność poszczególnych słów w tekście, podczas gdy burstiness ocenia zmienność struktury i długości zdań w całym dokumencie. Pisanie ludzkie zazwyczaj cechuje się wyższą perpleksją (bardziej nieprzewidywalny dobór słów) i wyższym burstiness (bardziej zróżnicowane struktury zdań), natomiast tekst generowany przez AI wykazuje niższe wartości obu wskaźników, ponieważ opiera się na wzorcach statystycznych z danych treningowych.
Wysoki burstiness tworzy rytmiczny przepływ, który zwiększa zaangażowanie czytelnika i ułatwia zrozumienie. Gdy autorzy przeplatają krótkie, mocne zdania z dłuższymi, złożonymi, utrzymują zainteresowanie odbiorcy i zapobiegają monotonii. Badania pokazują, że zróżnicowana struktura zdań poprawia zapamiętywanie i sprawia, że treść wydaje się bardziej autentyczna i rozmowna. Niski burstiness, charakteryzujący się jednolitą długością zdań, może sprawiać, że tekst wydaje się robotyczny i trudny do śledzenia, obniżając zarówno wskaźniki czytelności, jak i zaangażowania odbiorców.
Burstiness można celowo zwiększać poprzez świadome różnicowanie struktury zdań, jednak sztuczne działanie często skutkuje nienaturalnie brzmiącym tekstem, który może uruchomić inne mechanizmy wykrywające. Nowoczesne detektory AI analizują wiele cech lingwistycznych poza burstiness, takich jak spójność semantyczna, adekwatność kontekstowa i wzorce stylometryczne. Autentyczny burstiness wynika naturalnie z prawdziwego pisania ludzkiego i odzwierciedla unikalny styl autora, podczas gdy wymuszona zmienność zwykle nie posiada organicznej jakości charakterystycznej dla tekstów pisanych przez człowieka.
Osoby, dla których angielski nie jest językiem ojczystym, często osiągają niższe wartości burstiness, ponieważ ich wzorce pisania odzwierciedlają bardziej ograniczone słownictwo i prostsze strategie budowy zdań. Uczący się języka zwykle stosują bardziej jednolite, przewidywalne struktury zdań podczas zdobywania biegłości, unikając złożonych zdań i różnorodnych schematów składniowych. Tworzy to profil stylometryczny podobny do tekstu generowanego przez AI, prowadząc do fałszywych alarmów w systemach detekcji AI. Badanie Stanford University z 2023 roku dotyczące esejów TOEFL potwierdziło tę tendencję, wskazując na istotne ograniczenie metod wykrywania opartych na burstiness.
Duże modele językowe są trenowane na ogromnych zbiorach danych, gdzie uczą się przewidywać następne słowo na podstawie wzorców statystycznych. Podczas treningu modele te są optymalizowane tak, aby minimalizować perpleksję na danych uczących, co niezamierzenie prowadzi do powstawania jednolitych struktur zdań i przewidywalnych sekwencji słów. Skutkuje to konsekwentnie niskim burstiness, ponieważ modele generują tekst, wybierając statystycznie najbardziej prawdopodobne kombinacje słów, zamiast stosować zróżnicowaną, spontaniczną konstrukcję zdań charakterystyczną dla pisania ludzkiego. Zależność modeli od rozkładów prawdopodobieństwa tworzy jednolity podpis stylistyczny.
AmICited śledzi, jak marki i domeny pojawiają się w odpowiedziach generowanych przez AI na platformach takich jak ChatGPT, Perplexity i Google AI Overviews. Zrozumienie burstiness pomaga systemowi monitorującemu AmICited odróżnić autentyczne cytowania ludzkie od treści generowanych przez AI, które wspominają Twoją markę. Analizując wzorce burstiness wraz z innymi wskaźnikami lingwistycznymi, AmICited dostarcza dokładniejsze informacje o tym, czy Twoja marka jest cytowana w rzeczywiście ludzkich treściach, czy w odpowiedziach generowanych przez AI, umożliwiając lepsze zarządzanie reputacją.
Autorzy mogą organicznie poprawiać burstiness, świadomie różnicując konstrukcję zdań przy zachowaniu jasności i celu. Techniki obejmują naprzemienne stosowanie prostych zdań oznajmujących i złożonych zdań z wieloma członami, używanie środków retorycznych, takich jak równoważniki zdań i pauzy dla podkreślenia, oraz zróżnicowanie długości akapitów. Kluczem jest to, aby zmienność służyła sensowi treści, a nie istniała sama dla siebie. Czytanie na głos, studiowanie różnorodnych stylów pisania i redagowanie z uwzględnieniem rytmu naturalnie rozwijają umiejętność tworzenia autentycznego, angażującego tekstu o wysokim burstiness.
Zacznij śledzić, jak chatboty AI wspominają Twoją markę w ChatGPT, Perplexity i innych platformach. Uzyskaj praktyczne spostrzeżenia, aby poprawić swoją obecność w AI.
Dowiedz się, czym jest burstiness w treściach generowanych przez AI, jak różni się od wzorców pisania ludzi i dlaczego jest ważny dla wykrywania AI oraz autenty...
Dyskusja społeczności na temat burstiness w wykrywaniu treści AI – co to oznacza, jak wpływa na widoczność w AI i czy twórcy treści powinni to optymalizować....
Wskaźnik Perplexity mierzy przewidywalność tekstu w modelach językowych. Dowiedz się, jak ten kluczowy wskaźnik NLP kwantyfikuje niepewność modelu, jak jest obl...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.