
Czym jest meta tag noai i jak chroni Twoje treści przed AI?
Dowiedz się, czym jest meta tag noai, jak działa w celu zapobiegania zbieraniu danych treningowych przez AI, jakie ma ograniczenia oraz jak wdrożyć go na swojej...
6 min czytania

HTML-owy meta tag, który sygnalizuje systemom szkolącym AI i robotom internetowym, że zawartość strony nie powinna być wykorzystywana do trenowania modeli uczenia maszynowego. Oryginalnie wprowadzony przez DeviantArt, służy jako mechanizm ochrony treści i sygnał rezygnacji dla twórców obawiających się nieautoryzowanego zbierania danych przez AI.
HTML-owy meta tag, który sygnalizuje systemom szkolącym AI i robotom internetowym, że zawartość strony nie powinna być wykorzystywana do trenowania modeli uczenia maszynowego. Oryginalnie wprowadzony przez DeviantArt, służy jako mechanizm ochrony treści i sygnał rezygnacji dla twórców obawiających się nieautoryzowanego zbierania danych przez AI.
Meta tag NoAI to mechanizm ochrony treści wdrażany jako HTML-owy meta tag, który sygnalizuje systemom szkolącym AI i robotom internetowym, że zawartość strony nie powinna być wykorzystywana do trenowania modeli uczenia maszynowego. Oryginalnie wprowadzony przez DeviantArt we wrześniu 2022 roku, dyrektywa NoAI pojawiła się jako oddolna odpowiedź na obawy artystów, których prace były masowo pobierane do trenowania generatywnych modeli AI bez ich zgody lub wynagrodzenia. Meta tag działa przez dodanie prostego deklaracji HTML do nagłówka strony, jasno komunikując systemom AI, że dana treść jest wyłączona z wykorzystania do celów szkoleniowych. Choć w większości jurysdykcji nie jest prawnie wiążący, tag NoAI stanowi ważny mechanizm rezygnacji dla twórców chcących chronić swoją własność intelektualną w czasach coraz bardziej agresywnego zbierania danych przez AI.
Roboty internetowe (zwane również botami, pająkami lub scraperami) to zautomatyzowane programy, które systematycznie przeszukują internet, podążając za linkami i pobierając treści w celu indeksowania, analizy lub pozyskiwania danych do różnych zastosowań. Roboty te działają, czytając plik robots.txt znajdujący się w głównym katalogu strony, który zawiera instrukcje dotyczące tego, które obszary witryny powinny być dostępne lub niedostępne dla automatycznych odwiedzających. Plik robots.txt wykorzystuje konkretne dyrektywy, takie jak User-agent, Disallow i Allow, aby komunikować uprawnienia dla robotów, jednak przestrzeganie tych zasad jest całkowicie dobrowolne i zależy od tego, czy deweloper bota zdecyduje się do nich stosować. Oprócz robots.txt strony mogą komunikować swoje preferencje za pomocą nagłówków HTTP i meta tagów, które stanowią dodatkowe sygnały dotyczące praw i ograniczeń dotyczących wykorzystania treści. Różne typy robotów w różnym stopniu respektują te sygnały:
| Typ robota | Przestrzeganie robots.txt | Respektowanie meta tagów | Wykorzystanie do szkolenia AI |
|---|---|---|---|
| Wyszukiwarki | Wysokie | Wysokie | Ograniczone |
| Boty AI | Średnie | Średnie | Tak |
| Komercyjne scrapery | Niskie | Niskie | Różnie |
| Boty akademickie | Wysokie | Średnie | Tylko badania |
| Złośliwe boty | Brak | Brak | Nieograniczone |
Dyrektywy noai i noimageai pełnią pokrewne, lecz różniące się zastosowaniem funkcje w ochronie treści. Kluczowa różnica tkwi w ich zakresie i specyfice. Dyrektywa noai to szeroki sygnał wskazujący, że cała zawartość strony — w tym tekst, obrazy, kod i inne media — nie powinna być wykorzystywana do szkolenia AI. Jest więc odpowiednia dla witryn z mieszanym typem treści lub chcących kompleksowej ochrony. Dyrektywa noimageai natomiast dotyczy wyłącznie ochrony treści graficznych, pozwalając na ewentualne wykorzystanie tekstu i innych nieobrazkowych materiałów do szkolenia AI, przy jednoczesnym zabezpieczeniu zasobów wizualnych przed generatywnymi modelami obrazów. To rozróżnienie istotne jest zwłaszcza dla stron, które chcą umożliwić indeksowanie tekstu przez AI (np. dla wyszukiwarek czy dostępności), ale chronić materiały wizualne. Oto różnice we wdrożeniu:
<!-- Pełna ochrona wszystkich treści -->
<meta name="robots" content="noai">
<!-- Ochrona wyłącznie obrazów -->
<meta name="robots" content="noimageai">
<!-- Połączone podejście dla maksymalnej jasności -->
<meta name="robots" content="noai, noimageai">
Meta tag NoAI można wdrożyć na kilka sposobów, a wybór zależy od infrastruktury technicznej i konkretnych potrzeb. Najprostszą metodą jest dodanie meta tagu bezpośrednio do sekcji <head> w kodzie HTML, co stosuje dyrektywę do pojedynczych stron i pozwala na indywidualizację. W przypadku witryn z wieloma stronami lub przy chęci wdrożenia na całej stronie, bardziej skalowalnym rozwiązaniem jest ustawienie dyrektywy w nagłówkach odpowiedzi HTTP, co działa globalnie bez konieczności edycji każdej strony osobno. Dodatkowo, plik robots.txt może zawierać dyrektywy skierowane do konkretnych botów AI, choć ta metoda jest mniej ustandaryzowana niż meta tagi czy nagłówki. Oto trzy podstawowe metody wdrożenia:
<!-- Metoda 1: HTML-owy meta tag (najpopularniejsza) -->
<head>
<meta name="robots" content="noai">
</head>
# Metoda 2: Dyrektywa w robots.txt
User-agent: *
Disallow: /
X-Robots-Tag: noai
# Metoda 3: Nagłówek HTTP (przez .htaccess lub konfigurację serwera)
X-Robots-Tag: noai
Dla serwera Apache, dodaj do pliku .htaccess:
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
Dla serwera Nginx, dodaj do bloku serwera:
add_header X-Robots-Tag "noai" always;
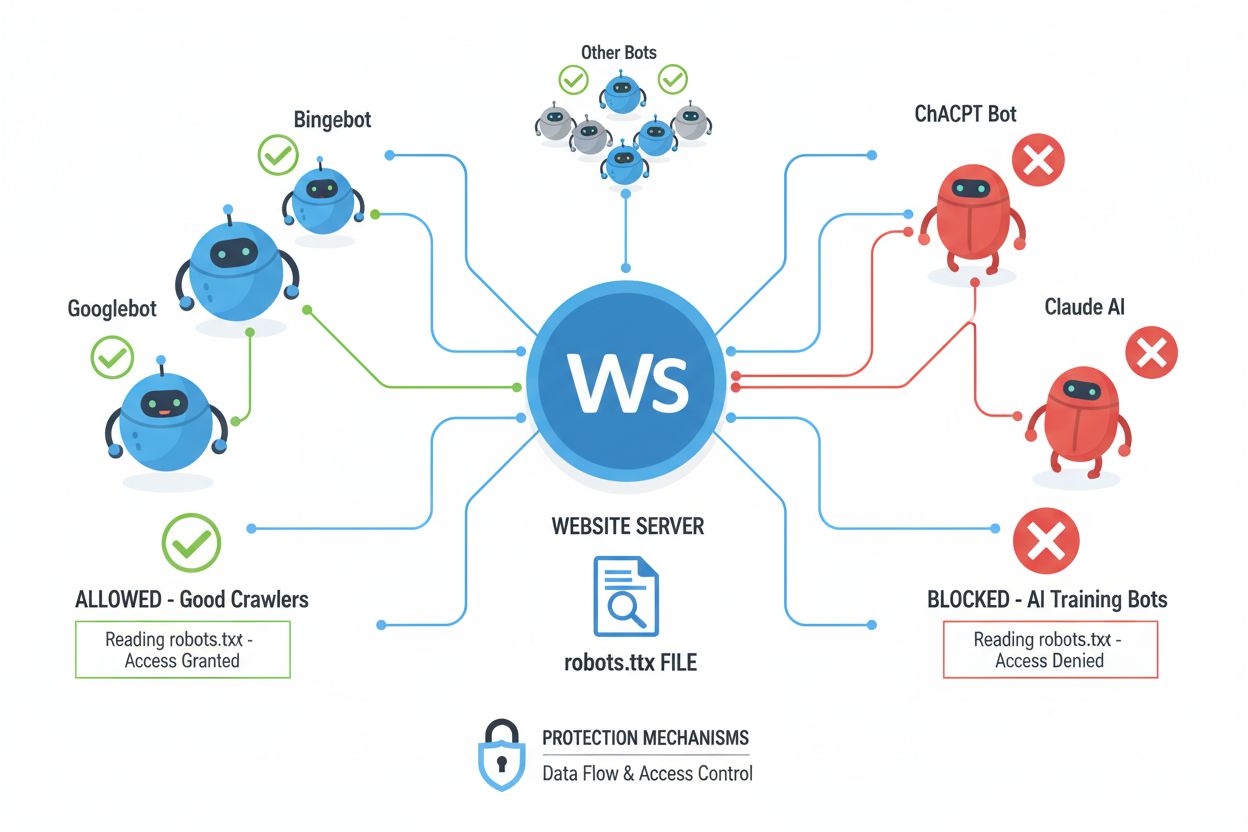
Choć meta tag NoAI to ważny krok w kierunku ochrony treści, działa on na zasadzie systemu honorowego, czyli zależy wyłącznie od tego, czy deweloperzy AI i scrapery zdecydują się go respektować. Największe firmy AI, takie jak OpenAI, Google i Anthropic, zaczęły uwzględniać dyrektywy NoAI w swoich botach, jednak nieuczciwi gracze i nieautoryzowane scrapery często ignorują te sygnały, przez co tag nie chroni przed zdeterminowanymi złodziejami danych. Skuteczność NoAI jest dodatkowo ograniczona tym, że zapobiega jedynie przyszłemu wykorzystaniu treści do szkolenia; nie usuwa danych już zebranych i zaimplementowanych w istniejących modelach, ani nie zapewnia środków prawnych w razie naruszeń. Poziom przestrzegania dyrektywy znacznie się różni w zależności od systemu AI — jedne ją respektują, inne celowo ją obchodzą, przez co NoAI jest użytecznym, lecz niepełnym rozwiązaniem. Tag nie chroni przed bezpośrednimi pobraniami, zrzutami ekranu czy ręcznym kopiowaniem treści i nie zapobiega wykorzystaniu treści przez konkurencję, która po prostu zignoruje dyrektywę. Dlatego NoAI powinien być traktowany jako jedna z warstw kompleksowej strategii ochrony treści, a nie jako rozwiązanie całościowe.
Meta tag NoAI zdobył szerokie zastosowanie wśród największych firm i platform AI – OpenAI, Google oraz Stability AI publicznie zobowiązały się do respektowania dyrektywy w swoich procesach szkoleniowych. Wdrożenie NoAI przez DeviantArt wpłynęło na szerszą branżową dyskusję o etycznym rozwoju AI i zgodzie twórców, zwiększając świadomość zarówno wśród deweloperów AI, jak i twórców treści. Jednak wdrożenie pozostaje niejednolite w branży — mniejsze firmy AI, badacze akademiccy i komercyjni scraperzy przestrzegają dyrektyw w różnym stopniu. Pojawiające się konkurencyjne standardy, takie jak C2PA (Coalition for Content Provenance and Authenticity) oraz dyskusje o maszynowo czytelnych wyrażeniach praw, wskazują, że branża dąży do bardziej zaawansowanych, prawnie wspieranych mechanizmów ochrony treści, wykraczających poza dobrowolne meta tagi. Organizacje branżowe i ciała standaryzujące aktywnie pracują nad formalizacją tych zabezpieczeń, przewidując, że przyszłe regulacje AI mogą wymagać wyraźnego przestrzegania preferencji twórców treści — co potencjalnie przekształci NoAI z dobrowolnego sygnału w prawnie egzekwowalny wymóg.
Wdrażanie ochrony NoAI powinno być częścią wielowarstwowego podejścia do bezpieczeństwa treści, a nie samodzielnym rozwiązaniem – łączy strategie techniczne, prawne i monitoring dla pełnej ochrony. Aby zmaksymalizować skuteczność, rozważ następujące najlepsze praktyki:
Ponadto regularnie audytuj wdrożenie ochrony treści, aby upewnić się, że wszystkie strony zawierają odpowiednie dyrektywy, i rozważ użycie narzędzi automatycznych do skanowania swoich treści w publicznych zestawach danych AI i repozytoriach szkoleniowych. Udokumentuj wdrożenie NoAI w polityce zarządzania treścią i komunikuj te zabezpieczenia swoim odbiorcom, aby wiedzieli, jakie kroki podejmujesz w celu ochrony ich pracy, jeśli prowadzisz platformę z treściami użytkowników.
Dyrektywa noai chroni wszystkie rodzaje treści (tekst, obrazy, kod) przed szkoleniem AI, podczas gdy noimageai dotyczy wyłącznie ochrony treści obrazkowych. Użyj noai dla pełnej ochrony, a noimageai, gdy chcesz pozwolić na indeksowanie tekstu, ale zabezpieczyć materiały wizualne przed generatywnymi modelami obrazów.
Nie, meta tag NoAI działa na zasadzie honorowego przestrzegania i zależy od tego, czy deweloperzy AI zdecydują się go respektować. Duże firmy, takie jak OpenAI i Google, szanują go, ale nieuczciwi gracze i nieautoryzowane scrapery często ignorują te sygnały, przez co stanowi jedynie jedną warstwę ochrony, a nie pełne rozwiązanie.
Możesz go wdrożyć na trzy sposoby: dodać HTML-owy meta tag do nagłówka strony, ustawić odpowiednie nagłówki HTTP na serwerze lub umieścić dyrektywy w pliku robots.txt. Najpopularniejszą i najprostszą metodą dla właścicieli stron jest zastosowanie meta tagu w HTML.
Najwięksi gracze AI, w tym OpenAI (ChatGPT), Google, Anthropic (Claude) oraz Stability AI, publicznie zobowiązali się do respektowania dyrektyw NoAI w swoich procesach szkoleniowych. Jednak przestrzeganie różni się w przypadku mniejszych firm AI, badaczy akademickich oraz komercyjnych scraperów.
Tak, można używać obu jednocześnie dla maksymalnej skuteczności. Meta tag NoAI i dyrektywy w robots.txt współpracują, przekazując preferencje dotyczące ochrony treści różnym rodzajom botów i systemów.
Połącz NoAI z innymi metodami ochrony, w tym nagłówkami HTTP, regułami robots.txt, znakowaniem wodnym, kontrolą dostępu oraz prawnymi warunkami korzystania. Monitoruj swoje treści w zestawach danych AI i rozważ użycie narzędzi do śledzenia nieautoryzowanego wykorzystania.
Choć jest szeroko stosowany przez największe firmy AI, NoAI nie jest jeszcze formalnym standardem W3C. Jednak organizacje branżowe pracują nad bardziej zaawansowanymi standardami, takimi jak C2PA i maszynowo czytelne wyrażenia praw, które mogą w przyszłości zapewnić podstawę prawną.
NoAI jest najskuteczniejszy w połączeniu z innymi metodami, takimi jak robots.txt, nagłówki HTTP, znakowanie wodne, kontrola dostępu i ochrona prawna. Żadna pojedyncza metoda nie zapewnia pełnej ochrony, dlatego zaleca się podejście warstwowe dla kompleksowego zabezpieczenia treści.
Śledź, które systemy AI cytują Twoją markę i treści dzięki platformie monitoringu AI AmICited. Dowiedz się dokładnie, jak Twoja praca jest wykorzystywana przez ChatGPT, Perplexity, Google AI Overviews i inne systemy AI.
Dowiedz się, czym jest meta tag noai, jak działa w celu zapobiegania zbieraniu danych treningowych przez AI, jakie ma ograniczenia oraz jak wdrożyć go na swojej...
Dyskusja społeczności na temat meta tagu noai i tego, czy skutecznie chroni treści przed wykorzystywaniem do trenowania AI. Użytkownicy dzielą się doświadczenia...

Dowiedz się, jak wdrożyć meta tagi noai i noimageai, aby kontrolować dostęp crawlerów AI do treści Twojej strony. Kompletny przewodnik po nagłówkach kontroli do...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.