
Reconhecimento de Entidades
O Reconhecimento de Entidades é uma capacidade de IA em PLN que identifica e categoriza entidades nomeadas em textos. Saiba como funciona, suas aplicações em mo...
12 min de leitura

Explore como sistemas de IA reconhecem e processam entidades em textos. Aprenda sobre modelos NER, arquiteturas transformer e aplicações reais do entendimento de entidades.
A compreensão de entidades tornou-se uma capacidade fundamental em sistemas modernos de inteligência artificial, permitindo que máquinas identifiquem e compreendam os principais agentes, locais e conceitos em textos não estruturados. Desde o impulsionamento de motores de busca que entendem a intenção do usuário até chatbots que respondem a perguntas complexas sobre pessoas e organizações específicas, o reconhecimento de entidades forma a base da interação significativa entre humanos e computadores. Essa capacidade técnica é crítica em diversos setores—instituições financeiras a utilizam para monitoramento de conformidade, sistemas de saúde para gestão de prontuários de pacientes, e plataformas de e-commerce dependem dela para entender menções de produtos e feedback de clientes. Compreender como sistemas de IA extraem e interpretam entidades é essencial para quem desenvolve ou implementa aplicações de PLN em ambientes de produção.
O Reconhecimento de Entidades Nomeadas (NER) é a tarefa de PLN que identifica e classifica entidades nomeadas—unidades específicas e significativas de informação—em textos, em categorias predefinidas. Essas entidades representam os elementos concretos que carregam peso semântico na linguagem: pessoas que realizam ações, organizações que tomam decisões, locais onde eventos acontecem, expressões temporais que ancoram eventos no tempo, valores monetários que quantificam transações e produtos que são comprados e vendidos. A classificação de entidades é importante porque transforma textos brutos em conhecimento estruturado, sobre o qual as máquinas podem raciocinar e agir; sem isso, um sistema não consegue distinguir “Apple a empresa” de “apple a fruta”, nem entender que “John Smith” e “J. Smith” referem-se à mesma pessoa. A capacidade de classificar entidades com precisão possibilita aplicações como construção de grafos de conhecimento, extração de informações, resposta a perguntas e detecção de relacionamentos.
| Tipo de Entidade | Definição | Exemplo |
|---|---|---|
| PESSOA | Seres humanos individuais | “Steve Jobs”, “Marie Curie” |
| ORGANIZAÇÃO | Empresas, instituições, grupos | “Microsoft”, “Nações Unidas”, “Universidade Harvard” |
| LOCALIZAÇÃO | Lugares e regiões geográficas | “Nova York”, “Rio Amazonas”, “Vale do Silício” |
| DATA | Expressões temporais e períodos de tempo | “15 de janeiro de 2024”, “próxima terça-feira”, “3º trimestre de 2023” |
| DINHEIRO | Valores monetários e moedas | “$50 milhões”, “€100”, “5000 ienes” |
| PRODUTO | Bens, serviços e criações | “iPhone 15”, “Windows 11”, “ChatGPT” |
Sistemas modernos de IA processam entidades por meio de um sofisticado pipeline multiestágio que começa com a tokenização, dividindo o texto bruto em tokens discretos que servem como unidades fundamentais para o processamento subsequente. Cada token é então convertido em uma representação numérica via word embeddings—vetores densos que capturam significado semântico—que são alimentados em arquiteturas de redes neurais projetadas para entender contexto e relações. Modelos baseados em transformers, que se tornaram a arquitetura dominante em PLN contemporâneo, processam sequências inteiras em paralelo (e não sequencialmente), permitindo capturar dependências de longo alcance e relações contextuais complexas, cruciais para o entendimento preciso de entidades. O mecanismo de self-attention dentro dos Transformers permite que cada token pondere dinamicamente a importância de todos os outros tokens na sequência, criando representações contextuais ricas onde o significado de uma palavra é moldado pelo contexto ao redor; é por isso que “banco” é entendido de forma diferente em “banco do rio” e “banco de poupança”. Modelos de linguagem pré-treinados como BERT e GPT aprendem padrões linguísticos gerais a partir de grandes corpora antes de serem ajustados para tarefas de reconhecimento de entidades, permitindo que aproveitem representações aprendidas de sintaxe, semântica e conhecimento de mundo. A camada final dos sistemas de reconhecimento de entidades geralmente utiliza uma abordagem de rotulação de sequência—frequentemente implementada como um Conditional Random Field (CRF) ou um cabeçalho de classificação simples—que atribui rótulos de entidade a cada token com base nas representações contextuais aprendidas pela rede neural. Essa arquitetura permite que sistemas de IA entendam não só quais entidades estão presentes, mas como elas se relacionam e que papéis desempenham dentro do contexto mais amplo do texto.
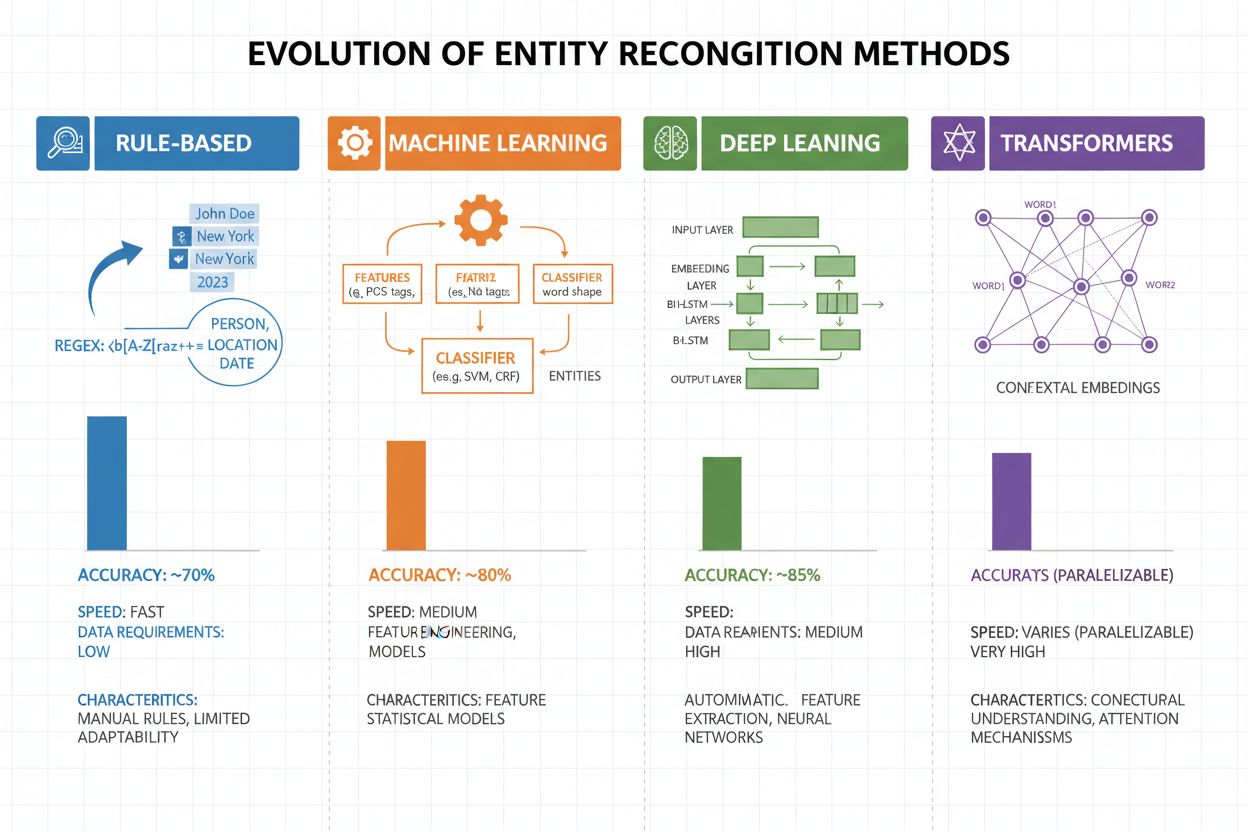
O reconhecimento de entidades evoluiu dramaticamente nas últimas duas décadas, indo de abordagens simples baseadas em regras para arquiteturas neurais sofisticadas. Sistemas iniciais dependiam de regras e dicionários criados manualmente, usando expressões regulares e correspondência de padrões para identificar entidades—métodos interpretáveis e com pouca necessidade de dados de treinamento, mas com baixa capacidade de generalização e alta manutenção. O advento do aprendizado de máquina trouxe abordagens supervisionadas como SVM e CRF, que aprendiam com dados rotulados por meio de engenharia de características, melhorando significativamente a precisão, embora ainda exigissem especialistas para desenhar boas features. Métodos de deep learning, especialmente LSTMs e BiLSTMs, automatizaram a extração de características ao aprender representações diretamente do texto bruto, atingindo precisão substancialmente maior sem engenharia manual, mas exigindo conjuntos de dados rotulados maiores. Modelos baseados em transformers como BERT e RoBERTa revolucionaram o campo ao explorar mecanismos de self-attention para capturar dependências de longo alcance e nuances contextuais, atingindo resultados de ponta (BERT alcançou F1 de 90,9% no CoNLL-2003) e viabilizando transfer learning a partir de grandes modelos pré-treinados. A relação entre complexidade e precisão mudou drasticamente: enquanto sistemas baseados em regras ainda são valiosos em ambientes com recursos limitados e domínios altamente especializados, modelos transformers agora dominam quando há recursos computacionais e dados rotulados suficientes, com alternativas leves como o DistilBERT oferecendo uma solução intermediária para sistemas de produção com restrições de latência.
Modelos baseados em transformers transformaram fundamentalmente o reconhecimento de entidades ao substituir o processamento sequencial por mecanismos de self-attention paralelos que consideram simultaneamente todos os tokens de uma sentença, proporcionando compreensão contextual mais rica do que arquiteturas anteriores. BERT e seus variantes (RoBERTa, DistilBERT, ALBERT) utilizam pré-treinamento bidirecional em grandes corpora não rotulados, aprendendo representações universais de linguagem que capturam informações sintáticas e semânticas antes de serem ajustados em tarefas NER com conjuntos rotulados relativamente pequenos. O paradigma de pré-treinamento e ajuste fino é especialmente poderoso para reconhecimento de entidades: modelos pré-treinados em bilhões de tokens desenvolvem representações robustas da estrutura da linguagem e padrões de entidades, podendo ser adaptados a domínios específicos com apenas milhares de exemplos rotulados, reduzindo dramaticamente a necessidade de dados em comparação ao treinamento do zero. Transformers se destacam no entendimento de entidades através do seu mecanismo de multi-head attention, que permite que diferentes cabeças de atenção se especializem em diferentes tipos de relações entre entidades—algumas cabeças podem focar em limites sintáticos, outras em associações semânticas entre entidades e seus contextos. O reconhecimento de entidades multilíngue foi revolucionado por modelos como mBERT e XLM-RoBERTa, pré-treinados em mais de 100 idiomas simultaneamente, permitindo transferência zero-shot e few-shot para idiomas com poucos recursos e vinculação de entidades entre línguas. Modelos emergentes como o GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) vão além ao permitir reconhecimento de entidades baseado em instruções, onde modelos podem identificar tipos de entidades arbitrários especificados em prompts de linguagem natural sem ajuste específico, representando uma tendência para sistemas de entendimento de entidades mais flexíveis e generalizáveis.
Apesar do progresso notável, sistemas de reconhecimento de entidades enfrentam desafios reais persistentes que limitam sua aplicação prática, sendo ambiguidade e sensibilidade ao contexto alguns dos mais difíceis—“Apple” exige interpretação se se refere à fruta ou à empresa de tecnologia, dependendo do contexto, e até modelos avançados têm dificuldades para desambiguar semanticamente textos ruidosos ou ambíguos. Entidades fora do vocabulário (OOV) representam outro desafio fundamental: modelos treinados em conjuntos padrão podem nunca encontrar entidades raras, nomes próprios de domínios emergentes ou variantes com erros de digitação, levando a classificações equivocadas ou não reconhecimento. Adaptação de domínio continua problemática porque modelos treinados em notícias (como o CoNLL-2003) frequentemente apresentam baixo desempenho em textos biomédicos, jurídicos ou de redes sociais, onde a distribuição de entidades e padrões linguísticos diferem muito, requerendo reanotação cara e ajuste fino para cada novo domínio. Erros de detecção de limites—quando sistemas identificam corretamente que uma entidade existe, mas determinam de forma errada o início ou fim—são comuns em entidades com várias palavras e estruturas aninhadas, como distinguir “Nova York” de “Nova York City” ou lidar com entidades como “Chief Executive Officer da Apple Inc.” Complexidades multilíngues agravam esses desafios, já que diferentes idiomas têm convenções de capitalização, estruturas morfológicas e padrões de nomeação próprios, fazendo com que modelos treinados em inglês frequentemente falhem quando aplicados a idiomas com propriedades linguísticas distintas. Escassez de dados para domínios especializados como nomes de doenças raras, tecnologias emergentes ou terminologia corporativa proprietária cria um gargalo em que o custo da anotação manual é proibitivo, forçando a escolha entre aceitar menor precisão ou investir pesado na coleta de treinamento específico.
A compreensão de entidades tornou-se indispensável em diversos setores, transformando a forma como organizações extraem valor de textos não estruturados. Em extração de informações e construção de grafos de conhecimento, o reconhecimento de entidades possibilita o preenchimento automatizado de bancos de dados estruturados a partir de documentos, impulsionando motores de busca e sistemas de recomendação que entendem relações entre pessoas, locais e conceitos. Organizações de saúde utilizam compreensão de entidades para identificar nomes de medicamentos, dosagens, sintomas e dados demográficos de pacientes em anotações clínicas, melhorando a tomada de decisão e permitindo sistemas de farmacovigilância em larga escala. Instituições financeiras usam reconhecimento de entidades para extrair símbolos de ações, valores monetários e eventos de mercado de notícias e relatórios de resultados, permitindo que sistemas de trading algorítmico e plataformas de gestão de risco reajam a informações relevantes em tempo real. Empresas de tecnologia jurídica aplicam compreensão de entidades para identificar automaticamente partes, datas, obrigações e cláusulas de responsabilidade em contratos, reduzindo o tempo de análise de documentos de semanas para horas. Plataformas de atendimento ao cliente e chatbots usam reconhecimento de entidades para extrair intenções do usuário e contexto relevante—como números de pedido, nomes de produtos e tipos de problemas—permitindo encaminhamento mais preciso e resolução mais rápida. Plataformas de e-commerce empregam compreensão de entidades para identificar nomes de produtos, marcas, características e especificações em avaliações de clientes e buscas, melhorando a descoberta de produtos e a personalização. Sistemas de recomendação de conteúdo usam reconhecimento de entidades para entender com quais entidades os usuários interagem, viabilizando filtragem colaborativa e recomendações baseadas em conteúdo mais sofisticadas, que aumentam engajamento e receita.
Implementar um sistema de compreensão de entidades de nível produtivo exige atenção cuidadosa à preparação dos dados, seleção de modelo e avaliação. Comece com dados anotados de alta qualidade: estabeleça definições claras de tipos de entidade, use métricas de acordo entre anotadores para garantir consistência e busque ao menos 500-1000 exemplos rotulados por tipo de entidade, embora aplicações específicas possam exigir mais. A escolha do modelo depende das restrições: sistemas baseados em regras oferecem interpretabilidade e baixa latência para domínios bem definidos, modelos tradicionais de aprendizado de máquina (CRF, SVM) fornecem bom desempenho com dados moderados, enquanto modelos baseados em transformers (BERT, RoBERTa) entregam precisão de ponta, porém exigem mais recursos computacionais e dados. Estratégias de treinamento e ajuste fino devem incluir técnicas de aumento de dados para lidar com desbalanceamento de classes, validação cruzada para evitar overfitting e ajuste cuidadoso de hiperparâmetros como taxa de aprendizado e tamanho do batch. Avalie seu sistema usando precisão (entidades corretas identificadas), recall (entidades encontradas dentre todas as existentes) e F1-score (média harmônica equilibrando ambos), com métricas separadas por tipo de entidade para identificar pontos fracos. Considerações de implantação incluem exigências de latência (processamento em lote vs. tempo real), necessidades de escalabilidade e integração com pipelines de dados existentes, enquanto o monitoramento pós-implantação deve acompanhar deriva de desempenho, taxas de falso positivo e feedback do usuário para acionar ciclos de re-treinamento.
O ecossistema de ferramentas de compreensão de entidades oferece soluções para todos os portes e necessidades. Bibliotecas open-source como spaCy fornecem pipelines NER prontos para produção com desempenho impressionante (F1-score de 89,22% em benchmarks padrão) e excelente documentação, tornando-se ideais para equipes com experiência em machine learning; NLTK possui valor educacional e recursos básicos de NER; e Hugging Face Transformers disponibiliza modelos pré-treinados de ponta que podem ser ajustados para domínios específicos com poucas linhas de código. Serviços gerenciados em nuvem eliminam preocupações de infraestrutura: Google Cloud Natural Language API, AWS Comprehend e IBM Watson NLP oferecem reconhecimento de entidades pré-treinado com suporte a múltiplos idiomas e tipos de entidade, lidando automaticamente com escalabilidade e integrando-se facilmente a pipelines de dados em nuvem. Frameworks especializados como Flair (construído em PyTorch com excelente suporte para rotulação de sequências) e DeepPavlov (com modelos pré-treinados para vários idiomas e domínios) atendem pesquisadores e equipes que precisam de mais customização que bibliotecas generalistas. A decisão entre construir soluções personalizadas e usar ferramentas prontas depende da sensibilidade dos seus dados (on-premise vs. nuvem), níveis de precisão exigidos, especificidade do domínio e expertise da equipe: utilize APIs gerenciadas para aplicações generalistas com tipos de entidades padrão, aproveite bibliotecas open-source para customização específica do domínio com dados internos e construa modelos próprios apenas quando as soluções existentes não atingirem seus requisitos de precisão ou latência.
O futuro da compreensão de entidades está sendo moldado por grandes modelos de linguagem que trazem flexibilidade e desempenho sem precedentes para a tarefa. Modelos como GPT-4 e Claude demonstram notáveis capacidades de reconhecimento de entidades few-shot e zero-shot, permitindo identificar tipos de entidades personalizados com apenas alguns exemplos ou até mesmo descrições em linguagem natural, reduzindo dramaticamente o ônus de anotação e acelerando o retorno do investimento. A compreensão multimodal de entidades surge como uma fronteira, combinando texto, imagens e dados estruturados para reconhecer entidades em documentos, faturas e páginas web com contexto mais rico, viabilizando aplicações como processamento automático de documentos e busca visual. Avanços em processamento em tempo real impulsionados por distilação de modelos e implantação em edge tornam o reconhecimento sofisticado de entidades viável em dispositivos móveis e sistemas IoT, abrindo novas aplicações em realidade aumentada, tradução em tempo real e sistemas autônomos. Avanços em ajuste fino específico de domínio estão criando modelos especializados para domínios biomédico, jurídico e financeiro que superam modelos generalistas por ordens de grandeza, com técnicas como pré-treinamento adaptado ao domínio e transfer learning tornando isso cada vez mais acessível. À medida que essas tecnologias amadurecem, a compreensão de entidades se tornará uma camada fundamental invisível nos sistemas de IA, permitindo que máquinas compreendam o mundo com entendimento semântico semelhante ao humano e abrindo possibilidades que estamos apenas começando a imaginar.
À medida que sistemas de IA como ChatGPT, Perplexity e Google AI Overviews se integram cada vez mais à forma como a informação é descoberta e consumida, entender como esses sistemas reconhecem e referenciam entidades—including sua marca—torna-se crítico. A compreensão de entidades é o mecanismo pelo qual sistemas de IA identificam e processam menções de empresas, produtos, pessoas e conceitos. Ao monitorar como sistemas de IA entendem e fazem referência à sua marca por meio do reconhecimento de entidades, você obtém insights sobre:
É exatamente isso que o AmICited monitora—acompanhando como sistemas de IA reconhecem e fazem referência à sua marca como entidade em várias plataformas de IA. Ao entender o reconhecimento de entidades, você entende melhor como sistemas de IA percebem e comunicam sobre o seu negócio.
O reconhecimento de entidades (NER) identifica e classifica entidades em um texto (por exemplo, 'Apple' como ORGANIZAÇÃO), enquanto a vinculação de entidades conecta essas entidades a bases de conhecimento ou referências canônicas (por exemplo, vinculando 'Apple' à página da Apple Inc. na Wikipédia). O reconhecimento de entidades é o primeiro passo; a vinculação de entidades adiciona fundamentação semântica.
Modelos avançados baseados em transformers, como o BERT, alcançam 90,9% de F1-score em benchmarks padrão como o CoNLL-2003. No entanto, a precisão varia significativamente de acordo com o domínio—modelos treinados em notícias apresentam desempenho ruim em textos biomédicos ou de redes sociais. A precisão no mundo real depende fortemente de adaptação ao domínio e da qualidade dos dados.
Sim, modelos multilíngues como mBERT e XLM-RoBERTa suportam mais de 100 idiomas simultaneamente. Entretanto, o desempenho varia conforme o idioma devido a diferenças em convenções de capitalização, morfologia e dados de treinamento disponíveis. Modelos específicos por idioma geralmente superam os multilíngues em aplicações críticas.
Sistemas baseados em regras usam padrões e dicionários criados manualmente (rápidos, interpretáveis, porém frágeis). Sistemas baseados em ML aprendem a partir de dados rotulados (mais flexíveis, melhor generalização, porém exigem dados de treinamento e engenharia de características). Abordagens modernas de deep learning automatizam a extração de características, alcançando precisão superior.
Sistemas baseados em regras precisam apenas de definições de padrões. Modelos tradicionais de ML requerem de 300 a 500 exemplos rotulados. Modelos baseados em transformers funcionam com 800+ exemplos, mas se beneficiam do transfer learning—modelos pré-treinados podem atingir bons resultados com apenas 100-200 exemplos específicos do domínio através de ajuste fino.
Os principais desafios incluem: ambiguidade (mesma palavra com significados diferentes), entidades fora do vocabulário, adaptação de domínio (modelos treinados em um domínio falham em outro), erros na detecção de limites, complexidades multilíngues e escassez de dados para domínios especializados. Estes exigem projeto de sistema cuidadoso e ajustes específicos de domínio.
O contexto é crucial—'banco' significa coisas diferentes em 'banco do rio' e 'banco de poupança'. Transformers modernos usam self-attention para ponderar o contexto dos tokens ao redor, possibilitando desambiguar entidades com base no contexto linguístico e semântico. O manuseio inadequado do contexto é uma das principais fontes de erro no reconhecimento de entidades.
Os próximos avanços incluem: grandes modelos de linguagem permitindo reconhecimento de entidades zero-shot, compreensão multimodal combinando texto e imagens, processamento em tempo real em dispositivos de borda e avanços em ajuste fino específico de domínio. A compreensão de entidades se tornará uma camada fundamental invisível, permitindo às máquinas compreender o mundo com entendimento semântico semelhante ao humano.
O AmICited rastreia menções de entidades em sistemas de IA como ChatGPT, Perplexity e Google AI Overviews. Entenda como a IA compreende e faz referência à sua marca em tempo real.
O Reconhecimento de Entidades é uma capacidade de IA em PLN que identifica e categoriza entidades nomeadas em textos. Saiba como funciona, suas aplicações em mo...

Saiba como os sistemas de IA identificam, extraem e compreendem os relacionamentos entre entidades em textos. Descubra técnicas de extração de relacionamentos, ...
Discussão da comunidade sobre como sistemas de IA entendem entidades e relacionamentos. Orientação prática sobre otimização de entidades para melhor visibilidad...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.