Meta Tags NoAI: Controlando o Acesso de IA por Meio de Cabeçalhos
Aprenda a implementar as meta tags noai e noimageai para controlar o acesso de crawlers de IA ao conteúdo do seu site. Guia completo sobre cabeçalhos de controle de acesso de IA e métodos de implementação.
Publicado em Jan 3, 2026.Última modificação em Jan 3, 2026 às 3:24 am
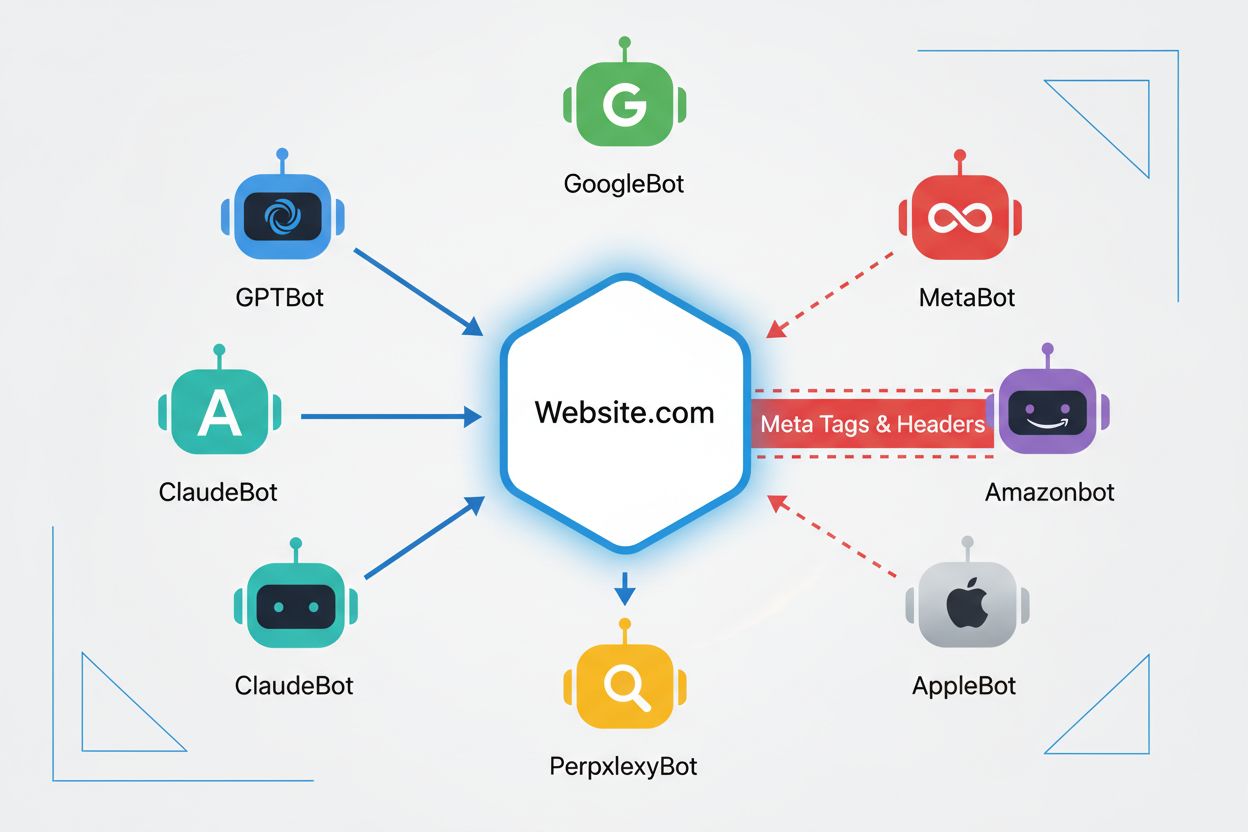
Web crawlers são programas automatizados que navegam sistematicamente pela internet, coletando informações de sites. Historicamente, esses bots eram operados principalmente por motores de busca como o Google, cujo Googlebot rastreava páginas, indexava conteúdos e direcionava usuários de volta aos sites por meio dos resultados de busca—criando uma relação mutuamente benéfica. No entanto, o surgimento dos crawlers de IA mudou fundamentalmente essa dinâmica. Diferente dos bots tradicionais de motores de busca, que fornecem tráfego de referência em troca de acesso ao conteúdo, crawlers de treinamento de IA consomem enormes quantidades de conteúdo web para construir conjuntos de dados para grandes modelos de linguagem, muitas vezes retornando pouco ou nenhum tráfego aos publishers. Essa mudança tornou as meta tags—pequenas diretivas HTML que comunicam instruções aos crawlers—ainda mais importantes para criadores de conteúdo que desejam manter controle sobre como seu trabalho é utilizado por sistemas de inteligência artificial.
O Que São as Meta Tags NoAI e NoImageAI?
As meta tags noai e noimageai são diretivas criadas pelo DeviantArt em 2022 para ajudar criadores de conteúdo a evitar que seu trabalho seja usado para treinar geradores de imagens por IA. Essas tags funcionam de maneira semelhante à tradicional diretiva noindex, que instrui motores de busca a não indexarem uma página. A diretiva noai sinaliza que nenhum conteúdo da página deve ser usado para treinamento de IA, enquanto noimageai impede especificamente que imagens sejam usadas no treinamento de modelos de IA. Você pode implementar essas tags na seção head do seu HTML usando a seguinte sintaxe:
<!-- Bloqueia todo o conteúdo do treinamento de IA --><metaname="robots"content="noai">
<!-- Bloqueia apenas imagens do treinamento de IA --><metaname="robots"content="noimageai">
<!-- Bloqueia conteúdo e imagens --><metaname="robots"content="noai, noimageai">
Aqui está uma tabela comparativa de diferentes diretivas de meta tags e seus propósitos:
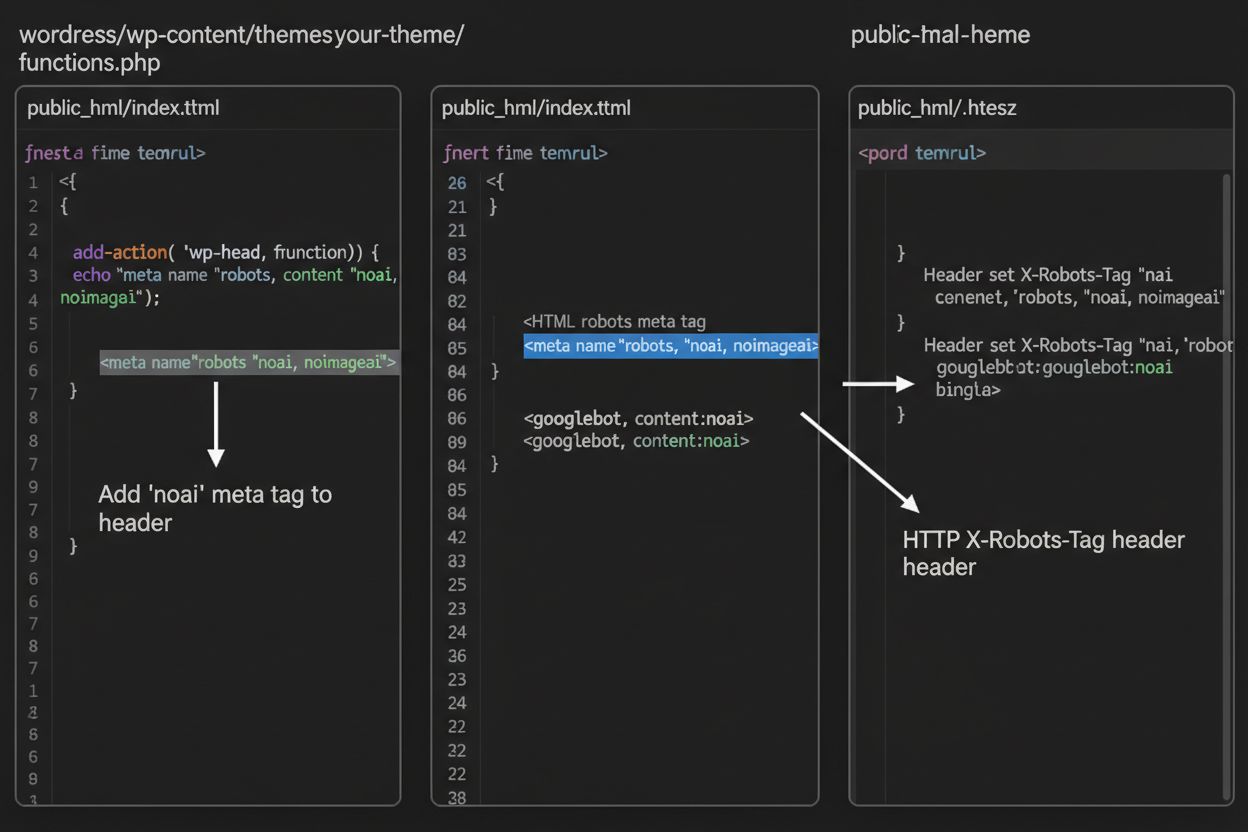
Enquanto meta tags são inseridas diretamente no seu HTML, cabeçalhos HTTP oferecem um método alternativo para comunicar diretivas de crawler no nível do servidor. O cabeçalho X-Robots-Tag pode incluir as mesmas diretivas das meta tags, mas opera de forma diferente—é enviado na resposta HTTP antes do conteúdo da página ser entregue. Essa abordagem é especialmente valiosa para controlar o acesso a arquivos não-HTML como PDFs, imagens e vídeos, onde não é possível inserir meta tags HTML.
Para servidores Apache, você pode definir cabeçalhos X-Robots-Tag no seu arquivo .htaccess:
<IfModulemod_headers.c> Header set X-Robots-Tag "noai, noimageai"</IfModule>
Para servidores NGINX, adicione o cabeçalho na configuração do servidor:
Cabeçalhos proporcionam proteção global em todo o seu site ou diretórios específicos, tornando-os ideais para estratégias abrangentes de controle de acesso de IA.
Como Crawlers de IA Respeitam (ou Ignoram) Essas Diretivas
A eficácia das tags noai e noimageai depende inteiramente de os crawlers optarem por respeitá-las. Crawlers bem-comportados de grandes empresas de IA geralmente honram essas diretivas:
Crawlers menores/desconhecidos - Podem não respeitar as diretivas
No entanto, bots mal-comportados e crawlers maliciosos podem ignorar deliberadamente essas diretivas, pois não existe um mecanismo de imposição. Diferente do robots.txt, que os motores de busca concordaram em respeitar como padrão do setor, noai não é um padrão oficial da web, o que significa que crawlers não têm obrigação de cumprir. Por isso, especialistas em segurança recomendam uma abordagem em camadas que combine múltiplos métodos de proteção em vez de depender apenas das meta tags.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Métodos de Implementação em Diferentes Plataformas
A implementação das tags noai e noimageai varia conforme a plataforma do seu site. Veja instruções passo a passo para as plataformas mais comuns:
1. WordPress (via functions.php)
Adicione este código ao arquivo functions.php do seu tema filho:
3. Squarespace
Acesse Configurações > Avançado > Injeção de Código e adicione na seção Header:
<metaname="robots"content="noai, noimageai">
4. Wix
Vá em Configurações > Código Personalizado, clique em “Adicionar Código Personalizado”, cole a meta tag, selecione “Head” e aplique a todas as páginas.
Cada plataforma oferece diferentes níveis de controle—WordPress permite implementação por página via plugins, enquanto Squarespace e Wix oferecem opções globais para todo o site. Escolha o método que melhor se adapta ao seu nível técnico e necessidades específicas.
Limitações e Eficácia das Tags NoAI
Embora as tags noai e noimageai representem um avanço importante na proteção de criadores de conteúdo, elas apresentam limitações significativas. Primeiro, não são padrões oficiais da web—o DeviantArt as criou como iniciativa comunitária, ou seja, não existe especificação formal ou mecanismo de imposição. Segundo, a conformidade é totalmente voluntária. Crawlers bem-comportados de grandes empresas respeitam essas diretivas, mas bots e scrapers mal-intencionados podem ignorá-las sem consequências. Terceiro, a falta de padronização faz com que a adoção varie. Algumas empresas menores de IA e organizações de pesquisa talvez nem conheçam essas diretivas, muito menos implementem suporte para elas. Por fim, as meta tags sozinhas não impedem agentes mal-intencionados de raspar seu conteúdo. Um crawler malicioso pode ignorar completamente suas diretivas, tornando essenciais camadas adicionais de proteção para uma segurança abrangente do conteúdo.
Combinando Meta Tags com robots.txt e Outros Métodos
A estratégia mais eficaz de controle de acesso de IA utiliza múltiplas camadas de proteção em vez de depender de um único método. Veja uma comparação entre diferentes abordagens de proteção:
Método
Escopo
Eficácia
Dificuldade
Meta Tags (noai)
Por página
Média (adesão voluntária)
Fácil
robots.txt
Todo o site
Média (apenas consultivo)
Fácil
Cabeçalhos X-Robots-Tag
Nível servidor
Média-Alta (todos arquivos)
Média
Regras de Firewall
Nível de rede
Alta (bloqueio na infra)
Difícil
Allowlisting de IP
Nível de rede
Muito Alta (fontes verificadas)
Difícil
Uma estratégia abrangente pode incluir: (1) implementar meta tags noai em todas as páginas, (2) adicionar regras no robots.txt bloqueando crawlers de treinamento de IA conhecidos, (3) definir cabeçalhos X-Robots-Tag no servidor para arquivos não-HTML e (4) monitorar logs do servidor para identificar crawlers que ignoram suas diretivas. Essa abordagem em camadas dificulta bastante a vida de agentes mal-intencionados, mantendo a compatibilidade com crawlers legítimos que respeitam suas preferências.
Monitoramento e Verificação da Conformidade dos Crawlers
Após implementar as tags noai e outras diretivas, você deve verificar se os crawlers realmente estão respeitando suas regras. O método mais direto é checar seus logs de acesso ao servidor para atividade de crawlers. Em servidores Apache, você pode buscar crawlers específicos:
Se encontrar solicitações de crawlers que você bloqueou, isso indica que estão ignorando suas diretivas. Em servidores NGINX, cheque /var/log/nginx/access.log usando o mesmo comando grep. Além disso, ferramentas como o Cloudflare Radar fornecem visibilidade sobre os padrões de tráfego de crawlers de IA em seu site, mostrando quais bots são mais ativos e como seu comportamento muda ao longo do tempo. O monitoramento regular dos logs—ao menos mensalmente—ajuda a identificar novos crawlers e verificar se suas medidas de proteção estão funcionando como esperado.
O Futuro dos Padrões de Controle de Acesso de IA
Atualmente, noai e noimageai estão em uma área cinzenta: são amplamente reconhecidas e respeitadas por grandes empresas de IA, mas permanecem não-oficiais e sem padronização. No entanto, há um movimento crescente em direção à padronização formal. O W3C (World Wide Web Consortium) e vários grupos do setor estão discutindo como criar padrões oficiais de controle de acesso de IA que dariam a essas diretivas o mesmo peso de padrões estabelecidos como o robots.txt. Se noai se tornar um padrão oficial da web, a conformidade passaria a ser uma prática esperada pelo setor, em vez de voluntária, aumentando significativamente sua eficácia. Esse esforço de padronização reflete uma mudança mais ampla na forma como a indústria de tecnologia enxerga os direitos dos criadores de conteúdo e o equilíbrio entre desenvolvimento de IA e proteção dos publishers. À medida que mais publishers adotam essas tags e exigem proteções mais robustas, aumenta a probabilidade de padronização oficial, tornando o controle de acesso de IA tão fundamental para a governança da web quanto as regras de indexação dos motores de busca.
Perguntas frequentes
O que é a meta tag noai e como ela funciona?
A meta tag noai é uma diretiva colocada na seção head do HTML do seu site que sinaliza para crawlers de IA que seu conteúdo não deve ser usado para treinar modelos de inteligência artificial. Ela funciona comunicando sua preferência para bots de IA 'bem-comportados', embora não seja um padrão oficial da web e alguns crawlers possam ignorá-la.
Noai é um padrão oficial da web?
Não, noai e noimageai não são padrões oficiais da web. Elas foram criadas pelo DeviantArt como uma iniciativa comunitária para ajudar criadores de conteúdo a protegerem seus trabalhos contra o treinamento de IA. No entanto, grandes empresas de IA como OpenAI, Anthropic e outras começaram a respeitar essas diretivas em seus crawlers.
Quais crawlers de IA respeitam a meta tag noai?
Principais crawlers de IA, incluindo GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) e outros respeitam a diretiva noai. Entretanto, alguns crawlers menores ou mal-comportados podem ignorá-la, por isso uma abordagem de proteção em camadas é recomendada.
Qual a diferença entre meta tags e cabeçalhos HTTP para controle de IA?
Meta tags são inseridas na seção head do seu HTML e se aplicam a páginas individuais, enquanto cabeçalhos HTTP (X-Robots-Tag) são definidos no nível do servidor e podem ser aplicados globalmente ou a tipos de arquivos específicos. Cabeçalhos são eficazes para arquivos não-HTML como PDFs e imagens, tornando-os mais versáteis para proteção abrangente.
Posso implementar tags noai no WordPress?
Sim, você pode implementar tags noai no WordPress por vários métodos: adicionando código ao arquivo functions.php do seu tema, usando um plugin como WPCode ou por meio de construtores de página como Divi e Elementor. O método functions.php é o mais comum e envolve adicionar um hook simples para inserir a meta tag no header do seu site.
Devo bloquear todos os crawlers de IA ou apenas crawlers de treinamento?
Isso depende dos seus objetivos de negócio. Bloquear crawlers de treinamento protege seu conteúdo de ser usado no desenvolvimento de modelos de IA. No entanto, bloquear crawlers de busca como OAI-SearchBot pode reduzir sua visibilidade em resultados de busca por IA e plataformas de descoberta. Muitos publishers usam uma abordagem seletiva que bloqueia crawlers de treinamento e permite crawlers de busca.
Como posso verificar se crawlers de IA estão respeitando minhas diretivas noai?
Você pode verificar os logs do seu servidor para atividade de crawlers usando comandos como grep para buscar agentes de usuário de bots específicos. Ferramentas como o Cloudflare Radar oferecem visibilidade sobre padrões de tráfego de crawlers de IA. Monitore seus logs regularmente para ver se crawlers bloqueados ainda estão acessando seu conteúdo, o que indicaria que estão ignorando suas diretivas.
O que devo fazer se crawlers ignorarem minhas meta tags noai?
Se crawlers ignorarem suas meta tags, implemente camadas adicionais de proteção, incluindo regras no robots.txt, cabeçalhos HTTP X-Robots-Tag e bloqueio no nível do servidor via .htaccess ou regras de firewall. Para verificação mais forte, use allowlisting de IP para permitir apenas solicitações de endereços IP verificados publicados pelas principais empresas de IA.
Como Identificar Crawlers de IA em Logs de Servidor: Guia Completo de Detecção
Aprenda como identificar e monitorar crawlers de IA como GPTBot, PerplexityBot e ClaudeBot em seus logs de servidor. Descubra strings de user-agent, métodos de ...
Quais Crawlers de IA Devo Permitir? Guia Completo para 2025
Saiba quais crawlers de IA permitir ou bloquear no seu robots.txt. Guia abrangente cobrindo GPTBot, ClaudeBot, PerplexityBot e mais de 25 crawlers de IA com exe...
Cartão de Referência de Crawlers de IA: Todos os Bots em um Relance
Guia completo de referência sobre crawlers e bots de IA. Identifique GPTBot, ClaudeBot, Google-Extended e mais de 20 outros crawlers de IA com user agents, taxa...
18 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.