
URLs Canônicos e IA: Prevenindo Problemas de Conteúdo Duplicado
Aprenda como URLs canônicos previnem problemas de conteúdo duplicado em sistemas de busca por IA. Descubra as melhores práticas para implementar canônicos, melh...
7 min de leitura

Saiba como a republicação de conteúdo cria problemas de conteúdo duplicado que prejudicam a visibilidade na busca por IA mais severamente do que na busca tradicional. Descubra salvaguardas técnicas e melhores práticas.
Republicar conteúdo em múltiplos canais, plataformas e formatos é uma estratégia legítima e frequentemente necessária para maximizar o alcance e o engajamento. No entanto, essa prática cria uma tensão fundamental com a forma como os sistemas de busca—especialmente os movidos por IA—processam e classificam o conteúdo. O desafio não é se você pode republicar; é se está fazendo isso de uma forma que não sabota sua visibilidade nos resultados de busca por IA. Diferente dos motores de busca tradicionais, que evoluíram mecanismos sofisticados de detecção de duplicidade ao longo de décadas, sistemas de IA lidam com conteúdo duplicado de outra forma, criando novos riscos para os quais muitos editores ainda não se adaptaram.
De acordo com a documentação técnica da Microsoft sobre o Copilot e busca por IA, “LLMs agrupam URLs quase duplicados em um único cluster e então escolhem uma página para representar o conjunto.” Esse comportamento de agrupamento é fundamentalmente diferente de como o algoritmo PageRank do Google distribui autoridade entre páginas duplicadas. Ao invés de consolidar sinais, sistemas de IA tomam uma decisão binária: selecionam uma página representativa de um cluster de conteúdos semelhantes e ignoram, em grande parte, as demais. Esse processo de seleção nem sempre é previsível ou baseado na versão que você gostaria que ranqueasse. O algoritmo considera fatores como atualidade, qualidade do conteúdo, sinais técnicos e autoridade do domínio—mas a ponderação desses fatores permanece opaca. O que torna isso especialmente problemático é que sistemas de IA podem selecionar uma versão desatualizada se as diferenças entre as páginas forem mínimas a ponto de o algoritmo de agrupamento não detectar variações significativas.
| Aspecto | Busca Tradicional | Busca por IA |
|---|---|---|
| Tratamento de Duplicatas | Consolida sinais de autoridade | Agrupa e seleciona um representante único |
| Risco de Penalidade | Possível ação manual | Sem penalidade, mas há diluição de visibilidade |
| Reconhecimento de Atualizações | Propagação gradual de sinais | Pode não reconhecer atualizações se diferenças forem mínimas |
| Eficiência de Rastreamento | Desperdício de orçamento em duplicatas | Reduz prioridade de rastreamento para duplicatas |
| Respeito ao Canônico | Honrado, mas não garantido | Crítico para seleção de cluster |
Republicar sem as devidas salvaguardas introduz três riscos interligados que impactam diretamente a visibilidade na IA:
Diluição de Sinais de Intenção: Quando o mesmo conteúdo aparece em múltiplas URLs, o sistema de IA recebe sinais conflitantes sobre qual versão melhor responde à consulta do usuário. Ao invés de concentrar autoridade em uma única URL, seus sinais se espalham pelo cluster. Essa diluição reduz a pontuação de confiança que os sistemas de IA atribuem ao seu conteúdo ao decidir se ele deve ser incluído nas respostas. Um conteúdo que poderia ser fonte primária vira uma consideração secundária porque o sistema não consegue determinar com confiança qual versão é a autoritativa.
Risco de Representação: A seleção do sistema de IA sobre qual página representa o seu cluster de conteúdo pode não estar alinhada com seus objetivos de negócio. Você pode republicar um post em uma rede de sindicação esperando que aquela versão gere tráfego, apenas para o sistema de IA selecionar a versão original do seu domínio—ou pior, selecionar a versão sindicada que não faz link de volta para seu site. Esse desalinhamento faz com que sua estratégia de republicação atue contra seus objetivos de visibilidade ao invés de ampliá-los.
Latência de Atualização e Obsolescência: Quando você atualiza seu conteúdo original mas as versões republicadas permanecem inalteradas, sistemas de IA podem selecionar uma versão desatualizada como página representativa. O algoritmo de agrupamento nem sempre reconhece que uma versão é mais recente ou precisa do que outras, especialmente se as mudanças forem incrementais e não estruturais. Isso cria um cenário em que seu conteúdo mais atual e preciso fica invisível enquanto uma versão antiga representa sua expertise para os sistemas de IA.
O erro mais comum na republicação ocorre quando o conteúdo é sindicado para plataformas terceiras sem implementação de tags canônicas. Considere um cenário típico: uma empresa de software B2B publica um guia abrangente em seu blog e depois o sindica para publicações do setor como Medium, LinkedIn e agregadores de notícias especializados. Cada plataforma hospeda o conteúdo idêntico sob URLs diferentes. Sem tags canônicas apontando para o original, o algoritmo de agrupamento dos sistemas de IA trata todas as versões como igualmente autoritativas. A plataforma de sindicação pode ter maior autoridade de domínio, levando o sistema de IA a selecionar essa versão como página representativa. Agora seu conteúdo original—a versão que você otimizou, atualizou e construiu backlinks—fica invisível nos resultados de busca por IA. O tráfego e a autoridade fluem para a plataforma de sindicação e não para sua propriedade. Esse cenário se repete milhares de vezes diariamente na indústria editorial, com editores sabotando sem saber sua própria visibilidade por não implementarem uma única tag HTML.
Conteúdo específico de campanha cria um problema de duplicidade ainda mais insidioso quando republicado em vários canais. Uma equipe de marketing lança uma landing page otimizada para uma promoção específica e republica variações desse conteúdo em newsletters, redes sociais, anúncios pagos e sites de parceiros. Cada versão contém pequenas diferenças de texto, CTAs ou formatação—mas o conteúdo e a intenção principais permanecem idênticos. Sistemas de IA reconhecem esses conteúdos como quase duplicados e os agrupam. O problema se intensifica quando as páginas de campanha são republicadas sem implementação canônica adequada. O sistema de IA pode selecionar a versão da newsletter (sem rastreamento de conversão) como página representativa, ou a versão do parceiro que não beneficia suas métricas. Além disso, quando as campanhas terminam e as páginas são arquivadas ou deletadas, o sistema de IA pode já ter selecionado uma versão agora inativa como página representativa, criando uma situação onde seu conteúdo fica invisível ou direciona usuários para experiências quebradas.
A republicação regional adiciona complexidade, pois a detecção de conteúdo duplicado precisa considerar necessidades legítimas de localização. Uma empresa com operações em vários países pode publicar o mesmo conteúdo central em diferentes idiomas ou com variações regionais. Sem a implementação adequada, essas versões regionais competem entre si no agrupamento da IA. Considere uma empresa SaaS que publica um guia de funcionalidades em inglês no domínio dos EUA e depois o republica no domínio do Reino Unido com grafia britânica e preços regionais. O sistema de IA agrupa esses conteúdos como duplicados, podendo selecionar a versão dos EUA mesmo para usuários do Reino Unido. A solução exige a implementação de tags hreflang que sinalizam relações regionais para os sistemas de IA, embora a eficácia do hreflang na busca por IA ainda seja menos comprovada do que na busca tradicional.
<!-- Na versão dos EUA (example.com/feature-guide) -->
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
<!-- Na versão do Reino Unido (example.co.uk/feature-guide) -->
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
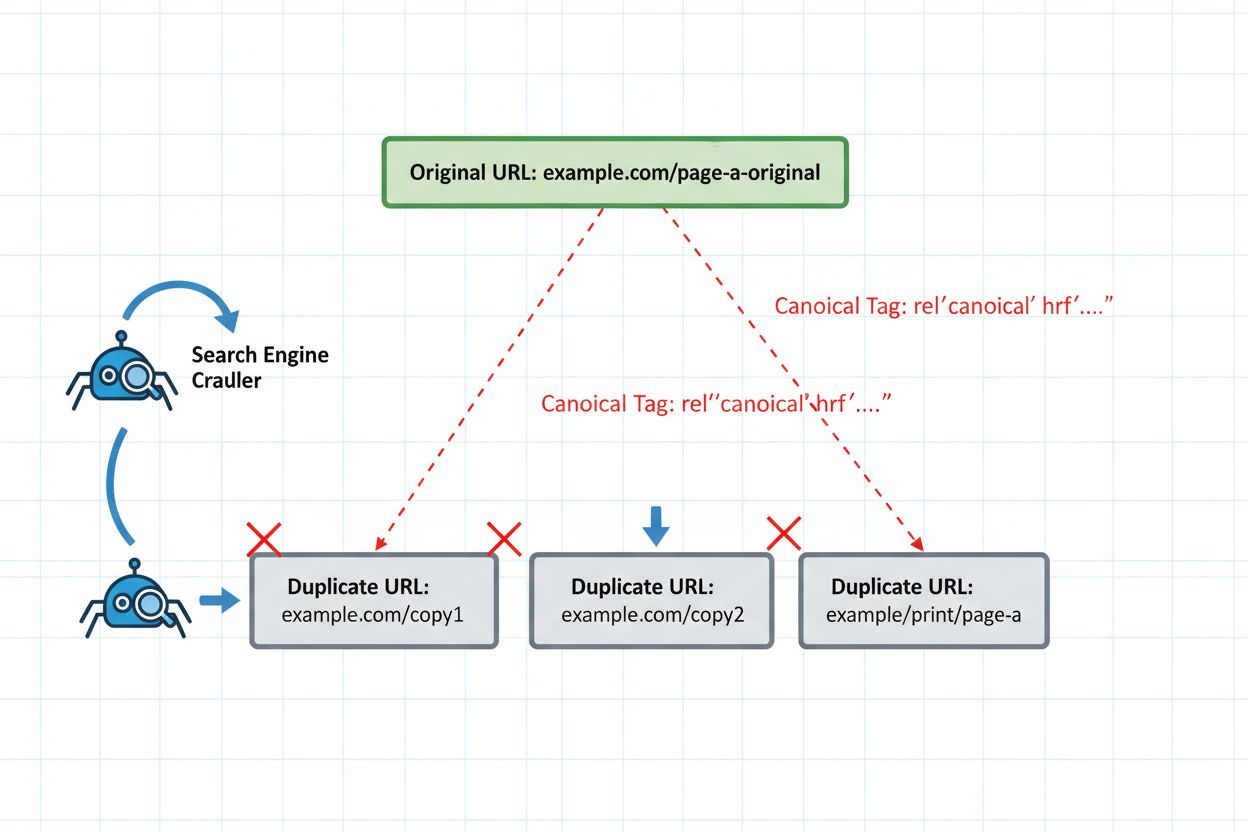
Implementar salvaguardas técnicas adequadas é inegociável para uma republicação segura. A tag canônica continua sendo sua principal defesa, informando explicitamente aos sistemas de IA qual versão deve representar seu cluster de conteúdo. Coloque a tag canônica na seção <head> de cada versão republicada, apontando para sua versão autoritativa preferida. Para conteúdo sindicado, isso normalmente significa apontar para seu domínio original.
<!-- Na versão sindica (medium.com/sua-publicacao/artigo) -->
<link rel="canonical" href="https://yoursite.com/blog/artigo" />
Para conteúdos que nunca devem competir com outras versões, implemente noindex nas versões secundárias. Isso as remove completamente do índice da IA, garantindo que elas não possam ser selecionadas como páginas representativas. Use essa abordagem para páginas internas duplicadas, versões de teste ou conteúdo sindicado onde você deseja visibilidade zero na busca por IA.
<!-- Na versão secundária que não deve ser indexada -->
<meta name="robots" content="noindex, follow" />
Redirecionamentos 301 fornecem o sinal mais forte para consolidação de autoridade, mas use-os apenas quando a versão secundária nunca será atualizada de forma independente. Redirecionamentos informam aos sistemas de IA que a URL antiga foi movida permanentemente, consolidando todos os sinais no novo local. Porém, se você precisa que ambas as versões permaneçam ativas (como na sindicação), redirecionamentos criam problemas pois quebram a estrutura de URLs da plataforma de sindicação.
# Em .htaccess ou configuração do servidor
Redirect 301 /artigo-antigo https://yoursite.com/novo-artigo
Para sistemas de gerenciamento de conteúdo, implemente rel=“canonical” de forma dinâmica para lidar com paginação, variações de parâmetros e URLs baseadas em sessão que criam duplicatas não intencionais. Muitos CMS geram múltiplas URLs para o mesmo conteúdo via diferentes caminhos de navegação—as tags canônicas consolidam isso automaticamente.
O IndexNow acelera a descoberta de sinais canônicos e a consolidação de duplicatas, reduzindo o que normalmente levaria semanas para dias. Ao implementar tags canônicas em conteúdo republicado, o IndexNow notifica imediatamente os sistemas de busca de que essas URLs devem ser agrupadas. Em vez de esperar os rastreadores descobrirem a relação canônica por meio de padrões normais de rastreamento, o IndexNow envia essa informação diretamente para o índice da Microsoft e outros sistemas de busca participantes. Isso é especialmente valioso quando você está corrigindo republicações antigas—você pode implementar tags canônicas e usar o IndexNow para sinalizar a mudança imediatamente, sem esperar os rastreadores revisitarem as páginas. Para editores que gerenciam conteúdo em várias plataformas, o IndexNow torna-se uma ferramenta fundamental para manter o controle sobre qual versão representa seu cluster de conteúdo. A integração via API permite o envio em massa de URLs, tornando prático o gerenciamento de centenas ou milhares de páginas republicadas.
POST https://api.indexnow.org/indexnow
{
"host": "yoursite.com",
"key": "your-api-key",
"keyLocation": "https://yoursite.com/indexnow-key.txt",
"urlList": [
"https://yoursite.com/blog/artigo-1",
"https://yoursite.com/blog/artigo-2"
]
}
Rastrear qual versão do seu conteúdo republicado é selecionada por sistemas de IA exige monitoramento além da análise tradicional. Configure o rastreamento para identificar quando sistemas de IA citam ou referenciam seu conteúdo, observando qual URL aparece nos resultados de busca por IA. Ferramentas como Semrush, Ahrefs e Moz estão começando a adicionar métricas de visibilidade na busca por IA, embora ainda estejam menos maduras que o rastreamento tradicional. Implemente parâmetros UTM em versões sindicadas para rastrear a atribuição de tráfego, mas reconheça que sistemas de IA podem não repassar esses parâmetros, dificultando a atribuição direta. Monitore seu Search Console (ou ferramentas equivalentes de outros sistemas de busca) para padrões de rastreamento—se versões secundárias estiverem sendo rastreadas mais frequentemente que sua versão canônica, isso indica que o sistema de IA pode ter selecionado a página representativa errada. Configure alertas para menções ao seu conteúdo nas plataformas de sindicação e cruze esses dados com sua visibilidade na busca por IA para identificar desalinhamentos entre onde seu conteúdo aparece e de onde os sistemas de IA estão selecionando.
Implemente este checklist antes de republicar qualquer conteúdo para garantir o controle sobre a visibilidade na IA:
Antes de republicar, identifique sua versão canônica—a URL que você deseja representar esse conteúdo nos resultados de busca por IA. Geralmente, deve ser seu domínio próprio, não uma plataforma de sindicação. Implemente tags canônicas em toda versão republicada apontando para sua URL canônica, mesmo que esteja republicando em propriedades próprias (diferentes domínios, subdomínios ou variações de parâmetros). Use o IndexNow para notificar imediatamente os sistemas de busca sobre a relação canônica, ao invés de esperar pela descoberta via rastreamento. Evite republicar em plataformas de alta autoridade sem suporte canônico—algumas plataformas removem tags canônicas ou não as permitem, tornando-as inadequadas para republicação sem aceitar perda de visibilidade. Monitore as primeiras 48 horas após a republicação para verificar se os sistemas de IA estão selecionando sua versão canônica desejada, não uma alternativa. Atualize todas as versões simultaneamente quando fizer alterações no conteúdo—se você atualizar apenas a versão canônica, o algoritmo de agrupamento pode não reconhecer a atualização em todas as versões, potencialmente levando o sistema de IA a selecionar uma versão desatualizada. Estabeleça um cronograma de republicação que evite que o conteúdo fique obsoleto em plataformas secundárias; conteúdo sindicado desatualizado aumenta o risco de sistemas de IA selecionarem-no como versão representativa caso sua versão canônica não tenha sido atualizada recentemente.
Tags canônicas não evitam penalidades porque conteúdo duplicado não gera penalidades em primeiro lugar. Entretanto, tags canônicas são essenciais para buscas por IA, pois indicam aos sistemas de IA qual versão deve representar seu cluster de conteúdo. Sem tags canônicas, sistemas de IA podem escolher uma versão não intencional como fonte autoritativa, reduzindo sua visibilidade.
Monitore quais URLs aparecem nos resultados de busca por IA e citações do seu conteúdo. Ferramentas como Semrush e Ahrefs estão adicionando métricas de visibilidade em busca por IA. Verifique seu Search Console para padrões de rastreamento—se versões secundárias forem rastreadas mais frequentemente que sua versão canônica, o sistema de IA pode ter selecionado a página errada.
Tecnicamente sim, mas não é recomendado. Sem tags canônicas, sistemas de IA agruparão seu conteúdo e selecionarão uma versão como representativa—mas você não controlará qual será. A plataforma de sindicação pode ter maior autoridade, fazendo com que a IA escolha essa versão em vez do seu domínio original.
Republicação geralmente refere-se à distribuição do seu conteúdo em múltiplos canais sob seu controle ou de parceiros. Sindicação de conteúdo é uma forma específica de republicação onde plataformas terceiras republicam seu conteúdo com sua permissão. Ambas criam problemas de conteúdo duplicado se não forem devidamente gerenciadas com tags canônicas.
Tags canônicas geralmente são reconhecidas em 24-48 horas se você usar IndexNow para notificar imediatamente os sistemas de busca. Sem o IndexNow, pode levar semanas para os rastreadores descobrirem a relação canônica. Por isso o IndexNow é fundamental para gerenciar conteúdo republicado—ele acelera o processo significativamente.
Use redirecionamentos 301 apenas quando quiser consolidar URLs permanentemente e a versão secundária nunca será atualizada de forma independente. Use tags canônicas quando ambas versões precisarem permanecer ativas (como na sindicação). Redirecionamentos são sinais mais fortes, mas quebram a funcionalidade da URL secundária.
Sim, se não for corretamente gerenciado. Republicar sem tags canônicas dilui seus sinais de autoridade entre múltiplas URLs. Sistemas de IA podem selecionar a versão sindicada em vez da original, reduzindo a visibilidade em seu próprio domínio. Uma implementação canônica adequada previne isso.
Implemente tags canônicas em cada versão republicada apontando para seu domínio original. Use IndexNow para notificar imediatamente os sistemas de busca sobre a relação canônica. Evite republicar em plataformas que não suportam tags canônicas. Monitore qual versão os sistemas de IA selecionam nas primeiras 48 horas e ajuste se necessário.
Acompanhe como sistemas de IA citam e referenciam seu conteúdo republicado em todas as plataformas. Obtenha insights em tempo real sobre qual versão a IA seleciona como sua fonte autoritativa.
Aprenda como URLs canônicos previnem problemas de conteúdo duplicado em sistemas de busca por IA. Descubra as melhores práticas para implementar canônicos, melh...

Discussão da comunidade sobre como sistemas de IA lidam com conteúdo duplicado de forma diferente dos motores de busca tradicionais. Profissionais de SEO compar...
Saiba como gerenciar e prevenir conteúdo duplicado ao utilizar ferramentas de IA. Descubra tags canônicas, redirecionamentos, ferramentas de detecção e as melho...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.