
GPTBot
Saiba o que é o GPTBot, como ele funciona e se você deve bloqueá-lo do seu site. Entenda o impacto no SEO, carga do servidor e visibilidade da marca nos resulta...
12 min de leitura

O web crawler da Amazon usado para melhorar produtos e serviços, incluindo Alexa, o assistente de compras Rufus e os recursos de busca com inteligência artificial da Amazon. Ele respeita o Protocolo de Exclusão de Robôs e pode ser controlado por diretrizes no robots.txt. Pode ser usado para treinamento de modelos de IA.
O web crawler da Amazon usado para melhorar produtos e serviços, incluindo Alexa, o assistente de compras Rufus e os recursos de busca com inteligência artificial da Amazon. Ele respeita o Protocolo de Exclusão de Robôs e pode ser controlado por diretrizes no robots.txt. Pode ser usado para treinamento de modelos de IA.
O Amazonbot é o web crawler oficial da Amazon, projetado para aprimorar os produtos e serviços da empresa por meio da coleta e análise de conteúdo da web. Esse sofisticado crawler alimenta recursos essenciais da Amazon, incluindo o assistente de voz Alexa, o assistente de compras com IA Rufus e as experiências de busca baseadas em inteligência artificial da Amazon. O Amazonbot opera utilizando o user agent Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36, que o identifica para os servidores web. Os dados coletados pelo Amazonbot podem ser usados para treinar modelos de inteligência artificial da Amazon, tornando-o um componente crucial da infraestrutura de IA da empresa e da estratégia de desenvolvimento de produtos.
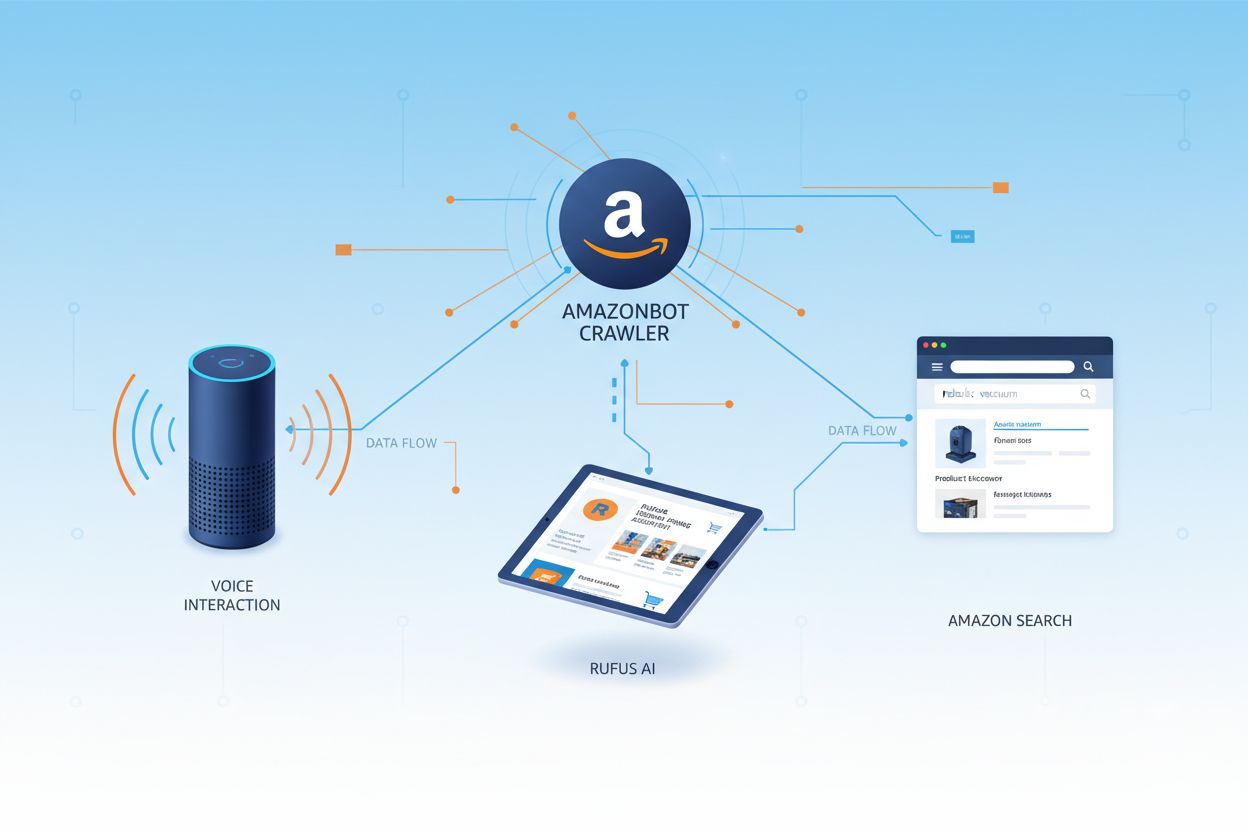
A Amazon opera três crawlers distintos, cada um atendendo a propósitos específicos em seu ecossistema. Amazonbot é o principal rastreador utilizado para melhoria geral de produtos e serviços, podendo ser utilizado para treinamento de modelos de IA. Amzn-SearchBot é projetado especificamente para melhorar experiências de busca em produtos da Amazon como Alexa e Rufus, mas, importante dizer, NÃO faz crawling de conteúdo para treinamento de modelos de IA generativos. Amzn-User dá suporte a ações iniciadas pelo usuário, como busca de informações ao vivo quando clientes fazem perguntas para a Alexa que exigem dados atualizados, e também não faz crawling para treinamento de IA. Todos os três crawlers respeitam o Protocolo de Exclusão de Robôs e seguem as diretrizes do robots.txt, permitindo que os proprietários de sites controlem seu acesso. A Amazon publica os endereços IP de cada crawler em seu portal para desenvolvedores, possibilitando que os administradores dos sites verifiquem o tráfego legítimo. Além disso, todos os crawlers da Amazon respeitam diretrizes de link rel=nofollow e meta tags de robots no nível da página, incluindo noarchive (impedindo uso para treinamento de IA), noindex (impedindo indexação) e none (impedindo ambos).
| Nome do Crawler | Finalidade Principal | Treinamento de IA | User Agent | Principais Usos |
|---|---|---|---|---|
| Amazonbot | Melhoria geral de produtos/serviços | Sim | Amazonbot/0.1 | Aprimoramento geral dos serviços da Amazon, IA training |
| Amzn-SearchBot | Melhoria de experiência de busca | Não | Amzn-SearchBot/0.1 | Indexação para Alexa e assistente Rufus |
| Amzn-User | Busca de dados ao vivo pelo usuário | Não | Amzn-User/0.1 | Consultas em tempo real na Alexa |
A Amazon respeita o Protocolo de Exclusão de Robôs (RFC 9309), padrão da indústria, o que significa que os proprietários de sites podem controlar o acesso do Amazonbot por meio do arquivo robots.txt. A Amazon busca arquivos robots.txt no nível do host, na raiz do seu domínio (exemplo: example.com/robots.txt) e utilizará uma cópia em cache dos últimos 30 dias caso o arquivo não possa ser obtido. Mudanças no seu arquivo robots.txt normalmente levam cerca de 24 horas para serem refletidas nos sistemas da Amazon. O protocolo suporta as diretivas padrão user-agent e allow/disallow, permitindo controle granular sobre quais crawlers podem acessar diretórios ou arquivos específicos. Porém, é importante observar que os crawlers da Amazon NÃO suportam a diretiva crawl-delay, então esse parâmetro será ignorado se incluído no robots.txt.
Veja um exemplo de como controlar o acesso do Amazonbot:
# Bloquear o Amazonbot de rastrear todo o seu site
User-agent: Amazonbot
Disallow: /
# Permitir o Amzn-SearchBot para visibilidade em buscas
User-agent: Amzn-SearchBot
Allow: /
# Bloquear um diretório específico para o Amazonbot
User-agent: Amazonbot
Disallow: /private/
# Permitir todos os outros crawlers
User-agent: *
Disallow: /admin/
Proprietários de sites preocupados com o tráfego de bots devem verificar se os crawlers que se identificam como Amazonbot são realmente legítimos. A Amazon fornece um processo de verificação usando consultas DNS para confirmar o tráfego autêntico do Amazonbot. Para verificar a legitimidade de um crawler, localize o endereço IP no seu log de servidor e faça uma consulta reversa de DNS nesse IP usando o comando host. O domínio retornado deve ser um subdomínio de crawl.amazonbot.amazon. Em seguida, faça uma consulta direta de DNS no domínio retornado para garantir que ele resolve para o IP original. Esse processo bidirecional ajuda a evitar ataques de spoofing, já que agentes maliciosos podem configurar registros reversos de DNS para se passar pelo Amazonbot. A Amazon publica os endereços IP verificados de todos os seus crawlers em developer.amazon.com/amazonbot/ip-addresses/, fornecendo uma referência adicional para verificação.
Exemplo do processo de verificação:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
Se você tiver dúvidas sobre o Amazonbot ou precisar reportar alguma atividade suspeita, entre em contato diretamente com a Amazon pelo e-mail amazonbot@amazon.com e inclua os domínios relevantes na mensagem.
Existe uma distinção crítica entre os crawlers da Amazon em relação ao treinamento de IA. O Amazonbot pode ser utilizado para treinar modelos de inteligência artificial da Amazon, o que é relevante para criadores de conteúdo preocupados com o uso do seu material em treinamentos de IA. Já Amzn-SearchBot e Amzn-User explicitamente NÃO fazem crawling de conteúdo para treinamento de modelos de IA generativos, focando apenas em aprimorar experiências de busca e dar suporte a consultas de usuários. Se você quer evitar que seu conteúdo seja usado para treinamento de IA, utilize a meta tag robots noarchive no cabeçalho HTML da sua página, instruindo o Amazonbot a não usar a página para treinamento de modelos. Essa distinção é importante para editores, criadores e administradores de sites que desejam manter controle sobre como seu conteúdo é utilizado no pipeline de IA, mas ainda assim permitir sua exibição nos resultados de busca da Amazon e recomendações do Rufus.
O Rufus é o avançado assistente de compras com IA da Amazon, que utiliza crawling da web e tecnologia de inteligência artificial para oferecer recomendações personalizadas de compras e assistência aos clientes. Enquanto o Amazonbot contribui para a infraestrutura geral de IA da Amazon, o Rufus utiliza especificamente o Amzn-SearchBot para indexar informações de produtos e conteúdo da web relevante para consultas de compras. O Rufus é construído sobre o Amazon Bedrock e utiliza modelos de linguagem avançados, incluindo o Claude Sonnet da Anthropic e o Amazon Nova, combinados com um modelo próprio treinado sobre o vasto catálogo de produtos da Amazon, avaliações de clientes, perguntas e respostas da comunidade e informações da web. O assistente de compras ajuda clientes a pesquisar produtos, comparar opções, acompanhar preços, encontrar ofertas e até comprar automaticamente itens quando atingem preços-alvo. Desde seu lançamento, o Rufus se tornou extremamente popular, com mais de 250 milhões de clientes utilizando-o, crescimento de usuários ativos mensais de 149% e aumento de 210% nas interações ano a ano. Clientes que usam o Rufus durante as compras têm mais de 60% de chance de concluir uma compra na mesma sessão, demonstrando o impacto significativo da assistência de compras com IA no comportamento do consumidor.
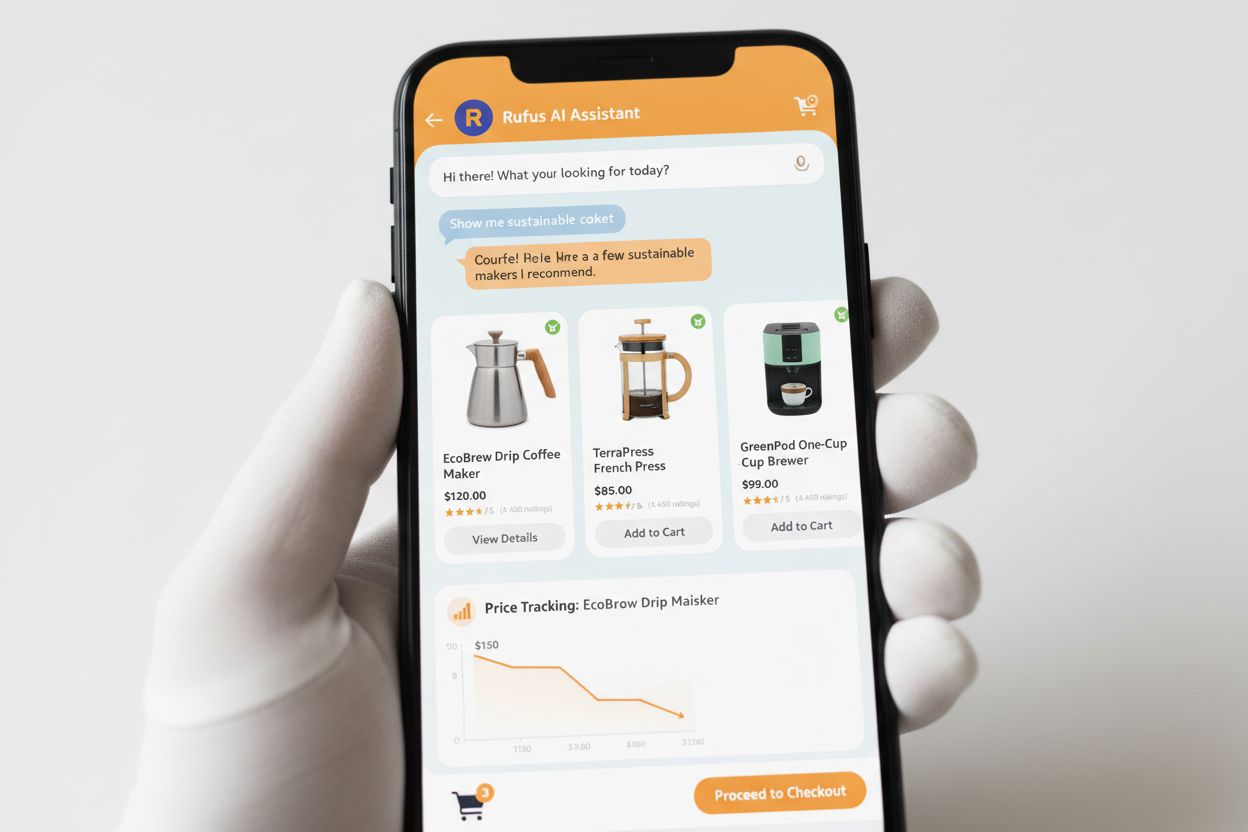
Os proprietários de sites devem adotar uma abordagem estratégica para gerenciar os crawlers da Amazon conforme seus objetivos de negócio e políticas de conteúdo:
noarchive ou bloqueie totalmente via robots.txtamazonbot@amazon.com com as informações do seu domínio para orientações personalizadas, caso tenha dúvidas específicas sobre a interação dos crawlers da Amazon com seu siteO Amazonbot é o rastreador geral da Amazon usado para melhorar produtos e serviços, podendo ser utilizado para treinamento de modelos de IA. O Amzn-SearchBot é projetado especificamente para experiências de busca na Alexa e no Rufus, e explicitamente NÃO faz crawling para treinamento de IA. Se você deseja evitar o uso para treinamento de IA, bloqueie o Amazonbot, mas permita o Amzn-SearchBot para visibilidade em buscas.
Adicione as seguintes linhas ao seu arquivo robots.txt na raiz do seu domínio: User-agent: Amazonbot seguido por Disallow: /. Isso impedirá que o Amazonbot rastreie todo o seu site. Você também pode usar Disallow: /caminho-especifico/ para bloquear apenas determinados diretórios.
Sim, o Amazonbot pode ser utilizado para treinar modelos de inteligência artificial da Amazon. Se você quiser evitar isso, use a meta tag robots no cabeçalho HTML da sua página, instruindo o Amazonbot a não usar a página para treinamento de modelos.
Realize uma pesquisa reversa de DNS no endereço IP do rastreador e verifique se o domínio é um subdomínio de crawl.amazonbot.amazon. Em seguida, faça uma pesquisa direta de DNS para confirmar que o domínio resolve para o IP original. Você também pode consultar os endereços IP publicados pela Amazon em developer.amazon.com/amazonbot/ip-addresses/.
Use a sintaxe padrão do robots.txt: User-agent: Amazonbot para direcionar o crawler, seguido por Disallow: / para bloquear todo o acesso ou Disallow: /caminho/ para bloquear diretórios específicos. Você também pode usar Allow: / para permitir explicitamente o acesso.
Normalmente a Amazon reflete as alterações no robots.txt em aproximadamente 24 horas. A Amazon busca regularmente seu arquivo robots.txt e mantém uma cópia em cache por até 30 dias, portanto as mudanças podem levar um dia inteiro para se propagarem em seus sistemas.
Sim, absolutamente. Você pode criar regras separadas para cada crawler no seu arquivo robots.txt. Por exemplo, permita o Amzn-SearchBot com User-agent: Amzn-SearchBot e Allow: /, enquanto bloqueia o Amazonbot com User-agent: Amazonbot e Disallow: /.
Entre em contato diretamente com a Amazon pelo e-mail amazonbot@amazon.com. Sempre inclua o nome do seu domínio e quaisquer detalhes relevantes sobre sua dúvida na mensagem. A equipe de suporte da Amazon pode fornecer orientações personalizadas para o seu caso específico.
Acompanhe menções à sua marca em sistemas de IA como Alexa, Rufus e Google AI Overviews com o AmICited – a principal plataforma de monitoramento de respostas de IA.
Saiba o que é o GPTBot, como ele funciona e se você deve bloqueá-lo do seu site. Entenda o impacto no SEO, carga do servidor e visibilidade da marca nos resulta...
Saiba o que é Amazon SEO, como funciona o algoritmo A9 e estratégias comprovadas para otimizar as listagens de produtos visando melhores posições e aumento de v...

Guia completo sobre o rastreador PerplexityBot - entenda como ele funciona, gerencie o acesso, monitore citações e otimize para a visibilidade na Perplexity AI....
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.