
Crawl Budget
Crawl budget é o número de páginas que os mecanismos de busca rastreiam em seu site dentro de um período. Saiba como otimizar o crawl budget para melhor indexaç...
14 min de leitura

Técnicas para garantir que crawlers de IA acessem e indexem eficientemente o conteúdo mais importante de um site dentro de seus limites de rastreamento. A otimização do crawl budget gerencia o equilíbrio entre a capacidade de rastreamento (recursos do servidor) e a demanda de rastreamento (requisições dos bots) para maximizar a visibilidade em respostas geradas por IA enquanto controla custos operacionais e carga do servidor.
Técnicas para garantir que crawlers de IA acessem e indexem eficientemente o conteúdo mais importante de um site dentro de seus limites de rastreamento. A otimização do crawl budget gerencia o equilíbrio entre a capacidade de rastreamento (recursos do servidor) e a demanda de rastreamento (requisições dos bots) para maximizar a visibilidade em respostas geradas por IA enquanto controla custos operacionais e carga do servidor.
Crawl budget refere-se à quantidade de recursos—medidos em requisições e banda—que mecanismos de busca e bots de IA alocam para rastrear seu site. Tradicionalmente, esse conceito aplicava-se principalmente ao comportamento de rastreamento do Google, mas o surgimento de bots movidos por IA transformou fundamentalmente a forma como as organizações devem pensar sobre o gerenciamento do crawl budget. A equação do crawl budget consiste em duas variáveis críticas: capacidade de rastreamento (o número máximo de páginas que um bot pode rastrear) e demanda de rastreamento (o número real de páginas que o bot deseja rastrear). Na era da IA, essa dinâmica tornou-se exponencialmente mais complexa, já que bots como o GPTBot (OpenAI), Perplexity Bot e ClaudeBot (Anthropic) agora competem pelos recursos do servidor junto com rastreadores tradicionais dos mecanismos de busca. Esses bots de IA operam com prioridades e padrões diferentes do Googlebot, frequentemente consumindo muito mais banda ao perseguir objetivos de indexação distintos, tornando a otimização do crawl budget não mais opcional, mas essencial para manter o desempenho do site e controlar custos operacionais.
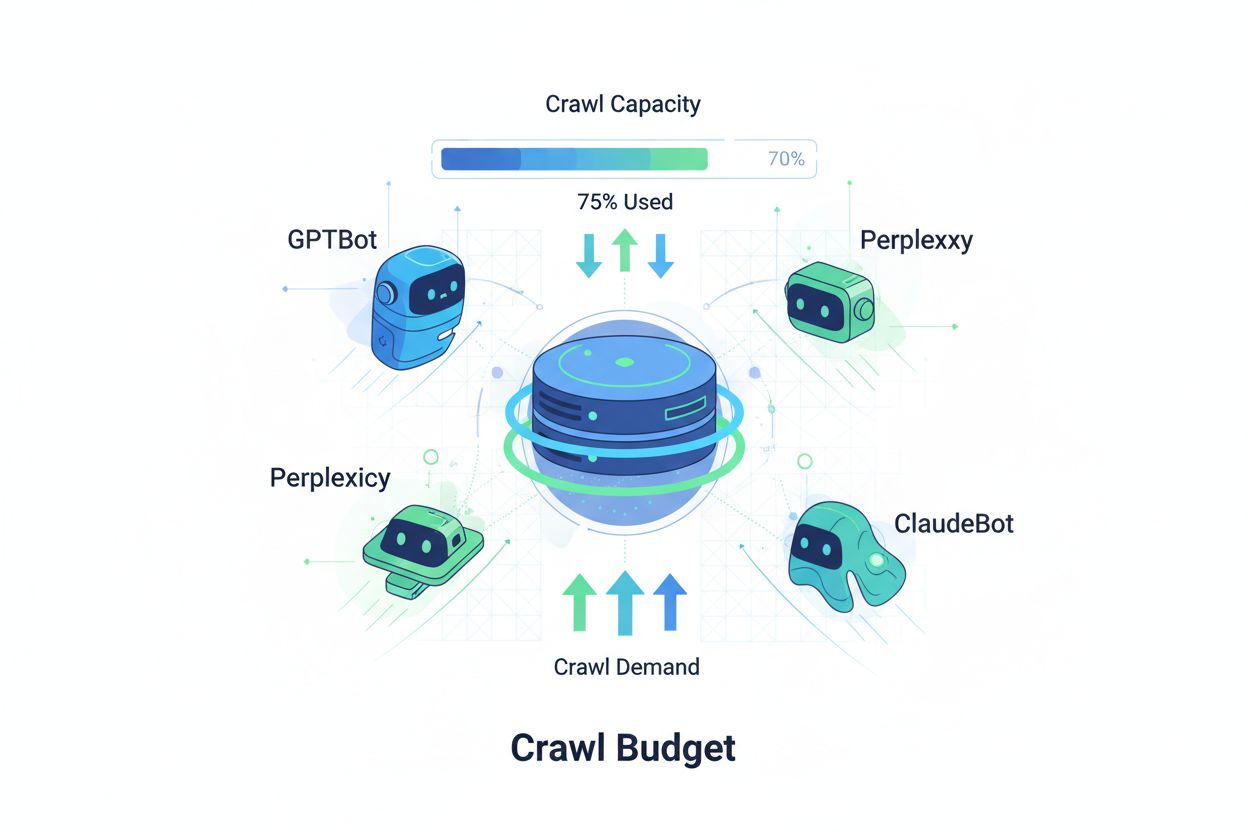
Crawlers de IA diferem fundamentalmente dos bots tradicionais dos mecanismos de busca em seus padrões de rastreamento, frequência e consumo de recursos. Enquanto o Googlebot respeita limites de crawl budget e implementa mecanismos de controle sofisticados, bots de IA geralmente apresentam comportamentos de rastreamento mais agressivos, às vezes requisitando o mesmo conteúdo várias vezes e demonstrando menos respeito aos sinais de carga do servidor. Pesquisas indicam que o GPTBot da OpenAI pode consumir de 12 a 15 vezes mais banda do que o crawler do Google em determinados sites, especialmente aqueles com grandes bibliotecas de conteúdo ou páginas frequentemente atualizadas. Essa abordagem agressiva decorre das necessidades de treinamento de IA—esses bots precisam ingerir continuamente conteúdo fresco para melhorar o desempenho do modelo, criando uma filosofia de rastreamento fundamentalmente diferente de mecanismos de busca focados em indexação para recuperação. O impacto no servidor é substancial: organizações relatam aumentos significativos nos custos de banda, utilização de CPU e carga do servidor atribuíveis diretamente ao tráfego de bots de IA. Além disso, o efeito cumulativo de múltiplos bots de IA rastreando simultaneamente pode degradar a experiência do usuário, tornar o carregamento das páginas mais lento e aumentar as despesas com hospedagem, tornando a distinção entre crawlers tradicionais e de IA uma consideração crítica de negócios e não apenas uma curiosidade técnica.
| Característica | Crawlers Tradicionais (Googlebot) | Crawlers de IA (GPTBot, ClaudeBot) |
|---|---|---|
| Frequência de Rastreamento | Adaptativa, respeita crawl budget | Agressiva, contínua |
| Consumo de Banda | Moderado, otimizado | Alto, intensivo em recursos |
| Respeito ao Robots.txt | Conformidade rigorosa | Conformidade variável |
| Comportamento de Cache | Cache sofisticado | Requisições frequentes repetidas |
| Identificação User-Agent | Clara, consistente | Às vezes ofuscada |
| Objetivo de Negócio | Indexação de busca | Treinamento de modelos/aquisição de dados |
| Impacto de Custo | Mínimo | Significativo (12-15x maior) |
Entender o crawl budget exige dominar seus dois componentes fundamentais: capacidade de rastreamento e demanda de rastreamento. Capacidade de rastreamento representa o número máximo de URLs que seu servidor pode suportar sendo rastreados em determinado período, determinado por vários fatores interconectados. Essa capacidade é influenciada por:
Demanda de rastreamento, por sua vez, representa quantas páginas os bots realmente querem rastrear, impulsionada por características do conteúdo e prioridades dos bots. Fatores que afetam a demanda de rastreamento incluem:
O desafio da otimização surge quando a demanda de rastreamento excede a capacidade de rastreamento—os bots precisam escolher quais páginas rastrear, podendo deixar de fora atualizações importantes. Por outro lado, quando a capacidade excede em muito a demanda, você desperdiça recursos do servidor. O objetivo é alcançar a eficiência de rastreamento: maximizar o rastreamento de páginas importantes enquanto minimiza rastreamentos desperdiçados em conteúdo de baixo valor. Esse equilíbrio torna-se cada vez mais complexo na era da IA, onde múltiplos tipos de bots com prioridades diferentes competem pelos mesmos recursos do servidor, exigindo estratégias sofisticadas para alocar o crawl budget de forma eficaz entre todos os interessados.
A medição do desempenho do crawl budget começa pelo Google Search Console, que fornece estatísticas de rastreamento na seção “Configurações”, mostrando requisições diárias de rastreamento, bytes baixados e tempos de resposta. Para calcular sua taxa de eficiência de rastreamento, divida o número de rastreamentos bem-sucedidos (respostas HTTP 200) pelo total de requisições de rastreamento; sites saudáveis costumam alcançar 85-95% de eficiência. Uma fórmula básica é: (Rastreamentos Bem-Sucedidos ÷ Total de Requisições de Rastreamento) × 100 = Eficiência de Rastreamento %. Além dos dados do Google, o monitoramento prático exige:
Para monitoramento específico de crawlers de IA, ferramentas como o AmICited.com oferecem rastreamento especializado das atividades do GPTBot, ClaudeBot e Perplexity Bot, trazendo insights sobre quais páginas esses bots priorizam e com que frequência retornam. Além disso, a implementação de alertas personalizados para picos incomuns de rastreamento—especialmente vindos de bots de IA—permite resposta rápida ao consumo inesperado de recursos. A métrica principal a ser acompanhada é o custo de rastreamento por página: dividir o total de recursos do servidor consumidos pelos rastreamentos pelo número de páginas únicas rastreadas revela se você está usando seu crawl budget eficientemente ou desperdiçando recursos em páginas de baixo valor.
Otimizar o crawl budget para bots de IA requer uma abordagem em múltiplas camadas, combinando implementação técnica com decisões estratégicas. As principais táticas de otimização incluem:
A decisão estratégica sobre qual tática adotar depende do seu modelo de negócios e estratégia de conteúdo. Sites de e-commerce podem bloquear crawlers de IA em páginas de produtos para evitar que concorrentes usem os dados para treinamento, enquanto editoras de conteúdo podem permitir o rastreamento visando ganhar visibilidade em respostas geradas por IA. Para sites que enfrentam real sobrecarga de servidor devido ao tráfego de bots de IA, implementar bloqueio específico por user-agent no robots.txt é a solução mais direta: User-agent: GPTBot seguido de Disallow: / impede que o crawler da OpenAI acesse seu site por completo. No entanto, essa abordagem sacrifica a visibilidade potencial em respostas do ChatGPT e outros aplicativos de IA. Uma estratégia mais refinada envolve o bloqueio seletivo: permitir que crawlers de IA acessem o conteúdo público enquanto bloqueia áreas sensíveis, arquivos ou conteúdo duplicado que desperdiça crawl budget sem agregar valor para o bot ou para seus usuários.
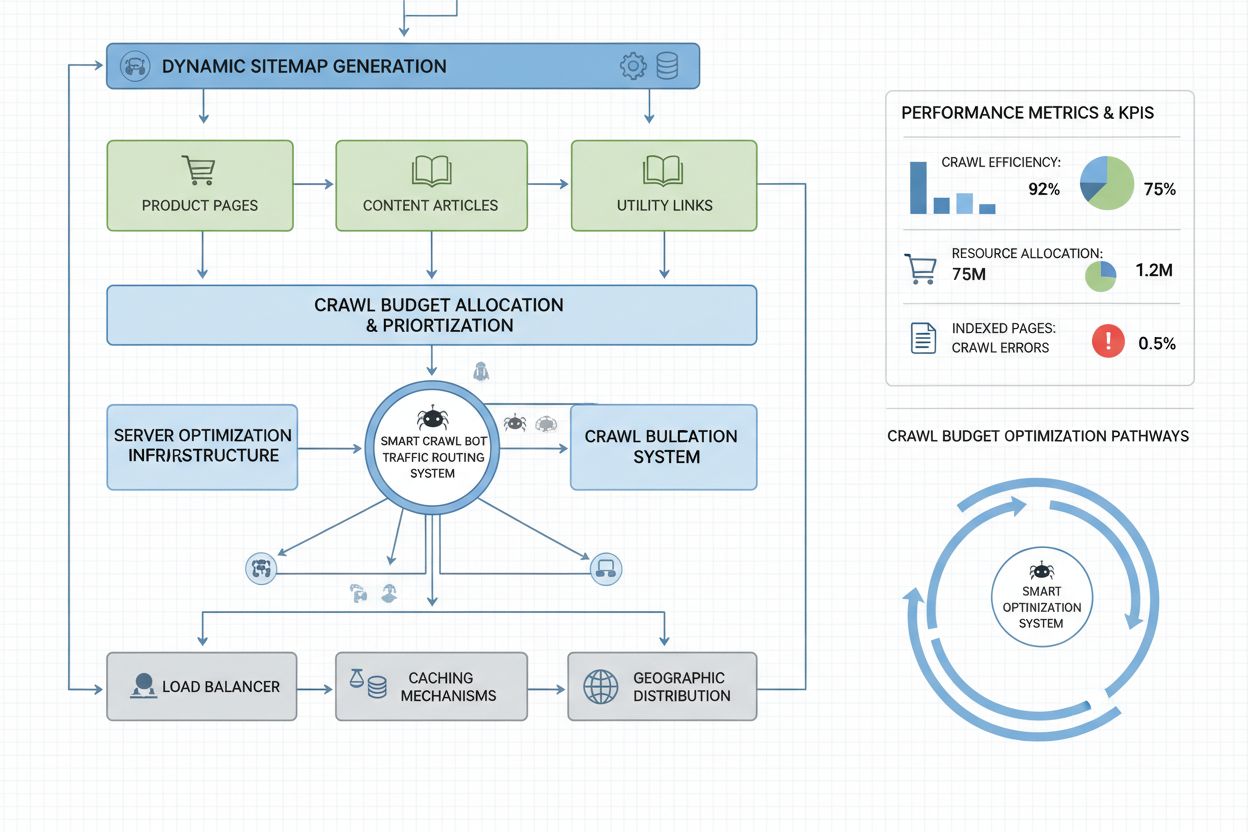
Sites em escala empresarial com milhões de páginas precisam de estratégias sofisticadas de otimização de crawl budget além das configurações básicas do robots.txt. Sitemaps dinâmicos representam um avanço crítico, onde os sitemaps são gerados em tempo real com base em atualização de conteúdo, pontuação de importância e histórico de rastreamento. Em vez de sitemaps XML estáticos listando todas as páginas, sitemaps dinâmicos priorizam páginas recentemente atualizadas, de alto tráfego e com potencial de conversão, garantindo que os bots foquem o crawl budget no conteúdo que realmente importa. Segmentação de URLs divide o site em zonas lógicas de rastreamento, cada uma com estratégias de otimização próprias—seções de notícias podem usar atualizações agressivas de sitemap para garantir que o conteúdo diário seja rastreado imediatamente, enquanto conteúdo perene utiliza atualizações menos frequentes.
Otimização do lado do servidor inclui a implementação de estratégias de cache conscientes do rastreamento, que servem respostas em cache para bots enquanto entregam conteúdo fresco para usuários, reduzindo a carga do servidor de requisições repetidas dos bots. Redes de entrega de conteúdo (CDNs) com roteamento específico para bots podem isolar o tráfego de bots do tráfego de usuários, evitando que crawlers consumam banda necessária aos visitantes reais. Limitação de taxa por user-agent permite que servidores desacelerem requisições de bots de IA mantendo velocidade normal para o Googlebot e visitantes humanos. Para operações realmente grandes, o gerenciamento distribuído do crawl budget em múltiplas regiões de servidor garante ausência de pontos únicos de falha e permite balanceamento geográfico da carga de bots. Previsão de rastreamento baseada em machine learning analisa padrões históricos para prever quais páginas os bots solicitarão a seguir, permitindo otimização proativa do desempenho e cache dessas páginas. Essas estratégias de nível empresarial transformam o crawl budget de uma restrição em um recurso gerenciado, permitindo que grandes organizações sirvam bilhões de páginas mantendo desempenho ideal tanto para bots quanto para usuários humanos.
A decisão de bloquear ou permitir crawlers de IA representa uma escolha estratégica fundamental de negócios, com implicações significativas para visibilidade, posicionamento competitivo e custos operacionais. Permitir crawlers de IA traz benefícios substanciais: seu conteúdo se torna elegível para inclusão em respostas geradas por IA, potencialmente gerando tráfego do ChatGPT, Claude, Perplexity e outros aplicativos de IA; sua marca ganha visibilidade em um novo canal de distribuição; e você se beneficia dos sinais de SEO provenientes de citações por sistemas de IA. Entretanto, esses benefícios vêm com custos: aumento da carga do servidor e consumo de banda, potencial treinamento de modelos concorrentes usando seu conteúdo proprietário e perda de controle sobre como suas informações são apresentadas e atribuídas em respostas de IA.
Bloquear crawlers de IA elimina esses custos, mas sacrifica os benefícios de visibilidade e pode ceder espaço no mercado para concorrentes que permitem o rastreamento. A estratégia ideal depende do seu modelo de negócios: editoras de conteúdo e organizações de notícias frequentemente se beneficiam ao permitir o rastreamento para ganhar distribuição via resumos de IA; empresas SaaS e sites de e-commerce podem bloquear crawlers para evitar que concorrentes treinem modelos com informações de produtos; instituições educacionais e organizações de pesquisa costumam permitir rastreamento para maximizar a disseminação do conhecimento. Uma abordagem híbrida oferece um caminho intermediário: permitir rastreamento do conteúdo público e bloquear acesso a áreas sensíveis, conteúdo gerado por usuários ou informações proprietárias. Essa estratégia maximiza os benefícios de visibilidade, protegendo ativos valiosos. Além disso, o monitoramento via AmICited.com e ferramentas semelhantes revela se seu conteúdo está realmente sendo citado por sistemas de IA—se seu site não aparece em respostas de IA mesmo permitindo rastreamento, bloquear torna-se uma opção mais atraente, já que você arca com o custo do rastreamento sem receber os benefícios de visibilidade.
O gerenciamento eficaz do crawl budget exige ferramentas especializadas que forneçam visibilidade sobre o comportamento dos bots e permitam decisões de otimização baseadas em dados. Conductor e Sitebulb oferecem análise de rastreamento de nível empresarial, simulando como mecanismos de busca rastreiam seu site e identificando ineficiências, rastreamentos desperdiçados em páginas de erro e oportunidades para melhorar a alocação do crawl budget. Cloudflare oferece gerenciamento de bots no nível de rede, permitindo controle granular sobre quais bots podem acessar seu site e aplicando limitação de taxa específica para crawlers de IA. Para monitoramento específico de crawlers de IA, o AmICited.com se destaca como a solução mais abrangente, rastreando GPTBot, ClaudeBot, Perplexity Bot e outros crawlers de IA com análises detalhadas mostrando quais páginas esses bots acessam, com que frequência retornam e se seu conteúdo aparece em respostas geradas por IA.
Análise de logs do servidor continua fundamental para otimização do crawl budget—ferramentas como Splunk, Datadog ou ELK Stack open-source permitem analisar logs de acesso brutos e segmentar tráfego por user-agent, identificando quais bots consomem mais recursos e quais páginas atraem mais rastreamento. Dashboards personalizados que acompanham tendências de rastreamento ao longo do tempo revelam se os esforços de otimização estão funcionando e se novos tipos de bots estão surgindo. Google Search Console continua fornecendo dados essenciais sobre o comportamento de rastreamento do Google, enquanto o Bing Webmaster Tools oferece insights semelhantes para o crawler da Microsoft. As organizações mais sofisticadas implementam estratégias de monitoramento com múltiplas ferramentas combinando Google Search Console para dados de rastreamento tradicional, AmICited.com para rastreamento de crawlers de IA, análise de logs de servidor para visibilidade abrangente e ferramentas especializadas como o Conductor para simulação e análise de eficiência de rastreamento. Essa abordagem em camadas oferece visibilidade completa sobre como todos os tipos de bots interagem com seu site, permitindo decisões de otimização baseadas em dados abrangentes e não em suposições. O monitoramento regular—idealmente revisões semanais das métricas de rastreamento—permite identificar rapidamente problemas como picos inesperados de rastreamento, aumento nas taxas de erro ou novos bots agressivos, possibilitando resposta rápida antes que questões de crawl budget afetem o desempenho do site ou os custos operacionais.
Bots de IA como GPTBot e ClaudeBot operam com prioridades diferentes do Googlebot. Enquanto o Googlebot respeita limites de crawl budget e implementa controle de taxa sofisticado, bots de IA frequentemente demonstram padrões de rastreamento mais agressivos, consumindo de 12 a 15 vezes mais banda. Bots de IA priorizam a ingestão contínua de conteúdo para treinamento de modelos, e não apenas a indexação de busca, tornando seu comportamento fundamentalmente diferente e exigindo estratégias de otimização distintas.
Pesquisas indicam que o GPTBot da OpenAI pode consumir de 12 a 15 vezes mais banda do que o crawler do Google em certos sites, especialmente aqueles com grandes bibliotecas de conteúdo. O consumo exato depende do tamanho do seu site, frequência de atualização de conteúdo e de quantos bots de IA estão rastreando simultaneamente. Vários bots de IA rastreando ao mesmo tempo podem aumentar significativamente a carga do servidor e os custos de hospedagem.
Sim, você pode bloquear crawlers de IA específicos usando o robots.txt sem impactar o SEO tradicional. Entretanto, bloquear crawlers de IA significa sacrificar visibilidade em respostas geradas por IA do ChatGPT, Claude, Perplexity e outros aplicativos de IA. A decisão depende do seu modelo de negócios—editoras de conteúdo geralmente se beneficiam ao permitir o rastreamento, enquanto sites de e-commerce podem bloquear para evitar treinamento de concorrentes.
Um gerenciamento ruim do crawl budget pode resultar em páginas importantes não sendo rastreadas ou indexadas, indexação mais lenta de novo conteúdo, aumento da carga do servidor e custos de banda, experiência do usuário degradada devido ao consumo de recursos por bots e perda de oportunidades de visibilidade tanto em buscas tradicionais quanto em respostas geradas por IA. Grandes sites com milhões de páginas são os mais vulneráveis a esses impactos.
Para melhores resultados, monitore métricas de crawl budget semanalmente, com checagens diárias durante grandes lançamentos de conteúdo ou em picos inesperados de tráfego. Use o Google Search Console para dados tradicionais, o AmICited.com para rastreamento de crawlers de IA e logs do servidor para uma visibilidade abrangente dos bots. O monitoramento regular permite identificar rapidamente problemas antes que impactem o desempenho do site.
O robots.txt tem eficácia variável com bots de IA. Enquanto o Googlebot respeita rigorosamente as diretivas do robots.txt, bots de IA apresentam conformidade inconsistente—alguns seguem as regras enquanto outros as ignoram. Para controle mais confiável, implemente bloqueio específico por user-agent, limitação de taxa no nível do servidor ou use ferramentas de gerenciamento de bots baseadas em CDN como o Cloudflare para controle mais granular.
O crawl budget impacta diretamente a visibilidade em IA, pois bots de IA não podem citar ou referenciar conteúdo que não rastrearam. Se suas páginas importantes não forem rastreadas devido a restrições de orçamento, elas não aparecerão em respostas geradas por IA. Otimizar o crawl budget garante que seu melhor conteúdo seja descoberto por bots de IA, aumentando as chances de ser citado em respostas do ChatGPT, Claude e Perplexity.
Priorize páginas usando sitemaps dinâmicos que destaquem conteúdo recentemente atualizado, páginas de alto tráfego e páginas com potencial de conversão. Use o robots.txt para bloquear páginas de baixo valor como arquivos e duplicatas. Implemente URLs limpas e linking interno estratégico para direcionar bots ao conteúdo importante. Monitore quais páginas bots de IA realmente rastreiam com ferramentas como o AmICited.com para refinar sua estratégia.
Acompanhe como bots de IA rastreiam seu site e otimize sua visibilidade em respostas geradas por IA com a plataforma de monitoramento abrangente do AmICited.com.
Crawl budget é o número de páginas que os mecanismos de busca rastreiam em seu site dentro de um período. Saiba como otimizar o crawl budget para melhor indexaç...
Saiba o que significa orçamento de rastreamento para IA, como ele difere do orçamento de rastreamento tradicional dos mecanismos de busca e por que isso importa...

Saiba como permitir ou bloquear seletivamente crawlers de IA com base em objetivos de negócios. Implemente o acesso diferencial de crawlers para proteger seu co...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.