
Como Corrigir Desinformação em Respostas de IA?
Aprenda métodos eficazes para identificar, verificar e corrigir informações imprecisas em respostas geradas por IA como ChatGPT, Perplexity e outros sistemas de...
10 min de leitura

Inferência é o processo pelo qual um modelo de IA treinado gera saídas, previsões ou conclusões a partir de novos dados de entrada, aplicando padrões e conhecimentos adquiridos durante o treinamento. Representa a fase operacional em que sistemas de IA aplicam sua inteligência aprendida para resolver problemas do mundo real em ambientes de produção.
Inferência é o processo pelo qual um modelo de IA treinado gera saídas, previsões ou conclusões a partir de novos dados de entrada, aplicando padrões e conhecimentos adquiridos durante o treinamento. Representa a fase operacional em que sistemas de IA aplicam sua inteligência aprendida para resolver problemas do mundo real em ambientes de produção.
Inferência é o processo pelo qual um modelo de inteligência artificial treinado gera saídas, previsões ou conclusões a partir de novos dados de entrada, aplicando padrões e conhecimentos aprendidos durante a fase de treinamento. No contexto de sistemas de IA, a inferência representa a fase operacional em que modelos de aprendizado de máquina fazem a transição do laboratório para ambientes de produção para resolver problemas do mundo real. Quando você interage com ChatGPT, Perplexity, Google AI Overviews ou Claude, está vivenciando a inferência em IA em ação—o modelo está recebendo sua entrada e gerando respostas inteligentes com base em padrões aprendidos a partir de conjuntos de dados massivos de treinamento. Inferência é fundamentalmente diferente do treinamento; enquanto o treinamento ensina ao modelo o que fazer, a inferência é onde o modelo realmente executa, aplicando o conhecimento adquirido a dados que nunca viu antes.
A distinção entre treinamento de IA e inferência de IA é fundamental para entender como sistemas modernos de inteligência artificial operam. Durante a fase de treinamento, cientistas de dados alimentam redes neurais com enormes conjuntos de dados curados, permitindo que o modelo aprenda padrões, relações e regras de decisão por meio de otimização iterativa. Esse processo é computacionalmente intensivo, frequentemente exigindo semanas ou meses de processamento em hardware especializado como GPUs e TPUs. Uma vez concluído o treinamento e o modelo tenha convergido para pesos e parâmetros ideais, ele entra na fase de inferência. Neste ponto, o modelo fica “congelado”—não aprende mais com novos dados—e passa a aplicar os padrões aprendidos para gerar previsões ou saídas sobre entradas nunca vistas. Segundo pesquisas da IBM e Oracle, é na inferência que o verdadeiro valor de negócios da IA é realizado, permitindo que organizações implementem capacidades de IA em escala em sistemas de produção. O mercado de inferência em IA foi avaliado em USD 106,15 bilhões em 2025 e deve crescer para USD 254,98 bilhões até 2030, refletindo a explosiva demanda por capacidades de inferência em diversos setores.
A inferência em IA opera por meio de um processo de múltiplas etapas que transforma dados brutos de entrada em saídas inteligentes. Quando um usuário faz uma consulta para um grande modelo de linguagem como o ChatGPT, o pipeline de inferência começa com a codificação da entrada, em que o texto é convertido em tokens numéricos que a rede neural pode processar. O modelo então entra na fase de preenchimento (prefill), onde todos os tokens de entrada são processados simultaneamente por todas as camadas da rede neural, permitindo ao modelo compreender o contexto e as relações na consulta do usuário. Esta fase é computacionalmente pesada, mas necessária para a compreensão. Após a fase de preenchimento, o modelo entra na fase de decodificação, na qual gera tokens de saída sequencialmente, um de cada vez, com cada novo token dependendo de todos os anteriores na sequência. Essa geração sequencial é o que cria o efeito de streaming característico visto pelos usuários ao interagir com chatbots de IA. Por fim, a etapa de conversão da saída transforma os tokens previstos de volta em texto legível, imagens ou outros formatos compreensíveis e interativos para os usuários. Todo esse processo precisa ocorrer em milissegundos para aplicações em tempo real, tornando a otimização da latência de inferência uma preocupação crítica para provedores de serviços de IA.
Organizações que implementam sistemas de IA precisam escolher entre três principais arquiteturas de inferência, cada uma otimizada para diferentes casos de uso e requisitos de desempenho. A inferência em lote processa grandes volumes de dados offline em intervalos programados, sendo ideal para cenários em que respostas em tempo real não são necessárias, como geração de painéis analíticos diários, avaliações semanais de risco ou atualizações noturnas de recomendações. Essa abordagem é altamente eficiente e econômica, pois pode processar milhares de previsões simultaneamente, amortizando custos computacionais entre várias requisições. A inferência online, também chamada de inferência dinâmica, gera previsões instantaneamente sob demanda com latência mínima, sendo essencial para aplicações interativas como chatbots, mecanismos de busca e sistemas de detecção de fraudes em tempo real. Inferência online exige infraestrutura sofisticada para manter baixa latência e alta disponibilidade, frequentemente utilizando estratégias de cache e otimização de modelos para garantir respostas em milissegundos. A inferência em streaming processa continuamente dados provenientes de sensores, dispositivos IoT ou pipelines de dados em tempo real, fazendo previsões para cada ponto de dado à medida que chega. Esse tipo alimenta aplicações como manutenção preditiva de equipamentos industriais, veículos autônomos que processam dados de sensores em tempo real e sistemas de cidades inteligentes que analisam padrões de tráfego continuamente. Cada tipo de inferência exige diferentes considerações arquitetônicas, requisitos de hardware e estratégias de otimização.
| Aspecto | Inferência em Lote | Inferência Online | Inferência em Streaming |
|---|---|---|---|
| Requisito de Latência | Segundos a minutos | Milissegundos | Tempo real (subsegundo) |
| Processamento de Dados | Grandes conjuntos offline | Solicitações individuais sob demanda | Fluxo contínuo de dados |
| Casos de Uso | Análises, relatórios, recomendações | Chatbots, busca, detecção de fraudes | Monitoramento IoT, sistemas autônomos |
| Eficiência de Custo | Alta (amortizada entre muitas previsões) | Média (infraestrutura sempre ativa) | Média a alta (depende do volume de dados) |
| Escalabilidade | Excelente (processamento em lote) | Boa (exige balanceamento de carga) | Excelente (processamento distribuído) |
| Prioridade de Otimização do Modelo | Vazão | Equilíbrio entre latência e vazão | Equilíbrio entre latência e precisão |
| Requisitos de Hardware | GPUs/CPUs padrão | GPUs/TPUs de alto desempenho | Hardware de borda especializado ou sistemas distribuídos |
A otimização da inferência tornou-se uma disciplina fundamental, pois as organizações buscam implantar modelos de IA de maneira mais eficiente e econômica. Quantização é uma das técnicas de otimização mais impactantes, reduzindo a precisão numérica dos pesos do modelo de 32 bits para 8 bits ou até 4 bits inteiros. Essa redução pode diminuir o tamanho do modelo em 75-90%, mantendo 95-99% da precisão original, resultando em inferências mais rápidas e menor uso de memória. Poda de modelos remove neurônios, conexões ou até camadas inteiras não críticas da rede neural, eliminando parâmetros redundantes que não contribuem significativamente para as previsões. Pesquisas mostram que a poda pode reduzir a complexidade do modelo em 50-80% sem perda substancial de precisão. Destilação de conhecimento treina um modelo “aluno” menor e mais rápido para imitar o comportamento de um “professor” maior e mais preciso, permitindo implantação em dispositivos com recursos limitados mantendo desempenho razoável. Otimização do processamento em lote agrupa múltiplas requisições de inferência para maximizar a utilização da GPU e a vazão. Cache de chave-valor armazena resultados intermediários para evitar cálculos redundantes durante a fase de decodificação em modelos de linguagem. Segundo a NVIDIA, combinar várias técnicas de otimização pode proporcionar melhorias de desempenho de até 10x e reduzir custos de infraestrutura em 60-70%. Essas otimizações são essenciais para implantar inferência em larga escala, especialmente para organizações que executam milhares de solicitações simultâneas.
Aceleração por hardware é fundamental para atingir os requisitos de latência e vazão das cargas de trabalho modernas de inferência em IA. Unidades de Processamento Gráfico (GPUs) continuam sendo os aceleradores de inferência mais usados devido à sua arquitetura paralela, naturalmente adequada para as operações matriciais dominantes em redes neurais. GPUs da NVIDIA alimentam a maioria das implantações de inferência de grandes modelos de linguagem no mundo, com seus núcleos CUDA especializados permitindo paralelismo massivo. Unidades de Processamento Tensor (TPUs), desenvolvidas pelo Google, são ASICs customizados otimizados especificamente para operações de redes neurais, oferecendo melhor desempenho por watt em certos cenários do que GPUs convencionais. FPGAs (Field-Programmable Gate Arrays) fornecem hardware personalizável que pode ser reprogramado para tarefas de inferência específicas, oferecendo flexibilidade para aplicações especializadas. Circuitos Integrados de Aplicação Específica (ASICs) como a TPU do Google ou o WSE-3 da Cerebras são projetados para cargas de trabalho particulares de inferência, oferecendo desempenho excepcional, mas com flexibilidade limitada. A escolha do hardware depende de vários fatores: arquitetura do modelo, latência exigida, demandas de vazão, restrições de energia e custo total de propriedade. Para inferência na borda, em dispositivos móveis ou sensores IoT, aceleradores de borda especializados e unidades de processamento neural (NPUs) possibilitam inferência eficiente com consumo mínimo de energia. O movimento global em direção às fábricas de IA—infraestrutura altamente otimizada para “fabricar” inteligência em escala—impulsionou grandes investimentos em hardware para inferência, com empresas implantando milhares de GPUs e TPUs em data centers para atender à demanda crescente por serviços de IA.
Sistemas de IA generativa como ChatGPT, Claude e Perplexity dependem inteiramente da inferência para gerar texto, código, imagens e outros conteúdos de forma semelhante à humana. Ao enviar um prompt para esses sistemas, o processo de inferência começa com a tokenização da sua entrada em representações numéricas processáveis pela rede neural. O modelo executa então a fase de preenchimento, processando todos os tokens de entrada simultaneamente para construir um entendimento abrangente de sua solicitação, incluindo contexto, intenção e nuances. Em seguida, o modelo entra na fase de decodificação, gerando tokens de saída sequencialmente, prevendo o próximo token mais provável com base em todos os anteriores e nos padrões aprendidos dos dados de treinamento. Essa geração token a token explica o texto transmitido em tempo real nessas plataformas. O processo de inferência precisa equilibrar múltiplos objetivos: gerar respostas precisas, coerentes e contextualmente apropriadas, mantendo baixa latência para o engajamento do usuário. Decodificação especulativa, uma técnica avançada de otimização de inferência, permite que um modelo menor antecipe múltiplos tokens futuros enquanto o modelo maior valida essas previsões, reduzindo significativamente a latência. A escala da inferência para grandes modelos de linguagem é impressionante—o ChatGPT da OpenAI processa milhões de solicitações de inferência diariamente, cada uma gerando centenas ou milhares de tokens, exigindo infraestrutura computacional massiva e estratégias sofisticadas de otimização para viabilidade econômica.
Para organizações preocupadas com a presença de sua marca e citação de conteúdo em respostas geradas por IA, o monitoramento de inferência tornou-se cada vez mais importante. Quando sistemas de IA como Perplexity, Google AI Overviews ou Claude geram respostas, realizam inferência em seus modelos treinados para produzir saídas que podem fazer referência ou citar seu domínio, marca ou conteúdo. Compreender como funcionam os sistemas de inferência ajuda as organizações a otimizar sua estratégia de conteúdo para garantir a representação adequada em respostas geradas por IA. A AmICited é especializada em monitorar onde marcas e domínios aparecem nas saídas de inferência de IA em várias plataformas, proporcionando visibilidade sobre como sistemas de IA citam e referenciam seu conteúdo. Esse monitoramento é crucial porque sistemas de inferência podem incluir ou excluir sua marca nas respostas com base na qualidade dos dados de treinamento, sinais de relevância e escolhas de otimização do modelo. Organizações podem usar dados de monitoramento de inferência para entender quais conteúdos são citados, com que frequência sua marca aparece em respostas de IA e se seu domínio está sendo corretamente atribuído. Essa inteligência possibilita decisões orientadas por dados sobre otimização de conteúdo, estratégias de SEO e posicionamento de marca no novo cenário de buscas impulsionado por IA. À medida que a inferência se torna a principal interface de descoberta de informações, monitorar sua presença em saídas geradas por IA é tão importante quanto a otimização tradicional para mecanismos de busca.
Implantar sistemas de inferência em escala apresenta diversos desafios técnicos, operacionais e estratégicos que as organizações precisam enfrentar. Gerenciamento de latência permanece um desafio constante, pois usuários esperam respostas em menos de um segundo de aplicações de IA interativas, mas modelos complexos com bilhões de parâmetros exigem tempo computacional significativo. Otimização de vazão é igualmente crítica—organizações precisam atender a milhares ou milhões de requisições de inferência simultâneas mantendo latência e precisão aceitáveis. Deriva de modelo ocorre quando o desempenho da inferência degrada ao longo do tempo à medida que a distribuição de dados do mundo real se distancia dos dados de treinamento, exigindo monitoramento contínuo e retreinamento periódico do modelo. Interpretabilidade e explicabilidade tornam-se cada vez mais importantes à medida que sistemas de inferência em IA tomam decisões que afetam usuários, exigindo das organizações o entendimento e explicação dos motivos das previsões dos modelos. Conformidade regulatória traz desafios crescentes, com regulamentos como o AI Act da União Europeia impondo requisitos de transparência, detecção de vieses e supervisão humana em sistemas de inferência. Qualidade dos dados permanece fundamental—sistemas de inferência só são tão bons quanto os dados em que foram treinados, e dados ruins levam a saídas enviesadas, imprecisas ou prejudiciais. Custos de infraestrutura podem ser substanciais, com implantações de inferência em larga escala exigindo grandes investimentos em GPUs, TPUs, redes e refrigeração. Escassez de talentos faz com que as organizações tenham dificuldade em encontrar engenheiros e cientistas de dados especializados em otimização de inferência, implantação de modelos e MLOps, elevando custos de contratação e atrasando prazos de implantação.
O futuro da inferência em IA está evoluindo rapidamente em diversas direções transformadoras, que vão redefinir como as organizações implementam e utilizam sistemas de IA. Inferência na borda—ou seja, executar inferência em dispositivos locais em vez de data centers na nuvem—está acelerando, impulsionada por avanços em compressão de modelos, hardware especializado para borda e preocupações com privacidade. Essa mudança viabilizará capacidades de IA em tempo real em smartphones, dispositivos IoT e sistemas autônomos sem depender de conectividade com a nuvem. Inferência multimodal, em que modelos processam e geram texto, imagens, áudio e vídeo simultaneamente, está se tornando cada vez mais comum, exigindo novas estratégias de otimização e considerações de hardware. Modelos de raciocínio que realizam inferência em múltiplas etapas para resolver problemas complexos estão surgindo, com sistemas como o o1 da OpenAI demonstrando que a inferência pode ser ampliada com mais tempo de computação e tokens, e não apenas pelo tamanho do modelo. Arquiteturas de serviço desagregado estão ganhando adoção, com clusters de hardware separados lidando com as fases de preenchimento e decodificação da inferência, otimizando o uso de recursos para diferentes padrões computacionais. Decodificação especulativa e outras técnicas avançadas de inferência estão se tornando práticas padrão, permitindo reduções de latência de 2 a 3 vezes. Inferência na borda combinada com aprendizado federado permitirá que organizações implantem capacidades de IA localmente enquanto mantêm privacidade e reduzem o uso de banda. O mercado de inferência em IA deve crescer a uma CAGR de 19,2% até 2030, impulsionado pela adoção corporativa crescente, novos casos de uso e a necessidade econômica de otimizar custos de inferência. À medida que a inferência se torna a principal carga de trabalho na infraestrutura de IA, técnicas de otimização, hardware especializado e frameworks de software específicos para inferência se tornarão cada vez mais sofisticados e essenciais para vantagem competitiva.
O treinamento de IA é o processo de ensinar um modelo a reconhecer padrões usando grandes conjuntos de dados, enquanto a inferência de IA ocorre quando esse modelo treinado aplica o que aprendeu para gerar previsões ou saídas em novos dados. O treinamento é computacionalmente intensivo e acontece uma vez, enquanto a inferência costuma ser mais rápida, menos exigente em recursos e ocorre continuamente em ambientes de produção. Pense no treinamento como estudar para uma prova e na inferência como realizar a prova em si.
A latência de inferência—o tempo que um modelo leva para gerar uma saída—é fundamental para a experiência do usuário e aplicações em tempo real. Inferência com baixa latência possibilita respostas instantâneas em chatbots, tradução em tempo real, veículos autônomos e sistemas de detecção de fraudes. Alta latência pode tornar aplicações inutilizáveis para tarefas sensíveis ao tempo. Empresas otimizam a latência usando técnicas como quantização, poda de modelos e hardware especializado como GPUs e TPUs para atender aos acordos de nível de serviço.
Os três principais tipos são: inferência em lote (processamento de grandes conjuntos de dados offline), inferência online (geração de previsões instantaneamente sob demanda) e inferência em streaming (processamento contínuo de dados de sensores ou dispositivos IoT). Inferência em lote é adequada para cenários como painéis analíticos diários, inferência online alimenta chatbots e mecanismos de busca, e inferência em streaming permite sistemas de monitoramento em tempo real. Cada tipo tem requisitos de latência e casos de uso diferentes.
A quantização reduz a precisão numérica dos pesos do modelo de 32 bits para 8 bits ou menos, diminuindo significativamente o tamanho do modelo e os requisitos computacionais, mantendo a precisão. A poda remove neurônios ou conexões não essenciais da rede neural, reduzindo a complexidade. Ambas as técnicas podem reduzir a latência de inferência em 50-80% e diminuir custos de hardware. Esses métodos de otimização são essenciais para implantações em dispositivos de borda e plataformas móveis.
A inferência é o mecanismo central que permite que sistemas de IA generativa produzam texto, imagens e código. Quando você solicita algo ao ChatGPT, o processo de inferência tokeniza sua entrada, processa-a pelas camadas da rede neural treinada e gera tokens de saída um a um. A fase de preenchimento processa todos os tokens de entrada simultaneamente, enquanto a fase de decodificação gera as saídas de forma sequencial. Essa capacidade de inferência é o que torna grandes modelos de linguagem responsivos e práticos para aplicações reais.
O monitoramento de inferência acompanha como modelos de IA se comportam em produção, incluindo precisão, latência e qualidade das saídas. Plataformas como a AmICited monitoram onde marcas e domínios aparecem em respostas geradas por IA em sistemas como ChatGPT, Perplexity e Google AI Overviews. Entender o comportamento da inferência ajuda as organizações a garantir que seu conteúdo seja citado e representado corretamente quando sistemas de IA fazem referência a seus domínios ou informações de marca.
Os aceleradores de inferência mais comuns incluem GPUs (Unidades de Processamento Gráfico) para processamento paralelo, TPUs (Unidades de Processamento Tensor) otimizadas para redes neurais, FPGAs (Matrizes de Portas Programáveis em Campo) para cargas de trabalho personalizáveis e ASICs (Circuitos Integrados de Aplicação Específica) projetados para tarefas específicas. GPUs são as mais utilizadas por equilibrar desempenho e custo, enquanto TPUs se destacam em inferência em grande escala. A escolha depende de requisitos de vazão, restrições de latência e orçamento.
O mercado global de inferência em IA foi avaliado em USD 106,15 bilhões em 2025 e tem previsão de alcançar USD 254,98 bilhões até 2030, representando uma taxa composta de crescimento anual (CAGR) de 19,2%. Esse crescimento rápido reflete a crescente adoção corporativa de aplicações de IA, com 78% das organizações usando IA em 2024, contra 55% em 2023. A expansão é impulsionada pela demanda por aplicações de IA em tempo real em setores como saúde, finanças, varejo e sistemas autônomos.
Comece a rastrear como os chatbots de IA mencionam a sua marca no ChatGPT, Perplexity e outras plataformas. Obtenha insights acionáveis para melhorar a sua presença de IA.
Aprenda métodos eficazes para identificar, verificar e corrigir informações imprecisas em respostas geradas por IA como ChatGPT, Perplexity e outros sistemas de...
Saiba o que é alucinação de IA, por que ela acontece no ChatGPT, Claude e Perplexity, e como detectar informações falsas geradas por IA nos resultados de busca....
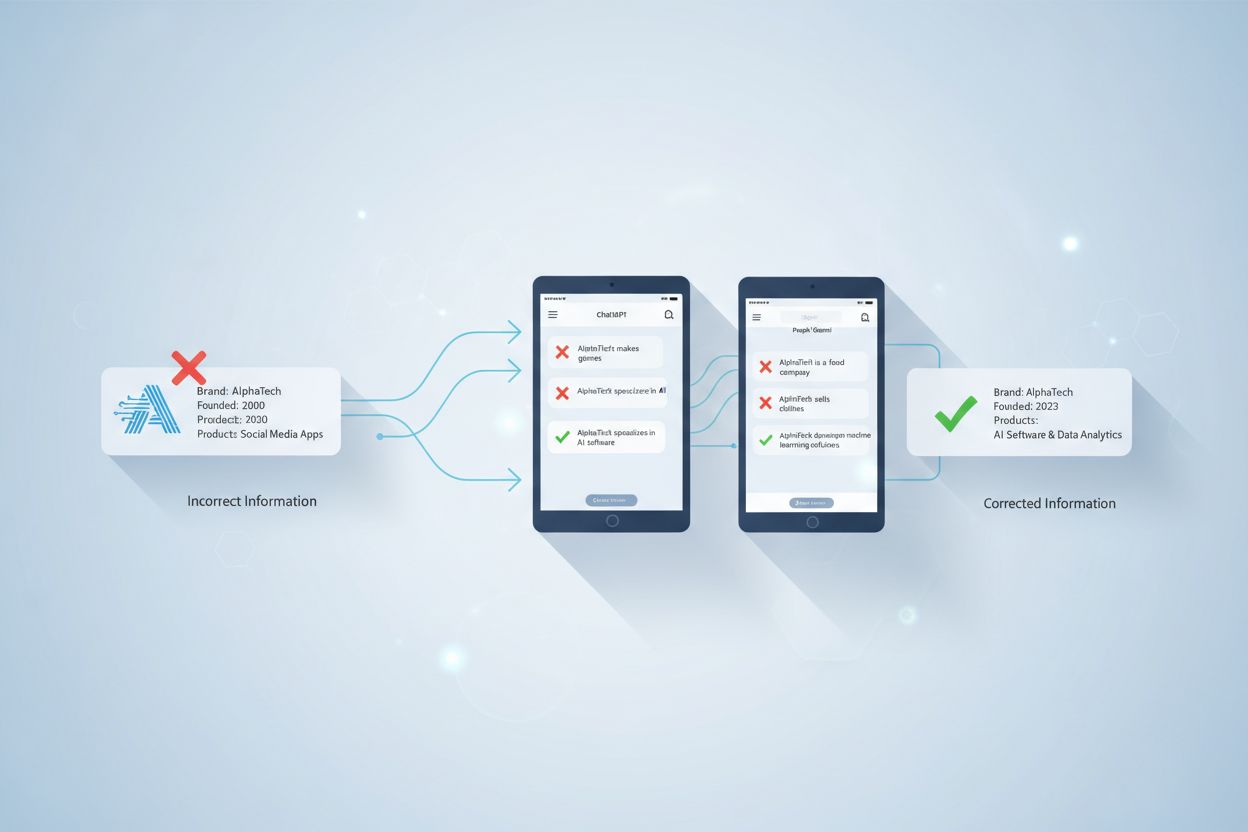
Aprenda a identificar e corrigir informações incorretas sobre marcas em sistemas de IA como ChatGPT, Gemini e Perplexity. Descubra ferramentas de monitoramento,...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.