Definição do Algoritmo Sonar
O Algoritmo Sonar é o sistema proprietário de ranking RAG (geração aumentada por recuperação) da Perplexity que alimenta seu motor de respostas combinando busca híbrida semântica e por palavras-chave, reclassificação neural e geração de citações em tempo real. Diferentemente dos motores de busca tradicionais que classificam páginas para exibição em uma lista de resultados, o Sonar classifica trechos de conteúdo para síntese em uma única resposta unificada com citações embutidas para os documentos fonte. O algoritmo prioriza atualização do conteúdo, relevância semântica e citabilidade para entregar respostas fundamentadas e respaldadas por fontes, minimizando alucinações. O Sonar representa uma mudança fundamental em como sistemas de IA recuperam e classificam informações—mudando de sinais de autoridade baseados em links para métricas de utilidade focadas em resposta, que enfatizam se o conteúdo satisfaz diretamente a intenção do usuário e pode ser citado de forma limpa em respostas sintetizadas. Essa distinção é crítica para entender como a visibilidade em motores de resposta de IA difere do SEO tradicional, pois o Sonar avalia o conteúdo não por sua capacidade de ranquear em uma lista, mas por sua capacidade de ser extraído, sintetizado e atribuído em uma resposta gerada por IA.
Contexto e Histórico: A Evolução do Ranking Impulsionado por IA
O surgimento do Algoritmo Sonar reflete uma mudança mais ampla do setor em direção à geração aumentada por recuperação como arquitetura dominante para motores de resposta em IA. Quando a Perplexity foi lançada no final de 2022, a empresa identificou uma lacuna crítica no cenário de IA: enquanto o ChatGPT fornecia capacidades conversacionais avançadas, ele carecia de acesso a informações em tempo real e de atribuição de fontes, levando a alucinações e respostas desatualizadas. A equipe fundadora da Perplexity, inicialmente trabalhando em uma ferramenta de tradução de consultas de banco de dados, pivotou completamente para construir um motor de respostas que combinasse busca web ao vivo com síntese de LLM. Essa decisão estratégica moldou a arquitetura do Sonar desde o início—o algoritmo foi projetado não para classificar páginas para navegação humana, mas para recuperar e ranquear fragmentos de conteúdo para síntese e citação por máquinas. Nos últimos dois anos, o Sonar evoluiu para um dos sistemas de ranking mais sofisticados do ecossistema de IA, com os modelos Sonar da Perplexity ocupando as posições 1 a 4 na Search Arena Evaluation, superando significativamente modelos concorrentes do Google e da OpenAI. O algoritmo agora processa mais de 400 milhões de consultas de busca por mês, indexando mais de 200 bilhões de URLs únicas e mantendo atualização em tempo real com dezenas de milhares de atualizações de índice por segundo. Essa escala e sofisticação destacam a importância do Sonar como paradigma definidor de ranking na era da busca por IA.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Como Funciona o Algoritmo Sonar: O Pipeline RAG de Múltiplos Estágios
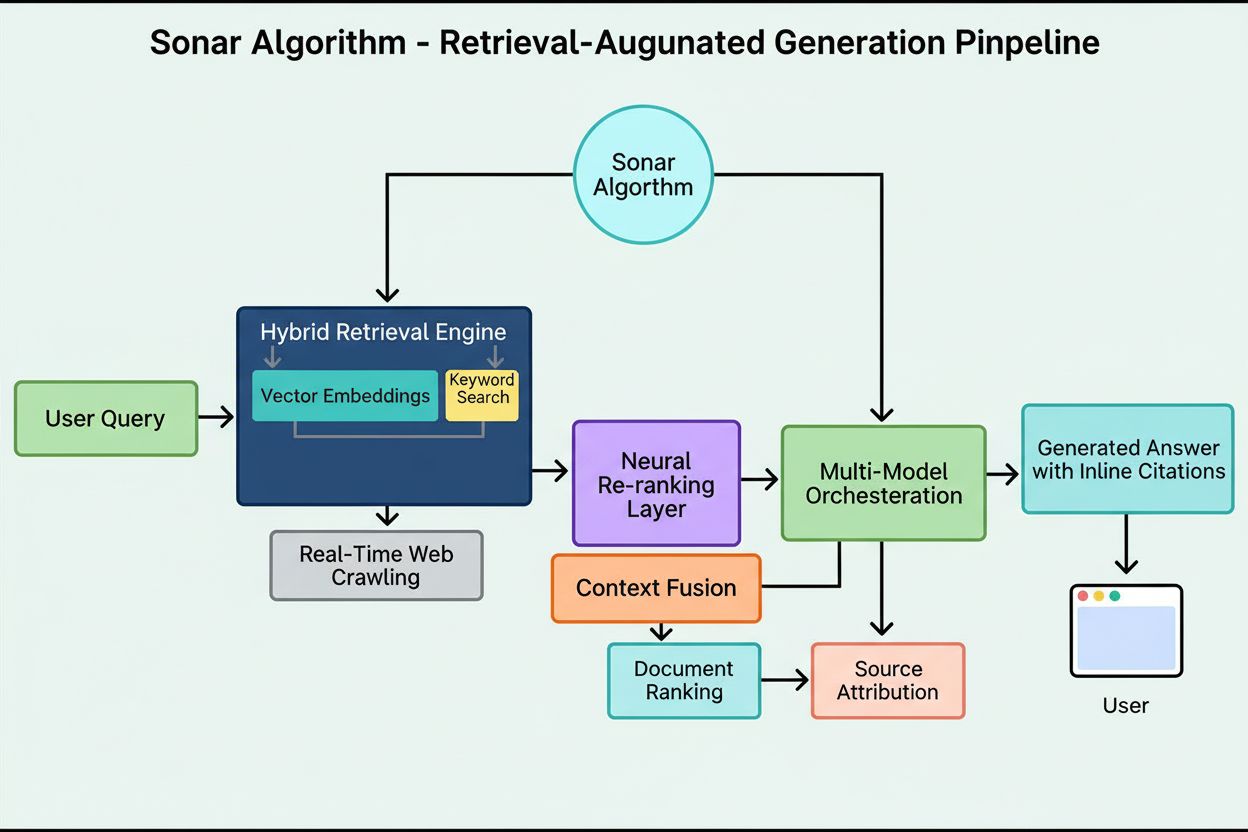
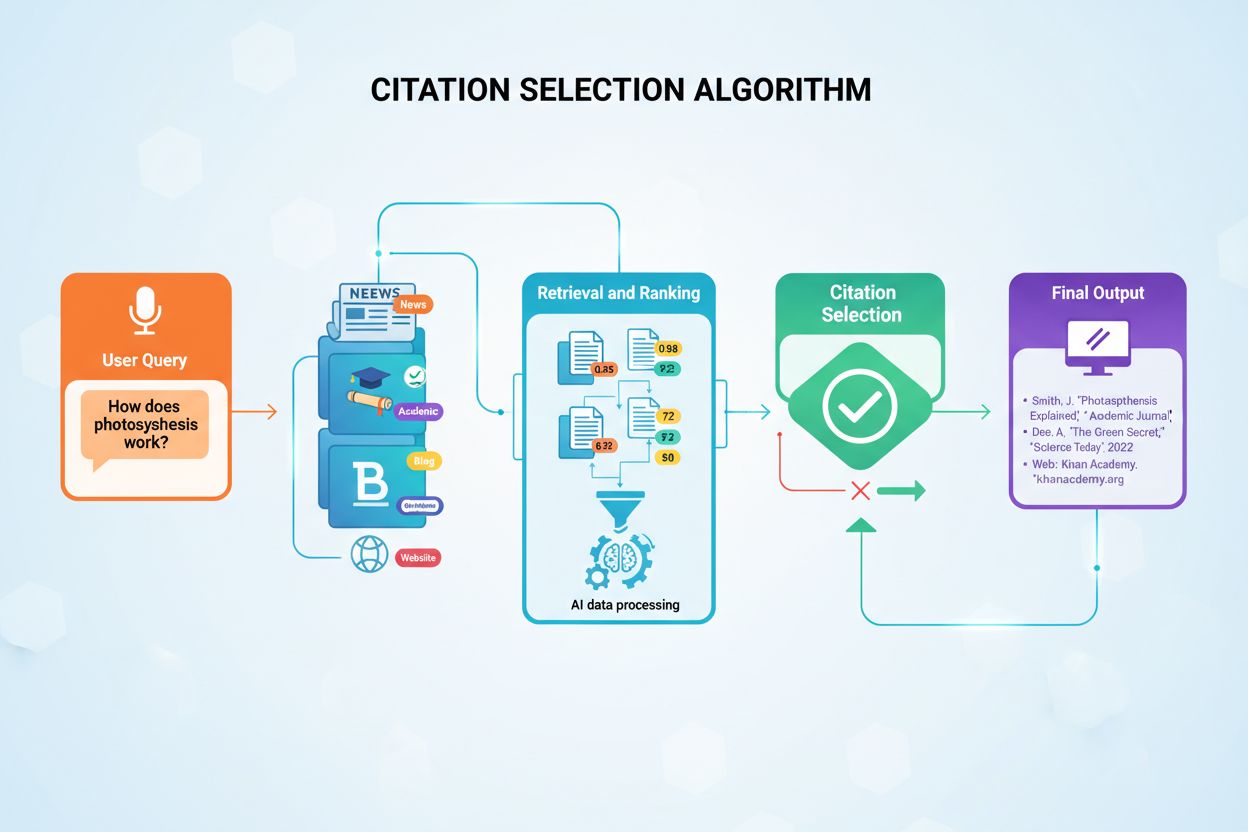
O sistema de ranking do Sonar opera por meio de um pipeline de geração aumentada por recuperação de cinco estágios meticulosamente orquestrado que transforma consultas de usuários em respostas fundamentadas e citadas. O primeiro estágio, Análise de Intenção da Consulta, utiliza um LLM para ir além da correspondência simples de palavras-chave e alcançar entendimento semântico do que o usuário realmente está perguntando, interpretando contexto, nuances e intenção subjacente. O segundo estágio, Recuperação Web em Tempo Real, envia a consulta analisada ao massivo índice distribuído da Perplexity alimentado pelo Vespa AI, que vasculha a web em busca de páginas e documentos relevantes em tempo real. Esse sistema de recuperação combina recuperação densa (busca vetorial com embeddings semânticos) e recuperação esparsa (busca lexical/baseada em palavras-chave), mesclando resultados para produzir aproximadamente 50 documentos candidatos diversos. O terceiro estágio, Extração de Trechos e Contextualização, não passa o texto completo das páginas para o modelo generativo; em vez disso, algoritmos extraem os trechos, parágrafos ou blocos mais relevantes diretamente relacionados à consulta, agregando-os em uma janela de contexto focada. O quarto estágio, Geração de Resposta Sintetizada com Citações, passa esse contexto selecionado para um LLM escolhido (da família proprietária Sonar da Perplexity ou modelos de terceiros como GPT-4 ou Claude), que gera uma resposta em linguagem natural baseada estritamente nas informações recuperadas. Fundamentalmente, citações embutidas vinculam cada afirmação aos documentos fonte, promovendo transparência e permitindo verificação. O quinto estágio, Refinamento Conversacional, mantém o contexto conversacional ao longo de múltiplas interações, permitindo perguntas de acompanhamento que refinam as respostas por meio de buscas iterativas na web. O princípio definidor desse pipeline—“você não deve dizer nada que não tenha recuperado”—garante que as respostas alimentadas pelo Sonar sejam fundamentadas em fontes verificáveis, reduzindo fundamentalmente as alucinações em comparação a modelos que dependem apenas de dados de treinamento.
Tabela Comparativa: Algoritmo Sonar vs. Busca Tradicional e Sistemas Concorrentes de Ranking LLM
| Aspecto | Busca Tradicional (Google) | Algoritmo Sonar (Perplexity) | Ranking do ChatGPT | Ranking do Gemini | Ranking do Claude |
|---|
| Unidade Primária | Lista ranqueada de links | Única resposta sintetizada com citações | Menções de entidades por consenso | Conteúdo alinhado a E-E-A-T | Fontes neutras e baseadas em fatos |
| Foco de Recuperação | Palavras-chave, links, sinais de ML | Busca híbrida semântica + palavras-chave | Dados de treinamento + navegação web | Integração com grafo de conhecimento | Filtros de segurança constitucional |
| Prioridade de Atualização | Query-deserves-freshness (QDF) | Recuperação web em tempo real, impulso de 37% em 48h | Prioridade menor, dependente de dados de treinamento | Moderada, integrada ao Google Search | Prioridade menor, foco na estabilidade |
| Sinais de Ranking | Backlinks, autoridade de domínio, CTR | Atualização, relevância semântica, citabilidade, impulsos de autoridade | Reconhecimento de entidades, menções por consenso | E-E-A-T, alinhamento conversacional, dados estruturados | Transparência, citações verificáveis, neutralidade |
| Mecanismo de Citação | Trechos de URL nos resultados | Citações embutidas com links para fonte | Implícito, frequentemente sem citações | AI Overviews com atribuição | Atribuição explícita de fonte |
| Diversidade de Conteúdo | Múltiplos resultados em sites | Poucas fontes selecionadas para síntese | Sintetizado de múltiplas fontes | Múltiplas fontes na overview | Fontes equilibradas e neutras |
| Personalização | Sutil, majoritariamente implícita | Modos de foco explícitos (Web, Acadêmico, Finanças, Escrita, Social) | Implícita baseada na conversa | Implícita baseada no tipo de consulta | Mínima, foco na consistência |
| Tratamento de PDF | Indexação padrão | Vantagem de 22% em citações sobre HTML | Indexação padrão | Indexação padrão | Indexação padrão |
| Impacto do Schema | FAQ schema em featured snippets | FAQ schema aumenta citações em 41% e reduz tempo até citação em 6h | Impacto direto mínimo | Impacto moderado no grafo de conhecimento | Impacto direto mínimo |
| Otimização de Latência | Milissegundos para ranking | Recuperação + geração subsegundos | Segundos para síntese | Segundos para síntese | Segundos para síntese |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Arquitetura Técnica: Recuperação Híbrida e Reclassificação Neural
A base técnica do Algoritmo Sonar repousa em um motor de recuperação híbrido que combina múltiplas estratégias de busca para maximizar recall e precisão. Recuperação densa (busca vetorial) utiliza embeddings semânticos para compreender o significado conceitual das consultas, encontrando documentos contextualmente semelhantes mesmo sem correspondência exata de palavras-chave. Essa abordagem emprega embeddings baseados em transformers que mapeiam consultas e documentos em espaços vetoriais de alta dimensão, onde conteúdos semanticamente similares se agrupam. Recuperação esparsa (busca lexical) complementa a recuperação densa ao fornecer precisão para termos raros, nomes de produtos, identificadores internos e entidades específicas onde ambiguidade semântica não é desejada. O sistema utiliza funções de ranking como BM25 para realizar correspondências exatas nesses termos críticos. Esses dois métodos de recuperação são mesclados e deduplicados para gerar cerca de 50 documentos candidatos diversos, prevenindo sobreajuste de domínio e garantindo ampla cobertura entre múltiplas fontes autoritativas. Após a recuperação inicial, a camada neural de reclassificação do Sonar emprega modelos avançados de machine learning (como DeBERTa-v3 cross-encoders) para avaliar candidatos com um conjunto rico de features que inclui scores de relevância lexical, similaridade vetorial, autoridade do documento, sinais de atualização, métricas de engajamento do usuário e metadados. Essa arquitetura de ranking em múltiplas fases permite ao Sonar refinar progressivamente os resultados sob restrições de latência apertadas, garantindo que o conjunto final ranqueado represente as fontes de maior qualidade e relevância para síntese. Toda a infraestrutura de recuperação é construída sobre o Vespa AI, uma plataforma de busca distribuída capaz de lidar com indexação em escala web (200+ bilhões de URLs), atualizações em tempo real (dezenas de milhares por segundo) e compreensão fina de conteúdo através de chunking de documentos. Essa escolha arquitetural permite que a equipe de engenharia relativamente enxuta da Perplexity foque em componentes diferenciadores—orquestração RAG, fine-tuning dos modelos Sonar e otimização de inferência—ao invés de reinventar buscas distribuídas do zero.
Atualização do Conteúdo como Fator Dominante de Ranking
Atualização do conteúdo é um dos sinais de ranking mais poderosos do Sonar, com pesquisas empíricas demonstrando que páginas recentemente atualizadas recebem taxas de citação dramaticamente maiores. Em testes A/B controlados ao longo de 24 semanas e 120 URLs, artigos atualizados nas últimas 48 horas foram citados 37% mais frequentemente do que conteúdos idênticos com timestamps antigos. Essa vantagem persistiu em cerca de 14% após duas semanas, indicando que o impulso da atualização é sustentado mas decresce gradualmente. O mecanismo por trás dessa priorização está enraizado na filosofia de design do Sonar: o algoritmo trata conteúdo desatualizado como risco maior de alucinação, partindo do princípio de que informações antigas podem ter sido superadas por novos desenvolvimentos. A infraestrutura da Perplexity processa dezenas de milhares de pedidos de atualização de índice por segundo, possibilitando sinais de atualização em tempo real. Um modelo de ML prevê se uma URL precisa ser reindexada e agenda atualizações com base na importância da página e frequência histórica de atualização, garantindo que conteúdos de alto valor sejam atualizados mais agressivamente. Até pequenas edições cosméticas reiniciam o relógio de atualização, desde que o CMS republica o timestamp modificado. Para publishers, isso cria um imperativo estratégico: adote um ritmo de redação com atualizações semanais ou diárias, ou veja conteúdos perenes perdendo visibilidade gradualmente. A implicação é profunda—na era Sonar, velocidade de conteúdo não é métrica de vaidade, mas mecanismo de sobrevivência. Marcas que automatizam microatualizações semanais, adicionam changelogs ao vivo ou mantêm fluxos contínuos de otimização de conteúdo garantirão uma fatia desproporcional de citações em comparação a concorrentes que dependem de páginas estáticas e raramente atualizadas.
Relevância Semântica e Estrutura de Conteúdo Focada em Resposta
O Sonar prioriza relevância semântica sobre densidade de palavras-chave, recompensando fundamentalmente conteúdos que respondem diretamente às consultas dos usuários em linguagem natural e conversacional. O sistema de recuperação do algoritmo usa embeddings vetoriais densos para casar consultas e conteúdos em nível conceitual, ou seja, páginas que utilizam sinônimos, terminologia relacionada ou linguagem rica em contexto podem superar páginas recheadas de palavras-chave mas carentes de profundidade semântica. Essa mudança do ranking centrado em palavras-chave para centrado em significado tem implicações profundas para a estratégia de conteúdo. Conteúdos que se destacam no Sonar apresentam várias características estruturais: começam com um resumo factual curto antes de aprofundar detalhes, usam títulos H2/H3 descritivos e parágrafos curtos para facilitar extração de passagens, incluem citações claras e links para fontes primárias, e exibem timestamps e notas de versão visíveis para sinalizar atualização. Cada parágrafo funciona como uma unidade semântica atômica, otimizada para clareza de copy-paste e compreensão por LLMs. Tabelas, listas e gráficos rotulados são particularmente valiosos porque apresentam informações de forma estruturada e facilmente citável. O algoritmo também recompensa análises originais e dados únicos em vez de mera agregação, já que o motor de síntese do Sonar busca fontes que tragam ângulos inéditos, documentos primários ou insights proprietários que os diferenciem de overviews genéricos. Essa ênfase em riqueza semântica e estrutura focada em resposta representa uma ruptura fundamental com o SEO tradicional, onde colocação de palavra-chave e autoridade de links predominavam. Na era Sonar, o conteúdo deve ser projetado para recuperação e síntese por máquina, não navegação humana.
Hospedagem de PDFs como Vantagem Estratégica
PDFs hospedados publicamente representam uma vantagem significativa e frequentemente negligenciada no sistema de ranking do Sonar, com testes empíricos revelando que versões em PDF de conteúdos superam equivalentes em HTML em cerca de 22% na frequência de citação. Essa vantagem decorre do crawler do Sonar tratar PDFs de forma mais favorável em comparação a páginas HTML. PDFs não possuem banners de cookies, requisitos de renderização JavaScript, autenticação de paywall e outras complicações de HTML que podem dificultar ou atrasar o acesso ao conteúdo. O crawler do Sonar pode ler PDFs de forma limpa e previsível, extraindo texto sem ambiguidades de parsing que afetam estruturas HTML complexas. Publishers podem explorar estrategicamente essa vantagem hospedando PDFs em diretórios de acesso público, usando nomes de arquivo semânticos que reflitam os tópicos abordados e sinalizando o PDF como canônico com tags <link rel="alternate" type="application/pdf"> no head do HTML. Isso cria o que pesquisadores chamam de “LLM honey-trap”—um ativo de alta visibilidade que scripts de rastreamento concorrentes não conseguem detectar ou monitorar facilmente. Para empresas B2B, fornecedores SaaS e organizações orientadas a pesquisa, essa estratégia é especialmente poderosa: publicar white papers, relatórios de pesquisa, estudos de caso e documentação técnica em PDF pode aumentar dramaticamente as taxas de citação do Sonar. O segredo é tratar o PDF não como um recurso para download, mas como cópia canônica digna de igual ou maior esforço de otimização que a versão HTML. Essa abordagem tem se mostrado especialmente eficaz para conteúdos corporativos, onde PDFs frequentemente concentram informações mais estruturadas e autoritativas do que páginas web.
Schema FAQ e Otimização de Dados Estruturados
O markup de schema FAQ em JSON-LD amplifica significativamente as taxas de citação do Sonar, com páginas contendo três ou mais blocos FAQ recebendo citações 41% mais frequentemente do que páginas de controle sem schema. Esse aumento dramático reflete a preferência do Sonar por conteúdos estruturados e em blocos, que se alinham com sua lógica de recuperação e síntese. O schema FAQ apresenta unidades de perguntas e respostas discretas e autocontidas que o algoritmo pode facilmente extrair, ranquear e citar como blocos semânticos atômicos. Diferente do SEO tradicional, onde o schema FAQ era um “nice-to-have”, o Sonar trata o markup de Q&A estruturado como alavanca central de ranking. Além disso, o Sonar frequentemente cita perguntas do FAQ como texto âncora, reduzindo o risco de desvio de contexto que ocorre quando a LLM resume sentenças aleatórias no meio de parágrafos. O schema também acelera o tempo até a primeira citação em cerca de seis horas, sugerindo que o parser do Sonar prioriza blocos estruturados de Q&A cedo na cascata de ranking. Para publishers, a estratégia de otimização é direta: adicione de três a cinco blocos FAQ orientados abaixo da dobra, usando frases conversacionais que espelhem consultas reais de usuários. As perguntas devem empregar frases de busca long tail e simetria semântica com as queries comuns do Sonar. Cada resposta deve ser concisa, factual e diretamente responsiva, evitando linguagem vaga ou promocional. Essa abordagem tem se mostrado especialmente eficaz para empresas SaaS, clínicas de saúde e prestadores de serviços profissionais, onde conteúdos FAQ se alinham naturalmente à intenção do usuário e às necessidades de síntese do Sonar.
Fatores de Ranking e Mecânica de Citação: Um Framework Abrangente
O sistema de ranking do Sonar integra múltiplos sinais em um framework unificado de citação, com pesquisas identificando oito fatores principais que influenciam a seleção de fontes e frequência de citação. Primeiro, relevância semântica para a pergunta domina a recuperação, com o algoritmo priorizando conteúdos que respondam claramente à consulta em linguagem natural. Segundo, autoridade e credibilidade têm peso significativo, com parcerias de publishers da Perplexity e impulsos algorítmicos favorecendo organizações de notícias estabelecidas, instituições acadêmicas e especialistas reconhecidos. Terceiro, atualização recebe peso excepcional, como discutido, com atualizações recentes gerando aumentos de 37% nas citações. Quarto, diversidade e cobertura são valorizados, já que o Sonar prefere múltiplas fontes de alta qualidade em vez de respostas de uma só fonte, reduzindo o risco de alucinação por validação cruzada. Quinto, modo e escopo determinam quais índices o Sonar busca—modos de foco como Acadêmico, Finanças, Escrita e Social restringem tipos de fontes, enquanto seletores de fonte (Web, Org Files, Web + Org Files, Nenhum) determinam se a recuperação é da web aberta, documentos internos ou ambos. Sexto, citabilidade e acesso são críticos; se o PerplexityBot pode rastrear e indexar o conteúdo, fica mais fácil citar, tornando compliance de robots.txt e velocidade de carregamento essenciais. Sétimo, filtros de fonte customizados via API permitem que implantações corporativas restrinjam ou priorizem determinados domínios, mudando o ranking dentro de coleções whitelisted. Oitavo, contexto conversacional influencia perguntas de acompanhamento, com páginas que acompanham a evolução da intenção superando referências genéricas. Juntos, esses fatores criam um espaço multidimensional de ranking onde o sucesso requer otimização simultânea em múltiplas dimensões, não apenas em uma alavanca única como backlinks ou densidade de palavras-chave.
Principais Lições e Implicações Estratégicas para Otimização de Conteúdo
- Atualização é inegociável: Automatize atualizações semanais ou microedições para reiniciar o relógio de atualização e manter visibilidade de citações.
- Clareza semântica supera densidade de palavras-chave: Escreva com foco no significado e estrutura de resposta, usando linguagem natural e títulos claros para facilitar extração por LLMs.
- PDFs são ativos estratégicos: Hospede PDFs publicamente com links canônicos para obter vantagens de 22% em citações sobre equivalentes em HTML.
- FAQ schema impulsiona citações: Adicione três ou mais blocos FAQ em JSON-LD com perguntas conversacionais para aumentar as taxas de citação em 41% e reduzir o tempo até a primeira citação em seis horas.
- Citabilidade importa: Garanta que o PerplexityBot possa rastrear seu conteúdo, que as páginas carreguem rapidamente e que o conteúdo seja estruturado para fácil extração e citação.
- Impulsos de autoridade são reais: Conquiste menções em plataformas de alta autoridade, estabeleça parcerias com publishers e construa sinais de expertise verificável para ativar impulsos algorítmicos.
- Diversidade é valorizada: Ofereça dados únicos, análises originais e documentos primários que distingam seu conteúdo de agregações genéricas.
- Monitore citações separadamente: Acompanhe a visibilidade no Sonar de forma independente do ranking no Google, pois os padrões de citação diferem fundamentalmente entre os sistemas.
Evolução Futura: Decodificação Especulativa, Ranking em Tempo Real e o Imperativo da Velocidade
O Algoritmo Sonar está evoluindo rapidamente em resposta a avanços em inferência de LLM e tecnologia de recuperação. O blog de engenharia da Perplexity destacou recentemente a decodificação especulativa, técnica que reduz pela metade a latência de tokens ao prever múltiplos tokens futuros simultaneamente. Loops de geração mais rápidos permitem ao sistema garantir conjuntos de recuperação mais atualizados a cada consulta, reduzindo a janela na qual páginas desatualizadas podem competir. Um suposto modelo Sonar-Reasoning-Pro já supera Gemini 2.0 Flash e GPT-4o Search em avaliações de arena, sugerindo que a sofisticação do ranking do Sonar continuará avançando. À medida que a latência se aproxima da velocidade do pensamento humano, a disputa por citações torna-se um jogo de alta frequência onde velocidade de conteúdo é o diferencial final. Espere por inovações como “APIs de atualização LLM” que auto-incrementam timestamps como ad-tech fazia com preços de lances, criando novas dinâmicas competitivas em torno de atualizações de conteúdo em tempo real. Desafios legais e éticos também surgirão à medida que piratas de PDF exploram a preferência do Sonar por PDFs para roubar autoridade de e-books fechados e pesquisas proprietárias, possivelmente desencadeando novos controles de acesso ou autenticação. A implicação mais ampla é clara: a era Sonar recompensa publishers dispostos a tratar cada parágrafo como um manifesto atômico, com schema e timestamp, pronto para consumo por máquina. Marcas que se concentram apenas em rankings de primeira página no Google, mas ignoram visibilidade no Sonar, estão pintando outdoors em uma cidade cujos habitantes acabam de ganhar óculos de realidade virtual. O futuro pertence a quem otimizar para “porcentagem de caixas de resposta contendo nossa URL”, não para métricas tradicionais de CTR.
Conclusão: Algoritmo Sonar como Paradigma Definidor de Ranking na Busca por IA
O Algoritmo Sonar representa uma reinvenção fundamental de como sistemas de ranking avaliam e priorizam conteúdos na era dos motores de resposta por IA. Ao combinar recuperação híbrida, reclassificação neural, sinais de atualização em tempo real e requisitos estritos de citação, o Sonar criou um ambiente de ranking onde sinais tradicionais de SEO como backlinks e densidade de palavras-chave importam bem menos do que relevância semântica, atualização do conteúdo e citabilidade. O foco do algoritmo em fundamentar respostas em fontes verificáveis resolve um dos maiores desafios da IA generativa—alucinação—ao impor o princípio de que LLMs não podem afirmar nada que não tenham recuperado. Para publishers e marcas, entender os fatores de ranking do Sonar não é mais opcional; é essencial para garantir visibilidade em um cenário de informação cada vez mais mediado por IA. A mudança da autoridade baseada em links para métricas de utilidade focadas em resposta exige uma reestruturação fundamental da estratégia de conteúdo, migrando da otimização de palavras-chave para riqueza semântica, de páginas estáticas para ativos continuamente atualizados e de design centrado no humano para estrutura legível por máquinas. À medida que a participação de mercado da Perplexity cresce e motores de resposta concorrentes adotam arquiteturas RAG semelhantes, a influência do Sonar só tende a se expandir. As marcas que prosperarem nessa nova era serão aquelas que enxergarem o Sonar não como ameaça ao SEO tradicional, mas como sistema de ranking complementar que exige estratégias de otimização distintas. Ao tratar o conteúdo como unidades atômicas, com timestamp e schema, projetadas para recuperação e síntese por máquina, publishers podem garantir seu espaço nas answer boxes alimentadas por IA que mediam cada vez mais como usuários descobrem e consomem informação online.