
Recunoașterea Entităților
Recunoașterea Entităților este o capacitate NLP AI care identifică și categorizează entități denumite în text. Află cum funcționează, aplicațiile sale în monito...
11 min citire

Explorează modul în care sistemele AI recunosc și procesează entitățile din text. Află despre modelele NER, arhitecturi transformer și aplicații reale ale înțelegerii entităților.
Înțelegerea entităților a devenit o capacitate esențială în sistemele moderne de inteligență artificială, permițând mașinilor să identifice și să înțeleagă actorii cheie, locurile și conceptele din textul nestructurat. De la motoare de căutare care înțeleg intenția utilizatorului, la chatbot-uri capabile să răspundă la întrebări complexe despre persoane și organizații specifice, recunoașterea entităților formează fundamentul interacțiunii relevante om-calculator. Această capabilitate tehnică este critică în toate industriile—instituțiile financiare o utilizează pentru monitorizarea conformității, sistemele de sănătate pentru gestionarea dosarelor pacienților, iar platformele de e-commerce se bazează pe ea pentru a înțelege mențiunile despre produse și feedbackul clienților. Înțelegerea modului în care sistemele AI extrag și interpretează entitățile este esențială pentru oricine dezvoltă sau implementează aplicații NLP în medii de producție.
Recunoașterea entităților denumite (NER) este sarcina NLP de a identifica și clasifica entitățile denumite—unități specifice, cu semnificație—din text în categorii predefinite. Aceste entități reprezintă subiectele concrete care poartă greutatea semantică a limbajului: persoane care acționează, organizații care iau decizii, locații unde au loc evenimente, expresii temporale care ancorează evenimentele în timp, valori monetare care cuantifică tranzacții și produse care se cumpără și se vând. Clasificarea entităților este importantă deoarece transformă textul brut în cunoștințe structurate pe care mașinile le pot înțelege și folosi; fără aceasta, un sistem nu poate distinge între „Apple compania” și „apple fructul” sau înțelege că „John Smith” și „J. Smith” se referă la aceeași persoană. Capacitatea de a clasifica corect entitățile permite aplicații precum construcția de grafuri de cunoștințe, extragerea de informații, răspunsul la întrebări și detecția relațiilor.
| Tip Entitate | Definiție | Exemplu |
|---|---|---|
| PERSON | Ființe umane individuale | “Steve Jobs,” “Marie Curie” |
| ORGANIZATION | Companii, instituții, grupuri | “Microsoft,” “Națiunile Unite,” “Universitatea Harvard” |
| LOCATION | Locuri și regiuni geografice | “New York,” “Râul Amazon,” “Silicon Valley” |
| DATE | Expresii temporale și perioade de timp | “15 ianuarie 2024,” “marțea viitoare,” “T3 2023” |
| MONEY | Valori monetare și valute | “$50 milioane,” “€100,” “5000 yeni” |
| PRODUCT | Bunuri, servicii, creații | “iPhone 15,” “Windows 11,” “ChatGPT” |
Sistemele AI moderne procesează entitățile printr-un pipeline sofisticat în mai multe etape, care începe cu tokenizarea, împărțind textul brut în tokeni discreți ce servesc drept unități fundamentale pentru procesările ulterioare. Fiecare token este apoi convertit într-o reprezentare numerică prin word embeddings—vectori densi ce captează semnificația semantică—care sunt introduși în arhitecturi de rețele neuronale concepute pentru a înțelege contextul și relațiile. Modelele bazate pe transformere, care au devenit arhitectura dominantă în NLP, procesează secvențe întregi în paralel și nu secvențial, permițând captarea dependențelor pe distanțe lungi și a relațiilor contextuale complexe, esențiale pentru înțelegerea exactă a entităților. Mecanismul de self-attention din Transformere permite fiecărui token să cântărească dinamic importanța fiecărui alt token din secvență, creând reprezentări contextuale bogate în care sensul unui cuvânt este modelat de contextul său; astfel „bancă” este înțeles diferit în „bancă de râu” față de „bancă de economii”. Modelele lingvistice pre-antrenate precum BERT și GPT învață tipare lingvistice generale din corpuri masive de text înainte de a fi ajustate pentru sarcini de recunoaștere a entităților, permițând valorificarea reprezentărilor sintaxei, semanticii și cunoștințelor generale. Ultimul strat al sistemelor de recunoaștere a entităților folosește de obicei o abordare de etichetare a secvențelor—adesea implementată ca un Conditional Random Field (CRF) sau un simplu cap de clasificare—care atribuie etichete de entitate fiecărui token pe baza reprezentărilor contextuale învățate de rețeaua neuronală. Această arhitectură permite sistemelor AI să înțeleagă nu doar ce entități sunt prezente, ci și cum se leagă între ele și ce roluri au în contextul mai larg al textului.
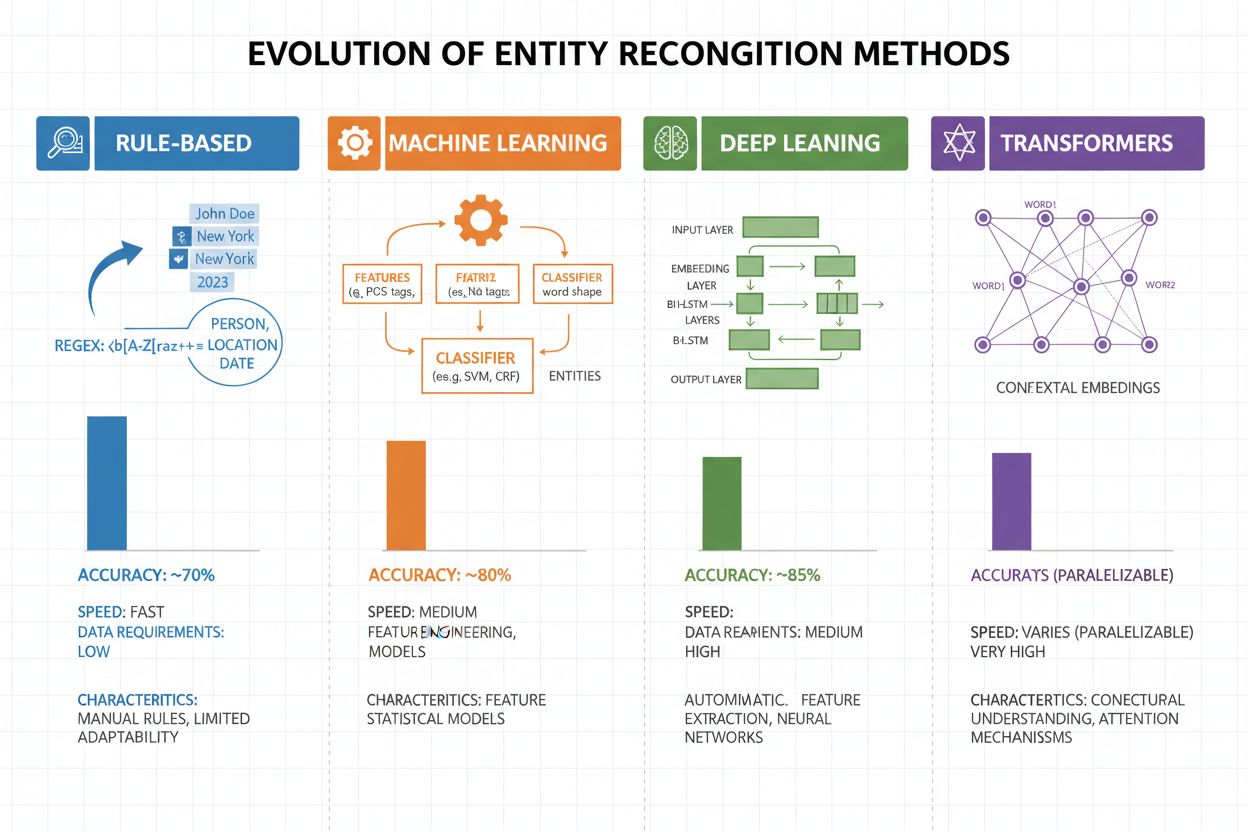
Recunoașterea entităților a evoluat dramatic în ultimele două decenii, trecând de la abordări simple bazate pe reguli la arhitecturi neuronale sofisticate. Sistemele timpurii se bazau pe reguli și dicționare create manual, folosind expresii regulate și potriviri de tipare pentru a identifica entități—metode care erau interpretabile și necesitau puține date de antrenament, dar generalizau slab și necesitau mentenanță ridicată. Apariția machine learning-ului a adus abordări supravegheate precum Support Vector Machines (SVM) și Conditional Random Fields (CRF), care învățau din date etichetate prin feature engineering, îmbunătățind semnificativ acuratețea, deși necesitau experți pentru proiectarea caracteristicilor relevante. Metodele de deep learning, în special LSTM și BiLSTM, au automatizat extragerea caracteristicilor prin învățarea reprezentărilor direct din textul brut, obținând acuratețe mult mai mare fără inginerie manuală de caracteristici, dar necesitând seturi mai mari de date etichetate. Modelele bazate pe transformere precum BERT și RoBERTa au revoluționat domeniul folosind mecanisme de self-attention pentru a capta dependențe pe distanțe lungi și nuanțe contextuale, atingând rezultate de top (BERT a atins 90,9% F1 pe CoNLL-2003) și permițând transfer learning din modele pre-antrenate masiv. Compromisul între complexitate și acuratețe s-a schimbat dramatic: deși sistemele bazate pe reguli sunt încă valoroase pentru medii cu resurse reduse sau domenii foarte specializate, modelele transformer domină atunci când există suficiente resurse de calcul și date etichetate, iar alternative mai ușoare precum DistilBERT oferă o variantă de compromis pentru sisteme de producție cu constrângeri de latență.
Modelele bazate pe transformere au transformat fundamental recunoașterea entităților, înlocuind procesarea secvențială cu mecanisme paralele de self-attention care iau simultan în considerare toți tokenii dintr-o propoziție, permițând o înțelegere contextuală mult mai bogată decât arhitecturile anterioare. BERT și variantele sale (RoBERTa, DistilBERT, ALBERT) folosesc pre-antrenament bidirecțional pe corpuri masive de date neetichetate, învățând reprezentări universale ale limbajului ce captează atât informații sintactice cât și semantice, înainte de a fi ajustate pe sarcini NER cu seturi relativ mici de date etichetate. Paradigma pre-antrenament și fine-tuning este deosebit de puternică pentru recunoașterea entităților: modelele pre-antrenate pe miliarde de tokeni dezvoltă reprezentări robuste ale structurii limbii și tiparelor de entități, care pot fi apoi adaptate la domenii specifice cu doar câteva mii de exemple, reducând dramatic necesarul de date față de antrenarea de la zero. Transformerele excelează în înțelegerea entităților datorită mecanismului multi-head attention, care permite ca diferite capete de atenție să se specializeze pe diferite tipuri de relații între entități—unele capete pot evidenția limitele sintactice, altele pot captura asocieri semantice între entități și contextul lor. Recunoașterea multilingvă a entităților a fost revoluționată de modele precum mBERT și XLM-RoBERTa, pre-antrenate pe peste 100 de limbi simultan, permițând transfer zero-shot și few-shot către limbi cu resurse reduse și legare cross-linguală a entităților. Modele emergente precum GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) împing limitele mai departe, permițând recunoașterea entităților pe bază de instrucțiuni, unde modelele pot identifica tipuri arbitrare de entități specificate în prompturi în limbaj natural, fără fine-tuning specific sarcinii, ceea ce reprezintă o tranziție către sisteme de înțelegere a entităților mai flexibile și generalizabile.
În ciuda progresului remarcabil, sistemele de recunoaștere a entităților se confruntă cu provocări reale persistente care limitează implementarea lor practică, iar ambiguitatea și sensibilitatea la context sunt printre cele mai dificil de depășit—cuvântul „Apple” necesită înțelegerea dacă se referă la fruct sau la compania tehnologică, pe baza contextului, iar chiar și modelele de top întâmpină dificultăți în dezambiguizare semantică în texte zgomotoase sau ambigue. Entitățile necunoscute (OOV) reprezintă o altă provocare fundamentală: modelele antrenate pe seturi standard pot să nu întâlnească niciodată entități rare, nume proprii din domenii emergente sau variații scrise greșit, ceea ce duce la clasificare greșită sau nerecunoaștere totală. Adaptarea la domeniu rămâne problematică deoarece modelele antrenate pe corpusuri de știri (precum CoNLL-2003) performează slab pe texte biomedicale, juridice sau din social media unde distribuțiile de entități și tiparele lingvistice diferă semnificativ, necesitând re-etichetare și fine-tuning costisitor pentru fiecare domeniu nou. Erorile de detecție a limitelor—când sistemele identifică corect existența unei entități, dar stabilesc greșit începutul sau sfârșitul—sunt frecvente mai ales pentru entități cu mai multe cuvinte și structuri încapsulate, precum diferențierea dintre „New York City” și „New York” sau gestionarea entităților de tipul „Chief Executive Officer of Apple Inc.”. Complexitățile multilingve complică suplimentar, deoarece limbile au convenții diferite de capitalizare, structuri morfologice și tipare de denumire a entităților, ceea ce face ca modelele antrenate pe engleză să eșueze adesea în limbi cu proprietăți lingvistice diferite. Lipsa de date pentru domenii specializate precum nume de boli rare, tehnologii emergente sau terminologie corporativă proprietară creează un blocaj unde costul etichetării manuale este prohibitiv, forțând practicienii să aleagă între acuratețe redusă sau investiții mari în colectarea de date specifice domeniului.
Înțelegerea entităților a devenit indispensabilă în toate industriile, transformând modul în care organizațiile extrag valoare din text nestructurat. În extragerea de informații și construcția de grafuri de cunoștințe, recunoașterea entităților permite popularea automată a bazelor de date structurate din documente, alimentând motoare de căutare și sisteme de recomandare care înțeleg relațiile dintre persoane, locuri și concepte. Organizațiile din sănătate folosesc înțelegerea entităților pentru a identifica denumiri de medicamente, doze, simptome și date demografice ale pacienților din notele clinice, îmbunătățind suportul decizional clinic și detectarea la scară a interacțiunilor adverse medicamentoase. Instituțiile financiare folosesc recunoașterea entităților pentru a extrage simboluri de acțiuni, valori monetare și evenimente de piață din fluxuri de știri și rapoarte financiare, facilitând sisteme de tranzacționare algoritmică și platforme de management al riscului ce reacționează în timp real. Firmele de tehnologie juridică aplică înțelegerea entităților pentru a identifica automat părți, date, obligații și clauze de răspundere în contracte, reducând timpul de revizuire de la săptămâni la ore. Platformele de suport clienți și chatbot folosesc recunoașterea entităților pentru a extrage intenții și context relevant—cum ar fi numere de comandă, denumiri de produse și tipuri de probleme—permițând rutare mai precisă și rezolvare mai rapidă. Platformele e-commerce utilizează înțelegerea entităților pentru a identifica nume de produse, branduri, caracteristici și specificații din recenziile clienților și căutări, îmbunătățind descoperirea produselor și personalizarea. Sistemele de recomandare de conținut folosesc recunoașterea entităților pentru a înțelege cu ce entități interacționează utilizatorii, permițând filtrare colaborativă și recomandări bazate pe conținut mai sofisticate, care cresc implicarea și veniturile.
Implementarea unui sistem de înțelegere a entităților de producție necesită atenție la pregătirea datelor, selecția modelului și evaluare. Pornește de la date etichetate de înaltă calitate: stabilește definiții clare pentru tipurile de entități, folosește metrici de acord între anotații pentru a asigura consistența și urmărește cel puțin 500-1000 de exemple etichetate per tip de entitate, deși aplicațiile specifice domeniului pot necesita mai multe. Selecția modelului depinde de constrângerile tale: sistemele bazate pe reguli oferă interpretabilitate și latență redusă pentru domenii bine definite, modelele ML tradiționale (CRF, SVM) oferă performanță bună cu date moderate, iar modelele bazate pe transformere (BERT, RoBERTa) oferă acuratețe de top dar necesită mai multe resurse de calcul și date. Strategiile de antrenare și fine-tuning ar trebui să includă tehnici de augmentare a datelor pentru a gestiona dezechilibrul de clase, cross-validation pentru prevenirea overfittingului și ajustarea atentă a hiperparametrilor precum rata de învățare și batch size. Evaluează sistemul folosind precizia (entități corect identificate), recall-ul (entități găsite din totalul celor reale) și scorul F1 (media armonică între cele două), cu metrici separate pentru fiecare tip de entitate pentru a identifica punctele slabe. Considerente de implementare includ cerințele de latență (procesare batch vs. în timp real), nevoile de scalare și integrarea cu pipeline-urile existente de date, iar monitorizarea post-implementare trebuie să urmărească deriva performanței, rata de fals pozitiv și feedbackul utilizatorilor pentru a declanșa cicluri de reantrenare.
Ecosistemul de instrumente pentru înțelegerea entităților oferă soluții pentru orice scală și caz de utilizare. Librării open-source precum spaCy oferă pipeline-uri NER gata de producție cu performanță impresionantă (89,22% F1 pe benchmark-uri standard) și documentație excelentă, fiind ideală pentru echipe cu expertiză ML; NLTK oferă valoare educațională și capabilități NER de bază; iar Hugging Face Transformers permite accesul la modele pre-antrenate de ultimă generație ce pot fi ajustate cu ușurință pentru domenii specifice. Serviciile cloud gestionate elimină grijile de infrastructură: Google Cloud Natural Language API, AWS Comprehend și IBM Watson NLP oferă recunoaștere pre-antrenată de entități cu suport pentru mai multe limbi și tipuri de entități, gestionând automat scalarea și integrându-se ușor cu pipeline-urile de date din cloud. Framework-uri specializate precum Flair (bazat pe PyTorch, cu suport excelent pentru etichetare de secvențe) și DeepPavlov (cu modele pre-antrenate pentru mai multe limbi și domenii) sunt potrivite pentru cercetători și echipe care au nevoie de mai multă personalizare decât oferă librăriile generale. Decizia între a construi soluții personalizate și a folosi instrumente predefinite depinde de sensibilitatea datelor (on-premise vs. cloud), nivelul de acuratețe dorit, specificitatea domeniului și expertiza echipei: folosește API-uri gestionate pentru aplicații generale cu tipuri standard de entități, adoptă librării open-source pentru personalizare pe date interne și dezvoltă modele custom doar când soluțiile existente nu ating acuratețea sau latența necesară.
Viitorul înțelegerii entităților este modelat de modele lingvistice mari care aduc flexibilitate și performanță fără precedent acestei sarcini. Modele precum GPT-4 și Claude demonstrează capabilități impresionante de recunoaștere a entităților în regim few-shot și zero-shot, permițând organizațiilor să identifice tipuri personalizate de entități cu doar câteva exemple sau chiar cu simple descrieri în limbaj natural, reducând dramatic efortul de etichetare și accelerând implementarea. Înțelegerea multimodală a entităților devine un nou orizont, combinând text, imagini și date structurate pentru a recunoaște entități în documente, facturi și pagini web cu context mai bogat, facilitând aplicații precum procesarea automată a documentelor și căutarea vizuală. Îmbunătățirile procesării în timp real datorate distilării modelelor și implementării pe edge fac posibilă recunoașterea sofisticată a entităților pe dispozitive mobile și sisteme IoT, deschizând aplicații noi în realitatea augmentată, traducere în timp real și sisteme autonome. Progresele în fine-tuning specific domeniului duc la apariția unor modele specializate pentru domenii biomedicale, juridice și financiare care depășesc modelele generale cu ordine de mărime, tehnici precum pre-antrenamentul adaptat pe domeniu și transfer learning făcând această abordare tot mai accesibilă. Pe măsură ce aceste tehnologii evoluează, înțelegerea entităților va deveni un strat de bază invizibil în sistemele AI, permițând mașinilor să înțeleagă lumea cu o profunzime semantică apropiată de cea umană și deschizând posibilități pe care abia începem să le intuim.
Pe măsură ce sisteme AI precum ChatGPT, Perplexity și Google AI Overviews devin tot mai integrate în modul în care informația este descoperită și consumată, înțelegerea modului în care aceste sisteme recunosc și menționează entități—inclusiv brandul tău—devine esențială. Înțelegerea entităților este mecanismul prin care AI identifică și procesează mențiunile despre companii, produse, persoane și concepte. Când monitorizezi modul în care sistemele AI înțeleg și menționează brandul tău prin recunoașterea entităților, obții perspective despre:
Acesta este exact ceea ce urmărește AmICited—monitorizând modul în care sistemele AI recunosc și menționează brandul tău ca entitate pe diverse platforme AI. Înțelegând recunoașterea entităților, poți înțelege mai bine modul în care AI percepe și comunică despre afacerea ta.
Recunoașterea entităților (NER) identifică și clasifică entitățile din text (de exemplu, 'Apple' ca ORGANIZAȚIE), în timp ce legarea entităților conectează acele entități la baze de cunoștințe sau referințe canonice (de exemplu, legarea lui 'Apple' la pagina de Wikipedia a Apple Inc.). Recunoașterea entităților este primul pas; legarea entităților adaugă ancorare semantică.
Modelele de ultimă generație bazate pe transformere precum BERT ating un scor F1 de 90,9% pe benchmark-uri standard precum CoNLL-2003. Totuși, acuratețea variază semnificativ în funcție de domeniu—modelele antrenate pe știri performează slab pe texte biomedicale sau din social media. Acuratețea reală depinde mult de adaptarea la domeniu și de calitatea datelor.
Da, modelele multilingve precum mBERT și XLM-RoBERTa suportă peste 100 de limbi simultan. Totuși, performanța variază în funcție de limbă din cauza diferențelor de capitalizare, morfologie și date de antrenament disponibile. Modelele specifice pe limbă depășesc de obicei modelele multilingve pentru aplicații critice.
Sistemele bazate pe reguli folosesc tipare și dicționare create manual (rapide, ușor de interpretat, dar fragile). Sistemele bazate pe ML învață din date etichetate (mai flexibile, generalizare mai bună, dar necesită date de antrenament și inginerie de caracteristici). Abordările moderne cu deep learning automatizează extragerea caracteristicilor, atingând acuratețe superioară.
Sistemele bazate pe reguli necesită doar definiții de tipare. Modelele ML tradiționale au nevoie de 300-500 de exemple etichetate. Modelele bazate pe transformere funcționează cu peste 800 de exemple, dar beneficiază de transfer learning—modelele pre-antrenate pot obține rezultate bune cu doar 100-200 de exemple specifice domeniului prin fine-tuning.
Provocările cheie includ: ambiguitatea (același cuvânt cu sensuri diferite), entități necunoscute, adaptarea la domeniu (modelele antrenate pe un domeniu eșuează pe altul), erori de detecție a limitelor, complexități multilingve și lipsa de date pentru domenii specializate. Acestea necesită proiectare atentă a sistemului și ajustare specifică domeniului.
Contextul este crucial—'bancă' are sensuri diferite în 'bancă de râu' vs. 'bancă de economii'. Transformerele moderne folosesc self-attention pentru a evalua contextul tuturor tokenilor din jur, permițând dezambiguizarea entităților pe baza contextului lingvistic și semantic. Gestionarea slabă a contextului este o sursă majoră de erori în recunoașterea entităților.
Dezvoltările viitoare includ: modele lingvistice mari care permit recunoașterea entităților fără antrenament prealabil, înțelegere multimodală combinând text și imagini, procesare în timp real pe dispozitive edge și progrese în fine-tuning specific domeniului. Înțelegerea entităților va deveni un strat de bază invizibil, permițând mașinilor să înțeleagă lumea cu o înțelegere semantică asemănătoare celei umane.
AmICited urmărește mențiunile entităților în sistemele AI precum ChatGPT, Perplexity și Google AI Overviews. Înțelege cum AI percepe și menționează brandul tău în timp real.
Recunoașterea Entităților este o capacitate NLP AI care identifică și categorizează entități denumite în text. Află cum funcționează, aplicațiile sale în monito...

Află cum să construiești vizibilitatea entității în căutarea AI. Stăpânește optimizarea knowledge graph, schema markup și strategii SEO pe entități pentru a cre...

Află cum optimizarea entităților ajută brandul tău să devină recunoscut de LLM-uri. Stăpânește optimizarea grafurilor de cunoștințe, marcarea cu schema și strat...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.