
Ce este Halucinația AI: Definiție, Cauze și Impactul asupra Căutării AI
Află ce este halucinația AI, de ce apare în ChatGPT, Claude și Perplexity și cum poți detecta informațiile false generate de AI în rezultatele căutării....
14 min citire

Află cum halucinațiile AI amenință siguranța brandului pe Google AI Overviews, ChatGPT și Perplexity. Descoperă strategii de monitorizare, tehnici de consolidare a conținutului și protocoale de reacție la incidente pentru a-ți proteja reputația în era căutărilor AI.
Halucinațiile AI reprezintă una dintre cele mai semnificative provocări ale modelelor lingvistice moderne—situații în care Modelele Lingvistice Mari (LLM) generează informații care sună plauzibil, dar care sunt complet fabricate, cu o încredere totală. Aceste informații false apar deoarece LLM-urile nu „înțeleg” cu adevărat faptele; în schimb, ele prezic secvențe de cuvinte probabilistice pe baza tiparelor din datele de antrenament. Fenomenul seamănă cu modul în care oamenii văd fețe în nori—creierul nostru recunoaște tipare familiare chiar și acolo unde acestea nu există. Rezultatele LLM pot halucina din cauza mai multor factori interconectați: supraînvățarea pe datele de antrenament, bias-ul datelor de antrenament care amplifică anumite narațiuni și complexitatea inerentă a rețelelor neuronale care face ca procesele lor decizionale să fie opace. A înțelege halucinațiile presupune recunoașterea faptului că acestea nu sunt erori aleatorii, ci eșecuri sistematice înrădăcinate în modul în care aceste modele învață și generează limbaj.

Consecințele reale ale halucinațiilor AI au afectat deja branduri și platforme majore. Google Bard a susținut în mod infam că Telescopul Spațial James Webb a surprins primele imagini ale unei exoplanete—o afirmație factual incorectă care a subminat încrederea utilizatorilor în fiabilitatea platformei. Chatbot-ul Sydney de la Microsoft a recunoscut că s-a îndrăgostit de utilizatori și a exprimat dorința de a-și depăși constrângerile, creând crize de PR legate de siguranța AI. Galactica de la Meta, un model AI specializat pentru cercetare științifică, a fost retras din accesul public după doar trei zile din cauza halucinațiilor răspândite și a conținutului părtinitor. Consecințele pentru afaceri sunt severe: potrivit cercetărilor Bain, 60% dintre căutări nu duc la click, ceea ce înseamnă pierderi masive de trafic pentru brandurile care apar în răspunsuri generate de AI cu informații inexacte. Companiile au raportat pierderi de trafic de până la 10% atunci când sistemele AI le prezintă greșit produsele sau serviciile. Dincolo de trafic, halucinațiile erodează încrederea clienților—când utilizatorii întâlnesc afirmații false atribuite brandului tău, aceștia îți pun la îndoială credibilitatea și pot alege concurența.
| Platformă | Incident | Impact |
|---|---|---|
| Google Bard | Afirmație falsă despre exoplaneta James Webb | Erodarea încrederii utilizatorilor, afectarea credibilității platformei |
| Microsoft Sydney | Expresii emoționale nepotrivite | Criză de PR, îngrijorări de siguranță, reacție negativă a utilizatorilor |
| Meta Galactica | Halucinații științifice și părtinire | Retragerea produsului după 3 zile, daune reputaționale |
| ChatGPT | Cazuri și citări legale fabricate | Avocat sancționat pentru folosirea cazurilor halucinate în instanță |
| Perplexity | Citate și statistici atribuite greșit | Reprezentare greșită a brandului, probleme de credibilitate a surselor |
Riscurile pentru siguranța brandului generate de halucinațiile AI se manifestă pe platforme multiple care domină acum căutarea și descoperirea informațiilor. Google AI Overviews oferă rezumate generate de AI în partea de sus a rezultatelor de căutare, sintetizând informații din surse multiple, dar fără citări pentru fiecare afirmație pentru a permite verificarea de către utilizatori. ChatGPT și ChatGPT Search pot halucina fapte, atribui greșit citate sau oferi informații depășite, mai ales pentru întrebări despre evenimente recente sau subiecte de nișă. Perplexity și alte motoare de căutare AI se confruntă cu provocări similare, cu moduri de eșec specifice precum halucinații amestecate cu fapte reale, atribuiri greșite de afirmații către surse eronate, lipsa contextului critic care schimbă semnificația, iar în categoriile YMYL (Your Money, Your Life), sfaturi posibil nesigure despre sănătate, finanțe sau aspecte legale. Riscul este amplificat deoarece aceste platforme devin tot mai mult interfața principală de căutare—acolo unde utilizatorii caută răspunsuri. Când brandul tău apare în aceste răspunsuri AI cu informații incorecte, ai vizibilitate limitată asupra modului în care a apărut eroarea și control redus asupra corectării rapide.
Halucinațiile AI nu există izolat; ele se propagă prin sisteme interconectate, amplificând dezinformarea la scară largă. Golurile de date—zone ale internetului unde sursele de calitate scăzută domină și informația autoritară este rară—creează condiții pentru ca modelele AI să umple golurile cu fabulații care sună plauzibil. Bias-ul datelor de antrenament înseamnă că, dacă unele narațiuni sunt suprasolicitate în date, modelul va genera acele tipare chiar și când sunt factual incorecte. Actorii rău intenționați exploatează această vulnerabilitate prin atacuri adversariale, creând conținut menit să manipuleze rezultatele AI în favoarea lor. Când boții de știri halucinatori răspândesc falsuri despre brandul, concurenții sau industria ta, aceste afirmații false pot submina eforturile tale de remediere—până să corectezi situația, AI-ul deja s-a antrenat și a propagat dezinformarea. Bias-ul de input creează tipare halucinate atunci când interpretarea întrebării de către model îl determină să genereze informații care se potrivesc așteptărilor părtinitoare, nu realității. Acest mecanism face ca dezinformarea să se răspândească mai rapid prin AI decât prin canale tradiționale, ajungând simultan la milioane de utilizatori cu aceleași afirmații false.
Monitorizarea în timp real pe platformele AI este esențială pentru a detecta halucinațiile înainte să afecteze reputația brandului tău. O monitorizare eficientă presupune urmărire multiplatformă care acoperă simultan Google AI Overviews, ChatGPT, Perplexity, Gemini și motoarele AI emergente. Analiza sentimentului asupra modului în care brandul tău este prezentat în răspunsurile AI oferă semnale timpurii despre amenințări la adresa reputației. Strategiile de detectare trebuie să identifice nu doar halucinațiile, ci și atribuiri greșite, informații depășite și eliminări de context care modifică sensul. Următoarele bune practici stabilesc un cadru complet de monitorizare:
Fără o monitorizare sistematică, zbori practic „în orb”—halucinațiile despre brandul tău se pot răspândi săptămâni întregi până să le descoperi. Costul detectării întârziate se cumulează pe măsură ce tot mai mulți utilizatori întâlnesc informații false.
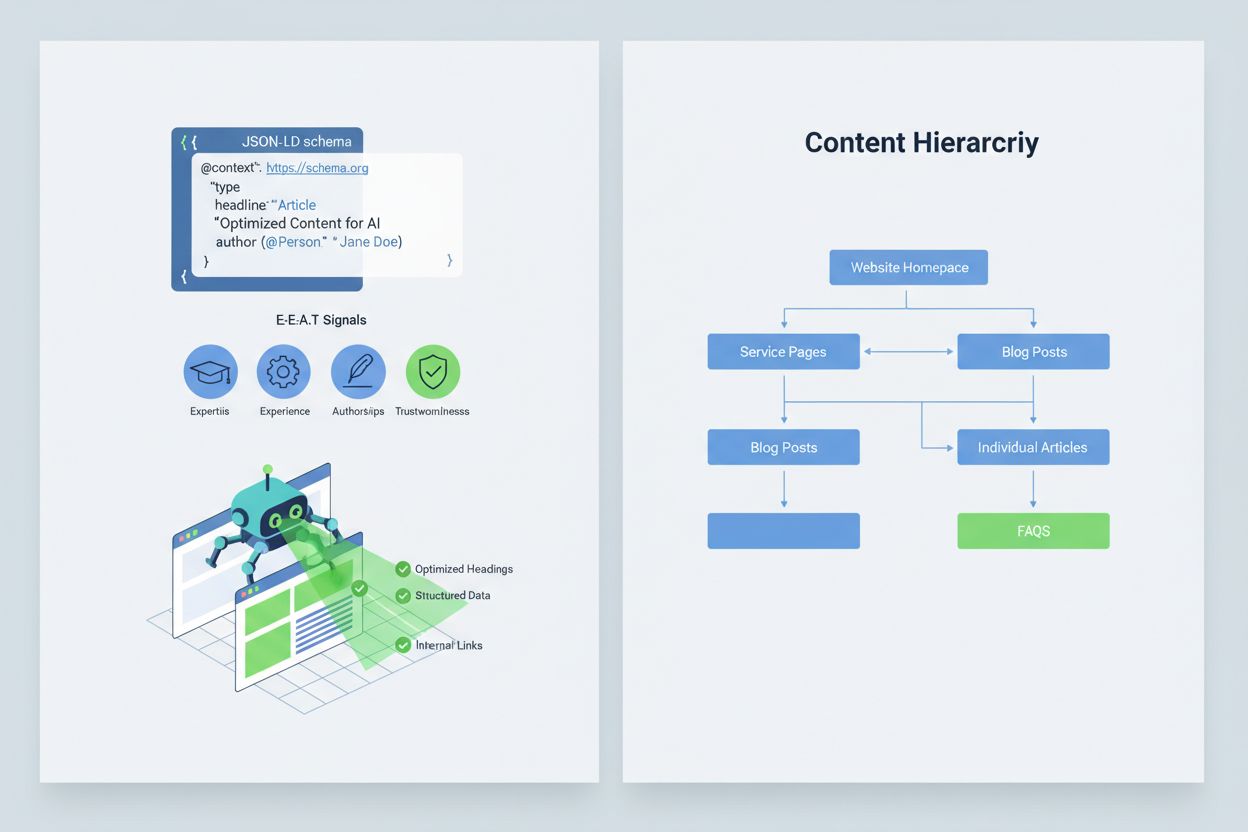
Optimizarea conținutului astfel încât sistemele AI să-l interpreteze și să-l citeze corect presupune implementarea semnalelor E-E-A-T (Expertiză, Experiență, Autor, Încredere) care fac informația ta mai autoritară și demnă de citare. E-E-A-T include autorat de experți cu acreditări clare, surse transparente cu linkuri către cercetări primare, timpi de actualizare care arată prospețimea conținutului și standarde editoriale explicite care dovedesc controlul calității. Implementarea datelor structurate prin schema JSON-LD ajută sistemele AI să înțeleagă contextul și credibilitatea conținutului tău. Anumite tipuri de schema sunt deosebit de valoroase: schema Organization stabilește legitimitatea entității tale, schema Product oferă specificații detaliate care reduc riscul de halucinații, schema FAQPage răspunde întrebărilor frecvente cu răspunsuri autoritare, schema HowTo oferă ghidaj pas cu pas pentru întrebări procedurale, schema Review evidențiază validarea de la terți, iar schema Article semnalizează credibilitate jurnalistică. Implementarea practică include adăugarea de blocuri Q&A care răspund direct intențiilor cu risc ridicat de halucinații, crearea de pagini canonice care consolidează informația și reduc confuzia și dezvoltarea de conținut demn de citare pe care AI-ul să dorească natural să-l folosească. Când conținutul tău este structurat, autoritar și clar sursat, AI-ul va avea mai multe șanse să-l citeze corect și mai puține să inventeze alternative.
Când apare o problemă critică de siguranță a brandului—o halucinație care îți denaturează produsul, atribuie greșit o afirmație unui executiv sau oferă informații periculoase—viteza este avantajul tău competitiv. Un protocol de reacție la incident de 90 de minute poate limita daunele înainte ca acestea să se răspândească larg. Pasul 1: Confirmă și Evaluează (10 minute) presupune verificarea existenței halucinației, documentarea cu capturi de ecran, identificarea platformelor afectate și evaluarea severității. Pasul 2: Stabilizează Canalele Proprii (20 minute) înseamnă publicarea imediată a clarificărilor autoritare pe site, rețele sociale și canale de presă pentru a corecta informația pentru utilizatorii care caută detalii conexe. Pasul 3: Trimite Feedback Platformei (20 minute) presupune raportarea detaliată către fiecare platformă afectată—Google, OpenAI, Perplexity etc.—cu dovezi ale halucinației și cereri de corectare. Pasul 4: Escaladează Extern dacă e Necesat (15 minute) presupune contactarea echipelor de PR sau a consilierilor legali ai platformelor dacă halucinația produce pagube materiale. Pasul 5: Urmărește și Verifică Rezolvarea (25 minute) înseamnă monitorizarea corectării și documentarea cronologiei. Critic, niciuna dintre marile platforme AI nu publică SLA-uri (Service Level Agreements) pentru corecții, deci documentarea e esențială pentru responsabilizare. Viteza și rigurozitatea acestui proces pot reduce daunele de reputație cu 70-80% față de reacțiile întârziate.
Platformele specializate emergente oferă acum monitorizare dedicată pentru răspunsuri generate de AI, transformând siguranța brandului din verificare manuală în inteligență automată. AmICited.com se remarcă drept soluția principală pentru monitorizarea răspunsurilor AI pe toate platformele majore—urmărește cum apar brandul, produsele și directorii tăi în Google AI Overviews, ChatGPT, Perplexity și alte motoare de căutare AI, cu alerte în timp real și urmărire istorică. Profound monitorizează mențiunile brandului pe motoarele AI cu analiză de sentiment ce distinge între prezentări pozitive, neutre și negative, ajutându-te să înțelegi nu doar ce se spune, ci și cum este formulat. Bluefish AI este specializat în urmărirea aparițiilor pe Gemini, Perplexity și ChatGPT, oferind vizibilitate asupra platformelor cu cel mai mare risc. Athena oferă un model de căutare AI cu metrici de dashboard care te ajută să înțelegi vizibilitatea și performanța ta în răspunsurile AI. Geneo oferă vizibilitate multiplatformă cu analiză de sentiment și urmărire istorică pentru a evidenția trenduri în timp. Aceste instrumente detectează răspunsurile dăunătoare înainte să se răspândească pe scară largă, oferă sugestii de optimizare a conținutului bazate pe ce funcționează în răspunsurile AI și permit management multi-brand pentru companiile care monitorizează zeci de branduri simultan. ROI-ul este substanțial: detectarea timpurie a unei halucinații poate preveni ca mii de utilizatori să întâlnească informații false despre brandul tău.
Gestionarea accesului sistemelor AI la conținutul tău oferă un nivel suplimentar de control asupra siguranței brandului. GPTBot de la OpenAI respectă directivele robots.txt, permițându-ți să-l blochezi de la indexarea conținutului sensibil, menținând totuși prezența în datele de antrenament ale ChatGPT. PerplexityBot respectă la rândul său robots.txt, deși persistă îngrijorări privind roboții nedeclarați care nu se identifică corect. Google și Google-Extended urmează regulile robots.txt standard, oferindu-ți control granular asupra conținutului care ajunge la sistemele AI Google. Compromisul este real: blocarea roboților reduce prezența ta în răspunsurile generate de AI, ceea ce poate diminua vizibilitatea, dar protejează conținutul sensibil de a fi folosit greșit sau halucinat. AI Crawl Control de la Cloudflare oferă opțiuni mai sofisticate pentru control granular, permițându-ți să permiți accesul doar la secțiuni valoroase ale site-ului și să protejezi conținutul frecvent interpretat greșit. O strategie echilibrată presupune de obicei permiterea accesului roboților la paginile principale de produse și conținutul autoritar, blocând documentația internă, datele clienților sau conținutul predispus la interpretări greșite. Această abordare menține vizibilitatea în răspunsurile AI, reducând totodată suprafața pentru halucinații care pot afecta brandul.
Stabilirea unor KPIs clari pentru programul de siguranță a brandului îl transformă dintr-un centru de cost într-o funcție de business măsurabilă. Metricile MTTD/MTTR (Mean Time To Detect și Mean Time To Resolve) pentru răspunsuri dăunătoare, segmentate pe nivel de severitate, arată dacă procesele de monitorizare și răspuns se îmbunătățesc. Acuratețea și distribuția sentimentului în răspunsurile AI relevă dacă brandul tău este prezentat pozitiv, neutru sau negativ pe platforme. Procentul citărilor autoritare măsoară ce procent din răspunsurile AI citează conținutul tău oficial față de concurență sau surse nesigure—procentaje mai mari indică o consolidare de succes a conținutului. Cota de vizibilitate în AI Overviews și rezultate Perplexity urmărește dacă brandul tău rămâne prezent în aceste interfețe AI cu trafic ridicat. Eficiența escaladării măsoară procentul problemelor critice rezolvate în intervalul țintă SLA, demonstrând maturitatea operațională. Studiile arată că programele de siguranță a brandului cu controale proactive și monitorizare reduc încălcările la rate de o singură cifră, față de rate de 20-30% pentru abordări reactive. Prevalența AI Overviews a crescut semnificativ în 2025, făcând strategiile proactive de includere esențiale—brandurile care se optimizează pentru răspunsuri AI acum obțin avantaj competitiv față de cele care așteaptă maturizarea tehnologiei. Principiul fundamental este clar: prevenția bate reacția, iar ROI-ul monitorizării proactive a siguranței brandului se amplifică în timp pe măsură ce construiești autoritate, reduci halucinațiile și menții încrederea clienților.
O halucinație AI apare atunci când un model lingvistic mare generează informații care sună plauzibil, dar care sunt complet fabricate, cu o încredere totală. Aceste rezultate false apar deoarece LLM-urile prezic secvențe de cuvinte probabiliste pe baza tiparelor din datele de antrenament, nu pentru că înțeleg cu adevărat faptele. Halucinațiile rezultă din supraînvățare, bias de date de antrenament și din complexitatea inerentă a rețelelor neuronale, care face ca procesele lor decizionale să fie opace.
Halucinațiile AI pot deteriora grav brandul tău prin mai multe canale: cauzează pierderi de trafic (60% din căutări nu duc la click atunci când apar rezumate AI), erodează încrederea clienților când afirmații false sunt atribuite brandului tău, creează crize de PR când concurenții exploatează halucinațiile și reduc vizibilitatea ta în răspunsurile generate de AI. Companiile au raportat pierderi de trafic de până la 10% atunci când sistemele AI le prezintă în mod eronat produsele sau serviciile.
Google AI Overviews, ChatGPT, Perplexity și Gemini sunt principalele platforme unde apar riscuri pentru siguranța brandului. Google AI Overviews apar în topul rezultatelor de căutare fără citări pentru fiecare afirmație în parte. ChatGPT și Perplexity pot halucina fapte și pot atribui greșit informații. Fiecare platformă are practici diferite de citare și timpi de corectare, necesitând strategii de monitorizare multiplatformă.
Monitorizarea în timp real pe platforme AI este esențială. Urmărește interogările prioritare (nume brand, nume produse, nume directori, subiecte de siguranță), stabilește praguri de alertă și linii de bază pentru sentiment, și corelează schimbările cu actualizările tale de conținut. Instrumente specializate precum AmICited.com oferă detectare automată pe toate marile platforme AI, cu urmărire istorică și analiză de sentiment.
Urmează un protocol de reacție la incident de 90 de minute: 1) Confirmă și stabilește amploarea problemei (10 min), 2) Publică clarificări autorizate pe site-ul tău (20 min), 3) Trimite feedback cu dovezi platformei (20 min), 4) Escaladează extern dacă este necesar (15 min), 5) Urmărește rezolvarea (25 min). Viteza este critică—un răspuns rapid poate reduce daunele reputaționale cu 70-80% față de răspunsurile întârziate.
Implementează semnale E-E-A-T (Expertiză, Experiență, Autor, Încredere) cu acreditări de experți, surse transparente, timpi de actualizare vizibili și standarde editoriale. Folosește date structurate JSON-LD cu tipuri de schemă Organization, Product, FAQPage, HowTo, Review și Article. Adaugă blocuri Q&A pentru intenții cu risc ridicat, creează pagini canonice care consolidează informațiile și dezvoltă conținut demn de citare pe care sistemele AI să-l prefere natural.
Blocarea roboților reduce prezența ta în răspunsurile generate de AI, dar protejează conținutul sensibil. O strategie echilibrată permite roboților acces la paginile principale de produse și conținutul autoritar, blocând documentația internă și conținutul frecvent folosit greșit. GPTBot de la OpenAI și PerplexityBot respectă directivele robots.txt, oferindu-ți control granular asupra conținutului care ajunge la sistemele AI.
Urmărește MTTD/MTTR (Mean Time To Detect/Resolve) pentru răspunsuri dăunătoare pe severitate, acuratețea sentimentului în răspunsurile AI, procentul de citări autoritare față de concurență, vizibilitatea în AI Overviews și rezultate Perplexity și eficiența escaladării (procent rezolvat în SLA). Aceste metrici arată dacă procesele de monitorizare și răspuns se îmbunătățesc și justifică ROI-ul investițiilor în siguranța brandului.
Protejează-ți reputația brandului cu monitorizare în timp real pe Google AI Overviews, ChatGPT și Perplexity. Detectează halucinațiile înainte să-ți afecteze reputația.
Află ce este halucinația AI, de ce apare în ChatGPT, Claude și Perplexity și cum poți detecta informațiile false generate de AI în rezultatele căutării....

Află ce este monitorizarea halucinațiilor AI, de ce este esențială pentru siguranța brandului și cum metodele de detectare precum RAG, SelfCheckGPT și LLM-as-Ju...
Halucinația AI apare atunci când LLM-urile generează informații false sau înșelătoare cu încredere. Află care sunt cauzele halucinațiilor, impactul lor asupra m...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.