Grounding și Căutarea pe Web: Când LLM-urile Accesează Informații Proaspete
Descoperă cum grounding-ul LLM și căutarea pe web permit sistemelor AI să acceseze informații în timp real, să reducă halucinațiile și să ofere citări corecte. Învață despre RAG, strategii de implementare și bune practici enterprise.
Publicat la Jan 3, 2026.Ultima modificare la Jan 3, 2026 la 3:24 am
Modelele lingvistice de mari dimensiuni sunt antrenate pe cantități vaste de date text, însă acest proces de antrenare are o limitare critică: captează doar informația disponibilă până la un anumit moment, cunoscut sub numele de data limită a cunoștințelor (knowledge cutoff). De exemplu, dacă un LLM a fost antrenat cu date până în decembrie 2023, nu are cunoștință despre evenimente, descoperiri sau dezvoltări apărute după acea dată. Când utilizatorii pun întrebări despre evenimente curente, lansări recente de produse sau știri de ultimă oră, modelul nu poate accesa aceste informații din datele sale de antrenament. În loc să admită incertitudinea, LLM-urile generează adesea răspunsuri ce sună plauzibil, dar sunt incorecte factual—un fenomen cunoscut sub numele de halucinație. Această tendință devine deosebit de problematică în aplicațiile unde acuratețea este esențială, precum suportul pentru clienți, consultanța financiară sau informațiile medicale, unde informațiile depășite sau fabricate pot avea consecințe grave.
Înțelegerea Fundamentelor Grounding-ului pentru LLM-uri
Grounding-ul este procesul de a suplimenta cunoștințele pre-antrenate ale unui LLM cu informații externe, contextuale, la momentul inferenței. În loc să se bazeze exclusiv pe tiparele învățate în timpul antrenamentului, grounding-ul conectează modelul la surse de date reale—fie că sunt pagini web, documente interne, baze de date sau API-uri. Acest concept provine din psihologia cognitivă, în special din teoria cogniției situate, care susține că cunoașterea este aplicată cel mai eficient atunci când este ancorată în contextul unde va fi folosită. Practic, grounding-ul transformă problema din “generează un răspuns din memorie” în “sintetizează un răspuns din informațiile oferite”. O definiție strictă din cercetările recente cere ca LLM-ul să folosească toate cunoștințele esențiale din contextul furnizat și să respecte acest cadru fără a halucina informații suplimentare.
Aspect
Răspuns Neancorat
Răspuns Grounded
Sursă de Informații
Doar cunoștințe pre-antrenate
Cunoștințe pre-antrenate + date externe
Acuratețe pentru Evenimente Recente
Scăzută (limite de knowledge cutoff)
Ridicată (acces la informații curente)
Risc de Halucinație
Ridicat (modelul “ghicește”)
Scăzut (constrâns de contextul oferit)
Capacitate de Citare
Limitată sau imposibilă
Trasabilitate completă a surselor
Scalabilitate
Fixă (dimensiunea modelului)
Flexibilă (se pot adăuga surse noi)
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
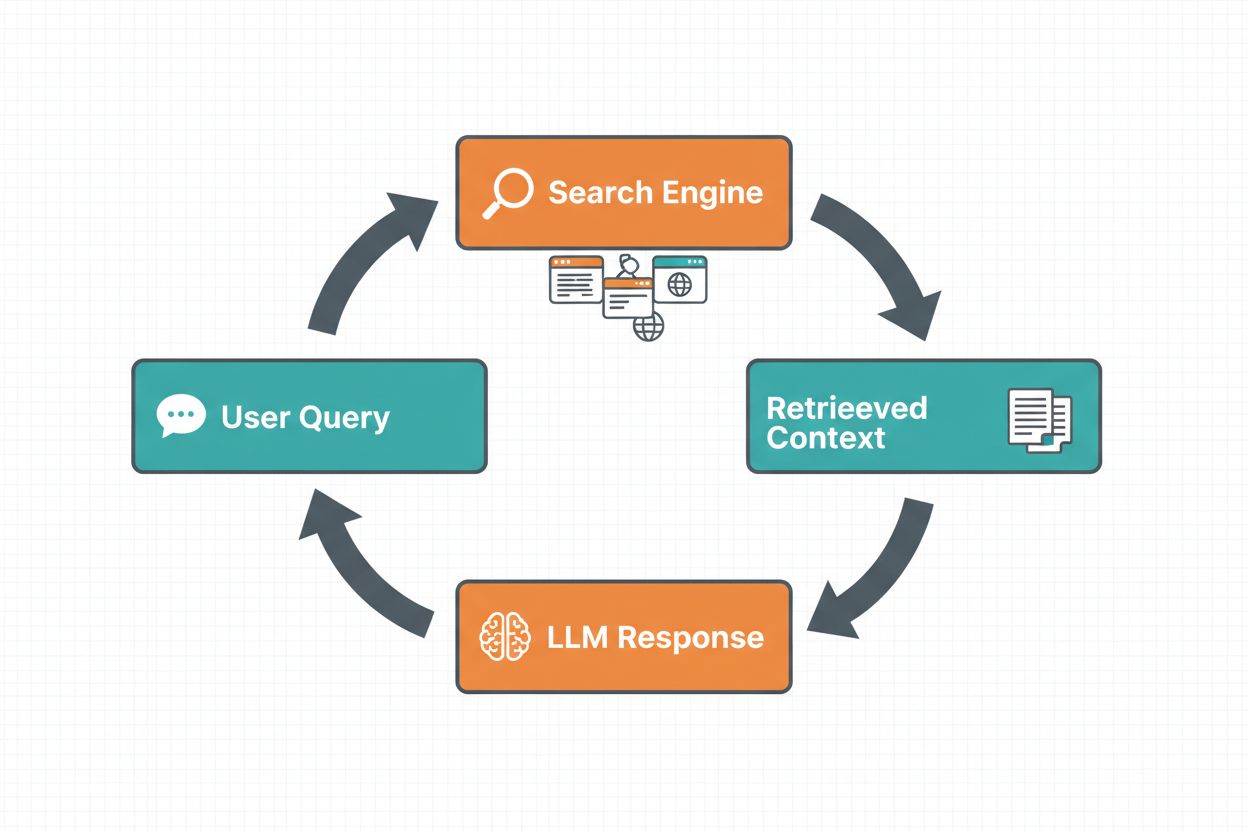
Grounding-ul prin căutare web permite LLM-urilor să acceseze informații în timp real prin căutarea automată pe web și încorporarea rezultatelor în procesul de generare a răspunsului. Fluxul de lucru urmează o secvență structurată: mai întâi, sistemul analizează promptul utilizatorului pentru a determina dacă o căutare pe web ar îmbunătăți răspunsul; apoi, generează una sau mai multe interogări optimizate pentru recuperarea informațiilor relevante; în continuare, execută aceste interogări pe un motor de căutare (precum Google Search sau DuckDuckGo); după aceea, procesează rezultatele căutării și extrage conținutul relevant; în final, oferă acest context LLM-ului ca parte a promptului, permițând modelului să genereze un răspuns grounded. Sistemul returnează și metadate de grounding—informații structurate despre ce interogări au fost executate, ce surse au fost recuperate și cum anumite părți ale răspunsului sunt susținute de aceste surse. Aceste metadate sunt esențiale pentru construirea încrederii și permit utilizatorilor să verifice afirmațiile.
Fluxul Grounding-ului prin Căutare Web:
Analiza Promptului: Modelul determină dacă este necesară căutarea web
Generarea Interogării: Creează interogări de căutare optimizate din inputul utilizatorului
Executarea Căutării Web: Recuperează rezultate de la motoarele de căutare
Procesarea Rezultatelor: Extrage și clasează informațiile relevante
Injectarea Contextului: Adaugă rezultatele căutării în promptul LLM-ului
Răspuns Grounded: Modelul generează răspuns cu citări
Returnarea Metadatelor: Oferă surse și dovezi de susținere
Retrieval Augmented Generation (RAG) a devenit tehnica dominantă de grounding, combinând decenii de cercetare în recuperarea informației cu capacitățile moderne ale LLM-urilor. RAG funcționează prin recuperarea mai întâi a documentelor sau pasajelor relevante dintr-o sursă externă de cunoștințe (de obicei indexată într-o bază de date vectorială), apoi oferind aceste elemente recuperate ca context pentru LLM. Procesul de recuperare are de obicei două etape: un retriever folosește algoritmi eficienți (precum BM25 sau căutare semantică cu embeddings) pentru a identifica documentele candidate, iar un ranker utilizează modele neuronale mai sofisticate pentru a re-clasa aceste candidate după relevanță. Contextul recuperat este apoi încorporat în prompt, permițând LLM-ului să sintetizeze răspunsuri ancorate în informații autoritare. RAG oferă avantaje semnificative față de fine-tuning: este mai eficient din punct de vedere al costurilor (nu este nevoie de reantrenarea modelului), mai scalabil (se pot adăuga ușor noi documente în baza de cunoștințe) și mai ușor de întreținut (actualizarea informațiilor fără reantrenare). De exemplu, un prompt RAG ar putea arăta astfel:
Folosește următoarele documente pentru a răspunde la întrebare.
[Întrebare]
Care este capitala Canadei?
[Document 1]
Ottawa este capitala Canadei, situată în Ontario...
[Document 2]
Canada este o țară din America de Nord cu zece provincii...
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Acces la Informații în Timp Real și Citări
Unul dintre cele mai convingătoare avantaje ale grounding-ului prin căutare web este capacitatea de a accesa și încorpora informații în timp real în răspunsurile LLM-ului. Acest lucru este deosebit de valoros pentru aplicațiile care necesită date actuale—analiza știrilor, cercetare de piață, informații despre evenimente sau disponibilitatea produselor. Dincolo de simplul acces la informații noi, grounding-ul oferă citări și atribuirea sursei, esențiale pentru construirea încrederii și permiterea verificării. Când un LLM generează un răspuns grounded, returnează metadate structurate care asociază afirmațiile specifice cu documentele sursă, permițând citări inline precum “[1] source.com” direct în textul răspunsului. Această capacitate este direct aliniată cu misiunea platformelor precum AmICited.com, care monitorizează modul în care sistemele AI fac referire și citează sursele pe diferite platforme. Capacitatea de a urmări ce surse a consultat un sistem AI și cum a atribuit informația devine din ce în ce mai importantă pentru monitorizarea brandului, atribuirea conținutului și asigurarea unui AI responsabil.
Reducerea Halucinațiilor prin Grounding
Halucinațiile apar deoarece LLM-urile sunt fundamental concepute să prezică următorul token pe baza tokenilor anteriori și a tiparelor învățate, fără o înțelegere inerentă a limitelor cunoștințelor lor. Când se confruntă cu întrebări dincolo de datele de antrenament, continuă să genereze text ce sună plauzibil în loc să admită incertitudinea. Grounding-ul abordează această problemă schimbând fundamental sarcina modelului: în loc să genereze din memorie, modelul sintetizează din informațiile furnizate. Din perspectivă tehnică, când contextul extern relevant este inclus în prompt, acesta modifică distribuția de probabilitate a tokenilor spre răspunsuri ancorate în acel context, reducând probabilitatea halucinațiilor. Cercetările demonstrează că grounding-ul poate reduce rata halucinațiilor cu 30-50% în funcție de task și implementare. De exemplu, la întrebarea “Cine a câștigat Euro 2024?” fără grounding, un model mai vechi ar putea oferi un răspuns incorect; cu grounding folosind rezultate din căutarea web, identifică corect Spania ca învingătoare cu detalii specifice despre meci. Acest mecanism funcționează deoarece mecanismele de atenție ale modelului se pot concentra acum pe contextul furnizat, în loc să se bazeze pe tipare potențial incomplete sau conflictuale din datele de antrenament.
Implementarea Grounding-ului Web – Abordări Practice
Implementarea grounding-ului prin căutare web presupune integrarea mai multor componente: un API de căutare (precum Google Search, DuckDuckGo prin Serp API sau Bing Search), logică pentru a determina când grounding-ul este necesar și prompt engineering pentru a încorpora eficient rezultatele căutării. O implementare practică începe de obicei prin evaluarea dacă întrebarea utilizatorului necesită informații actuale—acest lucru poate fi realizat chiar întrebând LLM-ul dacă promptul cere informații mai recente decât knowledge cutoff-ul său. Dacă este nevoie de grounding, sistemul execută o căutare web, procesează rezultatele pentru a extrage fragmente relevante și construiește un prompt care include atât întrebarea originală, cât și contextul rezultat din căutare. Considerațiile de cost sunt importante: fiecare căutare web implică costuri de API, așa că implementarea unui grounding dinamic (căutare doar când este necesar) poate reduce semnificativ cheltuielile. De exemplu, o întrebare de tipul “De ce este cerul albastru?” probabil nu necesită o căutare web, în timp ce “Cine este președintele actual?” cu siguranță da. Implementările avansate utilizează modele mai mici și mai rapide pentru decizia de grounding, reducând latența și costurile, rezervând modelele mari pentru generarea finală a răspunsurilor.
Provocări și Strategii de Optimizare
Deși grounding-ul este puternic, introduce mai multe provocări ce trebuie gestionate cu atenție. Relevanța datelor este esențială—dacă informațiile recuperate nu răspund de fapt întrebării utilizatorului, grounding-ul nu va ajuta și poate chiar introduce context irelevant. Cantitatea de date prezintă un paradox: deși mai multe informații par utile, cercetările arată că performanța LLM scade adesea cu input excesiv, un fenomen numit “pierdut în mijloc”, unde modelele au dificultăți în a găsi și folosi informațiile plasate în mijlocul contextelor lungi. Eficiența tokenilor devine o preocupare, deoarece fiecare fragment de context recuperat consumă tokeni, crescând latența și costul. Principiul “mai puțin înseamnă mai mult” se aplică: recuperează doar cele mai relevante k rezultate (de obicei 3-5), lucrează cu fragmente textuale mai mici în loc de documente întregi și extrage sentințele cheie din pasaje mai lungi.
Provocare
Impact
Soluție
Relevanța Datelor
Context irelevant care derutează modelul
Folosește căutare semantică + rankere; testează calitatea recuperării
Biasul Pierdut în Mijloc
Modelul ratează informații importante din mijloc
Minimizează dimensiunea inputului; plasează info critică la început/sfârșit
Eficiența Tokenilor
Latență și cost ridicat
Recuperează mai puține rezultate; folosește fragmente mai mici
Informații Învătrânite
Context depășit în baza de cunoștințe
Implementează politici de reîmprospătare; controlul versiunilor
Latență
Răspunsuri lente din cauza căutării + inferenței
Folosește operațiuni asincrone; cache pentru interogări frecvente
Grounding-ul în Producție – Considerații pentru Enterprise
Implementarea sistemelor de grounding în medii de producție necesită atenție la guvernanță, securitate și aspecte operaționale. Asigurarea calității datelor este fundamentală—informația pe care o folosești pentru grounding trebuie să fie corectă, actuală și relevantă pentru cazurile tale de utilizare. Controlul accesului devine critic atunci când grounding-ul se face pe documente proprietare sau sensibile; trebuie să te asiguri că LLM-ul accesează doar informații potrivite fiecărui utilizator, conform permisiunilor sale. Gestionarea actualizărilor și driftului presupune stabilirea unor politici pentru cât de des sunt reîmprospătate bazele de cunoștințe și cum sunt abordate conflictele între surse. Audit logging este esențial pentru conformitate și depanare—trebuie să captezi ce documente au fost recuperate, cum au fost clasate și ce context a fost oferit modelului. Alte considerații includ:
Implementarea buclelor de feedback de la utilizatori pentru a identifica și corecta erorile de grounding
Monitorizarea consumului de tokeni pentru optimizarea costurilor
Stabilirea controlului versiunilor la actualizarea bazelor de cunoștințe
Asigurarea conformității cu reglementările privind protecția datelor (GDPR, HIPAA, etc.)
Urmărirea comportamentului modelului pentru a detecta driftul sau degradarea în timp
Viitorul Grounding-ului și Tendințe Emergente
Domeniul grounding-ului pentru LLM evoluează rapid, dincolo de simpla recuperare de text. Apare grounding-ul multimodal, unde sistemele pot ancora răspunsurile în imagini, videoclipuri și date structurate alături de text—deosebit de important pentru domenii precum analiza documentelor juridice, imagistica medicală sau documentația tehnică. Raționamentul automatizat este suprapus peste RAG, permițând agenților nu doar să recupereze informații, ci și să sintetizeze din surse multiple, să tragă concluzii logice și să explice raționamentul. Guardrails sunt integrate cu grounding-ul pentru a asigura că, chiar și cu acces la informații externe, modelele respectă constrângerile de siguranță și politicile de conformitate. Actualizările modelului in-place reprezintă o altă frontieră—în loc să se bazeze exclusiv pe recuperarea externă, cercetătorii explorează modalități de a actualiza direct greutățile modelului cu informații noi, reducând potențial nevoia unor baze de cunoștințe externe extinse. Aceste progrese sugerează că viitoarele sisteme de grounding vor fi mai inteligente, mai eficiente și mai capabile să gestioneze taskuri complexe de raționament multi-pas, menținând totodată acuratețea factuală și trasabilitatea.
Întrebări frecvente
Care este diferența dintre grounding și fine-tuning?
Grounding-ul suplimentează un LLM cu informații externe la momentul inferenței fără a modifica modelul în sine, în timp ce fine-tuning-ul reantrenează modelul pe date noi. Grounding-ul este mai eficient din punct de vedere al costurilor, mai rapid de implementat și mai ușor de actualizat cu informații noi. Fine-tuning-ul este mai potrivit atunci când trebuie să schimbi fundamental comportamentul modelului sau când ai tipare specifice domeniului de învățat.
Cum reduce grounding-ul halucinațiile?
Grounding-ul reduce halucinațiile oferind LLM-ului un context factual din care să extragă răspunsuri, în loc să se bazeze doar pe datele de antrenament. Când informații externe relevante sunt incluse în prompt, distribuția de probabilitate a tokenilor modelului se orientează către răspunsuri ancorate în acel context, făcând mai puțin probabilă generarea de informații fabricate. Cercetările arată că grounding-ul poate reduce rata halucinațiilor cu 30-50%.
Ce este RAG și de ce este important?
Retrieval Augmented Generation (RAG) este o tehnică de grounding care recuperează documente relevante dintr-o sursă externă de cunoștințe și le oferă ca context LLM-ului. RAG este important pentru că este scalabil, eficient din punct de vedere al costurilor și îți permite să actualizezi informațiile fără să reantrenezi modelul. A devenit standardul în industrie pentru construirea aplicațiilor AI cu grounding.
Când ar trebui să implementez grounding-ul prin căutare web?
Implementează grounding-ul prin căutare web atunci când aplicația ta are nevoie de acces la informații actuale (știri, evenimente, date recente), când acuratețea și citările sunt critice sau când limita de cunoștințe a LLM-ului reprezintă o problemă. Folosește grounding dinamic pentru a căuta doar atunci când este necesar, reducând costurile și latența pentru întrebările care nu necesită informații proaspete.
Care sunt principalele provocări în implementarea grounding-ului?
Provocările cheie includ asigurarea relevanței datelor (informațiile recuperate trebuie să răspundă întrebării), gestionarea cantității de date (mai mult nu înseamnă întotdeauna mai bine), abordarea biasului 'pierdut în mijloc', unde modelele omit informații din contexte lungi, și optimizarea eficienței tokenilor. Soluțiile includ utilizarea căutării semantice cu rankere, recuperarea unui număr redus de rezultate dar de calitate superioară și plasarea informațiilor critice la începutul sau sfârșitul contextului.
Cum se leagă grounding-ul de monitorizarea răspunsurilor AI?
Grounding-ul este direct relevant pentru monitorizarea răspunsurilor AI deoarece permite sistemelor să ofere citări și atribuirea sursei. Platforme precum AmICited urmăresc cum sistemele AI fac referire la surse, lucru posibil doar când grounding-ul este implementat corect. Acest lucru ajută la asigurarea unei implementări AI responsabile și a atribuirii brandului pe diverse platforme AI.
Ce este biasul 'pierdut în mijloc'?
Biasul 'pierdut în mijloc' este un fenomen în care LLM-urile performează mai slab când informațiile relevante sunt plasate în mijlocul unor contexte lungi, comparativ cu informațiile aflate la început sau sfârșit. Acest lucru se întâmplă deoarece modelele tind să 'răsfoiască' când procesează cantități mari de text. Soluțiile includ minimizarea dimensiunii inputului, plasarea informațiilor critice în locații preferate și utilizarea de fragmente de text mai mici.
Cum pot optimiza grounding-ul pentru implementarea în producție?
Pentru implementarea în producție, concentrează-te pe asigurarea calității datelor, implementează controale de acces pentru informații sensibile, stabilește politici de actualizare și reîmprospătare, activează audit logging pentru conformitate și creează bucle de feedback pentru utilizatori pentru a identifica eșecurile. Monitorizează consumul de tokeni pentru optimizarea costurilor, implementează controlul versiunilor pentru bazele de cunoștințe și urmărește comportamentul modelului pentru detectarea driftului.
Monitorizează Cum Sistemele AI Fac Referire la Brandul Tău
AmICited urmărește cum GPT-urile, Perplexity și Google AI Overviews citează și fac referire la conținutul tău. Obține informații în timp real despre monitorizarea răspunsurilor AI și atribuirea brandului.
Cum decid LLM-urile ce să citeze: Înțelegerea selecției surselor de către AI
Descoperă cum Modelele Lingvistice Mari selectează și citează sursele prin ponderarea dovezilor, recunoașterea entităților și date structurate. Află procesul de...
Descoperă cum transformă Retrieval-Augmented Generation citările AI, permițând atribuirea exactă a surselor și răspunsuri fundamentate în ChatGPT, Perplexity și...
Definiție cuprinzătoare a modelelor lingvistice mari (LLM): sisteme AI antrenate pe miliarde de parametri pentru a înțelege și genera limbaj. Află cum funcțione...
14 min citire
Consimțământ Cookie Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.