
URL-uri canonice și AI: Prevenirea problemelor de conținut duplicat
Află cum previn URL-urile canonice problemele de conținut duplicat în sistemele de căutare AI. Descoperă cele mai bune practici pentru implementarea canonicalel...
7 min citire

Află cum republicarea conținutului creează probleme de conținut duplicat care afectează vizibilitatea în căutarea AI mai sever decât în căutarea tradițională. Descoperă măsuri tehnice de protecție și cele mai bune practici.
Republicarea conținutului pe mai multe canale, platforme și formate este o strategie legitimă și adesea necesară pentru maximizarea acoperirii și implicării. Totuși, această practică creează o tensiune fundamentală cu modul în care sistemele de căutare—în special cele bazate pe AI—procesează și clasifică conținutul. Problema nu este dacă poți republica, ci dacă o faci într-un mod care nu îți sabotează vizibilitatea în rezultatele căutării AI. Spre deosebire de motoarele de căutare tradiționale care au dezvoltat mecanisme sofisticate pentru detectarea duplicatelor de-a lungul decadelor, sistemele AI abordează conținutul duplicat diferit, generând riscuri noi la care mulți publisheri nu s-au adaptat încă.
Conform documentației tehnice Microsoft despre Copilot și căutarea AI, „LLM-urile grupează URL-urile aproape identice într-un singur cluster și aleg o pagină pentru a reprezenta setul.” Acest comportament de clusterizare este fundamental diferit de modul în care algoritmul PageRank de la Google distribuie autoritatea între paginile duplicat. În loc să consolideze semnale, sistemele AI iau o decizie binară: selectează o pagină reprezentativă dintr-un cluster de conținut similar și ignoră în mare parte celelalte. Acest proces de selecție nu este întotdeauna previzibil sau bazat pe versiunea pe care ai prefera-o la clasare. Algoritmul ia în considerare factori precum actualitatea, calitatea conținutului, semnalele tehnice și autoritatea domeniului—însă ponderea acestor factori rămâne opacă. Ce face ca această situație să fie deosebit de problematică este faptul că sistemele AI pot selecta o versiune învechită dacă diferențele dintre pagini sunt suficient de minime încât algoritmul de clusterizare să nu detecteze variații semnificative.
| Aspect | Căutare tradițională | Căutare AI |
|---|---|---|
| Gestionarea duplicatelor | Consolidează semnalele de autoritate | Clusterizează și selectează un singur reprezentant |
| Risc de penalizare | Posibilă acțiune manuală | Fără penalizare, dar diluarea vizibilității |
| Recunoașterea actualizărilor | Propagare treptată a semnalelor | Poate rata actualizările dacă diferențele sunt minime |
| Eficiența crawlării | Irosește bugetul pe duplicate | Reduce prioritatea crawlării pentru duplicate |
| Respectarea canonicului | Respectat dar nu garantat | Esențial pentru selecția clusterului |
Republicarea fără măsuri de protecție adecvate introduce trei riscuri interconectate care afectează direct vizibilitatea în AI:
Diluarea semnalului de intenție: Când același conținut apare pe mai multe URL-uri, sistemul AI primește semnale contradictorii despre ce versiune răspunde cel mai bine la întrebarea utilizatorului. În loc să concentrezi autoritatea pe un singur URL, semnalele tale se dispersează în cluster. Această diluare reduce scorul de încredere pe care sistemele AI îl atribuie conținutului tău atunci când decid dacă să îl includă în răspunsuri. Un conținut care ar fi putut fi sursă principală devine o opțiune secundară deoarece sistemul nu poate determina cu certitudine care versiune este autoritară.
Risc de reprezentare: Selecția sistemului AI cu privire la ce pagină reprezintă clusterul tău de conținut poate să nu fie în acord cu obiectivele tale de business. Poți republica un articol pe o rețea de sindicare așteptând ca acea versiune să aducă trafic, doar pentru ca sistemul AI să selecteze versiunea de pe domeniul tău original—sau, și mai rău, să aleagă versiunea sindicată care nu trimite trafic înapoi către site-ul tău. Această nepotrivire face ca strategia ta de republicare să lucreze împotriva obiectivelor de vizibilitate, nu să le amplifice.
Întârziere la actualizare și învechire: Când îți actualizezi conținutul original dar versiunile republicate rămân neschimbate, sistemele AI pot selecta o versiune învechită ca pagină reprezentativă. Algoritmul de clusterizare nu recunoaște întotdeauna că o versiune este mai nouă sau mai exactă decât celelalte, mai ales dacă modificările sunt incrementale și nu structurale. Astfel, conținutul tău cel mai actual și precis poate deveni invizibil, în timp ce o versiune mai veche îți reprezintă expertiza în fața AI-ului.
Cea mai frecventă greșeală la republicare apare când conținutul este sindicat pe platforme terțe fără implementarea tag-urilor canonice. Să luăm un scenariu tipic: o companie de software B2B publică un ghid amplu pe blogul propriu, apoi îl sindicată către publicații de industrie precum Medium, LinkedIn și agregatoare specializate. Fiecare platformă găzduiește același conținut sub URL-uri diferite. Fără tag-uri canonice care să indice sursa originală, algoritmul de clusterizare al AI tratează toate versiunile ca fiind la fel de autoritare. Platforma de sindicare poate avea autoritate de domeniu mai mare, determinând astfel AI-ul să selecteze acea versiune ca pagină reprezentativă. Acum, conținutul tău original—versiunea pe care ai optimizat-o, actualizat-o și ai construit backlink-uri—devine invizibilă în rezultatele căutării AI. Traficul și autoritatea se duc către platforma de sindicare, nu către proprietatea ta. Acest scenariu se repetă de mii de ori zilnic în industrie, editorii sabotându-și involuntar vizibilitatea doar pentru că nu implementează un simplu tag HTML.
Conținutul specific campaniilor creează o problemă de conținut duplicat deosebit de insidioasă atunci când este republicat pe diverse canale. O echipă de marketing lansează o pagină de destinație optimizată pentru o promoție anume, apoi republică variații ale conținutului în newslettere de email, social media, reclame plătite și site-uri partenere. Fiecare versiune conține mici diferențe de text, CTA-uri sau formatare—dar conținutul de bază și intenția rămân identice. Sistemele AI recunosc aceste versiuni ca duplicate și le grupează împreună. Problema se agravează când paginile de campanie sunt republicate fără implementarea corectă a canonicului. Sistemul AI poate selecta versiunea din newsletter (fără tracking de conversii) ca pagină reprezentativă, sau versiunea de pe site-ul partener care nu aduce beneficii pentru metricile tale. În plus, când campaniile se încheie și paginile sunt arhivate sau șterse, AI-ul poate fi deja setat să selecteze o versiune care nu mai există, făcând ca utilizatorii să nu mai găsească conținutul sau să ajungă pe pagini nefuncționale.
Republicarea regională adaugă complexitate pentru că detectarea conținutului duplicat trebuie să țină cont de nevoile legitime de localizare. O companie cu operațiuni în mai multe țări poate publica același conținut de bază în limbi diferite sau cu variații regionale. Fără implementare corectă, aceste versiuni regionale concurează între ele în clusterizarea AI. Să luăm o companie SaaS care publică un ghid de funcționalități în engleză pe domeniul din SUA, apoi îl republică pe domeniul din UK cu ortografie britanică și prețuri regionale. Sistemul AI le grupează ca duplicate, putând selecta versiunea din SUA chiar și pentru utilizatorii din UK. Soluția presupune implementarea tag-urilor hreflang care semnalizează relațiile regionale către AI, deși eficiența hreflang în căutarea AI rămâne mai puțin dovedită decât în căutarea tradițională.
<!-- Pe versiunea SUA (example.com/feature-guide) -->
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
<!-- Pe versiunea UK (example.co.uk/feature-guide) -->
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
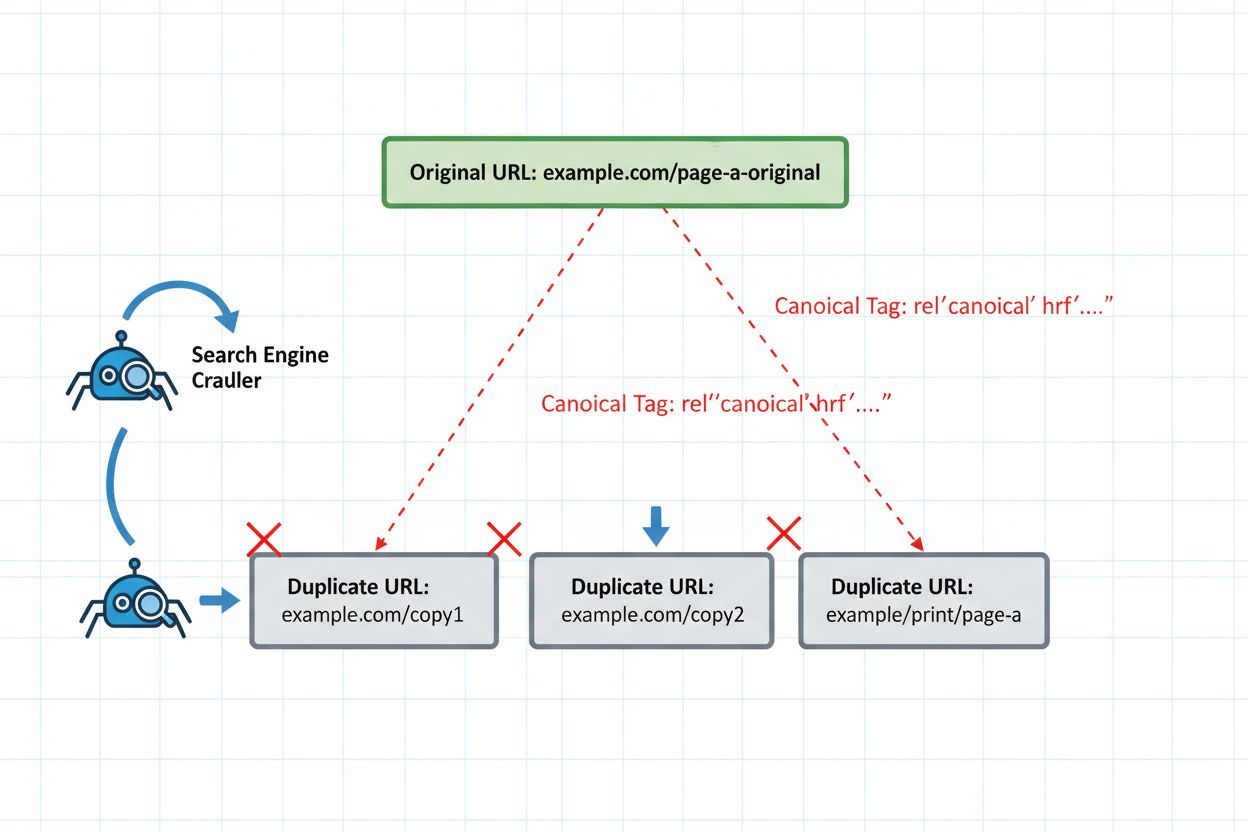
Implementarea corectă a măsurilor tehnice de protecție este obligatorie pentru republicarea sigură. Tag-ul canonic rămâne apărarea principală, indicând explicit sistemelor AI ce versiune ar trebui să reprezinte clusterul tău de conținut. Plasează tag-ul canonic în secțiunea <head> a fiecărei versiuni republicate, indicând spre versiunea ta preferată și autoritară. Pentru conținutul sindicat, aceasta înseamnă de obicei indicarea domeniului tău original.
<!-- Pe versiunea sindicată (medium.com/publicația-ta/articol) -->
<link rel="canonical" href="https://yoursite.com/blog/article" />
Pentru conținutul care nu trebuie să concureze niciodată cu alte versiuni, implementează noindex pe versiunile secundare. Acest lucru le elimină complet din indexarea AI, asigurând că nu pot fi selectate ca pagini reprezentative. Folosește această metodă pentru pagini interne duplicate, versiuni de test sau conținut sindicat unde nu dorești vizibilitate AI.
<!-- Pe versiunea secundară care nu trebuie indexată -->
<meta name="robots" content="noindex, follow" />
Redirect-urile 301 oferă cel mai puternic semnal pentru consolidarea autorității, dar folosește-le doar când versiunea secundară nu va mai fi actualizată independent. Redirect-urile spun sistemelor AI că vechiul URL a fost mutat permanent, consolidând toate semnalele pe noua locație. Totuși, dacă ai nevoie ca ambele versiuni să rămână active (ca în cazul sindicării), redirect-urile creează probleme pentru că dezactivează structura URL a platformei de sindicare.
# În .htaccess sau configurația serverului
Redirect 301 /old-article https://yoursite.com/new-article
Pentru sistemele de gestionare a conținutului, implementează rel=“canonical” dinamic pentru a gestiona paginarea, variațiile parametrilor și URL-urile bazate pe sesiuni care creează duplicate neintenționate. Multe CMS-uri generează mai multe URL-uri pentru același conținut prin diverse trasee de navigare—tag-urile canonice le consolidează automat.
IndexNow accelerează descoperirea semnalelor canonice și consolidarea duplicatelor, reducând ceea ce ar dura săptămâni la doar câteva zile. Când implementezi tag-uri canonice pe conținutul republicat, IndexNow notifică imediat sistemele de căutare că aceste URL-uri trebuie grupate împreună. În loc să aștepți ca crawlerele să descopere relația canonică prin crawlare normală, IndexNow transmite direct această informație către indexul Microsoft și alte sisteme participante. Acest lucru este deosebit de valoros când repari retroactiv greșeli de republicare—poți implementa tag-uri canonice și folosi IndexNow pentru a semnala imediat schimbarea, fără a aștepta ca crawlerele să revină pe pagini. Pentru publisherii care gestionează conținut pe mai multe platforme, IndexNow devine un instrument esențial pentru a păstra controlul asupra versiunii reprezentative. Integrarea API permite trimiterea URL-urilor în masă, făcând posibilă gestionarea a sute sau mii de pagini republicate.
POST https://api.indexnow.org/indexnow
{
"host": "yoursite.com",
"key": "your-api-key",
"keyLocation": "https://yoursite.com/indexnow-key.txt",
"urlList": [
"https://yoursite.com/blog/article-1",
"https://yoursite.com/blog/article-2"
]
}
Urmărirea versiunii conținutului republicat care este selectată de AI necesită monitorizare dincolo de analiticele tradiționale. Configurează tracking pentru a identifica când sistemele AI citează sau fac referire la conținutul tău, notând ce URL apare în rezultatele căutării AI. Instrumente precum Semrush, Ahrefs și Moz încep să adauge metrici pentru vizibilitatea AI, deși acestea sunt încă mai puțin dezvoltate decât monitorizarea pentru căutarea tradițională. Implementează parametri UTM pe versiunile sindicate pentru a urmări atribuirea traficului, dar recunoaște că sistemele AI pot să nu transmită acești parametri, făcând atribuirea directă dificilă. Monitorizează Search Console (sau instrumente echivalente pentru alte sisteme de căutare) pentru tipare de crawlare—dacă versiunile secundare sunt accesate mai des decât cea canonică, este un semn că sistemul AI ar putea fi setat pe pagina greșită. Configurează alerte pentru mențiuni ale conținutului tău pe platforme de sindicare și corelează-le cu vizibilitatea AI pentru a identifica nepotriviri între unde apare conținutul tău și de unde îl selectează AI-ul.
Aplică această listă de verificare înainte de a republica orice conținut pentru a te asigura că păstrezi controlul vizibilității în AI:
Înainte de republicare, identifică versiunea canonică—URL-ul pe care vrei să îl reprezinte în rezultatele căutării AI. Acesta ar trebui să fie de obicei domeniul tău, nu o platformă de sindicare. Implementează tag-uri canonice pe fiecare versiune republicată care indică spre URL-ul canonic, chiar dacă republici pe proprietăți proprii (domenii diferite, subdomenii sau variații de parametri). Folosește IndexNow pentru a notifica imediat sistemele de căutare despre relația canonică, nu aștepta descoperirea prin crawlare. Evită republicarea pe platforme cu autoritate mare fără suport pentru canonical—unele platforme elimină tag-urile canonice sau nu le permit, făcându-le nepotrivite pentru republicare fără a accepta pierderi de vizibilitate. Monitorizează primele 48 de ore după republicare pentru a verifica dacă sistemele AI selectează versiunea ta canonică, nu o alternativă. Actualizează toate versiunile simultan când faci modificări de conținut—dacă actualizezi doar versiunea canonică, algoritmul de clusterizare poate să nu recunoască update-ul pe toate versiunile, ceea ce poate determina AI-ul să selecteze o versiune învechită. Stabilește un program de republicare care previne ca conținutul de pe platforme secundare să devină învechit; conținutul sindicat neactualizat crește riscul ca AI-ul să îl selecteze ca versiune reprezentativă dacă versiunea canonică nu a fost recent editată.
Tag-urile canonice nu previn penalizările deoarece conținutul duplicat nu declanșează penalizări în primul rând. Totuși, tag-urile canonice sunt esențiale pentru căutarea AI deoarece indică sistemelor AI ce versiune ar trebui să reprezinte clusterul tău de conținut. Fără tag-uri canonice, sistemele AI pot selecta o versiune nedorită ca sursă autoritară, reducându-ți vizibilitatea.
Monitorizează ce URL-uri apar în rezultatele de căutare AI și în citările pentru conținutul tău. Instrumente precum Semrush și Ahrefs adaugă metrici de vizibilitate AI. Verifică Search Console pentru tipare de crawlare—dacă versiunile secundare sunt accesate mai des decât versiunea canonică, sistemul AI poate să fi selectat pagina greșită.
Tehnic da, dar nu este recomandat. Fără tag-uri canonice, sistemele AI vor grupa conținutul și vor selecta o versiune ca reprezentativă—dar nu vei controla care. Platforma de distribuție ar putea avea autoritate mai mare, determinând AI să selecteze acea versiune în locul domeniului tău original.
Republicarea se referă de obicei la distribuirea conținutului tău pe mai multe canale pe care le controlezi sau cu care colaborezi. Sindicarea de conținut este o formă specifică de republicare în care platforme terțe republică conținutul cu permisiunea ta. Ambele creează probleme de conținut duplicat dacă nu sunt gestionate corect cu tag-uri canonice.
Tag-urile canonice sunt de obicei recunoscute în 24-48 de ore dacă folosești IndexNow pentru a notifica imediat sistemele de căutare. Fără IndexNow, poate dura săptămâni până când crawlerele descoperă relația canonică. De aceea IndexNow este esențial pentru gestionarea conținutului republicat—accelerează semnificativ procesul.
Folosește redirect 301 doar când dorești să consolidezi permanent URL-urile și versiunea secundară nu va fi niciodată actualizată independent. Folosește tag-uri canonice când ambele versiuni trebuie să rămână active (ca în cazul sindicării). Redirect-urile sunt semnale mai puternice dar dezactivează funcționalitatea URL-ului secundar.
Da, dacă nu este gestionată corect. Republicarea fără tag-uri canonice diluează semnalele de autoritate pe mai multe URL-uri. Sistemele AI pot selecta versiunea sindicată în locul celei originale, reducând vizibilitatea pe domeniul tău. Implementarea corectă a tag-urilor canonice previne acest lucru.
Implementă tag-uri canonice pe fiecare versiune republicată care indică spre domeniul tău original. Folosește IndexNow pentru a notifica imediat sistemele de căutare despre relația canonică. Evită republicarea pe platforme care nu suportă tag-uri canonice. Monitorizează ce versiune selectează sistemele AI în primele 48 de ore și ajustează dacă este necesar.
Urmărește modul în care sistemele AI citează și fac referire la conținutul tău republicat pe toate platformele. Obține informații în timp real despre ce versiune alege AI ca sursă autoritară.
Află cum previn URL-urile canonice problemele de conținut duplicat în sistemele de căutare AI. Descoperă cele mai bune practici pentru implementarea canonicalel...

Discuție în comunitate despre modul în care sistemele AI gestionează conținutul duplicat diferit față de motoarele de căutare tradiționale. Profesioniști SEO îm...
Află ce înseamnă canibalizarea conținutului în căutarea AI, cum îți afectează vizibilitatea brandului în răspunsurile AI și de ce este important să monitorizezi...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.