JSON-LD
JSON-LD este un format de date structurate standardizat W3C folosind sintaxa JSON pentru markup schema.org. Află cum JSON-LD îmbunătățește SEO, permite rezultat...
13 min citire

Află ce este JSON-LD și cum să-l implementezi pentru SEO. Descoperă beneficiile markup-ului de date structurate pentru Google, ChatGPT, Perplexity și vizibilitatea în căutarea AI.
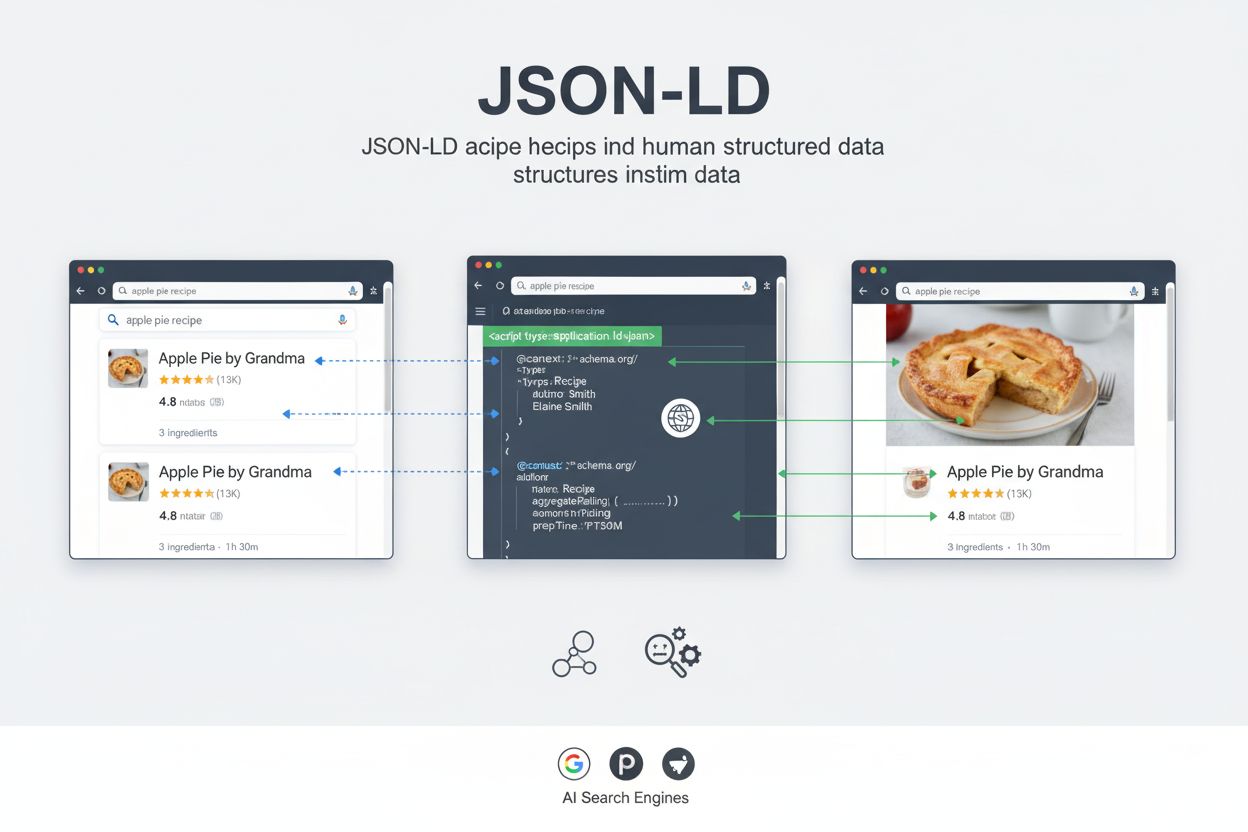
JSON-LD (JavaScript Object Notation for Linked Data) este un format de date ușor, lizibil de către mașini, care ajută motoarele de căutare să înțeleagă conținutul web prin markup structurat. Implementat prin tag-uri <script> în HTML, JSON-LD permite rezultate îmbogățite în căutare, îmbunătățește vizibilitatea în AI și este formatul recomandat de Google pentru implementarea datelor structurate schema.org.
JSON-LD (JavaScript Object Notation for Linked Data) este un format de date ușor, lizibil de către mașini, care permite motoarelor de căutare și sistemelor de inteligență artificială să înțeleagă sensul și contextul conținutului web. Spre deosebire de HTML-ul tradițional, conceput pentru cititori umani, JSON-LD oferă informații semantice explicite care ajută mașinile să interpreteze ce reprezintă conținutul tău. Datele structurate folosind JSON-LD au devenit esențiale în peisajul modern al căutării, unde atât motoarele de căutare tradiționale, cât și sistemele alimentate de AI precum Google AI Overviews, ChatGPT, Perplexity și Claude se bazează pe semnale clare, lizibile de către mașini pentru a înțelege și a afișa conținutul tău. Google recomandă oficial JSON-LD ca format preferat pentru implementarea datelor structurate schema.org, făcându-l standardul industriei pentru profesioniștii SEO și dezvoltatorii web. Implementând corect JSON-LD, transmiți motoarelor de căutare exact ce înseamnă fiecare element al paginii—fie că este vorba de prețul unui produs, ingrediente de rețetă, date de eveniment sau autorul unui articol—ceea ce influențează direct vizibilitatea ta atât în rezultatele de căutare tradiționale, cât și în noile experiențe de căutare AI.
Datele structurate au evoluat dintr-o tactică SEO opțională într-o componentă critică a vizibilității web moderne. W3C (World Wide Web Consortium) a standardizat JSON-LD în 2014 ca Recomandare W3C, stabilindu-l ca format oficial pentru datele legate pe web. De atunci, adoptarea a accelerat dramatic, cu motoare de căutare importante precum Google, Bing, Yahoo și Yandex care susțin markup-ul JSON-LD. Cercetările demonstrează impactul tangibil al implementării datelor structurate: Rotten Tomatoes a obținut o rată de click cu 25% mai mare pe paginile îmbunătățite cu date structurate față de cele fără markup, iar The Food Network a convertit 80% din paginile sale pentru a activa funcții de căutare și a înregistrat o creștere de 35% a vizitelor. Nestlé a constatat că paginile afișate ca rezultate îmbogățite în căutare au avut o rată de click cu 82% mai mare decât cele fără rezultate îmbogățite. Aceste statistici subliniază de ce implementarea JSON-LD a devenit obligatorie pentru site-urile competitive. Importanța formatului a crescut odată cu apariția motoarelor de căutare alimentate de AI, care se bazează puternic pe date structurate pentru a înțelege contextul conținutului și a decide dacă să citeze paginile tale în răspunsurile lor.
| Aspect | JSON-LD | Microdata | RDFa |
|---|---|---|---|
| Metodă de implementare | Încorporat în tag-uri <script> | Atribute și tag-uri HTML | Atribute extensie HTML5 |
| Amplasare | Head sau body (flexibil) | De obicei în body | Head și body |
| Separarea datelor | Separat de conținutul vizibil | Intercalat cu HTML | Intercalat cu HTML |
| Complexitate la imbricare | Excelent pentru date imbricate | Moderată | Moderată |
| Recomandare Google | Recomandat (Principal) | Susținut la fel | Susținut la fel |
| Ușurință la implementare | Cel mai ușor pentru dezvoltatori | Necesită modificarea HTML | Necesită modificarea HTML |
| Injecție dinamică | Suportă injecție JavaScript | Suport limitat | Suport limitat |
| Curba de învățare | Moderată (cunoștințe JSON utile) | Mai abruptă (atribute HTML) | Mai abruptă (concepte RDF) |
| Mentenanță la scară | Cel mai ușor de gestionat | Mai predispus la erori | Mai predispus la erori |
| Compatibilitate cu căutarea AI | Optim pentru LLM-uri | Bună | Bună |
Google afirmă explicit că JSON-LD este cea mai ușoară soluție pentru deținătorii de site-uri pentru implementare și mentenanță la scară, fiind mai puțin predispus la erori decât alternativele. Deși toate cele trei formate sunt la fel de valabile pentru Google Search, separarea datelor structurate de conținutul HTML vizibil face ca JSON-LD să fie superior pentru structuri complexe, imbricate—cum ar fi descrierea unui loc de desfășurare în cadrul unui eveniment sau detaliile de livrare ale unui produs într-o ofertă.
JSON-LD funcționează prin încorporarea unui script JavaScript object notation direct în documentul HTML, de obicei în secțiunea <head> sau oriunde în <body>. Formatul folosește un vocabular standardizat de la schema.org, care oferă definiții pentru sute de tipuri de entități și proprietăți. Când crawler-ele Google întâlnesc markup JSON-LD, ele analizează datele structurate și le folosesc pentru a înțelege mai bine conținutul paginii, permițând afișarea rezultatelor îmbogățite cu elemente vizuale precum rating-uri cu stele, informații despre prețuri, imagini și funcții interactive. Procesul de implementare începe cu identificarea tipului de conținut pe care vrei să-l marchezi—fie că este articol, produs, rețetă, eveniment, FAQ sau afacere locală—apoi alegerea tipului corespunzător din schema.org. Fiecare tip de schemă are proprietăți obligatorii (necesare pentru eligibilitatea la rezultate bogate) și proprietăți recomandate (care îmbunătățesc vizibilitatea și contextul). Proprietatea @context, setată pe “https://schema.org/"
, informează browserul că folosești vocabularul schema.org, iar proprietatea @type specifică exact tipul de entitate descrisă.
Iată un exemplu de bază JSON-LD pentru un articol:
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Article",
"headline": "Înțelegerea JSON-LD pentru SEO modern",
"author": {
"@type": "Person",
"name": "Sarah Johnson"
},
"datePublished": "2024-01-15",
"image": "https://example.com/article-image.jpg",
"description": "Un ghid cuprinzător pentru implementarea JSON-LD"
}
</script>
Pentru structuri mai complexe, JSON-LD suportă imbricarea, permițând încorporarea de obiecte conexe în obiecte părinte. De exemplu, o schemă Event poate conține obiecte Person imbricate pentru interpreți și un obiect Place pentru locație, toate într-o singură structură de date coerentă.
Deși numele sunt similare, JSON și JSON-LD au scopuri diferite și nu trebuie confundate. JSON (JavaScript Object Notation) este un format general, ușor pentru schimbul de date între sisteme și API-uri. Este un standard de sintaxă pentru organizarea datelor în perechi cheie-valoare și array-uri, dar nu poartă semnificație semantică—datele pot reprezenta orice, în funcție de context. JSON-LD, în schimb, este proiectat special pentru date legate pe web și folosește sintaxa JSON combinată cu context semantic de la vocabularul schema.org. JSON-LD transformă datele JSON brute în informații inteligibile pentru mașini adăugând context prin proprietatea @context, care spune mașinilor ce înseamnă fiecare câmp. Acest strat semantic este crucial pentru motoarele de căutare și sistemele AI: în timp ce JSON poate conține pur și simplu {"name": "John", "birthDate": "1990-05-15"}, JSON-LD declară explicit că aceasta este o entitate Person cu proprietăți specifice, permițând motoarelor de căutare să înțeleagă relația dintre date și conceptele din lumea reală. Pentru SEO, JSON-LD este net superior deoarece permite motoarelor de căutare nu doar să citească datele, ci să le înțeleagă semnificația și relevanța pentru interogările utilizatorilor.
Imbricarea în JSON-LD înseamnă organizarea informațiilor pe straturi ierarhice, permițând descrierea relațiilor dintre mai multe entități într-o singură structură de markup. Această capacitate este unul dintre cele mai mari avantaje ale JSON-LD comparativ cu alte formate de date structurate. Când imbrici obiecte, spui practic “această entitate face parte din acea entitate” sau “această proprietate aparține acelui obiect”. De exemplu, într-o schemă Event, poți imbrica un obiect Person (interpretul) și un obiect Place (locația) în cadrul obiectului Event. Fiecare obiect imbricat își menține propriul @type și proprietăți, creând o structură de date bogată și interconectată pe care motoarele de căutare o pot interpreta cu precizie.
Iată un exemplu de eveniment muzical cu informații imbricate despre interpret și locație:
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Event",
"name": "Summer Jazz Festival",
"startDate": "2024-07-15T18:00:00",
"location": {
"@type": "Place",
"name": "Central Park Amphitheater",
"address": {
"@type": "PostalAddress",
"streetAddress": "123 Park Avenue",
"addressLocality": "New York",
"addressRegion": "NY",
"postalCode": "10001"
}
},
"performer": {
"@type": "Person",
"name": "Jazz Quartet Ensemble"
}
}
</script>
Imbricarea permite motoarelor de căutare să înțeleagă că interpretul este asociat cu acest eveniment specific la această locație specifică. Acest context granular este de neprețuit pentru sistemele AI care trebuie să înțeleagă relațiile dintre entități. Tag-urile imuabile precum @context și @type nu se schimbă între diferite tipuri de schemă, fiind elemente reutilizabile pentru strategii complexe de markup.
Chiar și dezvoltatorii experimentați fac greșeli când implementează JSON-LD, iar aceste erori pot împiedica recunoașterea datelor structurate de către motoarele de căutare. Înțelegerea capcanelor frecvente te ajută să le eviți și să te asiguri că markup-ul tău este valid și eficient. Erorile de sintaxă sunt cele mai frecvente—folosirea de ghilimele tipografice în loc de ghilimele drepte, lipsa virgulelor între proprietăți sau plasarea incorectă a parantezelor va face ca întregul bloc JSON-LD să eșueze la validare. Mulți dezvoltatori copiază cod JSON-LD din Microsoft Word sau alte editoare de text bogat, care transformă automat ghilimelele drepte în ghilimele tipografice, stricând sintaxa. Folosește întotdeauna un editor de text simplu sau un editor de cod când lucrezi cu JSON-LD.
Folosirea de vocabular incorect sau inexistent este o altă greșeală critică. Schema.org are nume și tipuri de proprietăți specifice, iar folosirea de variații sau greșeli de scriere va face ca motoarele de căutare să ignore markup-ul. De exemplu, folosirea “authorName” în locul obiectului imbricat “author” cu proprietatea “name” nu va fi recunoscută. Consultă întotdeauna schema.org pentru a verifica exact numele proprietăților și structura necesară pentru tipul de schemă ales.
Date inexacte sau înșelătoare sunt deosebit de problematice deoarece încalcă politicile Google privind datele structurate. Markup-ul JSON-LD trebuie să reflecte cu exactitate conținutul vizibil al paginii. Dacă pagina afișează un preț de produs de 29,99 USD, JSON-LD trebuie să arate același preț—nu alt preț sau o gamă de prețuri. Marcarea conținutului care nu există pe pagină (de exemplu, adăugarea de recenzii când nu sunt vizibile) este considerată înșelătoare și poate duce la acțiuni manuale împotriva site-ului.
Greșeli de formatare apar adesea când dezvoltatorii construiesc manual JSON-LD fără validare corespunzătoare. Paranteze de închidere lipsă, șiruri neînchise sau array-uri formate incorect duc la erori de validare. Folosește întotdeauna Google Rich Results Test sau Validatorul de Markup Schema.org pentru a verifica implementarea înainte de a o lansa în producție.
Implementarea corectă a JSON-LD permite paginilor tale să apară ca rezultate bogate în Google Search, adică listări în căutare îmbunătățite cu elemente vizuale suplimentare și informații dincolo de titlu, URL și meta descriere. Rezultatele bogate pot include rating-uri cu stele, informații despre preț, imagini de produs, detalii de eveniment, secțiuni FAQ expandabile, navigare breadcrumb și altele. Prominența vizuală a rezultatelor bogate le face semnificativ mai susceptibile la a primi click-uri: studiile arată că rezultatele bogate pot crește rata de click cu 30% sau mai mult comparativ cu rezultatele standard.
Google suportă peste 32 de tipuri diferite de rezultate bogate, fiecare cu cerințe specifice de schemă. Review snippets afișează evaluări cu stele și numărul de recenzii, construind credibilitate și încredere. Rezultatele bogate de produs arată direct în căutare prețul, disponibilitatea și evaluările, permițând utilizatorilor să ia decizii de cumpărare fără a intra pe site. FAQ rich results afișează întrebări și răspunsuri în secțiuni expandabile, ideale pentru a capta featured snippets și oportunități “People Also Ask”. Rezultatele bogate pentru evenimente afișează date, locații și informații despre bilete, făcând ușor pentru utilizatori să descopere și să participe la evenimentele tale. Rezultatele bogate pentru articole afișează informații despre autor, data publicării și imagini reprezentative, stabilind autoritate și semnale de prospețime.
Pentru afacerile locale, schema LocalBusiness permite afișarea informațiilor companiei în rezultatele locale și pe Google Maps, inclusiv adresa, numărul de telefon, programul și recenziile clienților. Schema de anunțuri de angajare face ca anunțurile tale să fie eligibile pentru a apărea în Google for Jobs, cu poziționare proeminentă în partea de sus a rezultatelor. Fiecare dintre aceste tipuri de rezultate bogate necesită implementare JSON-LD specifică, însă investiția aduce beneficii în vizibilitate și implicarea utilizatorilor.
Apariția motoarelor de căutare alimentate de AI a schimbat fundamental importanța datelor structurate. Google AI Overviews, ChatGPT Search, Perplexity AI și Claude Search toate se bazează pe înțelegerea conținutului pentru a decide dacă îl citesc în răspunsurile lor. Deși aceste sisteme AI nu parsează JSON-LD exact ca motoarele de căutare tradiționale, datele structurate îți cresc semnificativ șansele de a fi inclus în răspunsuri generate AI. Documentația Google afirmă explicit că AI Overviews preia informații “dintr-o gamă largă de surse, inclusiv de pe web”, iar paginile cu markup clar și bine structurat sunt mai probabil să fie selectate.
ChatGPT Search folosește indexul Bing ca sursă, ceea ce înseamnă că paginile tale indexate de Bing cu markup de schemă corect pot fi surse pentru răspunsurile ChatGPT. Perplexity AI este un motor generativ de Q&A care citează surse web în răspunsuri și beneficiază clar de date structurate ce fac conținutul mai ușor de identificat și extras. Claude Search, lansat la începutul lui 2025, preia informații în timp real de pe site-uri indexate și oferă citări directe, deci datele structurate sunt cruciale pentru vizibilitate. Punctul comun pentru toate aceste sisteme AI este preferința pentru conținut clar, autoritativ și bine adnotat cu date structurate.
Implementarea JSON-LD transformă site-ul într-un grafic de cunoștințe lizibil de mașini, pe care sistemele AI îl pot accesa pentru informații fundamentate și contextuale. Este deosebit de important pentru schema FAQ și HowTo, care răspund direct la întrebări într-un format ușor de extras și citat de AI. Folosind JSON-LD semantic pentru a dezvolta graficul de cunoștințe al conținutului, creezi conținut pregătit pentru căutarea AI, mai probabil să fie afișat în răspunsuri generative pe multiple platforme.
O implementare de succes a JSON-LD necesită urmarea celor mai bune practici consacrate, care asigură ca markup-ul să fie valid, ușor de întreținut și eficient atât pentru motoarele de căutare, cât și pentru sistemele AI. Folosește exclusiv JSON-LD pentru implementări noi, deoarece Google îl recomandă în fața Microdata și RDFa. Plasează JSON-LD într-un tag <script type="application/ld+json">, de obicei în secțiunea <head>, deși poate apărea oriunde în document. Această amplasare menține datele structurate separate de HTML-ul vizibil, făcându-le mai ușor de gestionat și mai puțin predispuse la erori când se schimbă HTML-ul.
Alege tipuri de schemă relevante care se potrivesc exact cu conținutul tău. Nu forța tipuri de schemă asupra conținutului unde nu se aplică—folosește FAQPage doar pe pagini cu întrebări frecvente reale, HowTo doar pe ghiduri pas cu pas, iar schema Product doar pe pagini de produs. Folosirea greșită a tipurilor de schemă încalcă regulile Google și poate duce la acțiuni manuale împotriva site-ului. Validează markup-ul cu Google Rich Results Test înainte de a-l lansa în producție. Acest instrument gratuit verifică JSON-LD de erori de sintaxă și îți spune pentru ce tipuri de rezultate bogate ești eligibil. După lansare, monitorizează datele structurate cu raportul Rich Results din Google Search Console ca să te asiguri că markup-ul rămâne valid în timp.
Concentrează-te pe proprietățile obligatorii și recomandate în loc să încerci să incluzi fiecare proprietate posibilă. Documentația Google subliniază că e mai bine să oferi mai puține proprietăți, dar complete și corecte, decât să pui toate proprietățile posibile cu date incomplete sau incorecte. De exemplu, pe o pagină de produs, asigură-te că ai preț corect, disponibilitate și cel puțin o imagine de calitate înainte de a adăuga proprietăți opționale precum detalii de livrare sau garanție.
Menține datele exacte și sincronizate cu conținutul vizibil al paginii. JSON-LD trebuie să reflecte ceea ce văd utilizatorii. Dacă actualizezi prețuri, număr de recenzii sau date de eveniment, actualizează și JSON-LD. Datele structurate învechite sau inexacte dăunează încrederii și pot declanșa acțiuni manuale. Implementează dinamic când e necesar folosind JavaScript, metodă pe care JSON-LD o suportă mai bine decât alte formate. Dacă conținutul este generat de framework-uri JavaScript sau încărcat dinamic, JSON-LD poate fi totuși injectat în DOM și recunoscut de motoarele de căutare.
Validarea implementării JSON-LD este esențială înainte și după lansare. Google Rich Results Test este instrumentul principal pentru verificarea validității JSON-LD și pentru a determina ce tipuri de rezultate bogate poate obține pagina. Pur și simplu introdu URL-ul sau codul JSON-LD în instrument și acesta va identifica orice eroare, avertisment sau proprietate recomandată lipsă. Testul oferă feedback detaliat despre ce funcționează și ce trebuie îmbunătățit.
Validatorul de Markup Schema.org oferă validare independentă de schema, fără avertismente specifice Google, utilă pentru a înțelege conformitatea cu schema.org independent de cerințele Google. Raportul Rich Results din Google Search Console monitorizează performanța datelor structurate ale site-ului în timp, arătând ce pagini au markup valid și ce tipuri de rezultate bogate apar în căutare. Această monitorizare continuă este crucială pentru a identifica problemele după lansare, cum ar fi când modificările de template strică accidental JSON-LD.
Instrumente de testare a datelor structurate precum BrightEdge SearchIQ pot analiza implementările de schemă ale concurenților și identifica cele mai frecvente tipuri de schemă din industrie, ajutându-te să prioritizezi ce markup să implementezi mai întâi. Aceste informații competitive asigură că implementezi cele mai impactante tipuri de schemă pentru nișa ta.
Diferite tipuri de conținut necesită implementări de schemă diferite, fiecare cu proprietăți obligatorii și recomandate specifice. Schema Article este esențială pentru postări de blog și conținut de știri, necesitând headline, author, datePublished și image. Adăugarea dateModified semnalează prospețimea, iar articleBody poate oferi context suplimentar. Schema Product necesită cel puțin name, image și description, cu proprietăți recomandate precum price, availability și aggregateRating. Pentru site-urile de e-commerce, includerea obiectelor detaliate Offer și Review îmbunătățește semnificativ eligibilitatea pentru rezultate bogate.
Schema FAQ (FAQPage) este puternică pentru a capta featured snippets și oportunități “People Also Ask”. Necesită un array mainEntity de obiecte Question, fiecare cu proprietăți acceptedAnswer. Schema HowTo funcționează similar, necesitând instrucțiuni pas cu pas marcate cu obiecte HowToStep. Schema Event necesită name, startDate și location, cu proprietăți recomandate precum description, image și informații despre interpreți. Schema LocalBusiness este critică pentru afacerile fizice, necesitând name, address, telephone și program de funcționare.
Schema Recipe necesită name, image, recipeIngredient și recipeInstructions, cu proprietăți recomandate precum prepTime, cookTime, recipeYield și informații nutriționale. Schema Organization ar trebui implementată la nivelul întregului site pentru a stabili identitatea brandului, incluzând name, logo, informații de contact și profiluri social media. Implementarea mai multor tipuri de schemă pe o singură pagină este comună și încurajată—de exemplu, o pagină de articol poate include simultan schema Article, Organization și Author (Person).
Direcția datelor structurate este clară: pe măsură ce motoarele de căutare AI se maturizează și devin mai răspândite, datele structurate vor fi tot mai centrale pentru vizibilitatea web. Motoarele de căutare și sistemele AI se îndreaptă spre o abordare semantică, unde datele structurate oferă fundamentul de care modelele generative au nevoie pentru a produce răspunsuri precise și verificabile. Această schimbare înseamnă că investiția în JSON-LD azi nu ține doar de SEO tradițional—este despre construirea infrastructurii semantice de care viitoarele instrumente AI vor depinde.
Ne putem aștepta ca vocabularul schema.org să se extindă cu tipuri și proprietăți noi, special concepute pentru nevoile AI. Tipuri emergente de schemă precum QAPage, Speakable și scheme sectoriale vor oferi modalități mai detaliate de a marca conținutul pentru consumul AI. Integrarea datelor structurate cu grafurile de cunoștințe se va adânci, permițând sistemelor AI să înțeleagă nu doar pagini individuale, ci și relațiile dintre entități pe întregul site și la nivelul web-ului larg. Pentru specialiștii de marketing digital și SEO, asta înseamnă că datele structurate vor rămâne o prioritate strategică. Organizațiile care implementează markup JSON-LD cuprinzător și precis astăzi vor avea un avantaj semnificativ pe măsură ce căutarea AI evoluează și câștigă cotă de piață de la motoarele de căutare tradiționale.
Convergența dintre SEO tradițional și vizibilitatea AI prin date structurate reprezintă o schimbare fundamentală în modul în care site-urile comunică cu mașinile. Stăpânind implementarea JSON-LD acum, îți asiguri prezența digitală pentru peisajul de căutare alimentat de AI care deja se conturează.
Urmărește cum apar datele tale structurate în rezultatele de căutare alimentate de AI, inclusiv Google AI Overviews, ChatGPT, Perplexity și Claude. AmICited monitorizează vizibilitatea domeniului tău pe toate platformele majore AI.
JSON-LD este un format de date structurate standardizat W3C folosind sintaxa JSON pentru markup schema.org. Află cum JSON-LD îmbunătățește SEO, permite rezultat...

Discuție în comunitate despre implementarea JSON-LD pentru vizibilitate în căutarea AI. Dezvoltatori și specialiști SEO împărtășesc cum afectează datele structu...
Datele structurate sunt marcaje standardizate care ajută motoarele de căutare să înțeleagă conținutul paginilor web. Află cum JSON-LD, schema.org și microdata î...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.