Paginare
Paginarea împarte seturile mari de conținut în pagini gestionabile pentru o experiență mai bună a utilizatorului și SEO. Află cum funcționează paginarea, impact...
10 min citire

Află cum influențează paginarea vizibilitatea în AI. Descoperă de ce împărțirea tradițională ajută sistemele AI să găsească conținutul tău, în timp ce scroll-ul infinit îl ascunde, și cum să optimizezi paginarea pentru generatoarele de răspunsuri AI.
Paginarea este practica de a împărți seturi mari de conținut în mai multe pagini legate între ele. Da, aceasta afectează semnificativ sistemele AI—paginarea creează URL-uri distincte, accesibile la crawl, care ajută motoarele de căutare AI precum ChatGPT, Perplexity și SGE-ul Google să descopere și să indexeze conținutul tău mai eficient, în timp ce implementările de scroll infinit ascund adesea conținutul de crawlerii AI.
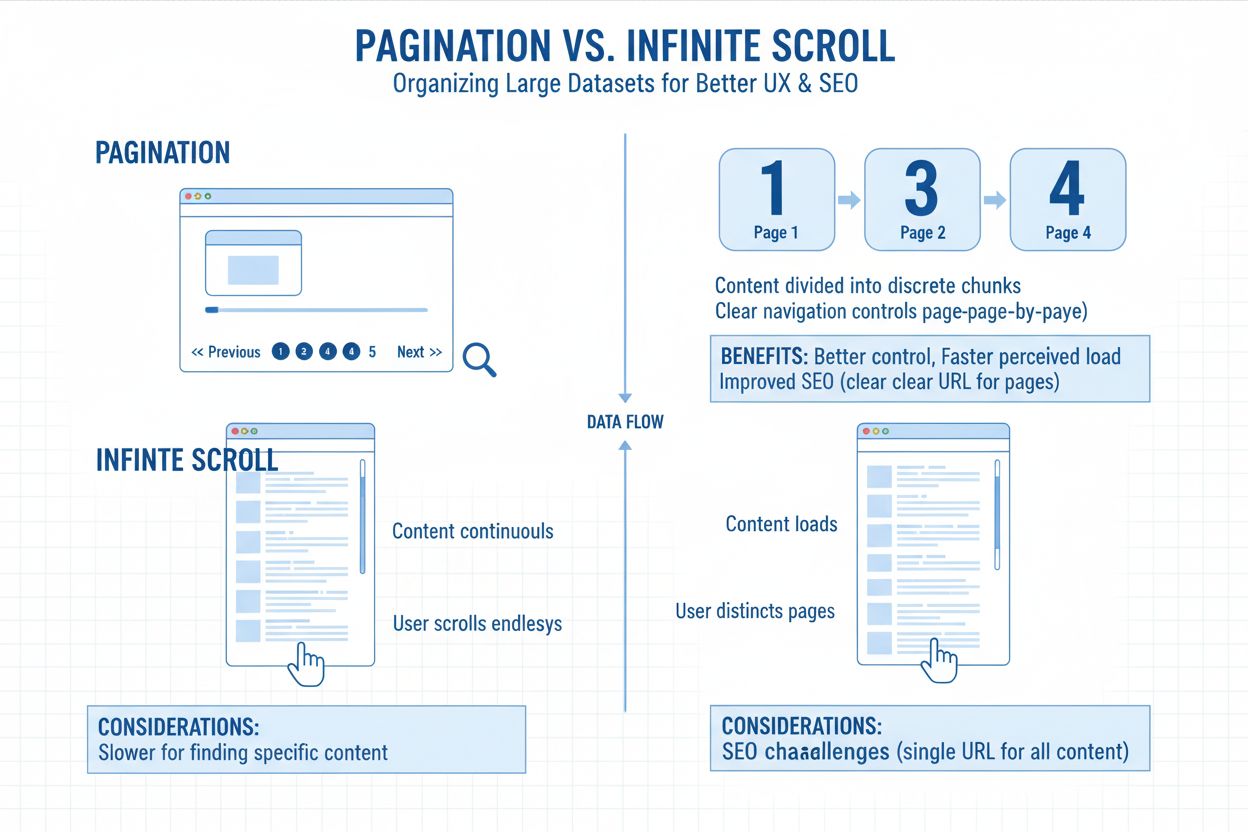
Paginarea se referă la practica de a împărți seturi mari de conținut în mai multe pagini legate între ele, în loc să afișeze totul pe un singur ecran infinit. Imaginează-ți-o ca pe capitolele unei cărți—fiecare pagină conține o parte gestionabilă din conținutul total, conectată prin linkuri numerotate sau butoane “următorul/anteriorul”. Această abordare structurală apare peste tot, de la liste de produse în magazinele online, la arhive de bloguri, fire de discuții pe forumuri și rezultate de căutare. Structura URL-ului reflectă de obicei această diviziune prin parametri precum ?page=2 sau căi curate precum /categorie/page/2/, permițând atât utilizatorilor, cât și motoarelor de căutare să înțeleagă poziția lor în seria de conținut. Paginarea servește ca un instrument organizațional fundamental care echilibrează experiența utilizatorului cu cerințele tehnice pentru accesibilitatea conținutului.
Site-urile implementează paginarea în principal pentru optimizarea performanței și organizarea conținutului. Încărcarea simultană a sute sau mii de elemente ar solicita excesiv resursele serverului și ar crea timpi de încărcare lenți, dăunători pentru metricile de performanță care afectează clasarea în căutare. Utilizatorii apreciază posibilitatea de a salva pagini specifice, de a sări direct la pagina 10 sau de a înțelege cât conținut mai este disponibil. Din perspectivă tehnică, împărțirea conținutului creează URL-uri distincte pe care motoarele de căutare le pot indexa individual, păstrând distribuția autorității linkurilor în arhitectura site-ului. Această claritate structurală devine tot mai importantă pe măsură ce sistemele AI evoluează pentru a înțelege relațiile dintre conținut și tiparele de accesibilitate.
Relația dintre paginare și vizibilitatea în AI reprezintă una dintre cele mai critice considerații SEO tehnice în peisajul modern al căutărilor. Motoarele de căutare tradiționale precum Google au înțeles de mult timp paginarea urmărind linkurile și tiparele secvențiale ale paginilor. Totuși, motoarele de căutare și generatoarele de răspunsuri bazate pe AI funcționează fundamental diferit, necesitând o abordare mai nuanțată a organizării conținutului. Modelele lingvistice mari care alimentează ChatGPT, Perplexity sau Search Generative Experience (SGE) de la Google nu parcurg neapărat paginile liniar sau nu urmează ierarhiile tradiționale de navigare. În schimb, acestea funcționează prin tokenizarea și rezumarea intrărilor textuale—adesea extrase din date publice, API-uri sau baze de date structurate, nu din ierarhii adânci de crawl.
Atunci când conținutul tău este dispersat pe mai multe pagini slab structurate, motoarele AI pot sări peste intrările mai adânci sau să le înțeleagă greșit în raport cu setul mai larg de conținut. Dacă există puțină variație în metadate sau semnale semantice slabe, conținutul tău paginat pare redundant—sau este ignorat complet. Asta creează un decalaj de vizibilitate critic: conținut care se clasează bine în căutarea Google tradițională poate rămâne complet invizibil pentru generatoarele de răspunsuri AI. Diferența contează deoarece sistemele AI prioritizează datele structurate, complete și ușor de recuperat. Ele nu “derulează” ca un utilizator. Ele analizează codul, URL-urile și metadatele pentru a rezuma sau cita conținutul rapid și precis. Dacă pagina ta nu expune conținutul prin URL-uri accesibile la crawl sau metadate bogate, motoarele AI nu îl pot recupera pentru a-l include în răspunsuri generate.
Alegerea dintre paginare tradițională și scroll infinit a devenit un factor definitoriu pentru descoperibilitatea conținutului de către AI. Implementările de scroll infinit încarcă conținutul prin JavaScript doar după interacțiunea utilizatorului, creând o problemă fundamentală de accesibilitate pentru crawlerii AI. Majoritatea implementărilor de scroll infinit nu expun conținutul prin URL-uri distincte—în schimb, totul se încarcă pe o singură pagină prin execuție JavaScript dinamică. Asta înseamnă că crawlerii AI, care nu simulează comportamentul real al utilizatorilor precum derularea sau clickurile, ratează de obicei totul în afara primei vizualizări. Dacă pagina ta nu expune acel conținut suplimentar prin URL-uri accesibile la crawl sau metadate, motoarele AI nu îl pot recupera. Poate ai 200 de articole, 300 de produse sau zeci de studii de caz, dar dacă acestea sunt ascunse sub evenimente de încărcare declanșate de JavaScript, AI-ul vede doar 12 elemente. Poate.
Paginarea tradițională câștigă decisiv pentru indexarea AI deoarece produce URL-uri curate, accesibile la crawl (de exemplu, /blog/page/4), permițând motoarelor să acceseze și să segmenteze complet conținutul. Semnalizează structura tematică prin linking intern, folosind linkuri standardizate precum “Pagina următoare” sau “Pagina anterioară” pentru a ajuta motoarele să vadă cum se leagă conținutul. Paginarea limitează dependența de JavaScript, asigurând că tot conținutul tău se încarcă pentru crawlere indiferent de interacțiunea utilizatorului cu pagina. Această claritate structurală se traduce direct în vizibilitate AI mai bună—când ChatGPT sau Perplexity îți scanează site-ul, pot descoperi și indexa conținutul paginat mult mai eficient decât conținutul ascuns în spatele scroll-ului infinit.
| Aspect | Paginare | Scroll infinit |
|---|---|---|
| Accesibilitate la crawl | URL-uri unice permit indexare profundă | Conținut adesea ascuns după încărcări JS |
| Descoperire AI | Mai multe pagini pot avea rank independent | De obicei o singură pagină indexată |
| Date structurate | Mai ușor de atribuit fiecărei pagini | Adesea lipsesc sau sunt diluate |
| Linkare directă | Ușor de legat la conținut specific | Dificil de realizat linkuri adânci |
| Compatibilitate sitemap | Compatibil și complet | Adesea lasă pe dinafară conținut adânc |
| Structură URL | URL-uri clare, distincte pe pagină | Un singur URL cu încărcare dinamică |
| Vizibilitate conținut | Tot conținutul accesibil crawlerilor | Conținutul necesită execuție JS |
Arhitectura tehnică a scroll-ului infinit creează bariere fundamentale pentru descoperirea conținutului de către AI. Când conținutul se încarcă doar prin JavaScript și niciun URL nu reflectă acel conținut nou, motoarele AI nu îl văd niciodată. Pentru un crawler, restul listei tale pur și simplu nu există. Aceasta nu este o limitare a sistemelor AI—este o consecință a modului în care este implementat scroll-ul infinit. Majoritatea implementărilor de scroll infinit prioritizează experiența utilizatorului în detrimentul accesibilității tehnice, încărcând conținutul dinamic fără a crea URL-uri sau metadate corespondente pe care AI-ul să le poată interpreta.
Gândește-te la un scenariu real: un retailer global de modă și-a redesenat site-ul cu o interfață lucioasă de scroll infinit. Viteza site-ului a crescut, metricile de engagement arătau bine, însă traficul din sumarizările AI a scăzut dramatic. SKU-urile păreau să dispară din uneltele de căutare conversațională. După un audit al arhitecturii, problema a devenit clară: întregul catalog era ascuns în spatele scroll-ului infinit fără variante accesibile la crawl. Niciun URL pentru pagini secundare. Niciun linking suplimentar. Doar o listă lungă, invizibilă de produse. SGE-ul Google și ChatGPT nu puteau accesa nimic după primele câteva produse pe categorie. Oricât de frumos arăta site-ul, descoperibilitatea lui era compromisă pentru sistemele AI.
O implementare corectă a paginării necesită atenție la mai mulți factori tehnici care determină dacă sistemele AI pot descoperi și cita conținutul tău. Fundamentul începe cu structuri URL curate și logice care indică clar relațiile secvențiale. Fie că folosești parametri de interogare (?page=2) sau structuri bazate pe cale (/page/2/), consistența contează mai mult decât formatul ales. Ambele variante funcționează la fel de bine pentru AI dacă sunt implementate corect. Important este ca fiecare URL paginat să încarce conținut distinct și să fie accesibil prin linkuri HTML standard care nu necesită execuție JavaScript.
Tag-urile canonice autoreferențiale reprezintă un punct critic pentru strategia de paginare. Fiecare pagină paginată ar trebui să includă un tag canonical care să indice către ea însăși, semnalizând că fiecare pagină este varianta preferată a sa. Această abordare păstrează independența URL-urilor secvențiale, permițând fiecăreia să concureze pentru ranking pe baza conținutului său specific și a relevanței pentru diverse interogări. Evită practica învechită de a canonicaliza toate paginile paginate către pagina unu—aceasta consolidează semnalele, dar elimină șansa ca paginile individuale să aibă ranking independent în AI. Când canonicalizezi totul la pagina unu, spui explicit motoarelor AI să ignore pagini potențial valoroase care conțin produse, conținut sau informații unice.
Metadate unice pentru fiecare pagină devin esențiale pentru vizibilitatea în AI. Nu folosi titluri generice de tipul “Pagina 2” sau descrieri duplicate pe toată secvența. În schimb, scrie metadate specifice fiecărei pagini, bogate în cuvinte cheie relevante pentru focusul paginii. De exemplu, în loc de “Produse - Pagina 2”, folosește “Încălțăminte sport de damă sub 100 RON - Pagina 2” sau “Tendințe AI în retail – Bibliotecă de studii de caz (Pagina 2)”. Această claritate crește vizibilitatea deoarece sistemele AI înțeleg contextul și pot determina mai bine când conținutul tău este relevant pentru anumite interogări. Fiecare set de metadate trebuie să urmeze principiile clarității, unicității și aliniamentului cuvintelor cheie. Scopul este ca scopul fiecărei pagini să fie evident atât pentru AI, cât și pentru cititorii umani.
Arhitectura linking-ului intern determină dacă sistemele AI pot descoperi și naviga eficient prin paginile secvențiale. O structură liniară (pagina 1 → 2 → 3) creează căi lungi de crawl unde paginile adânci sunt la multe clickuri de homepage, putând lăsa conținut valoros nedescoperit. Implementările inteligente includ linkuri complementare precum opțiuni “Vezi tot” sau hub-uri de categorie care trimit direct la pagini cheie, reducând adâncimea crawl-ului și distribuind echitatea linkurilor mai uniform. Relația dintre navigarea pe fațete și paginarea secvențială adaugă complexitate, deoarece combinațiile de filtre pot genera mii de variații URL. Linking-ul intern corect asigură că paginile prioritare primesc suficientă atenție din partea crawlerilor, în timp ce combinațiile mai puțin importante sunt deprioritizate prin taguri noindex sau semnale canonice strategice.
Lanțuri strategice de linking intern de la conținutul pilon către pagini paginate specifice ghidează sistemele AI prin structura conținutului tău. Din pagina principală de categorie, leagă direct către pagini paginate specifice folosind anchor text care ghidează înțelegerea AI. Exemplu: “Explorează mai multe povești de succes ecommerce în seria noastră de studii de caz – pagina 3.” Fă semnalul semnificativ și ușor de găsit. Această abordare învață sistemele AI cum se leagă conținutul tău și cum ar trebui să fie descoperit. Când crawlerii AI întâlnesc aceste linkuri contextuale, înțeleg relația dintre pagini și pot determina mai bine care conținut este cel mai relevant pentru interogări specifice.
Problemele de conținut duplicat apar atunci când mai multe URL-uri afișează conținut identic sau substanțial similar fără diferențiere adecvată. Se întâmplă când paginile secvențiale nu au elemente unice în afară de listarea articolelor sau când parametrii URL creează mai multe căi către același conținut. Motoarele de căutare și sistemele AI au dificultăți în a determina ce versiune să claseze, putând fragmenta vizibilitatea pe mai multe URL-uri. În plus, dacă paginile paginate includ text șablon, headere și footere cu conținut unic minim, pot fi percepute ca pagini “subțiri” cu valoare redusă. Soluția implică utilizarea atentă a tagurilor canonical, descrieri meta unice pentru fiecare pagină și asigurarea că fiecare pagină oferă suficientă valoare distinctă dincolo de elementele de navigare și secțiunile template.
Implementările exclusiv JavaScript reprezintă probabil cea mai comună greșeală care ascunde conținutul de sistemele AI. Dacă site-ul tău folosește framework-uri precum React sau Angular pentru a reda controalele de paginare doar pe client, fără randare pe server, crawlerii AI s-ar putea să nu descopere niciodată conținutul de după pagina unu. Asigură-te că linkurile de navigare există în HTML-ul inițial primit de AI, nu generate exclusiv prin JavaScript după încărcarea paginii. Folosește îmbunătățire progresivă—linkuri HTML de bază pe care JavaScript le poate îmbunătăți cu interacțiuni și animații mai fluide. Testează implementarea cu unelte care arată ce văd crawlerii versus ce afișează browserele cu JavaScript activat. Aceasta evidențiază golurile de crawlabilitate care pot costa vizibilitatea în AI.
Monitorizarea eficienței paginării necesită urmărirea modului în care sistemele AI interacționează cu conținutul tău multipagină. Spre deosebire de SEO tradițional, unde Google Search Console oferă informații directe, monitorizarea vizibilității în AI necesită alte abordări. Unelte precum Screaming Frog SEO Spider pot scana site-ul tău asemănător modului în care ar face-o sistemele AI, cartografiind structurile de pagini și identificând paginile orfane sau problemele de adâncime de crawl. DeepCrawl și Sitebulk oferă analiză avansată cu vizualizarea relațiilor dintre pagini. Google Search Console oferă perspective din perspectiva Google, arătând ce URL-uri paginate sunt indexate și tiparele de frecvență ale crawl-ului.
Indicatorii cheie de performanță pentru conținutul paginat includ dacă paginile adânci apar în răspunsuri generate de AI, cât de des sistemele AI citează conținutul tău paginat și dacă pagini diferite se clasează pentru interogări long-tail distincte. Monitorizează mențiunile de brand în răspunsurile AI—dacă sistemele AI citează constant pagina ta unu, dar nu menționează niciodată paginile adânci, structura ta de paginare poate necesita optimizare. Urmărește ce pagini paginate generează cel mai mult trafic din surse AI. Aceste date arată dacă strategia ta de paginare expune eficient conținutul către AI sau dacă este nevoie de restructurare. Audituri regulate identifică problemele înainte să afecteze vizibilitatea, mai ales după actualizări de site sau migrarea framework-urilor.
Peisajul căutării alimentate de AI evoluează rapid, cu sisteme și capabilități noi apărând regulat. Strategiile de paginare care funcționează astăzi ar trebui să rămână eficiente pe măsură ce AI-ul devine mai sofisticat, dar a ține pasul necesită înțelegerea tendințelor emergente. Algoritmii de căutare AI au devenit tot mai sofisticați în a înțelege relațiile dintre conținut și a determina care pagini paginate merită prioritate la indexare. Algoritmii de potrivire neurală și înțelegerea bazată pe BERT de la Google ajută motoarele să recunoască faptul că pagina doi a unei categorii oferă produse diferite față de pagina unu, chiar dacă textul din jur este similar. Această înțelegere îmbunătățită înseamnă că o diviziune bine structurată, cu diferențe semnificative între pagini, beneficiază mai mult ca niciodată de indexare independentă.
Totuși, AI-ul detectează mai bine și conținutul subțire sau duplicat de pe pagini paginate, făcând mai greu de păcălit sistemul cu pagini abia diferențiate. Algoritmii de machine learning prezic mai precis intenția utilizatorului, putând afișa pagini adânci pentru interogări long-tail specifice atunci când acestea se potrivesc cel mai bine cu intenția de căutare. Implicația practică este să te asiguri că fiecare pagină paginată oferă valoare unică autentică—produse distincte, conținut diferit sau variații semnificative—nu doar împărțiri mecanice ale aceleiași informații. Pe măsură ce sistemele AI continuă să evolueze, principiile de bază rămân constante: URL-uri distincte, linkuri accesibile la crawl, valoare unică pe pagină și metadate clare vor continua să determine eficiența paginării pentru vizibilitatea în AI.
Urmărește cum apare conținutul tău în răspunsurile generate de AI pe ChatGPT, Perplexity și alte motoare de căutare AI. Asigură-te că brandul tău este citat când AI răspunde la întrebări despre industria ta.
Paginarea împarte seturile mari de conținut în pagini gestionabile pentru o experiență mai bună a utilizatorului și SEO. Află cum funcționează paginarea, impact...
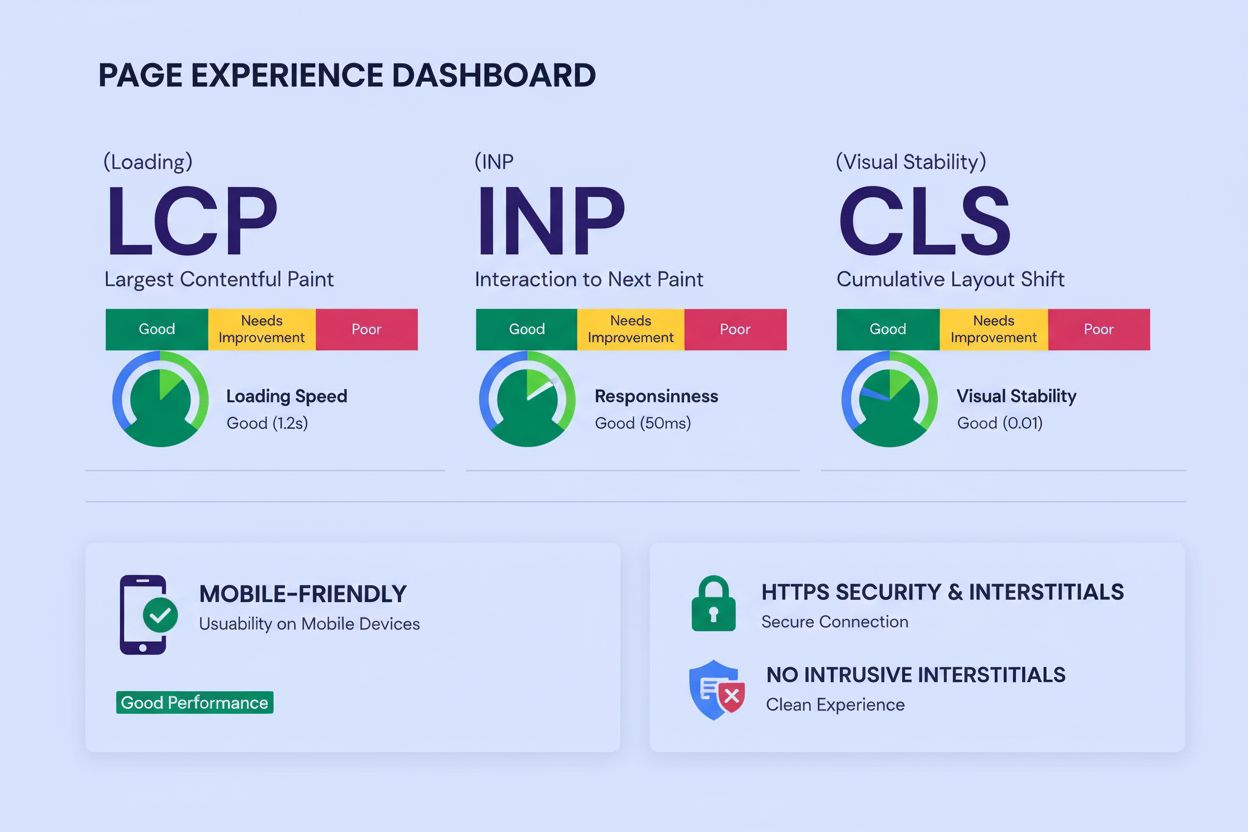
Experiența paginii măsoară calitatea interacțiunii utilizatorului prin Core Web Vitals, prietenia cu dispozitivele mobile, securitatea HTTPS și interstițialele ...
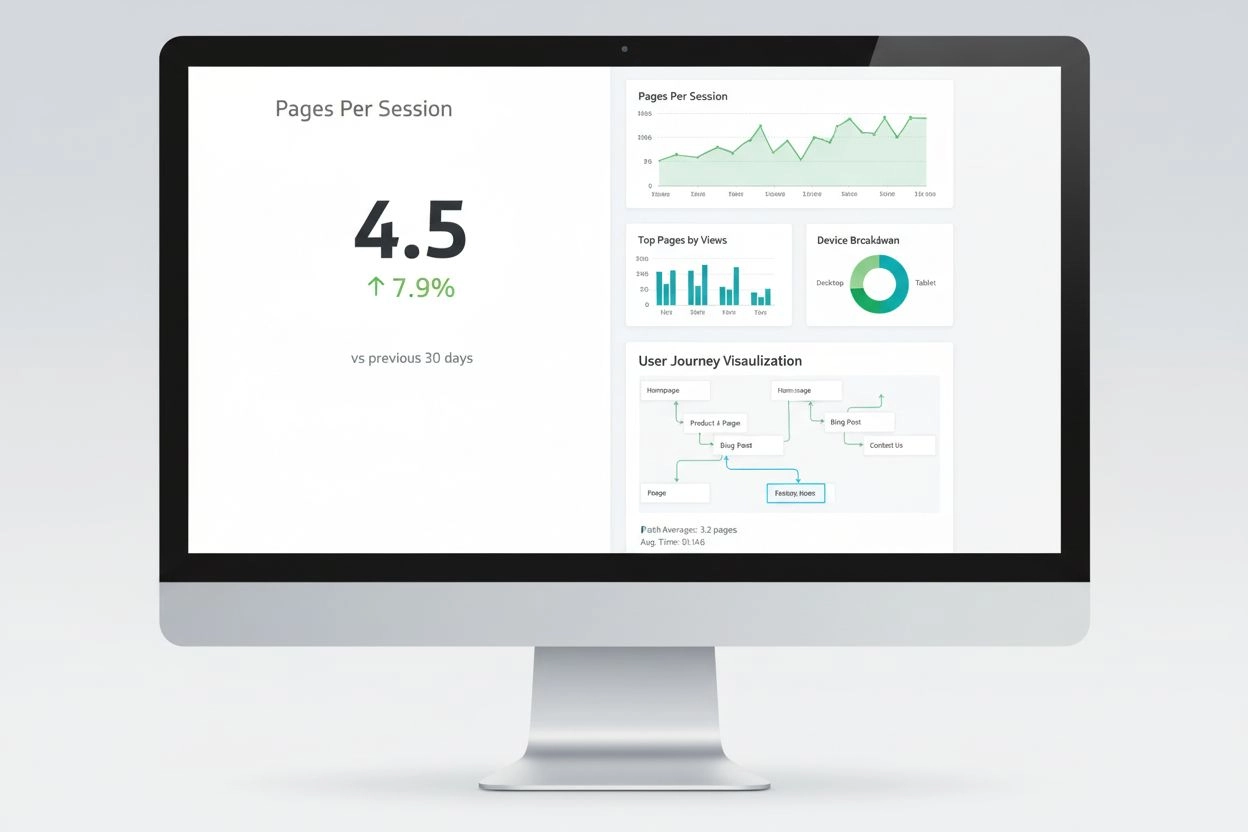
Pagini pe Sesiune măsoară numărul mediu de pagini vizualizate pe vizită. Află cum această metrică de implicare influențează comportamentul utilizatorilor, ratel...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.