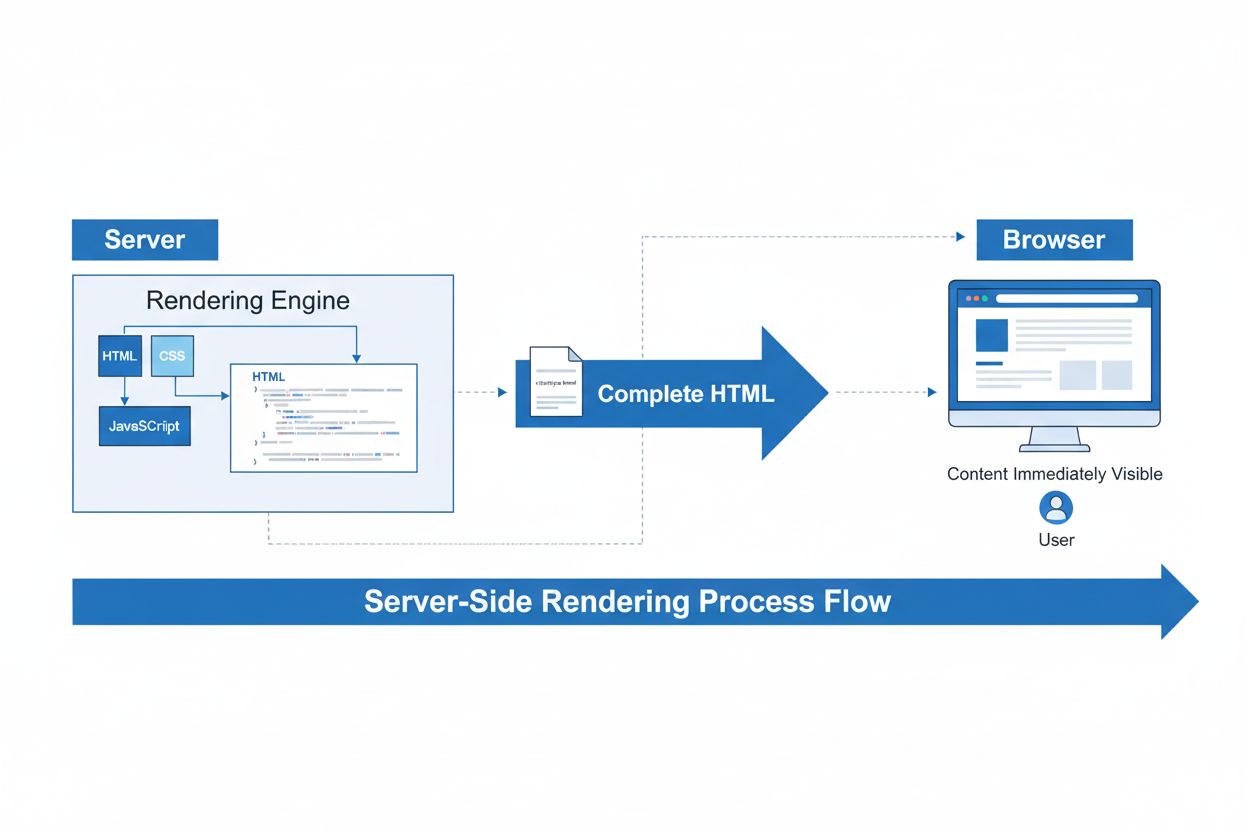
Server-Side Rendering (SSR)
Server-Side Rendering (SSR) este o tehnică web în care serverele redau pagini HTML complete înainte de a le trimite către browsere. Află cum SSR îmbunătățește S...
12 min citire

Află cum redarea pe partea de server permite procesare AI eficientă, implementarea modelelor și inferență în timp real pentru aplicații cu inteligență artificială și fluxuri de lucru LLM.
Redarea pe partea de server pentru AI este o abordare arhitecturală în care modelele de inteligență artificială și procesarea inferenței au loc pe server, nu pe dispozitivele client. Aceasta permite gestionarea eficientă a sarcinilor AI cu cerințe computaționale ridicate, asigură performanță constantă pentru toți utilizatorii și simplifică implementarea și actualizarea modelelor.
Redarea pe partea de server pentru AI se referă la un model arhitectural în care modelele de inteligență artificială, procesarea inferenței și sarcinile computaționale sunt executate pe serverele de backend în loc de pe dispozitivele client, cum ar fi browserele sau telefoanele mobile. Această abordare diferă fundamental de redarea tradițională pe partea de client, unde JavaScript rulează în browserul utilizatorului pentru a genera conținut. În aplicațiile AI, redarea pe partea de server înseamnă că modelele lingvistice mari (LLM), inferența de machine learning și generarea de conținut asistată de AI au loc centralizat pe infrastructuri server puternice înainte ca rezultatele să fie trimise utilizatorilor. Această schimbare arhitecturală a devenit din ce în ce mai importantă pe măsură ce capabilitățile AI au devenit mai solicitante computațional și integrale pentru aplicațiile web moderne.
Conceptul a apărut din recunoașterea unei nepotriviri critice între ceea ce cer aplicațiile AI moderne și ceea ce pot oferi în mod realist dispozitivele client. Framework-urile tradiționale de dezvoltare web precum React, Angular și Vue.js au popularizat redarea pe partea de client în anii 2010, dar această abordare creează provocări semnificative când este aplicată fluxurilor de lucru intensive AI. Redarea pe partea de server pentru AI abordează aceste provocări folosind hardware specializat, management centralizat al modelelor și infrastructură optimizată pe care dispozitivele client pur și simplu nu le pot egala. Aceasta reprezintă o schimbare fundamentală de paradigmă în modul în care dezvoltatorii proiectează aplicații cu AI integrat.
Cerințele computaționale ale sistemelor AI moderne fac ca redarea pe partea de server să fie nu doar benefică, ci adesea necesară. Dispozitivele client, în special smartphone-urile și laptopurile accesibile, nu au suficientă putere de procesare pentru a gestiona eficient inferența AI în timp real. Când modelele AI rulează pe dispozitivele client, utilizatorii se confruntă cu întârzieri vizibile, descărcarea rapidă a bateriei și performanță inconstantă, în funcție de capabilitățile hardware-ului lor. Redarea pe partea de server elimină aceste probleme prin centralizarea procesării AI pe infrastructuri dotate cu GPU-uri, TPU-uri și acceleratoare AI specializate care oferă performanțe cu mult peste cele ale dispozitivelor de consum.
Dincolo de performanța brută, redarea pe partea de server pentru AI oferă avantaje critice în managementul modelelor, securitate și consistență. Când modelele AI rulează pe servere, dezvoltatorii pot actualiza, ajusta și implementa instantaneu versiuni noi fără ca utilizatorii să fie nevoiți să descarce actualizări sau să gestioneze diferite versiuni local. Acest lucru este deosebit de important pentru modelele lingvistice mari și sistemele de machine learning care evoluează rapid cu îmbunătățiri și patch-uri de securitate frecvente. În plus, păstrarea modelelor AI pe servere previne accesul neautorizat, extragerea modelelor și furtul de proprietate intelectuală, riscuri care apar atunci când modelele sunt distribuite către dispozitivele client.
| Aspect | AI pe partea de client | AI pe partea de server |
|---|---|---|
| Locația procesării | Browserul sau dispozitivul utilizatorului | Servere de backend |
| Cerințe hardware | Limitate de capabilitățile dispozitivului | GPU-uri, TPU-uri, acceleratoare AI specializate |
| Performanță | Variabilă, dependentă de dispozitiv | Constantă, optimizată |
| Actualizări model | Necesită descărcări de la utilizator | Implementare instantanee |
| Securitate | Modelele expuse extragerii | Modelele protejate pe servere |
| Latență | Depinde de puterea dispozitivului | Infrastructură optimizată |
| Scalabilitate | Limitată la nivel de dispozitiv | Scalabilitate ridicată între utilizatori |
| Complexitate de dezvoltare | Mare (fragmentare dispozitive) | Mică (management centralizat) |
Suprasarcina de rețea și latența reprezintă provocări semnificative în aplicațiile AI. Sistemele AI moderne necesită comunicare constantă cu serverele pentru actualizări de modele, acces la date de antrenament și scenarii de procesare hibridă. Redarea pe partea de client crește ironic numărul de cereri de rețea față de aplicațiile tradiționale, reducând avantajele de performanță pe care ar trebui să le ofere procesarea pe partea de client. Redarea pe partea de server consolidează aceste comunicări, reducând întârzierile și permițând funcționalități AI în timp real precum traducere live, generare de conținut și procesare computer vision să ruleze fluent, fără penalizările de latență ale inferenței pe partea de client.
Complexitatea sincronizării apare atunci când aplicațiile AI trebuie să mențină consistența stării între mai multe servicii AI simultan. Aplicațiile moderne folosesc adesea servicii de embedding, modele de completare, modele ajustate și motoare de inferență specializate care trebuie să colaboreze. Gestionarea acestei stări distribuite pe dispozitivele client introduce complexitate semnificativă și creează potențial de inconsistențe de date, mai ales în funcționalități AI colaborative în timp real. Redarea pe partea de server centralizează managementul stării, asigurând rezultate consistente pentru toți utilizatorii și eliminând efortul de inginerie necesar sincronizării complexe pe partea de client.
Fragmentarea dispozitivelor creează provocări mari de dezvoltare pentru AI pe partea de client. Dispozitivele diferă foarte mult în ceea ce privește capabilitățile AI, inclusiv unități de procesare neurală, accelerare GPU, suport WebGL și constrângeri de memorie. Crearea unor experiențe AI consistente într-un astfel de peisaj fragmentat necesită eforturi de inginerie substanțiale, strategii de degradare grațioasă și mai multe ramuri de cod pentru diferite capabilități hardware. Redarea pe partea de server elimină complet această fragmentare, asigurând că toți utilizatorii accesează aceeași infrastructură AI optimizată, indiferent de specificațiile dispozitivului lor.
Redarea pe partea de server permite arhitecturi de aplicații AI mai simple și mai ușor de întreținut prin centralizarea funcționalității critice. În loc să distribuie modele AI și logica de inferență către mii de dispozitive client, dezvoltatorii mențin o implementare unică, optimizată, pe servere. Această centralizare aduce beneficii imediate precum cicluri de implementare mai rapide, depanare mai ușoară și optimizare de performanță mai simplă. Când un model AI necesită îmbunătățiri sau se descoperă un bug, dezvoltatorii îl rezolvă o singură dată pe server, în loc să încerce să trimită update-uri către milioane de dispozitive client cu rate de adopție variabile.
Eficiența resurselor se îmbunătățește dramatic cu redarea pe partea de server. Infrastructura server permite partajarea eficientă a resurselor între toți utilizatorii, cu pooling de conexiuni, strategii de caching și load balancing pentru optimizarea utilizării hardware-ului. Un singur GPU pe server poate procesa cererile de inferență ale miilor de utilizatori secvențial, în timp ce distribuirea aceleiași capacități pe dispozitivele client ar necesita milioane de GPU-uri. Această eficiență se traduce în costuri operaționale mai mici, impact redus asupra mediului și scalabilitate mai bună pe măsură ce aplicațiile cresc.
Securitatea și protecția proprietății intelectuale devin mult mai ușor de gestionat cu redarea pe partea de server. Modelele AI reprezintă investiții substanțiale în cercetare, date de antrenament și resurse computaționale. Păstrarea modelelor pe servere previne atacurile de extragere a modelelor, accesul neautorizat și furtul de proprietate intelectuală care devin posibile când modelele sunt distribuite către dispozitive client. În plus, procesarea pe server permite control de acces detaliat, jurnalizare a acțiunilor și monitorizare a conformității imposibil de aplicat pe dispozitivele client distribuite.
Framework-urile moderne au evoluat pentru a susține eficient redarea pe partea de server pentru fluxuri de lucru AI. Next.js conduce această evoluție cu Server Actions care permit procesarea AI direct din componentele de server. Dezvoltatorii pot apela API-uri AI, procesa modele lingvistice mari și transmite răspunsuri către client cu minim de cod boilerplate. Framework-ul gestionează complexitatea comunicării server-client, permițând dezvoltatorilor să se concentreze pe logica AI, nu pe infrastructură.
SvelteKit oferă o abordare axată pe performanță pentru redarea AI pe partea de server prin load functions care rulează pe server înainte de redare. Acest lucru permite pre-procesare de date AI, generare de recomandări și pregătire de conținut îmbunătățit cu AI înainte de a trimite HTML către client. Aplicațiile rezultate au o amprentă JavaScript minimă, menținând în același timp toate capabilitățile AI, ceea ce duce la experiențe excepțional de rapide.
Unelte specializate precum Vercel AI SDK abstractizează complexitatea transmiterii răspunsurilor AI, gestionării numărării tokenilor și integrării diferitelor API-uri AI. Aceste instrumente permit dezvoltatorilor să creeze aplicații AI sofisticate fără cunoștințe profunde de infrastructură. Opțiuni de infrastructură precum Vercel Edge Functions, Cloudflare Workers și AWS Lambda asigură procesare AI pe partea de server distribuită global, reducând latența prin procesarea cererilor mai aproape de utilizatori, menținând totodată managementul centralizat al modelelor.
Redarea AI eficientă pe partea de server necesită strategii sofisticate de caching pentru a gestiona costurile computaționale și latența. Caching-ul cu Redis stochează răspunsuri AI solicitate frecvent și sesiuni de utilizator, eliminând procesarea redundantă pentru interogări similare. Caching-ul prin CDN distribuie conținut AI generat static la nivel global, asigurând că utilizatorii primesc răspunsuri de la servere apropiate geografic. Strategiile de caching la edge distribuie conținut procesat AI în rețelele edge, oferind răspunsuri cu latență ultra-redusă, în timp ce se menține managementul centralizat al modelelor.
Aceste abordări de caching lucrează împreună pentru a crea sisteme AI eficiente, scalabile la milioane de utilizatori fără creșteri proporționale în costuri computaționale. Prin cache-uirea răspunsurilor AI pe mai multe niveluri, aplicațiile pot servi majoritatea cererilor din cache, calculând răspunsuri noi doar pentru interogări cu adevărat noi. Aceasta reduce dramatic costurile de infrastructură și îmbunătățește experiența utilizatorului prin timpi de răspuns mai rapizi.
Evoluția către redarea pe partea de server reprezintă o maturizare a practicilor de dezvoltare web ca răspuns la cerințele AI. Pe măsură ce AI devine centrală pentru aplicațiile web, realitățile computaționale impun arhitecturi centrate pe server. Viitorul implică abordări hibride sofisticate care decid automat unde să redea în funcție de tipul de conținut, capabilitățile dispozitivului, condițiile rețelei și cerințele procesării AI. Framework-urile vor îmbunătăți progresiv aplicațiile cu capabilități AI, asigurând funcționalitatea de bază universală și experiențe îmbunătățite acolo unde este posibil.
Această schimbare de paradigmă integrează lecțiile din epoca Single Page Application și abordează provocările aplicațiilor native AI. Uneltele și framework-urile sunt pregătite pentru ca dezvoltatorii să valorifice beneficiile redării pe partea de server în era AI, permițând apariția noii generații de aplicații web inteligente, receptive și eficiente.
Urmărește cum apar domeniul și brandul tău în răspunsurile generate de AI pe ChatGPT, Perplexity și alte motoare de căutare AI. Obține informații în timp real despre vizibilitatea ta în AI.
Server-Side Rendering (SSR) este o tehnică web în care serverele redau pagini HTML complete înainte de a le trimite către browsere. Află cum SSR îmbunătățește S...

Află cum redarea dinamică influențează vizibilitatea crawlerilor AI, ChatGPT, Perplexity și Claude. Descoperă de ce sistemele AI nu pot reda JavaScript și cum s...
Află cum redarea JavaScript influențează vizibilitatea site-ului tău în motoarele de căutare AI precum ChatGPT, Perplexity și Claude. Descoperă de ce crawlerii ...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.