
Managementul crawlerelor AI
Află cum să gestionezi accesul crawlerelor AI la conținutul site-ului tău. Înțelege diferența dintre crawlerele de antrenare și cele de căutare, implementează c...
8 min citire
Strategii pentru a asigura că sistemele AI au acces la conținut actualizat, nu la versiuni învechite din cache. Managementul cache-ului echilibrează avantajele de performanță ale cache-ului cu riscul de a furniza informații depășite, folosind strategii de invalidare și monitorizare pentru a menține prospețimea datelor și a reduce latența și costurile.
Strategii pentru a asigura că sistemele AI au acces la conținut actualizat, nu la versiuni învechite din cache. Managementul cache-ului echilibrează avantajele de performanță ale cache-ului cu riscul de a furniza informații depășite, folosind strategii de invalidare și monitorizare pentru a menține prospețimea datelor și a reduce latența și costurile.
Managementul cache-ului AI se referă la abordarea sistematică de stocare și regăsire a rezultatelor calculate anterior, a ieșirilor modelelor sau a răspunsurilor API pentru a evita procesarea redundantă și a reduce latența în sistemele de inteligență artificială. Provocarea principală constă în echilibrarea beneficiilor de performanță ale datelor cache-uite cu riscul de a oferi informații învechite sau depășite care nu mai reflectă starea curentă a sistemului sau cerințele utilizatorului. Aceasta devine deosebit de critică în modelele mari de limbaj (LLM) și în aplicațiile AI unde costurile de inferență sunt substanțiale, iar timpul de răspuns influențează direct experiența utilizatorului. Sistemele de management al cache-ului trebuie să determine inteligent când rezultatele cache-uite rămân valide și când este necesară o nouă procesare, ceea ce face din această componentă o considerație arhitecturală fundamentală pentru implementările AI în producție.
Impactul unui management eficient al cache-ului asupra performanței sistemelor AI este semnificativ și măsurabil pe multiple planuri. Implementarea strategiilor de caching poate reduce latența răspunsului cu 80-90% pentru interogări repetate și, simultan, poate reduce costurile API cu 50-90%, în funcție de rata de acces la cache și de arhitectura sistemului. Dincolo de metricile de performanță, managementul cache-ului influențează direct consistența acurateței și fiabilitatea sistemului, deoarece invalidarea corectă a cache-ului asigură utilizatorilor informații actuale, în timp ce un management deficitar poate introduce probleme de învechire a datelor. Aceste îmbunătățiri devin tot mai importante pe măsură ce sistemele AI se extind pentru a procesa milioane de cereri, unde efectul cumulativ al eficienței cache-ului determină direct costurile infrastructurii și satisfacția utilizatorilor.
| Aspect | Sisteme cu cache | Sisteme fără cache |
|---|---|---|
| Timp de răspuns | Cu 80-90% mai rapid | Bază (de referință) |
| Costuri API | Reducere de 50-90% | Cost integral |
| Acuratețe | Consistentă | Variabilă |
| Scalabilitate | Mare | Limitată |
Strategiile de invalidare a cache-ului stabilesc cum și când datele cache-uite sunt reîmprospătate sau eliminate din stocare, reprezentând una dintre cele mai critice decizii în proiectarea arhitecturii cache-ului. Diferite abordări de invalidare oferă compromisuri distincte între prospețimea datelor și performanța sistemului:
Alegerea strategiei de invalidare depinde fundamental de cerințele aplicației: sistemele care prioritizează acuratețea datelor pot accepta costuri de latență mai mari prin invalidare agresivă, în timp ce aplicațiile critice pentru performanță pot tolera date ușor învechite pentru a menține timpi de răspuns sub-milisecundă.
Caching-ul prompturilor în modelele mari de limbaj reprezintă o aplicație specializată de management al cache-ului care stochează stări intermediare ale modelului și secvențe de tokeni pentru a evita reprocesarea unor intrări identice sau similare. LLM-urile suportă două abordări principale de caching: caching exact, care potrivește prompturile identic, caracter cu caracter, și caching semantic, care identifică prompturi echivalente funcțional, chiar dacă sunt formulate diferit. OpenAI implementează caching automat al prompturilor cu o reducere de 50% a costurilor pentru tokenii cache-uiți, necesitând segmente minime de prompt de 1024 tokeni pentru a activa beneficiile caching-ului. Anthropic oferă caching manual al prompturilor cu reduceri de costuri de până la 90%, dar necesită ca dezvoltatorii să gestioneze explicit cheile de cache și durata acestora, cu cerințe minime de cache între 1024-2048 tokeni, în funcție de configurația modelului. Durata cache-ului în sistemele LLM variază de obicei de la câteva minute la câteva ore, echilibrând economiile computaționale obținute prin reutilizarea stărilor cache-uite cu riscul de a furniza rezultate depășite pentru aplicații sensibile la timp.
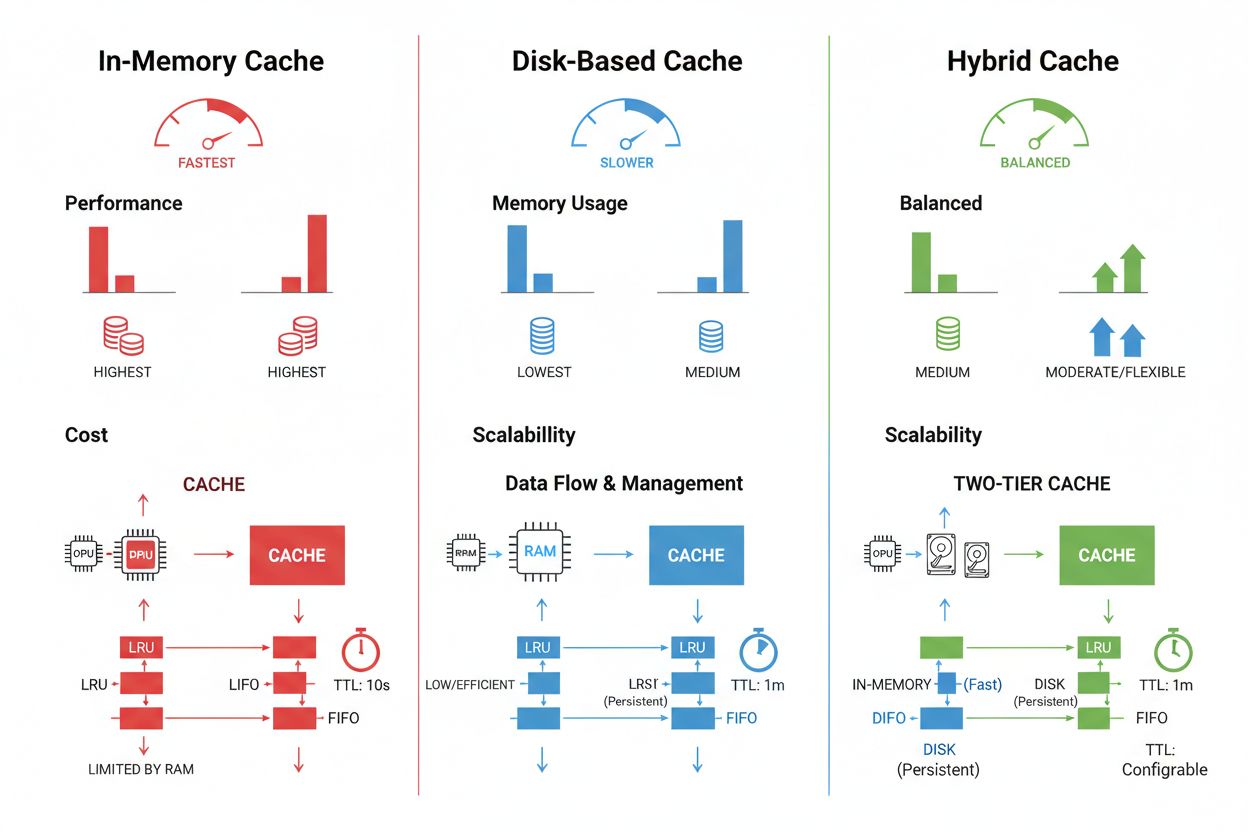
Tehnicile de stocare și management al cache-ului variază semnificativ în funcție de cerințele de performanță, volumul de date și constrângerile infrastructurale, fiecare abordare având avantaje și limitări distincte. Soluțiile de caching în memorie, precum Redis, oferă viteze de acces la nivel de microsecundă, ideale pentru interogări cu frecvență ridicată, dar consumă multă memorie RAM și necesită o gestionare atentă a acesteia. Caching-ul pe disc permite gestionarea unor seturi de date mai mari și persistă la repornirea sistemului, dar introduce o latență de ordinul milisecundelor comparativ cu soluțiile în memorie. Abordările hibride combină ambele tipuri de stocare, direcționând datele accesate frecvent în memorie și păstrând seturile de date mai mari pe disc:
| Tip de stocare | Potrivit pentru | Performanță | Consum de memorie |
|---|---|---|---|
| În memorie (Redis) | Interogări frecvente | Cea mai rapidă | Ridicat |
| Pe disc | Seturi de date mari | Moderată | Scăzut |
| Hibrid | Sarcini mixte | Echilibrată | Echilibrat |
Un management eficient al cache-ului necesită configurarea unor setări TTL adecvate care să reflecte volatilității datelor—TTL-uri scurte (minute) pentru date care se schimbă rapid versus TTL-uri mai lungi (ore/zile) pentru conținut stabil—combinate cu monitorizarea continuă a ratei de acces la cache, a tiparelor de eliminare și a utilizării memoriei pentru identificarea oportunităților de optimizare.
Aplicațiile AI din lumea reală demonstrează atât potențialul transformator, cât și complexitatea operațională a managementului cache-ului în diverse scenarii de utilizare. Chatboții pentru servicii clienți utilizează caching-ul pentru a oferi răspunsuri consistente la întrebări frecvente, reducând costurile de inferență cu 60-70% și permițând o scalare eficientă la mii de utilizatori simultan. Asistenții de programare cache-uiesc tipare de cod și fragmente de documentație comune, permițând dezvoltatorilor să primească sugestii de completare automată cu latențe sub 100ms chiar și în perioadele de vârf. Sistemele de procesare a documentelor cache-uiesc embedding-uri și reprezentări semantice ale documentelor analizate frecvent, accelerând semnificativ căutările de similaritate și sarcinile de clasificare. Totuși, managementul cache-ului în producție introduce provocări semnificative: complexitatea invalidării crește exponențial în sistemele distribuite unde consistența cache-ului trebuie menținută între mai multe servere, constrângerile de resurse impun compromisuri dificile între dimensiunea și acoperirea cache-ului, apar riscuri de securitate atunci când datele cache-uite conțin informații sensibile ce necesită criptare și control al accesului, iar coordonarea actualizărilor cache-ului între microservicii poate duce la condiții de cursă și inconsistențe ale datelor. Soluțiile de monitorizare cuprinzătoare care urmăresc prospețimea cache-ului, rata de acces și evenimentele de invalidare devin esențiale pentru menținerea fiabilității sistemului și identificarea momentului când strategiile de cache trebuie ajustate în funcție de evoluția tiparelor de date și a comportamentului utilizatorilor.
Invalidarea cache-ului elimină sau actualizează datele învechite atunci când apar modificări, oferind prospețime imediată, dar necesitând declanșatori bazate pe evenimente. Expirarea cache-ului stabilește o limită de timp (TTL) pentru perioada în care datele rămân în cache, oferind o implementare mai simplă, dar putând furniza date învechite dacă TTL-ul este prea mare. Multe sisteme combină ambele abordări pentru performanță optimă.
Un management eficient al cache-ului poate reduce costurile API cu 50-90% în funcție de rata de acces la cache și de arhitectura sistemului. Caching-ul prompturilor la OpenAI oferă o reducere de 50% a costurilor pentru tokenii cache-uiți, iar Anthropic oferă până la 90% reducere. Economiile reale depind de tiparele de interogare și de cât de multe date pot fi cache-uite eficient.
Caching-ul prompturilor stochează stările intermediare ale modelului și secvențele de tokeni pentru a evita reprocesarea unor intrări identice sau similare în modelele mari de limbaj. Suportă caching exact (potrivire caracter cu caracter) și caching semantic (prompturi echivalente funcțional cu formulări diferite). Aceasta reduce latența cu 80% și costurile cu 50-90% pentru interogări repetate.
Strategiile principale sunt: Expirarea pe bază de timp (TTL) pentru eliminare automată după o anumită durată, Invalidarea pe bază de eveniment pentru actualizări imediate la schimbarea datelor, Invalidarea semantică pentru interogări similare pe bază de semnificație, și abordări hibride ce combină mai multe strategii. Alegerea depinde de volatilitatea datelor și cerințele de prospețime.
Caching-ul în memorie (precum Redis) oferă viteze de acces la nivel de microsecundă, ideal pentru interogări frecvente, dar consumă multă RAM. Caching-ul pe disc permite gestionarea unor seturi de date mai mari și persistă la reporniri, dar introduce latență la nivel de milisecundă. Abordările hibride combină ambele metode, direcționând datele accesate frecvent în memorie, păstrând seturi mari pe disc.
TTL este un cronometru care stabilește cât timp datele cache-uite rămân valide înainte de expirare. TTL-urile scurte (minute) sunt potrivite pentru date care se schimbă rapid, în timp ce TTL-urile mai lungi (ore/zile) sunt adecvate pentru conținut stabil. Configurarea corectă a TTL-ului echilibrează prospețimea datelor cu evitarea reîmprospătărilor inutile ale cache-ului și încărcarea serverului.
Un management eficient al cache-ului permite sistemelor AI să gestioneze semnificativ mai multe cereri fără extinderea proporțională a infrastructurii. Prin reducerea sarcinii computaționale per cerere, sistemele pot deservi milioane de utilizatori mai eficient din punct de vedere al costurilor. Rata de acces la cache determină direct costurile de infrastructură și satisfacția utilizatorilor în producție.
Cache-uirea datelor sensibile introduce vulnerabilități de securitate dacă nu sunt criptate corespunzător și controlate accesul. Riscurile includ accesul neautorizat la informații cache-uite, expunerea datelor în timpul invalidării cache-ului și cache-uirea accidentală a conținutului confidențial. Criptarea completă, controlul accesului și monitorizarea sunt esențiale pentru protejarea datelor sensibile din cache.
AmICited urmărește modul în care sistemele AI fac referire la brandul tău și asigură că conținutul tău rămâne actual în cache-urile AI. Obține vizibilitate asupra managementului cache-ului AI și prospețimii conținutului în GPT, Perplexity și Google AI Overviews.
Află cum să gestionezi accesul crawlerelor AI la conținutul site-ului tău. Înțelege diferența dintre crawlerele de antrenare și cele de căutare, implementează c...

Află cum să gestionezi crizele de reputație de brand în răspunsurile generate de AI de la ChatGPT, Perplexity și alte motoare de căutare AI. Descoperă strategii...
Află ce înseamnă managementul reputației pentru căutarea AI, de ce contează pentru brandul tău și cum să îți monitorizezi prezența în ChatGPT, Perplexity, Claud...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.